
作者:尤浚哲
今天要开箱的是研华MIC-743-AT , 搭载最新 NVIDIA® Jetson Thor™ 模块,我们好奇:一台边缘 AI 系统,真的能在本地端「扛得起」百亿参数等级的模型吗?
在测试之前,先看看 MIC-743参数规格。
基于 NVIDIA® Jetson T5000™ 算力高达2070 TFLOPS (FP4)
支持 1 x QSFP28 (4 x 25GbE)
支持1 x 5GbE, 4 x USB 3.2 Gen 2, 1 x M.2 Ekey(WiFi), 1 x M.2 Bkey (LTE)
双天线孔位,对应无线通信需求
5G Base-T 网络端口与 QSFP28 高速模块插槽,展现数据中心等级的传输能力
出厂自带1T NVMe SSD,支持2个SATA硬盘扩展

我们这次实测的是 研华 MIC-743-AT,用的是NVIDIA Jetson Thor 模块: NVIDIA Jetson T5000打造的系统, 我们直接把 GPT-OSS 120B 丢上 MIC-743-AT-ES,一款搭载 NVIDIA Jetson Thor 模块的 AI 推理系统,实测它的真实表现。

实测模型效能:
GPT-OSS 20B vs GPT-OSS 120B
我分别加载两款 GPT-OSS 模型(20B 与 120B)用 Ollama 本地推理测试其效能:
【测试环境】
硬件平台:研华 MIC-743-AT
AI 模块:NVIDIA Jetson T5000
内存:128GB LPDDR5X
OS / SDK:Ubuntu + JetPack 7.0
测试工具:Ollama,本地推理
模型:GPT-OSS:20B 与 GPT-OSS:120B
【实测数据】
