

你po的照片,
可能被用来训练AI
分享照片已经成为互联网时代的人们习以为常的行为,现实中的生活得发到网上才能算圆满。但是正因为此,你可能已经成为人工智能的“老熟人”了。这究竟是怎么回事?本期Quiriosity带你一探究竟。

The photo is undeniably cute: a mom and a dad — he with a stubbly beard and rimless glasses, she with choppy brown hair and a wide grin — goofing around and eating ice cream with their two toddler daughters.
这无疑是一张有爱的照片:妈妈蓬乱着棕色头发笑容满面,爸爸带着无框眼镜一脸胡茬,还有一对蹒跚学步的女儿,一家人吃着冰激凌,嘻嘻哈哈地消磨时间

The picture, which was uploaded to photo-sharing site Flickr in 2013, isn't just adorable; with a bunch of different faces in various positions, it's also useful for training facial-recognition systems, which use artificial intelligence to identify people in photos and videos. It was among a million images that IBM harnessed for a new project that aims to help researchers study fairness and accuracy in facial recognition, called Diversity in Faces.
不过这张2013年上传到图片分享网站Flickr的照片不只是看起来有爱而已。由于照片中分布着不同的面孔,它还可以帮助训练人脸识别系统。该系统采用了人工智能技术,来识别照片和视频中的人。IBM公司的一个新项目“多样面孔”致力于协助研究人脸识别合理性与准确度。他们为此利用了一百万张照片,而这张家庭照只是其中之一。
The woman who shot the image, a librarian in rural Vermont named Jessamyn West, was surprised and angry when she found out the photo was being used by IBM. She had uploaded it to Flickr with a Creative Commons license that lets others use the photo. But something about not knowing that this image, along with other Creative Commons-licensed pictures she took — a self-portrait and about a dozen other shots — were included in a facial-recognition dataset bothered her.
这张照片的拍摄者是佛蒙特州乡村的一位名叫Jessamyn West的图书管理员。当她发现这张照片被IBM使用时,她感到又惊讶又愤怒。她上传到Flickr的照片具有知识共享许可,也就是说,其他人可以使用该照片。但是她并不知道这张照片以及其它获得知识共享许可的照片(一张个人肖像以及数张其他照片)都被纳入了人脸识别资料集中,这让她感到困扰。
For years researchers have turned to the internet to collect and annotate photos of all kinds of objects — including many, many faces — in hopes of making computers better understand the world around them. This frequently means using Creative Commons-licensed images from Flickr, pulling images from Google Image search, snagging them from public Instagram accounts or other methods (some legitimate, some perhaps not). The resulting datasets are typically meant for academic work, like training or testing a facial-recognition algorithm. But increasingly facial recognition is moving out of the labs and into the domain of big business, as companies such as Microsoft, Amazon, Facebook, and Google stake their futures on AI.
多年来,研究人员在互联网上收集和标记拍摄各种物体的照片,其中也包括许多人的面孔。他们希望能让计算机更好地了解周围的世界。也就是说,他们会使用来自Flickr的具有知识共享许可的图像,从Google Image搜索中提取图像,从公开的Instagram帐号中抓取图像,或者采用其他或合法或非法的方法获取图像。得到的数据集通常用于学术研究,如训练或测试人脸识别算法。但随着微软,亚马逊,Facebook和谷歌等公司将其未来押注于人工智能领域,面部识别越来越多地从实验室转移到大型企业。
And as consumers are increasingly aware of the power of the data they leave like breadcrumbs across the internet, facial-recognition datasets are becoming a flash point for worries about privacy and a future where surveillance may be more commonplace.
随着消费者越来越意识到他们在互联网上留下的像面包屑一样的数据具有怎样的威力,人脸识别数据集正成为人们对于隐私泄露以及在未来监控寻常化问题的担忧焦点。
As a result, some researchers say they're now rethinking the Wild West atmosphere that pervades the face-gathering status quo, and what it means to give consent for the use of an image of yourself (or of someone else that you photographed) in a world where we constantly share our lives online.
因此,一些研究人员表示,他们也在反思在人脸图像收集的方法上过于粗放的现状,以及反思在当今这个人人在网上分享生活的时代,用户许可使用个人照片(或是自己拍摄的他人肖像)意味着什么。
这些面孔从何而来?
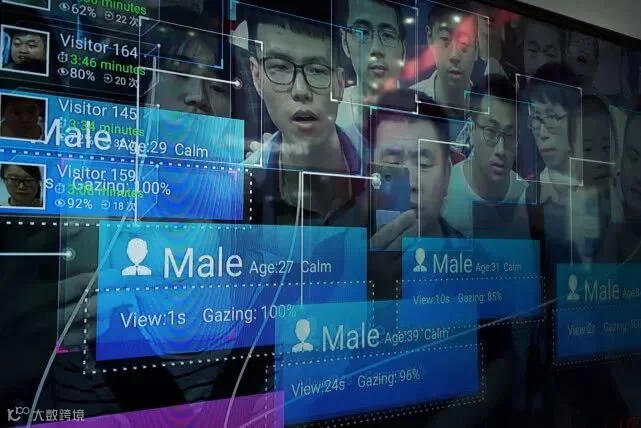
Facial recognition has improved dramatically in recent years due to the popularity of a powerful form of machine learning called deep learning. In a typical system, faces are scanned (from still images, videos, or a live stream), and their features analyzed and then compared with labeled faces in a database.
作为一种强有力的机器学习模式,“深度学习”的风靡使得人脸识别技术在近年来发展迅速。人脸识别系统从静态图片、视频或直播中扫描人脸,先是分析面孔特征,再与数据库中被标记的面孔作对比。
The technology is being used to fight human trafficking and help people speed through airport security; it's also being used for surveillance by law enforcement groups, at concerts, at sports events, and elsewhere.
人脸识别技术现被用于打击人口贩卖以及提高人们在机场通过安检的速度。(执法部门还在演唱会、体育比赛等其他场合利用该技术来监控现场。)
Yet there are still accuracy issues. Researchers are increasingly concerned about bias in AI systems, which is evident in, say, how well the tech can do things like correctly recognize people of color and women. One reason for this issue is that the datasets used to train the software may be disproportionately male and white; IBM believes Diversity in Faces is more balanced than previous datasets.
然而,人脸识别技术仍然不够精确。研究人员们越来越关心人工智能系统中存在的偏差。这些偏差在识别有色人种和女性时表现得尤为明显。这种问题出现的原因之一在于,用于训练软件的数据集里绝大多数是白人和男性的面孔。IBM认为,与此前的数据集相比,“多样面孔”数据集中的人脸变得更加多样了。
Diversity is important for training, but so is the sheer amount of data used. Facial recognition systems may be trained and tested on thousands or even millions of faces, and the internet has long been an irresistible resource.
人脸数据的多样性以及绝对数量对于训练AI都非常重要。人脸识别系统需要数千甚至数百万张脸来进行训练和测试,所以互联网长期以来一直是难以抗拒的资源库。
Those images had been uploaded to Flickr both by regular people like West, and by pros, all with Creative Commons licenses. These are special kinds of copyright licenses that clearly state the terms under which such images and videos can be used and shared by others, though you may not be thrilled about the specific ways they are used.
这些具有知识共享许可的照片被像West一样的普通人以及一些专业人士上传到Flickr。知识共享许可证是一种特殊的版权证书,它明确规定在某些条件下这些图片和视频可以被他人使用和分享,尽管你可能会对它们的具体用途感到失望。

