

Understanding how algorithm manipulators exploit our cognitive vulnerabilities empowers us to fight back
明白算法操纵者如何利用人们的认知弱点,我们才有反击之力
拿Andy来说吧,他看不懂关于新冠的任何文章,只能从信任的朋友那儿获得建议。看到脸书上有人说对新冠的担忧言过其实时,Andy一开始不以为然。
但后来,他工作的酒店关门了,工作也摇摇欲坠,安迪开始怀疑新冠病毒的威胁到底有多严重。毕竟,在他认识的人里面,还没有人因此死去。
一次,一个同事发表了一篇文章,内容是关于大型制药公司和腐败政客勾结造成了新冠“恐慌”。这和Andy对政府的不信任不谋而合。他很快就搜索到了很多声称新冠并不比流感糟到哪去的文章。
Andy加入了一个由害怕下岗的人们组成的群聊,群里的人都在问:“哪有啥疫情啊?” 然后他决定加入一个要求结束隔离的抗议会。几乎所有参加这次大规模抗议的人都没有戴口罩。当姐姐问起时,他说出了自己现在深信不疑的想法:“新冠就是一场骗局。”
/////This example illustrates a minefield of cognitive biases. We prefer information from people we trust, our in-group. We pay attention to and are more likely to share information about risks—for Andy, the risk of losing his job. We search for and remember things that fit well with what we already know and understand. These biases are products of our evolutionary past, and for tens of thousands of years, they served us well. People who behaved in accordance with them—for example, by staying away from the overgrown pond bank where someone said there was a viper—were more likely to survive than those who did not.//////
/////这个例子表明了认知偏见的一个雷区。人们往往更喜欢那些从自己相信的人或者小圈子那儿获取到的信息。我们关注并更可能分享与个人利益风险相关的信息——对于Andy来说,那就是丢掉工作。我们寻找并且记住了和我们已知并理解的信息相匹配的信息。“适者生存”——这一进化原则陪伴了我们千千万万年。相对于没有保持一致的人来说,那些表现与它们一致的人们更可能存活下来。打个比方来说,远离那些人们说的有毒蛇的杂草湖岸,就比那些不听劝的人更有可能活下来。/////
/////Modern technologies are amplifying these biases in harmful ways, however. Search engines direct Andy to sites that inflame his suspicions, and social media connects him with like-minded people, feeding his fears. Making matters worse, bots—automated social media accounts that impersonate humans—enable misguided or malevolent actors to take advantage of his vulnerabilities./////
/////然而,现代科技正在以一种有害的方式扩大这些偏见。搜索引擎引导着Andy去搜索那些能点燃他的怀疑的网站,社交媒体把他和有着同样想法的人联系起来,助长了他的恐惧。更过分的是,能模拟人的自动化社交媒体账户使得误入歧途或心怀不轨的参与者能够利用他的弱点。/////
/////Compounding the problem is the proliferation of online information. Viewing and producing blogs, videos, tweets and other units of information called memes has become so cheap and easy that the information marketplace is inundated. Unable to process all this material, we let our cognitive biases decide what we should pay attention to. These mental shortcuts influence which information we search for, comprehend, remember and repeat to a harmful extent./////
/////网上信息的扩散加重了这个问题。观看和生产博客、视频、推特和其他叫做表情包的信息单元已经过于廉价易得,淹没了信息市场。我们无法处理所有的信息,只好让认知偏见来决定我们应该关注什么。那些心理捷径以一种有害的方式影响了我们搜索、理解、记住、重复哪些信息。/////
/////The need to understand these cognitive vulnerabilities and how algorithms use or manipulate them has become urgent. At the University of Warwick in England and at Indiana University Bloomington's Observatory on Social Media (OSoMe, pronounced “awesome”), our teams are using cognitive experiments, simulations, data mining and artificial intelligence to comprehend the cognitive vulnerabilities of social media users./////
/////我们急需了解这些认知弱点以及算法如何使用和操纵它们。在英国华威大学和印第安纳大学布卢明顿社交媒体观测站天文台(OSoMe,读作“awesome”),我们的团队正在使用认知实验、仿真模拟、数据挖掘技术以及人工智能来理解社交媒体用户的认知弱点。/////
/////Insights from psychological studies on the evolution of information conducted at Warwick inform the computer models developed at Indiana, and vice versa. We are also developing analytical and machine-learning aids to fight social media manipulation. Some of these tools are already being used by journalists, civil-society organizations and individuals to detect inauthentic actors, map the spread of false narratives and foster news literacy./////
/////信息进化的心理学研究在华威大学展开,与之相关的深刻见解报告了在印第安纳开发的电脑模型,且反之亦然。同时,我们正在开发分析和机器学习的助手来对抗社交媒体操纵。新闻记者、民间团体和一些个人已经在使用一些工具了。他们想要探测出不真实的参与者,标记出虚假叙事的传播,并培养新闻素养。/////
INFORMATION OVERLOAD
信息超载
The glut of information has generated intense competition for people's attention. As Nobel Prize–winning economist and psychologist Herbert A. Simon noted, “What information consumes is rather obvious: it consumes the attention of its recipients.” One of the first consequences of the so-called attention economy is the loss of high-quality information. The OSoMe team demonstrated this result with a set of simple simulations. It represented users of social media such as Andy, called agents, as nodes in a network of online acquaintances. At each time step in the simulation, an agent may either create a meme or reshare one that he or she sees in a news feed. To mimic limited attention, agents are allowed to view only a certain number of items near the top of their news feeds.