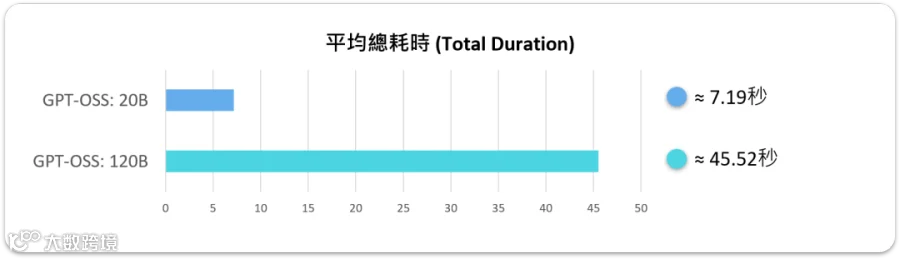
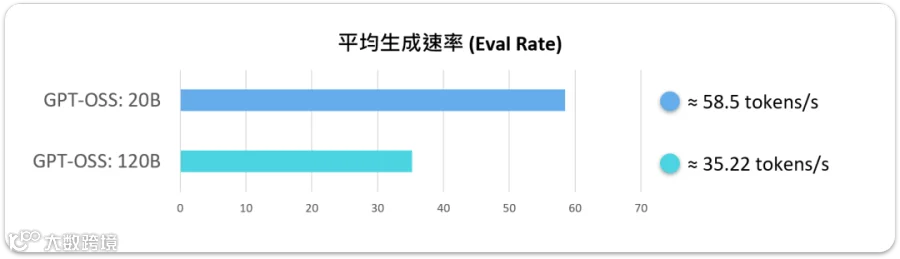
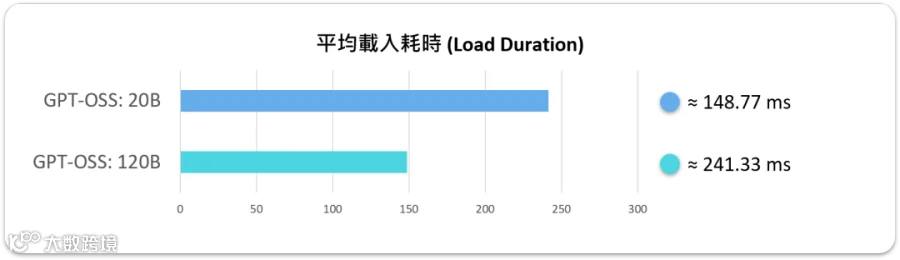
在实际测试 【GPT-OSS 20B 】的时候,整体体验可以说是相当顺畅。
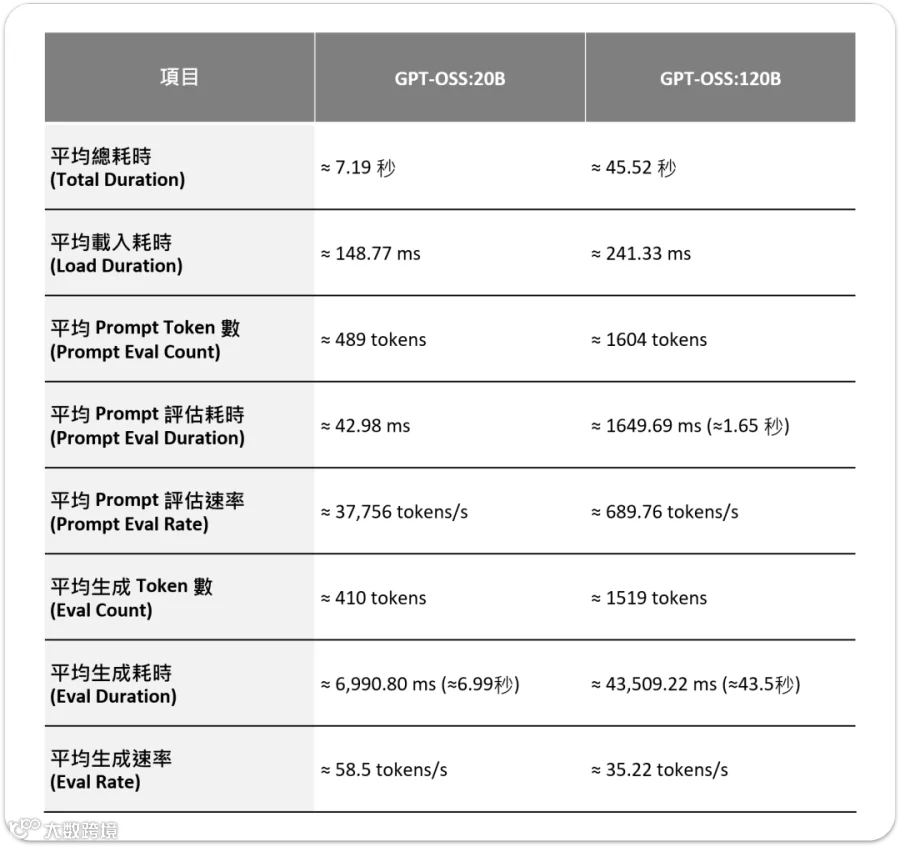
平均总耗时大概在 7 秒多,加载时间更是不到 150 毫秒,几乎可以忽略不计。Prompt 部分处理了将近 500 个 tokens,但评估只花了 0.04 秒,等于一秒能吞掉快四万个 token,效率惊人。生成阶段平均输出 410 个 tokens,大概 7 秒就跑完,换算下来生成速度稳定在 58.5 tokens/s,对于交互式应用来说,这已经是非常理想的表现。
相较之下,【GPT-OSS 120B】 的表现虽然慢了一些,但依旧让人印象深刻。平均总耗时来到 45 秒左右,其中加载时间大概 0.24 秒,虽然比 20B 稍长,不过放在百亿级别模型的规模里,这样的开局速度其实算很快了。Prompt 部分一次处理超过 1600 个 tokens,光是评估就花了 1.65 秒,效率自然没办法和 20B 相提并论。不过生成过程输出了 1500 多个 tokens,平均速度维持在 35 tokens/s,以 120B 的庞大参数量来看,能在边缘端跑出这个数字,真的非常惊人。
简单来说,20B 适合实时互动,速度快、延迟低;120B 则是给需要更高语言理解力和更深度推理的场景使用。两者的表现刚好形成了「速度 vs. 智能密度」的对比,取决于在不同应用中要优先考虑哪一个。
详细数据如下:
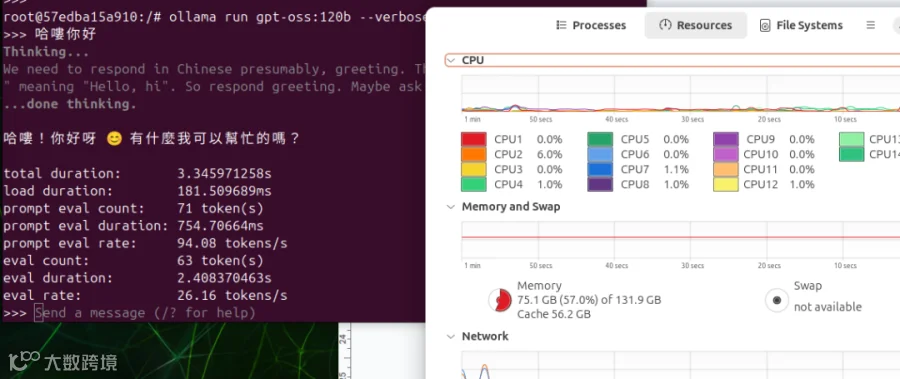