Creative Commons licenses were first released in 2002, and Flickr in particular has been around since 2004 — way before the current AI boom.
知识共享许可证在2012年首次颁布,而Flickr早在2004年——人工智能狂潮到来许久之前——就已经出现在人们的视野之中了。
While researchers freely use images on sites like Flickr, they also acknowledge that many people posting these photos may be surprised to learn they can be used to train or test AI.
当研究人员们随心所欲地用着Flickr等网站上的照片时,他们也知道,发布这些照片的人得知照片被用于训练或测试AI后可能会感到惊讶。

调整预期
IBM told CNN Business that it is "committed to the privacy rights of individuals" and that anyone who is included in the dataset can opt out at any time. It's not offering a tool of its own to find out if specific images are linked in the dataset.
IBM告诉CNN商业版说,他们“致力于维护个体的隐私权”,并称数据库中的所有成员都能在任意时刻选择退出。(但)他们并不提供查找数据库中的特定图片的工具。
Meanwhile, researchers at graphics chip maker Nvidia are looking at IBM's experience and thinking about how to change their own practices.
同时,图形芯片制造商Nvidia的研究人员正在借鉴IBM的经验,思考着如何改进自己的产品。
In March, Nvidia released an online tool that lets people see if their images are included in the dataset used to train StyleGAN, an AI system unveiled in February. That dataset contains 70,000 high-quality, Creative Commons-licensed Flickr images.
Nvidia在3月发布了一款在线工具,让人们能看到自己的照片是否被收集在用于训练人工智能系统StyleGAN的数据集中,该系统在今年2月推出,其中囊括了7万张高质量且拥有知识共享许可的Flickr照片。