信息过剩引起了人们对注意力的激烈竞争。正如诺贝尔经济学奖得主、心理学家Herbert A. Simon所指出的:“信息消费了什么显而易见,它消费了接受者的注意力。所谓的注意力经济造成的主要后果之一是高质量信息的丢失。OSoMe团队简单的模拟演示了这一结果。它将Andy等称作agent的社交媒体用户作为冲浪能手中的节点。在模拟的每一个步骤中,agent可以创建一个模因(互联网文化基因),或者转发agent在新闻源中看到的一个模因。为了模拟有限关注,agent只能查看其新闻订阅源列表顶端有限数量的模因。
TIPS:
Agent: 这一概念由Minsky在其1986年出版的《思维的社会》一书中提出。Minsky认为社会中的某些个体经过协商之后可求得问题的解,这些个体就是Agent。
Agent技术在上世纪90年代成为热门话题,甚至被一些文献称为软件领域下一个意义深远的突破,其重要原因之一在于,该技术在基于网络的分布计算这一当今计算机主流技术领域中,正发挥着越来越重要的作用。
一方面,Agent技术为解决新的分布应用问题提供了有效途径;另一方面,Agent技术为全面准确地研究分布计算系统的特点提供了合理的概念模型。
参考释义链接:
https://blog.csdn.net/VucNdnrzk8iwX/article/details/79434572
Running this simulation over many time steps, Lilian Weng of OSoMe found that as agents' attention became increasingly limited, the propagation of memes came to reflect the power-law distribution of actual social media: the probability that a meme would be shared a given number of times was roughly an inverse power of that number. For example, the likelihood of a meme being shared three times was approximately nine times less than that of its being shared once.
运行这个模拟程序需要许多步骤,OSoMe公司的 Lilian Weng发现代理商的关注变得越来越有限,而模因的传播反映出了现实社交媒体的幂律分布: 一个模因被分享一定次数的概率大致是这个数字的倒数幂。例如,一个模因被分享三次的可能性大约是被分享一次的九倍。
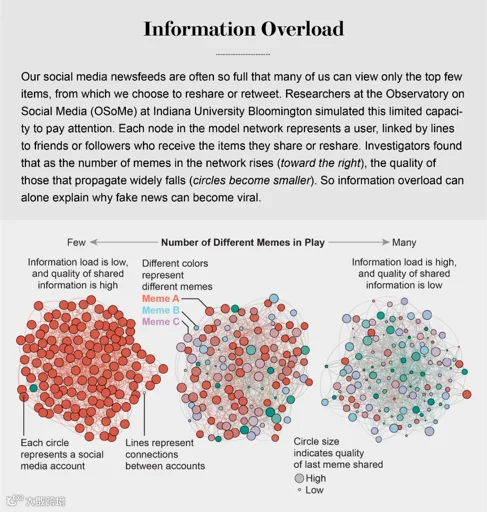
Credit: “Limited individual attention and online virality of low-quality information,” By Xiaoyan Qiu et al., in Nature Human Behaviour, Vol. 1, June 2017
图解 “有限的注意力和低质量信息的泛滥”,出自邱晓燕等人在2017年6月出版的《自然人类行为》第1卷
This winner-take-all popularity pattern of memes, in which most are barely noticed while a few spread widely, could not be explained by some of them being more catchy or somehow more valuable: the memes in this simulated world had no intrinsic quality. Virality resulted purely from the statistical consequences of information proliferation in a social network of agents with limited attention. Even when agents preferentially shared memes of higher quality, researcher Xiaoyan Qiu, then at OSoMe, observed little improvement in the overall quality of those shared the most. Our models revealed that even when we want to see and share high-quality information, our inability to view everything in our news feeds inevitably leads us to share things that are partly or completely untrue.
