
“ RAG中召回策略有多种多样,但同样构建上下文也有很多方法。”
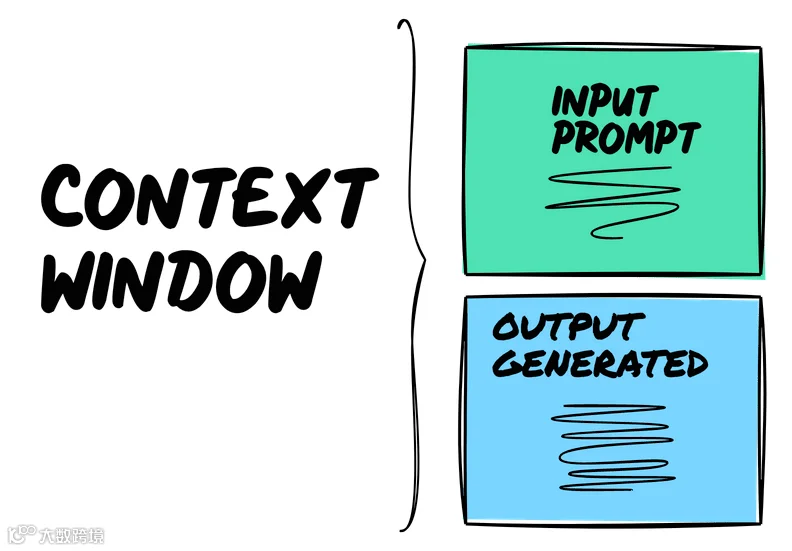
之前在社群有过一次关于关键字和语义检索的讨论,不过当时两个人好像不在一个频道上,他说他的关键字召回,我说我是语义召回,然后讨论到了怎么chunk的问题。
在关键字召回中,需要根据段落和语句进行分词,如jieba分词库;因此一般情况下会使用段落和句子的chunk方式,但是在语义检索中,分词会使用多种组合策略,如标题,段落,句子,长度等;使用不同的检索方式需要用到不同的chunk策略才能达到最好的效果。
然后这里对方又提了一个问题,你是怎么构建上下文的?
当时看到这句话就觉得好莫名其妙,肯定是用召回的数据做上下文啊;但是仔细一想好像又不太对,然后他又问你是怎么做chunk和文档的关联关系的,看到这里发现事情好像远远没有自己想的那么简单。之后,他又问了一句,你会根据chunk的内容,再次召回完整段落吗?
OK,这时就发现问题出在哪了,应该用什么构建上下文?
怎么构建上下文
在RAG中,构建上下文是很重要的一件事,也是整个RAG流程中的最后一步;一般情况下,都会用问题,历史记录,系统提示词以及召回的文档一起构建上下文。
但现在这个问题就出在召回的文档上,应该召回哪些文档?
从语义召回的角度来说,召回文档肯定是根据语义进行召回,召到那些数据就用那些数据做上下文,或者再进行一次rerank重排,之后再做上下文。
但是这里有个问题,假如说你的一个文档有十个段落,然后每个段落被拆分成三个chunk,这时就有三十个chunk,然后你根据语义召回时,召回了其中的五个chunk,然后这五个chunk分别位于其中的三个段落中。
这时,就出现了一个问题,如果从语义相似度的角度出发,应该使用这五个chunk做上下文,因为它们语义相似度最高;但是这里不知道大家有没有想过这样一个问题?
从正常的逻辑上来讲,每个段落的内容相关度应该是最高的;因此,理论来说语义相似度召回的数据也应该是在一个或两个段落中;但是现在的问题是,语义最相关的出现在了其中的三个段落中,也就是说相关性最高的段落中有一部分数据是语义无关的?这里是不是就矛盾了?
说到这里可能很多人觉得很绕,那我们就说的直白点;理论上来说,我们召回了五个chunk,然后这五个chunk存在三个段落中;这时,理论上我们应该把这三个段落的完整内容拿来做上下文,因为段落之间肯定是高度相关的内容。
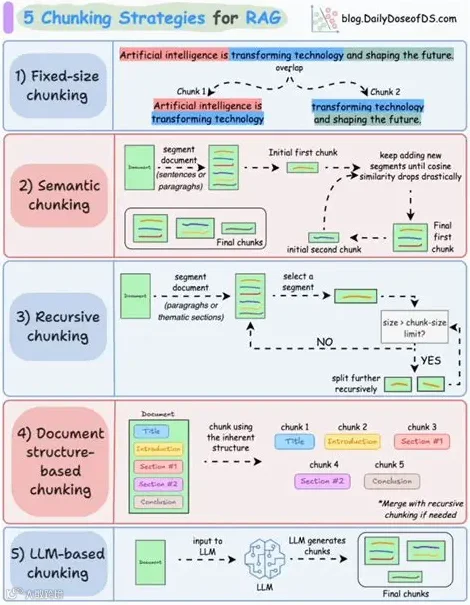
但事实上,我们可能很多人只是用这五个chunk做上下文,而不是考虑把这三个段落的内容全部拿出来做上下文。所以,这时我们应该怎么选才合适?
其实,这两者之间并不是非此即彼的关系,理论上来说我们可以选择任何一种方式,也可以采用两者混合的方式;举例来说,如果一个文档段落数据长短不一,长的有几百上千字,短的才几十上百字;如果按照统一的段落构建上下文,这时可能会出现大量的噪音数据,并且会严重影响到模型的生成质量和加快token消耗。
所以,根据chunk召回完整段落内容,可以根据不同的场景选择折中的方案,而不是一棒子打死,必须使用某种方式。并且,有时为了减少token消耗,提升模型的准确性,我们可能还会对召回的数据做语义合并,尽量减少上下文的长度。