这些都是拿来训练StyleGAN AI系统的面孔
The company also included a list of steps users can take if they want their photo removed from the dataset, and if they'd like to avoid having it used for future computer-vision research. These suggestions include making the photo private, changing the license attached to it, or even adding a tag to the photo — a word or phrase associated with the image that's searchable on Flickr — that says "no_cv" to show they don't want it to be used for computer-vision research.
如果用户想要把他们的照片从数据库中撤走,或是不想让这些照片再被用于计算机视觉技术的研究,公司还为他们提供了一系列的方案。这些方案包括建议将照片标为个人所有,更换附在照片后的协议内容,或甚至是给照片加上标签——照片上附有的可在Flickr上搜索到的某个单词或短语——表达出“No cv(No computer vision)”的涵义,以表明他们不希望照片被用于计算机视觉技术的研究。
"I think a lot of people either don't care or would actively want their photos to go into something like StyleGAN," David Luebke, Nvidia's vice president of graphics research said."But if you don't, there should be a way to opt out."
“我觉得人们对于自己的照片被纳入StyleGan系统收录这种事,要么满不在乎,要么十分乐意。” David Luebke,Nvidia公司图像研究部门的副总裁说道。“但是如果你不想让自己的照片用于此类训练,我们就需要提供一种退出系统的方法。”
等待法律的援助

Artificial intelligence has been rolled out so swiftly in recent years that regulations have barely begun to be formulated, let alone implemented. And when it comes to gathering and using images for facial recognition, companies and researchers aren't legally obligated to tell people much of anything.
近年来,人工智能的发展势不可挡,人们基本上还没开始制定相关的规范,更不用说实行了。当谈及为人脸识别而收集和使用照片这一问题时,公司和研究人员并没有法律义务来告诉人们相关的细节。
There are no such federal rules related to how the technology can be built or used. A bit more has happened at the state level: Illinois, for example, has a law that requires companies get consent from customers before collecting biometric information. And the state senate in Amazon and Microsoft's home state of Washington recently passed a bill that limits the use of facial recognition. That bill still has to pass the state's house of representatives.
还没有相关的联邦法律规定这项技术可以怎样被开发或使用,不过各州已经有了一些进展:例如,伊利诺伊州的法律规定,公司必须得到顾客的许可后才能采集他们的生物信息。来自亚马逊和微软所在的华盛顿州的参议员们,最近刚通过了一项限制人脸识别技术使用的法案。不过这项法案还需要得到该州众议员的通过才能生效。
Creative Commons CEO Ryan Merkley and others think legislation concerning how data is gathered for training and testing this kind of technology should be considered. This could happen in the not-so-distant future: in March, a Senate bill was introduced that would force companies to get consent from consumers before collecting and sharing identifying data.
知识共享首席执行官Ryan Merkley和其他人都认为,对于训练和测试这种人脸识别技术所需要的数据,其采集方式应该纳入立法的考虑范围。今年三月,参议院提出了一项法案,强制要求公司要先获得用户的许可,才能进行人脸识别数据的采集和分享——而在不久的将来,这项法案或可成功推行。
Even in the absence of strict legal boundaries for using images of people to train AI systems, there's an ethical boundary companies and research groups should pass, said Jeremy Gillula, technology policy director for digital rights group the Electronic Frontier Foundation.
数字版权组织电子前哨基金会的技术政策总监Jeremy Gillula称,虽然现在使用人脸照片来训练人工智能系统并不存在严格的法律界限,但即使这样,公司与研究小组仍需要跨越伦理的界限。
In his view, that means getting explicit consent from people whose faces are in those images. Sometimes that will be hard, he said, but that's a reality companies should have to face.
在他看来,这就代表着,公司必须得到相关用户的明确许可,才能使用有其面部信息的照片。他说,有时这样的许可是很难获得的,但公司必须面对这一现实。
来源 | CNN
编译 | 张萌 梁沅 刘与晨
指导教师 | 刘佳
排版 | 刘与晨