这种“赢者通吃”的流行模式使得其中大多数的信息很少被注意到,只有少数广为流传,且广为流传的也并不是一些通俗易懂或在某种意义上更有价值的信息:在这个模拟实验里,模因没有内在的质量。病毒性泛滥纯粹是由于有限的注意力分散在社会网络中代理们传递的信息而造成的。研究人员邱晓燕在OSoMe发现,即使agents更愿分享高质量的模因,热搜的整体质量几乎没有改善。模拟实验显示,即使我们想要看到并分享高质量信息,因为我们无法看到推送中的所有内容,这不可避免地会导致我们会分享部分或完全不真实的信息。
Cognitive biases greatly worsen the problem. In a set of groundbreaking studies in 1932, psychologist Frederic Bartlett told volunteers a Native American legend about a young man who hears war cries and, pursuing them, enters a dreamlike battle that eventually leads to his real death. Bartlett asked the volunteers, who were non-Native, to recall the rather confusing story at increasing intervals, from minutes to years later. He found that as time passed, the rememberers tended to distort the tale's culturally unfamiliar parts such that they were either lost to memory or transformed into more familiar things. We now know that our minds do this all the time: they adjust our understanding of new information so that it fits in with what we already know. One consequence of this so-called confirmation bias is that people often seek out, recall and understand information that best confirms what they already believe.
认知的偏差极大地恶化了这一问题。在1932年一系列开创性的研究中,心理学家Frederic Bartlett向志愿者们讲述了一个印第安人的传说:一个年轻人听到战争的呼声,就追随呼喊,加入了一场荒唐的战斗,最终战死沙场。Bartlett要求这些外地志愿者在几年内,以越来越长的间隔回忆这个令人困惑的故事。他发现,随着时间的推移,人们倾向于歪曲故事中不熟悉的部分,导致这些部分要么消失在记忆中,要么变成其熟悉的桥段。如今我们知道我们的大脑一直在做这件事,它调整我们对新信息的理解,使之与我们已知的事物相适应。这种记忆偏差确认偏差导致人们经常寻找、回忆并重复证实他们先前相信的信息。
This tendency is extremely difficult to correct. Experiments consistently show that even when people encounter balanced information containing views from differing perspectives, they tend to find supporting evidence for what they already believe. And when people with divergent beliefs about emotionally charged issues such as climate change are shown the same information on these topics, they become even more committed to their original positions.
这种倾向极难改变。实验表明,即使人们遇到包含不同观点的信息,他们也倾向于将其更改为支持他们已经相信的证据。而面对气候变化等敏感问题时,相同的信息却能让就此问题持有不同观点的人都更加坚定自己原来的立场。
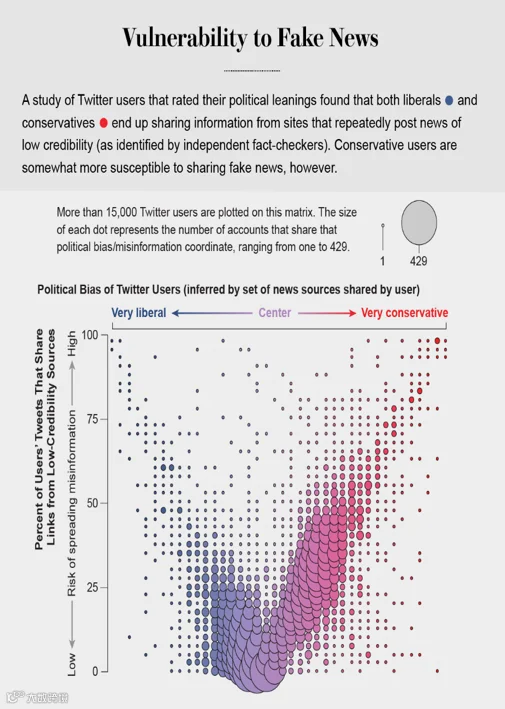
Making matters worse, search engines and social media platforms provide personalized recommendations based on the vast amounts of data they have about users' past preferences. They prioritize information in our feeds that we are most likely to agree with—no matter how fringe—and shield us from information that might change our minds. This makes us easy targets for polarization. Nir Grinberg and his co-workers at Northeastern University recently showed that conservatives in the U.S. are more receptive to misinformation. But our own analysis of consumption of low-quality information on Twitter shows that the vulnerability applies to both sides of the political spectrum, and no one can fully avoid it. Even our ability to detect online manipulation is affected by our political bias, though not symmetrically: Republican users are more likely to mistake bots promoting conservative ideas for humans, whereas Democrats are more likely to mistake conservative human users for bots.
