“ Agent智能体之所以是一个魔鬼,是因为它的问题都隐藏在细节里。”
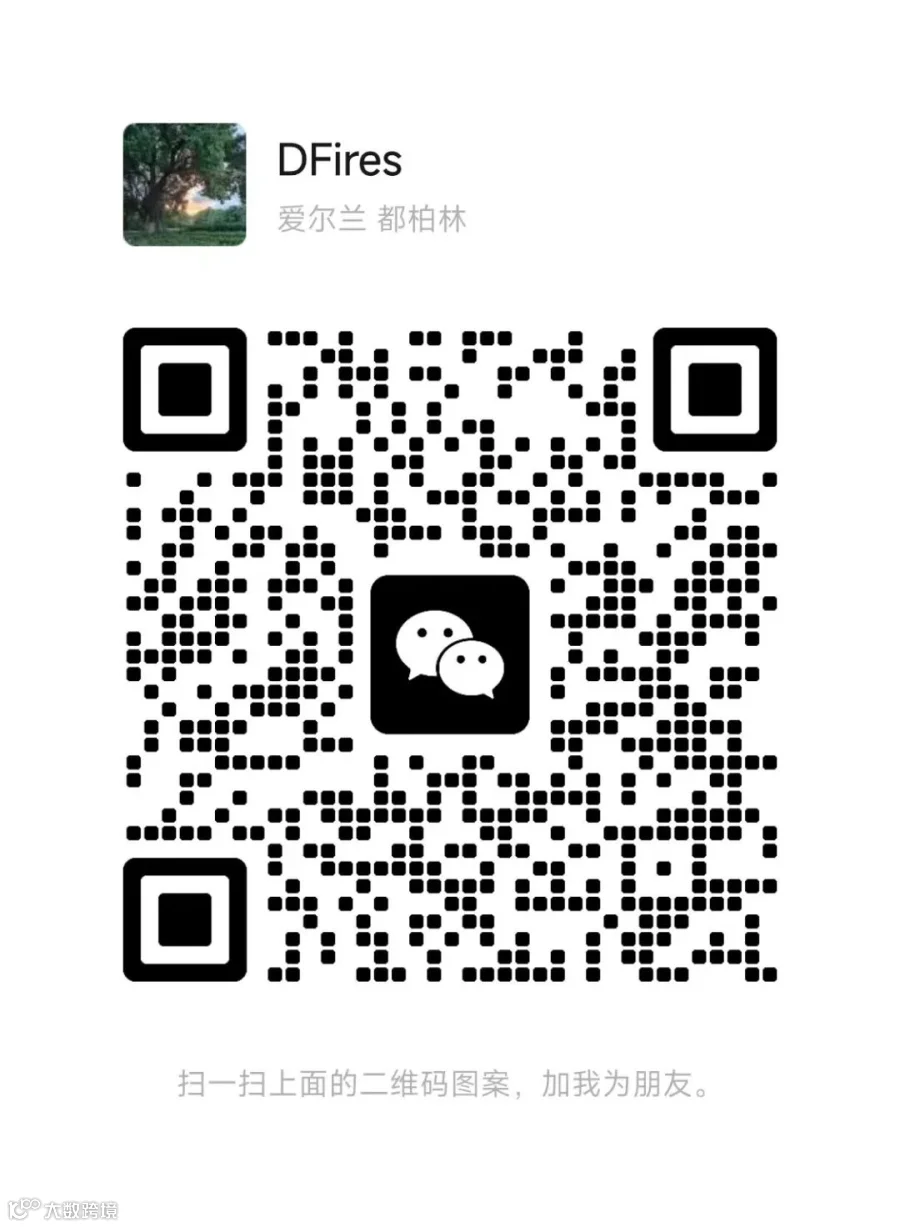
很多人觉得 Agent 高深莫测、LangGraph / 各类框架眼花缭乱,又是状态机又是节点流转,扒开所有封装与花哨概念,原生 Agent 的核心逻辑,就5 步循环。
一、先拆解最朴素的 Agent 底层源码
就是代码里这套 while 死循环,所有智能体,从简易工具调用到复杂多轮自主规划,根基全来自这 5 步:
while not done:#1 把当前状态给LLMresponse = llm.chat(system_prompt + state + tool_descriptions)#2 解析LLM决策action = parse_action(response)#3 执行工具result = execute_tool(action)#4 更新状态state = update_state(state, action, result)#5 判断是否结束done = check_completion(state)
就这么几行,剩下的都是细节;但这些细节里隐藏着无数的魔鬼。
一句话总结:LLM 思考→出工具指令→调用工具拿真实数据→更新上下文→判断收不收尾,没完就循环复盘
二、框架那么复杂,到底在封装什么?
