“ 文档内容提取是RAG文档预处理的第一步,比如说OCR技术。”
在RAG中很多人并没有意识到内容提取的重要性,甚至有些人简单认为只要把内容读出来即可;但事实上真的如此吗?内容提取可能远比你想的重要且复杂。
文档提取还要保留文档的结构用以构建metadata
内容提取
为什么在RAG中内容提取那么重要?
文档提取是RAG中文档预处理的第一步,而文档预处理的质量直接关系到整个RAG系统的质量;文档预处理做不好就会出现,文档里有就是召不回或者召回错误文档。
而且从文档预处理的流程来说,第一步内容提取,第二步数据清洗,第三步构建元数据,第四步切分,第五步向量化入库。
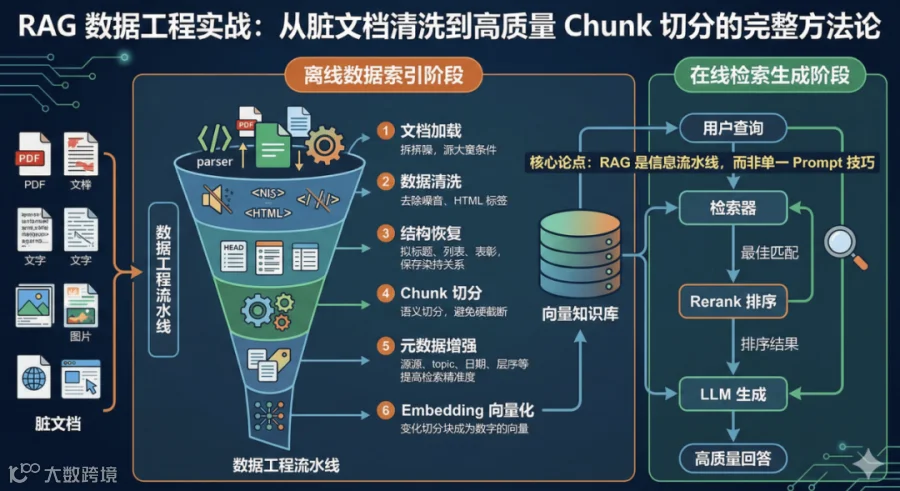
第一步内容提取如果处理不好,那么后面的步骤很难做好,毕竟第一步就是错的,后续怎么做也不可能得到正确的结果;这就是失之毫厘,差之千里。
文档提取并不是一些人认为的,只需要简单的读取文档内容即可,而是要处理复杂的文档结构,处理多种模态的数据类型;既要保证准确性,又要保证完整性和文档结构。
以PDF文件为例,这是一种对人类友好但对模型来说非常不友好的一种文档格式;比如说有些pdf文档会存在多栏排版的问题,简单的内容读取或者OCR扫描,会丢失文档内容的结构和顺序,导致整篇文档一片混乱无法处理。所以这时就需要使用具有版面分析能力的OCR才能保证内容的完整性。
其次,标题层级,段落顺序,列表,脚注,页眉页脚等都需要能识别出来才行;虽然页眉页脚等内容对chunk来说没什么意义,甚至被算作是噪音,但在构建元数据时,其又是必不可少的节点。
针对复杂文档,可能存在表格,图片,跨页内容等情况,如果提取不当就会导致文档内容混乱无法处理。
怎么进行文档提取?
文档提取一般借助于第三方文档处理工具包,但由于这些工具的能力限制,因此一般只能处理一些简单的文档;比如pdf处理工具pypdf2,excel处理工具pandas等。
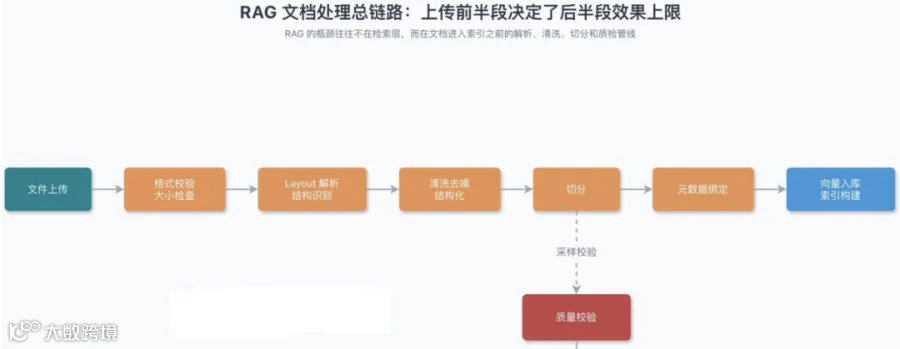
但在RAG中由于文档的复杂性,一般会使用OCR,多模态或者机器学习等多种方法来提升文档处理的效果。
而在真实的业务场景中,一般情况下不会只选择一种方式,而是同时集成多种不同的文档工具,针对不同的文档类型和文档内容,选择合适的处理策略。
总之,不管是OCR也好,自定义处理工具也好,亦或者其它方式;内容提取的目的就是拿到高质量,结构化的文档内容,尽可能的保证文档内容的完整性和准确性,这是下一步数据清洗,构建结构关系和切片的基础。
如果你也有RAG相关或者文档预处理相关的问题,可以给我私信或者添加微信进行交流。