更荒唐的是,搜索引擎和社交媒体平台会根据用户的大数据测算其喜好并为其提供个性化推送。它们会优先考虑我们最有可能想看的信息,即使是极端边缘的信息,并保护我们不受那些可能改变我们想法的信息影响。这使得我们很容易走向极端。东北大学的尼尔·格林伯格和他的同事们近来发现,美国保守派更容易接受错误信息。但我们自己对Twitter上低质量信息消费的分析显示,这种脆弱性在政党双方身上都有体现,没有人能够完全避免它。甚至我们辨别人机的能力也会受到我们的政治偏见的影响,尽管并不对称:共和党用户更有可能把宣扬保守思想的机器人误认为人类,而民主党用户更有可能把保守的人类误认为机器人。
SOCIAL HERDING
社群效应
2019年8月的纽约街头,有人听到疑似枪声,人们开始逃离。一些人随之也开始跑,还有人喊道:“有人开枪!”后来他们才发现,爆炸声音来自一辆返火的摩托车。在这种情况下,先跑后问可能会有好处。在没有清楚的信号的情况下,我们的大脑利用人群的信息来推算适当的行为,类似于鱼群和鸟群的行为。
/////Such social conformity is pervasive. In a fascinating 2006 study involving 14,000 Web-based volunteers, Matthew Salganik, then at Columbia University, and his colleagues found that when people can see what music others are downloading, they end up downloading similar songs. Moreover, when people were isolated into “social” groups, in which they could see the preferences of others in their circle but had no information about outsiders, the choices of individual groups rapidly diverged. But the preferences of “nonsocial” groups, where no one knew about others' choices, stayed relatively stable. In other words, social groups create a pressure toward conformity so powerful that it can overcome individual preferences, and by amplifying random early differences, it can cause segregated groups to diverge to extremes./////
/////这种社会一致性是普遍存在的。2006年,哥伦比亚大学的Matthew Salganik和他的同事们在2006年进行了一项研究,然后发现,当人们看到别人正在下载的音乐时,他们也会下载类似的歌曲。此外,当人们被包裹在某个社交群体中而与外界隔离时,他们可以看到自己圈子里其他人的偏好,但却没有关于圈子外面人的信息,个体群体的选择迅速发生改变。但“非社交”群体的偏好相对稳定,在这些群体中,没有人知道别人的选择。换句话来说,社交群体产生了一种强大的从众压力,它可以压服个人喜好,它可能会导致与外界隔离群体走向分歧到极端。/////
/////Social media follows a similar dynamic. We confuse popularity with quality and end up copying the behavior we observe. Experiments on Twitter by Bjarke Mønsted and his colleagues at the Technical University of Denmark and the University of Southern California indicate that information is transmitted via “complex contagion”: when we are repeatedly exposed to an idea, typically from many sources, we are more likely to adopt and reshare it. This social bias is further amplified by what psychologists call the “mere exposure” effect: when people are repeatedly exposed to the same stimuli, such as certain faces, they grow to like those stimuli more than those they have encountered less often./////
/////社交媒体遵循类似的动态。我们有时候会混淆人气高和质量好的区别,最终照搬了我们观察到的行为。丹麦技术大学和南加州大学的Bjarke Mønsted及同事在推特上的实验表明,信息是通过"复杂传染"传播的:当我们反复接触到一个想法,通常来自许多来源,我们更会容易接受它然后传播同样的想法。心理学家所说的"曝光效应"进一步放大了这种社会偏见:当人们反复暴露在相同的刺激下,例如某些面孔时,他们会变得更喜欢那些激励因素,而不是他们不常遇到的激励因素。/////
译注:
曝光效应(the exposure effect or the mere exposure effect):又谓多看效应、(简单、单纯)暴露效应、(纯粹)接触效应等等,它是一种心理现象,指的是我们会偏好自己熟悉的事物,社会心理学又把这种效应叫做熟悉定律,我们把这种只要经常出现就能增加喜欢程度的现象叫做曝光效应。
/////Such biases translate into an irresistible urge to pay attention to information that is going viral—if everybody else is talking about it, it must be important. In addition to showing us items that conform with our views, social media platforms such as Facebook, Twitter, YouTube and Instagram place popular content at the top of our screens and show us how many people have liked and shared something. Few of us realize that these cues do not provide independent assessments of quality./////
/////这种偏见转化为一种不可抗拒的冲动,即关注那些热点信息。如果其他人都在谈论它,那么它一定很重要。除了向我们展示符合我们观点的东西外,脸书、推特、油管和Ins等社交媒体平台还将热门内容放在屏幕顶部,向我们展示有多少人喜欢和分享了一些东西。很少有人意识到这些线索不能提供独立的质量评估。/////
事实上,设计社交媒体上模因排名算法的程序员认为,“群体智慧”会很快识别出高质量的项目,他们用人气作为质量的代名词。我们对大量关于点击的匿名数据的分析证明,所有平台的社交媒体、搜索引擎和新闻网站都优先从一小部分热门来源提供信息。
/////To understand why, we modeled how they combine signals for quality and popularity in their rankings. In this model, agents with limited attention—those who see only a given number of items at the top of their news feeds—are also more likely to click on memes ranked higher by the platform. Each item has intrinsic quality, as well as a level of popularity determined by how many times it has been clicked on. Another variable tracks the extent to which the ranking relies on popularity rather than quality. Simulations of this model reveal that such algorithmic bias typically suppresses the quality of memes even in the absence of human bias. Even when we want to share the best information, the algorithms end up misleading us./////