不少初学者上手 LangGraph、AutoGPT、OpenAI Agent SDK,被节点、边、路由、子图绕晕,其实框架做的只有三件事:
state是个字典,框架改成强类型结构体,区分用户问题、历史对话、工具返回、中间草稿,避免上下文乱拼接、字段错乱。
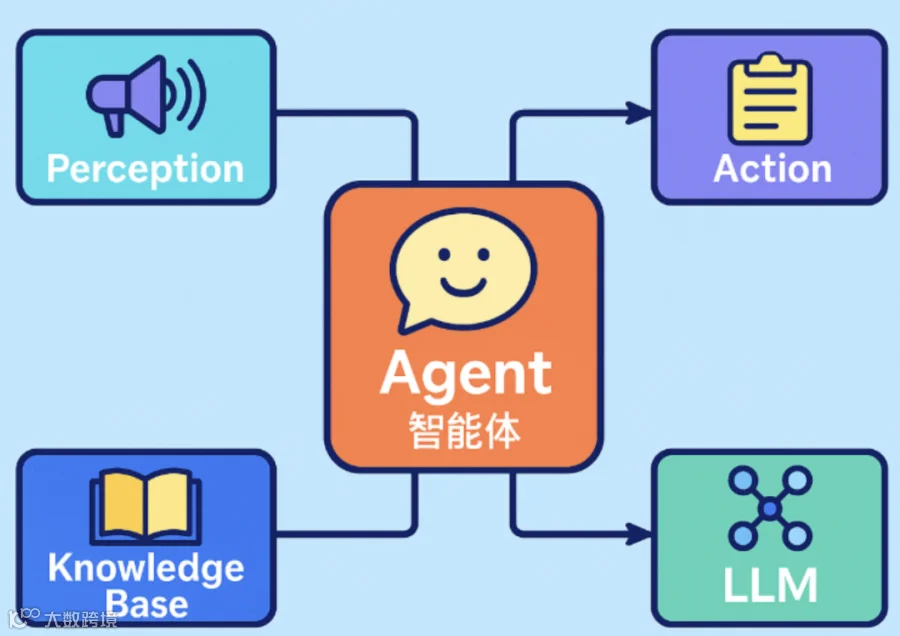
一句话戳破真相:核心逻辑永远是 5 步循环,框架只是给细节做工程化兜底。
三、决定 Agent 上限的,全是不起眼的细节
同样的 5 步代码,有人做出来一问就乱调用工具,有人能自主完成复杂调研、数据分析任务,差距全藏在细碎优化里:
1、第一步:Prompt 与上下文(最影响思考方向)
parse_action解析直接崩盘。
2、第二步:Action 解析容错
大模型天生输出自由文本,偶尔不按指定 JSON / 标签格式返回,健壮的解析器要做:正则兜底、错误重试、格式纠错,简陋解析直接抛出异常,Agent 当场中断。
3、第三步:工具执行层
工具接口异常、返回空数据、报错信息杂乱,要不要把错误信息精简后塞回 state?粗暴丢原始报错会污染 LLM 后续思考。
4、第四步:状态更新规则
哪些信息留存历史、哪些临时丢弃?工具冗余返回、无效思考记录不做过滤,会持续干扰后续 LLM 决策。
5、第五步:终止条件设计
靠 LLM 自主判断结束?还是配置关键词 / 结果阈值?终止规则不合理要么任务没完没了无限循环,要么没做完就提前收尾。
市面上 90% Agent 效果差距,不在核心算法,全在上述细节打磨。
四、新手落地建议:从极简循环起步,别一上来堆重型框架
文末小结
Agent 没有玄学,万变不离 5 步循环。所有高大上的智能体产品、自研 Agent 平台,内核都是这套思考 - 行动 - 复盘闭环。看懂底层逻辑,再看各类 Agent 技术、框架选型,瞬间拨开迷雾。
文末互动:你踩过 Agent 哪些细节大坑?是工具乱调用还是上下文失控?
如果你也有类似的问题,可以加我微信聊聊或者评论区留言。