
全文2197字
预计阅读时间 5分钟

01
PaLM 2,Google为GPT准备的新对手
谷歌发布了其最新的AI语言模型PaLM 2:作为GPT-4 等类似模型的竞争对手。
“受益于广泛的逻辑和推理训练,PaLM 2 模型具有更强大的逻辑和推理能力”谷歌 CEO Sundar Pichai 在公司的 I/O 大会上表示。“它还接受了来自 100 多种语言的多语种文本训练。”
注:Google每年一次的开发者大会,公司会在I/O上介绍技术进展并进行未来展望
“PaLM 2 models are stronger in logic and reasoning, thanks to broad training in logic and reasoning,” said Google CEO Sundar Pichai onstage at the company’s I/O conference. “It’s also trained on multilingual text spanning over 100 languages.”
在 PaLM 2发布之前,谷歌高级研究总监 Slav Petrov告诉记者,PaLM 2 在文本任务方面表现得更好,包括推理、写代码和翻译。“与 2022 年 4 月发布的 PaLM 1 相比,它有了显著的提升。”
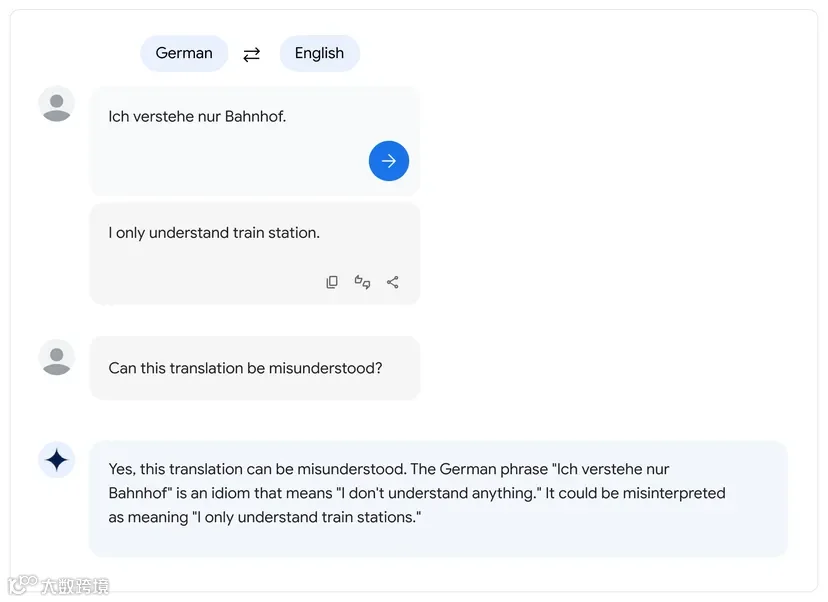
Petrov 举了一个德语短语的例子来介绍 PaLM 2 如何理解不同语言中的成语:“Ich verstehe nur Bahnhof”,字面意思是“我只了解火车站”,但实际上这句话的意思是“我不明白你在说什么”,或者用英语成语来说,“这对我来说就像希腊语。”
As an example of its multilingual capabilities, Petrov showed how PaLM 2 is able to understand idioms in different languages, giving the example of the German phrase “Ich verstehe nur Bahnhof,” which literally translates to “I only understand train station” but is better understood as “I don’t understand what you’re saying” or, as an English idiom, “it’s all Greek to me.”
P1
演示示意如下图
在一篇阐释PaLM 2 能力的研究论文中,谷歌的工程师声称该系统的语言熟练程度“足以教授该语言”,并指出这在一定程度上要归功于其训练数据中非英语文本所占比例更高。
与其他大型语言模型一样,PaLM 2 的训练需要大量的时间和资源。它不是一个单一的产品,而是基于该模型的一系列不同产品,可以面向个人消费者或者企业进行部署。模型有四种大小,从小到大分别是:Gecko(壁虎)、Otter(水獭)、Bison(野牛)和 Unicorn(独角兽),同时,部署的模型可以针对特定领域的数据进行微调,以便满足企业客户的特殊需求。
Like other large language models, which take huge amounts of time and resources to create, PaLM 2 is less a single product than a family of products — with different versions that will be deployed in consumer and enterprise settings. The system is available in four sizes, named Gecko, Otter, Bison, and Unicorn, from smallest to largest, and has been fine-tuned on domain-specific data to perform certain tasks for enterprise customers.