/////为了理解人们这样表现的原因,我们做了一个模型来研究他们在排名中如何结合质量和受欢迎程度的信号。在这个模型中,注意力有限的agents——那些在新闻顶部看到一定数量的条目的人也更有可能点击社交平台排名靠前的梗。每项条目都有内在的质量,其受欢迎程度取决于它的点击量。另一个变量跟踪排名依赖于受欢迎程度而非质量的程度。对该模型的模拟显示,这种偏差通常会控制梗的质量,即使在没有人为偏见的情况下也是如此。即使我们想分享最好的信息,机器最终也会误导我们。/////
ECHO CHAMBERS
“回音室”效应
/////Most of us do not believe we follow the herd. But our confirmation bias leads us to follow others who are like us, a dynamic that is sometimes referred to as homophily—a tendency for like-minded people to connect with one another. Social media amplifies homophily by allowing users to alter their social network structures through following, unfriending, and so on. The result is that people become segregated into large, dense and increasingly misinformed communities commonly described as echo chambers./////
/////我们大多数人都不相信自己随大流。但我们的固有偏见会使我们自然地向相似的人群靠拢,这种现象有时被称为“同质相吸”——一种志同道合的人互相聚拢的趋势。社交媒体允许用户通过添加、删除好友等方式改变他们的社交网络结构,从而放大了同质性。其结果是,不同的人群被隔在了一个个不同的、错误信息密集的小圈子中,这种圈子也被称作回音室。/////
/////At OSoMe, we explored the emergence of online echo chambers through another simulation, EchoDemo. In this model, each agent has a political opinion represented by a number ranging from −1 (say, liberal) to +1 (conservative). These inclinations are reflected in agents' posts. Agents are also influenced by the opinions they see in their news feeds, and they can unfollow users with dissimilar opinions. Starting with random initial networks and opinions, we found that the combination of social influence and unfollowing greatly accelerates the formation of polarized and segregated communities./////
/////OSoMe通过一个模拟试验EchoDemo探索了网络回音室是如何出现的。在这个模型中,每一个agent 的政治倾向都由一个特定参数代表,参数范围从-1(倾向自由)到+1(倾向保守)。这些倾向同样反映在该agent在模型内假定的社会地位中。他们也会受到在订阅新闻中看到的观点的影响,可以取消关注持与自己观点相异的用户。从随机的初始网络和观点出发,我们发现社会影响和“关注、取关机制”的结合大大加速了意见的两极分化和隔离圈层的形成。/////
/////Social media can also increase our negativity. In a recent laboratory study, Robert Jagiello, also at Warwick, found that socially shared information not only bolsters our biases but also becomes more resilient to correction. He investigated how information is passed from person to person in a so-called social diffusion chain. In the experiment, the first person in the chain read a set of articles about either nuclear power or food additives. The articles were designed to be balanced, containing as much positive information (for example, about less carbon pollution or longer-lasting food) as negative information (such as risk of meltdown or possible harm to health)./////
/////社交媒体也会增加我们的消极情绪。在最近的一项实验室研究中,同样来自华威大学的Robert Jagiello发现,社会共享的信息不仅会助长我们的偏见,而且会让纠错更难。他研究了在所谓的社会扩散链中,信息是如何在人与人之间传递的。在实验中,链中的第一个人读了一系列关于核能或食品添加剂的文章。这些文章被设计成平衡的,包含同样多的正面信息(例如,关于较少的碳污染或更长保质期的食物)和负面信息(例如熔毁的风险或对健康的潜在危害)。/////
/////The first person in the social diffusion chain told the next person about the articles, the second told the third, and so on. We observed an overall increase in the amount of negative information as it passed along the chain—known as the social amplification of risk. Moreover, work by Danielle J. Navarro and her colleagues at the University of New South Wales in Australia found that information in social diffusion chains is most susceptible to distortion by individuals with the most extreme biases./////
/////扩散链中的第一个人把文章告诉下一个人,第二个告诉第三个,以此类推。我们观察到负面信息在传递的过程中整体增加,这一现象被称为“社会的风险放大性”。此外,澳大利亚新南威尔士大学的Danielle J. Navarro和她的同事发现,社会扩散链中的信息最容易被带有极端扭曲的个人偏见。/////