GPT-OSS 120B模型运行结果
当我输入「哈啰你好」后,模型不仅正确理解语境,还贴心地补了一句「有什么我可以帮忙的吗?」。
这种自然的互动让人有种「真的在本地端跑超大模型」的震撼感。虽然目前效能不算极致,但能够脱机、随时唤起这样的语言模型,本身就是一种里程碑。
有趣的是,在模型响应过程中 CPU 几乎没有被吃满,显示运算核心可能主要落在 GPU,CPU 只负责周边调度。另一方面,内存吃掉 75GB,这和 GPT-120B 这样的庞大参数量完全符合预期。
这也意味着,想在本地端玩 120B 模型,没有 128GB 以上内存 几乎不用考虑。

LLM 效能对照实验
为了更全面观察NVIDIA Jetson Thor 在不同模型下的表现,我们针对多款 LLM 做了推理速度,整理如下:
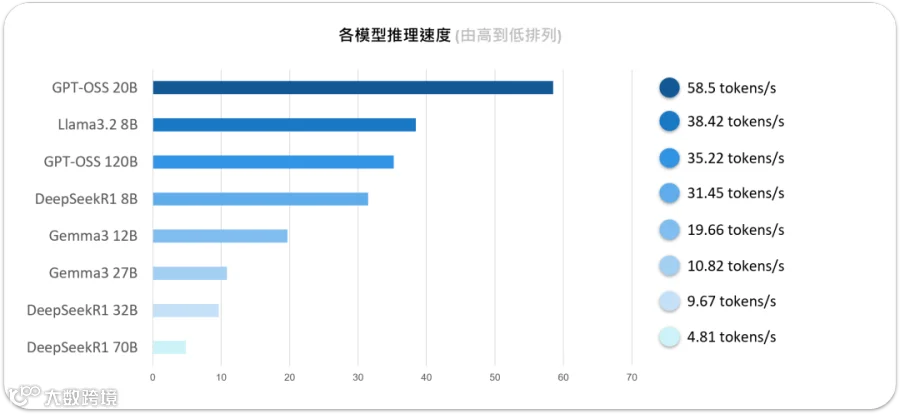
从这份数据看下来,其实趋势满明显的:模型参数越大,生成速度自然就慢下来。不过有趣的是,像 GPT-OSS 120B 这样的百亿等级模型,还能稳定跑到 35 token/s,这表现已经超乎预期,算是惊艳了。
反观小模型的优势就更直接了,像 GPT-OSS 20B 和 Llama3.2 8B,速度可以冲到 38 到 58 token/s,对需要实时互动或低延迟场景来说,绝对是首选。
至于 DeepSeek R1 系列,8B 还算能接受,但 70B 就有点太吃力了,速度掉到只剩 4.81 token/s,几乎无法用在实时应用上。

实测结论
整体测下来,我觉得 NVIDIA Jetson Thor 在本地推理百亿等级的模型时,效能真的有惊喜。像 GPT-OSS 120B 这样的庞然大物,依然能跑出大约 26 tokens/s 的稳定输出速度,这在生成任务里已经算是中高水平,完全超乎我原本的预期。再来看资源使用,内存大概吃掉 57%,虽然不算小,但至少还保留了余裕,代表后续如果要拉更长的上下文,甚至加上额外的并行任务,系统还有空间能承受。
更有意思的是 CPU 几乎没什么压力,大部分工作都被 GPU/Tensor Core 扛下来,这正好展现了 Jetson Thor 做为专用 AI 加速器的价值:它不是靠把 CPU来撑效能,而是有效率地把推理任务交给对的硬件。
最后谈到应用价值,我认为 MIC-743-AT 已经成功证明了一件事:在边缘端要跑超大规模模型不再是不可能的任务。它不只能撑起 120B 参数的 LLM,还能保持实用的推理速度,这对智能制造、智能交通,甚至需要本地生成式 AI 的场景,都开启了新的可能。
如果您对研华MIC-743感兴趣,可联系研华当地业务或者登录研华官网获取产品详细参数规格书。