为了方便你理解不同模型的区别,我们可以用汽车制造举个例子:他们就像共享同一种底盘的不同卡车,通过在底盘上加装不同的发动机或者保险杠,我们就得到了适应不同环境的卡车。据Petrov表示,有一个版本的 PaLM 基于健康数据进行训练(Med-PaLM 2),谷歌称其能以“专家”水平回答类似于美国医学执照考试的问题;还有一个版本基于网络安全数据进行训练(Sec-PaLM 2),可以“解释潜在恶意脚本的行为并帮助检测代码中的威胁”。这两种模型都将通过谷歌云提供,首先提供给谷歌选定的客户。
注:恶意脚本是指一切以制造危害或者损害系统功能为目的而从软件系统中增加、改变或删除的任何脚本。传统的恶意脚本包括:病毒,蠕虫,特洛伊木马,和攻击性脚本
Think of these adaptations like taking a basic truck chassis and adding a new engine or front bumper to accomplish certain tasks or work better in specific terrain. There’s a version of PaLM trained on health data (Med-PaLM 2), which Google says can answer questions similar to those found on the US Medical Licensing Examination to an “expert” level and another version trained on cybersecurity data (Sec-PaLM 2) that can “explain the behavior of potential malicious scripts and help detect threats in code,” said Petrov. Both of these models will be available via Google Cloud, initially to select customers.
在谷歌自己的业务范围内,PaLM 2 已被用于为 25 个功能和产品提供支持,包括公司的实验性聊天机器人 Bard。通过PaLM 2,Bard现在具有更强大的代码编写能力、更好的多语种适应性。它还被用于支持谷歌 Workspace 应用程序中的功能,如 Docs、Slides 和 Sheets(你可以理解为Words、PPT和Excel)。
02
可以在手机本地运行的AI模型
非常特殊的一点在于,谷歌称PaLM 2 最轻量版本 Gecko 足够小,可以在手机上运行,每秒处理 20 个Token——大约相当于 16 或 17 个单词。谷歌没有说明用于测试该模型的硬件,只是说它是在“最新手机”上运行。尽管如此,这种语言模型的微型化仍具有重要意义。这些系统在云中运行的成本很高,而在本地使用它们还有其他好处,比如提高隐私性。问题是,小版本的语言模型不可避免地比它们的大型版本功能更少。
Notably, Google says the lightest version of PaLM 2, Gecko, is small enough to run on mobile phones, processing 20 tokens per second — roughly equivalent to around 16 or 17 words. Google did not say what hardware was used to test this model, only that it was running “on the latest phones.” Nevertheless, the miniaturization of such language models is significant. Such systems are expensive to run in the cloud, and being able to use them locally would have other benefits, like improved privacy. The problem is that smaller versions of language models are inevitably less capable than their larger brethren.
P2
PaLM 2 演示推理能力

通过 PaLM 2,谷歌希望缩小与竞争对手(如 Microsoft)之间的“AI 差距”,后者一直在积极将 AI 语言工具推向其 Office 软件套件。Microsoft 现在提供总结文档、编写电子邮件、生成演示幻灯片等的 AI 功能。谷歌需要与该公司保持同步,否则可能被认为在 AI 研究方面过于缓慢。
03
AI 技术还存在哪些问题?
尽管 PaLM 2 对谷歌在 AI 语言模型方面的工作而言确实是一个进步,但它依然面临着一些技术问题和挑战。
例如,一些专家开始质疑语言模型初始训练数据的合法性。这些数据通常从互联网上抓取,很多时候包括受版权保护的文本和盗版电子书。创建这些模型的科技公司通常会拒绝回答关于他们获取训练数据来源的问题。谷歌在描述 PaLM 2 时也延续了这一做法,只指称该系统的训练语料库包括“多样化的来源:网络文档、书籍、代码、数学和对话数据”,但没有明确说明数据的来源。
For example, some experts are beginning to question the legality of training data used to create language models. This data is usually scraped from the internet and often includes copyright-protected text and pirated ebooks. Tech companies creating these models have generally responded by refusing to answer questions about where they source their training data from. Google has continued this tradition in its description of PaLM 2, noting only that the system’s training corpus is comprised of “a diverse set of sources: web documents, books, code, mathematics, and conversational data,” without offering further detail.
类似 PaLM 2 这样的语言模型输出中也存在一些固有问题,如“幻觉”(即这些系统生成虚假信息的倾向)。谷歌研究副总裁 Zoubin Ghahramani 在接受 The Verge 采访时表示,在这方面,PaLM 2 相对于早期模型有所改进,“我们正在投入大量精力改进事实和逻辑归因的度量标准”,但他指出,整个领域在应对 AI 生成的虚假信息方面“仍有很长的路要走”。
There are also problems inherent to the output of language models like “hallucinations,” or the tendency of these systems to simply make up information. Speaking to The Verge, Google VP of research Zoubin Ghahramani says that, in this regard, PaLM 2 was an improvement on earlier models “in the sense that we’re putting a huge amount of effort into continually improving metrics of groundedness and attribution” but noted that the field as a whole “still has a ways to go” in combating false information generated by AI.
原文链接:
https://www.theverge.com/2023/5/10/23718046/google-ai-palm-2-language-model-bard-io
编译 | 高语阳
排版 | 高语阳
👇点击关注,携手成长