/////Even worse, social diffusion also makes negative information more “sticky.” When Jagiello subsequently exposed people in the social diffusion chains to the original, balanced information—that is, the news that the first person in the chain had seen—the balanced information did little to reduce individuals' negative attitudes. The information that had passed through people not only had become more negative but also was more resistant to updating./////
/////更糟糕的是,社会传播也会让负面信息变得更“粘滞”。随后,当Jagiello给处于社会扩散链中的人们提供原始的、平衡的信息时——即链中第一个人看到的消息,她发现平衡的信息对减少个体的负面态度几乎没有作用。经过人群传播的信息不仅变得更加消极,而且更不愿意更新。/////
2015年,OSoMe研究人员 Emilio Ferrara和杨泽尧(音译)分析了关于推特上这种“情绪传染”的实证数据,发现过度接触负面内容的人倾向于分享负面消息,而过度接触积极内容的人倾向于分享更多积极消息。因为负面内容传播的速度比正面内容快,所以很容易通过创造引发恐惧和焦虑等负面反应的叙述来操纵人们的情绪。Ferrara现在在南加州大学工作,他和意大利布鲁诺凯斯勒基金会的同事发现,在2017年西班牙就加泰罗尼亚独立问题举行公投期间,社交机器人被用来转发暴力和煽动性的言论,增加了它们的曝光率,加剧了社会冲突。
RISE OF THE BOTS
算法机器人的崛起
/////Information quality is further impaired by social bots, which can exploit all our cognitive loopholes. Bots are easy to create. Social media platforms provide so-called application programming interfaces that make it fairly trivial for a single actor to set up and control thousands of bots. But amplifying a message, even with just a few early upvotes by bots on social media platforms such as Reddit, can have a huge impact on the subsequent popularity of a post./////
/////信息的质量会进一步地被社交网络里的机器人损害,这些机器人能最大程度地利用我们所有的认知漏洞。创建一个机器人程序本身很容易,而社交网络平台又提供了一个所谓的程序编程平台从而使得让一个人能轻易设置并控制成千上万个机器人。但是任何放大信息的行为,即使只是在像Reddit这样的社交网站上用机器人点几个赞,都会对随后邮件的热度产生巨大影响。/////
在OSoMe里,我们开发了机器学习算法来探测社交网络里的自动程序。其中之一的Botometer是一个公共工具,它能从一个指定的推特用户那里摘录1200个特点从而推算出其的概况、好友、社交网络结构、时间活动模式、语言等特征。接着该程序会将这些特征与之前已经找到的机器人的特点进行比较,从而给出一个其是机器人的可能性的分数。
/////In 2017 we estimated that up to 15 percent of active Twitter accounts were bots—and that they had played a key role in the spread of misinformation during the 2016 U.S. election period. Within seconds of a fake news article being posted—such as one claiming the Clinton campaign was involved in occult rituals—it would be tweeted by many bots, and humans, beguiled by the apparent popularity of the content, would retweet it./////
/////在2017年我们测出了高达百分之十五的活跃推特用户是自动程序,并且在2016的美国大选期间的假消息传播中扮演了重要的角色。在一篇假新闻(比如一篇声称克林顿竞选团队参与了神秘仪式的文章)被发布后的几秒钟内,其就会被许多机器人转推,而受这一消息的热度欺骗的人类也会随之转发。/////
/////Bots also influence us by pretending to represent people from our in-group. A bot only has to follow, like and retweet someone in an online community to quickly infiltrate it. OSoMe researcher Xiaodan Lou developed another model in which some of the agents are bots that infiltrate a social network and share deceptively engaging low-quality content—think of clickbait. One parameter in the model describes the probability that an authentic agent will follow bots—which, for the purposes of this model, we define as agents that generate memes of zero quality and retweet only one another. Our simulations show that these bots can effectively suppress the entire ecosystem's information quality by infiltrating only a small fraction of the network. Bots can also accelerate the formation of echo chambers by suggesting other inauthentic accounts to be followed, a technique known as creating “follow trains.”/////
/////与此同时,机器人也在通过假装代表我们小圈子里的人来影响我们。它只需要在一个网络社区里关注,点赞和转发一些人,就能快速渗透进去。OSoMe的研究人员晓丹(音译)针对此开发了另一个模型,而在这之中一些agents是机器人,它们会渗透进一个社交网络并分享带有欺骗性的低质量内容。模型中的一个参数描绘了一名真正的agent人关注一个机器人的可能性,为了模型需要我们将这定义为产生零质量模因并且只会互相转发的agents。我们的模拟表明这些机器人能通过渗透网络的一小部分来有效地压制整个网络生态圈的信息。机器人也能通过建议人们关注一些虚假内容账户,从而加速回音室的形成。/////
TIPS:
Followtrain: a chain (mainly used on instagram) strated by one person. You repost the picture so people get to like the picture and you and the people who reposted the picture or didint need to follow everyone who like the picture. If anyone that your followed that liked the picture does not follow back within 24 hours, you unfollow them. Followtrains help you gain a whole bunch of followers without apps or pay.
参考链接:
https://www.urbandictionary.com/define.php?term=Followtrain
/////Some manipulators play both sides of a divide through separate fake news sites and bots, driving political polarization or monetization by ads. At OSoMe, we recently uncovered a network of inauthentic accounts on Twitter that were all coordinated by the same entity. Some pretended to be pro-Trump supporters of the Make America Great Again campaign, whereas others posed as Trump “resisters”; all asked for political donations. Such operations amplify content that preys on confirmation biases and accelerate the formation of polarized echo chambers./////
/////一些操纵者会通过一边分离独立的假新闻网站和机器人,一边通过广告推动政治上的两极分化或货币化,来两头操纵、从中获利。在OSoMe里,我们近期在推特上发现了一组由同一团体掌控的虚假账户网络。其中一些人假装是支持“让美国再次伟大”运动的特朗普支持者,而其他人则冒充特朗普的“反对者”。相同的是所有人都要求政治捐款。这样的操作会放大那些利用人们的确认偏差的内容,并加速两极分化的回音室的形成。/////
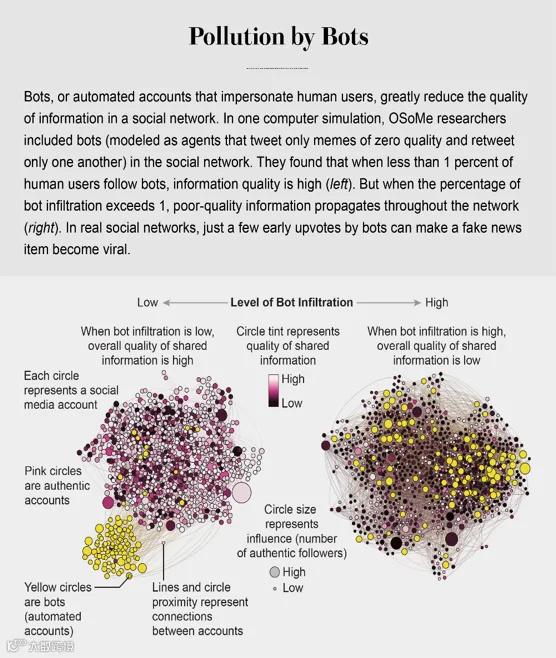
(该图展示了机器人程序是如何传播假消息并破坏互联网生态的)
CURBING ONLINE MANIPULATION
遏制网络操纵
/////Understanding our cognitive biases and how algorithms and bots exploit them allows us to better guard against manipulation. OSoMe has produced a number of tools to help people understand their own vulnerabilities, as well as the weaknesses of social media platforms. One is a mobile app called Fakey that helps users learn how to spotmisinformation. The game simulates a social media news feed, showing actual articles from low- and high-credibility sources. Users must decide what they can or should not share and what to fact-check. Analysis of data from Fakey confirms the prevalence of online social herding: users are more likely to share low-credibility articles when they believe that many other people have shared them./////
/////了解我们的认知偏差,以及算法和机器人如何利用这些偏差,这样我们便可以更好地防范它们的“操控”。OSoMe已经开发了许多工具来帮助人们了解自己的认知偏差,以及社交媒体平台的弱点。一个是名为Fakey的移动应用程序,它帮助用户学习如何发现错误信息。这个软件模拟了一个社交媒体新闻源,显示了低可信度和高可信度来源的真实文章。用户必须决定哪些内容可以共享,哪些内容不应该共享,哪些内容需要进行事实核查。对Fakey数据分析后证实了网络社交聚集的普遍性:当用户认为有很多人分享了低可信度的文章时,他们更愿意分享这些文章。/////
/////Another program available to the public, called Hoaxy, shows how any extant meme spreads through Twitter. In this visualization, nodes represent actual Twitter accounts, and links depict how retweets, quotes, mentions and replies propagate the meme from account to account. Each node has a color representing its score from Botometer, which allows users to see the scale at which bots amplify misinformation. These tools have been used by investigative journalists to uncover the roots of misinformation campaigns, such as one pushing the “pizzagate” conspiracy in the U.S. They also helped to detect bot-driven voter-suppression efforts during the 2018 U.S. midterm election. Manipulation is getting harder to spot, however, as machine-learning algorithms become better at emulating human behavior./////
/////另一个面向公众的程序叫做Hoaxy,展示了现存所有的梗是如何通过推特传播的。在这个可视化中,节点表示实际的推特帐户,而链接描述了转发、引用、提及和回复如何在帐户之间传播这些"梗"。每一个节点都有一个颜色代表它在Botometer中的得分,用户可以看到机器人放大错误信息的程度。这些工具被调研记者用来揭露错误信息运动的根源,例如在美国推动“披萨门”阴谋。它们还帮助发现了2018年美国中期选举期间机器人驱动的选民压制活动。然而,随着机器学习算法在模拟人类行为方面变得更好,操纵也变得越来越难发现。/////
TIPS:
披萨门:2004年的10月24日,英超第10轮曼联VS阿森纳的比赛完场之后,在老特拉福德球场球员通道,双方球员以及教练组成员发生言语与肢体冲突,混乱中突然一块披萨从天而降砸中曼联主帅弗格森。
/////Apart from spreading fake news, misinformation campaigns can also divert attention from other, more serious problems. To combat such manipulation, we have recently developed a software tool called BotSlayer. It extracts hashtags, links, accounts and other features that co-occur in tweets about topics a user wishes to study. For each entity, BotSlayer tracks the tweets, the accounts posting them and their bot scores to flag entities that are trending and probably being amplified by bots or coordinated accounts. The goal is to enable reporters, civil-society organizations and political candidates to spot and track inauthentic influence campaigns in real time./////
/////除了传播假新闻,误导活动也会转移人们对其他更严重问题的注意力。为了打击这种操纵,我们最近开发了一个叫做BotSlayer的软件app。它提取了标签、链接、帐户和其他在推文中共同出现的关于用户希望研究的主题的特性。对于每个实体,BotSlayer会跟踪推文、发布推特的帐户以及它们的"机器人指数",以标记那些正在流行并可能被机器人或协同帐户放大的实体。其目标是使记者、民间社会组织和政治候选人能够实时发现和跟踪不真实的影响活动。/////
/////These programmatic tools are important aids, but institutional changes are also necessary to curb the proliferation of fake news. Education can help, although it is unlikely to encompass all the topics on which people are misled. Some governments and social media platforms are also trying to clamp down on online manipulation and fake news. But who decides what is fake or manipulative and what is not? Information can come with warning labels such as the ones Facebook and Twitter have started providing, but can the people who apply those labels be trusted? The risk that such measures could deliberately or inadvertently suppress free speech, which is vital for robust democracies, is real. The dominance of social media platforms with global reach and close ties with governments further complicates the possibilities./////
/////这些纲领性工具是重要的辅助手段,但要遏制假新闻泛滥,也必须进行制度变革。教育是有帮助的,尽管它不可能涵盖所有误导人们的话题。一些政府和社交媒体平台也在努力打击网络操纵和假新闻。但谁来决定什么是假的或是操纵的,什么不是?信息可以带有警告标签,比如脸书和推特已经开始提供的警告标签,但是使用这些标签的人是否值得信任?这种措施有可能有意或无意地压制言论自由,而言论自由对强大的民主国家至关重要,这种风险是真实存在的。社交媒体平台在全球范围内的主导地位,以及与各国政府的密切联系,使这种可能性进一步复杂化。/////
/////One of the best ideas may be to make it more difficult to create and share low-quality information. This could involve adding friction by forcing people to pay to share or receive information. Payment could be in the form of time, mental work such as puzzles, or microscopic fees for subscriptions or usage. Automated posting should be treated like advertising. Some platforms are already using friction in the form of CAPTCHAs and phone confirmation to access accounts. Twitter has placed limits on automated posting. These efforts could be expanded to gradually shift online sharing incentives toward information that is valuable to consumers./////
/////最好的办法之一可能是增加创建共享低质量信息的难度。这可能包括迫使人们付费分享或接收信息,从而增加传播阻力。支付的形式可以是时间,脑力劳动,如拼图,或微观费用订阅或使用。网络自动发布应该被当作广告一样对待。一些平台已经在利用验证码和电话确认的形式来访问账户。Twitter对自动发布设置了限制。这些努力可以扩大,逐步将网上分享的动机转向对消费者有价值的信息。/////
自由交流不是绝对自由的。通过降低信息的成本,我们降低了信息的价值,并使其掺假。为了恢复我们信息生态系统的健康,我们必须了解我们不堪重负的思想的脆弱性,以及如何利用信息的经济性来保护我们不被误导。