
出品 | CSDN(ID:CSDNnews)
- 新会话开启后,AI 遗忘项目既定的技术栈与代码规范;
- 长对话后期,因上下文污染和注意力漂移,AI 逻辑混乱甚至原地打转;
- 自动生成代码存在隐藏逻辑缺陷或依赖问题,导致 PR 多次被退回。


核心共识:Agent = Model + Harness
Agent=Model+Harness



第一关:如何让 AI 读懂巨型代码库?
痛点:AI 记不住项目规范,大库读不完
解法:五层记忆体系 + 上下文分诊
1. 建立分层的记忆架构
- Enterprise 级:企业全局 CLAUDE.md,写入不可绕过的安全与合规策略(如严禁代码外发、禁止硬编码密钥)。
- User 级:存放个人编码偏好(如交流语言、快捷指令映射)。
- Project 级:团队共享的项目级规范(如规定使用 Fastify 框架和 pnpm 包管理)。Anthropic 官方建议该文件控制在 200~300 行以内,作为始终在线的 P0 槽,每行皆为关键规则。
- Rules 级:将细分领域规范(如前端组件、数据库迁移、测试策略)拆解为独立文件。利用 YAML Frontmatter 的 paths 字段声明 Glob 模式进行条件化加载,实现按需取用。
- Local 级:存放个人临时备忘,自动纳入.gitignore,不提交至代码库。
2. 上下文分诊:类比操作系统调度

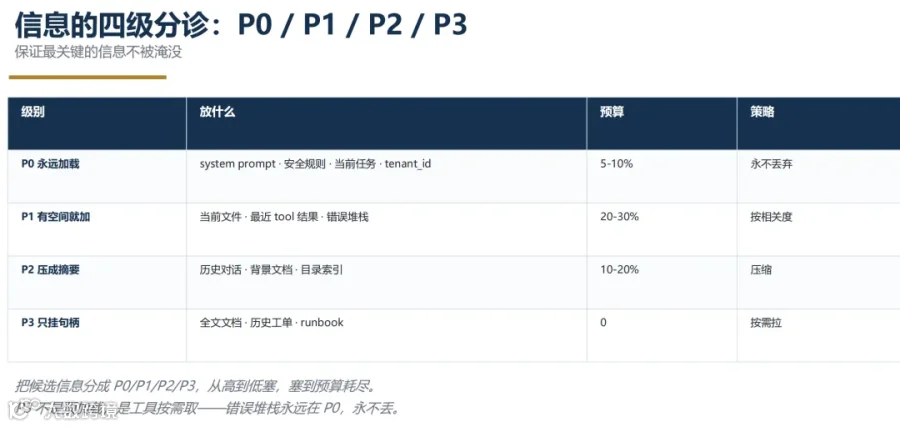

第二关:如何控制 AI 的幻觉?
痛点:AI 给出看起来对、实际是错的代码
解法:结构化上下文 + Hooks 质量门禁
1. 结构化输入,注入而非生成
- 反例:帮我优化这个函数。
- 正例:优化 src/utils/parser.ts 的 parseConfig 函数,瓶颈在第 42 行的循环。
2. Stop Hook 作为契约:将控制交回确定性工程
{
"hooks": {
"Stop": [
{
"matcher": "All",
"command": "pnpm lint && pnpm test",
"blocking": true
}
]
}
}
第三关:如何实现经验复用?
痛点:好 Prompt 锁在个人脑子里,无法团队共享
解法:从 Prompt 到声明式 Skill
- 启动阶段:仅加载每个 Skill 顶部的 name 和 description(约 100 tokens 元数据)。
- 匹配阶段:当用户输入命中 Skill 语义(如提到“审查代码”),系统才展开完整的 SKILL.md 主文件。
- 执行阶段:仅在需要动作时,动态调用挂载的 bundled 脚本或外部资源。

第四关:算力贵、用量不透明?探寻 Token 经济学
痛点:一次任务烧了多少钱说不清,长对话越到后面越贵
解法:反向选型、多层路由与 Talker-Reasoner 架构
1. 建立模型选择矩阵

2. 反向选型:在受限模型下选择“模式”
- 单次调用 Opus:价格高昂,面对边缘 case 仍可能出错。
- Haiku 便宜模型 + 迭代自愈:让 Haiku 写代码,另一个 Haiku 做 Code Review,循环迭代 2 轮。其综合算力成本远低于单次调用顶级模型,但最终产出质量反而实现反超。
3. Talker-Reasoner 双系统
- Talker:采用 200ms 的极速便宜模型(如 Haiku),负责立即回复用户、边聊边等;
- Reasoner:采用慢速但聪明的模型(如 Opus/reasoning),在后台进行深度推理,将推理出的信念状态(belief state)源源不断供给 Talker。

第五关:约束与放手
痛点:AI 改对了 Bug,却顺手改了三处不该改的安全逻辑
解法:约束行动而不是约束思考,引入 HITL 人工审核
- 只读/低爆炸半径操作:(如查代码、看文档)自动放行,不中断流程。
- 可写/中等影响操作:留痕放行,记录全链路 Keyed log,事后支持完整 replay 溯源。
- 高爆炸半径/不可逆操作:强制触发阻断,并在控制台弹出 HITL 人工审核面板,需人工确认后方可继续执行。
第六关:复杂的编排载体该如何抉择?
痛点:SubAgent、Skill、Workflow、Agent Team 概念混淆,不知道怎么组织
解法:一张四方图厘清边界

- Skill = 岗位操作手册:静态的、跨任务复用的知识包与 SOP 模板,代表 Agent 的职业能力。
- SubAgent = 专职员工:具备独立的、被隔离的上下文空间,执行完特定任务后即刻销毁,实现防污染。
- Workflow = SOP 流程图:将控制流显式、确定性地冻结在代码或脚本中,适用于多步、有明确目标的长期自动化流程。
- Agent Team = 持续协作的虚拟团队:维持长期的、多人的对话交互,各个 Mate 角色拥有持久化 Session。
第七关:如何防止长任务状态漂移?
痛点:复杂的长任务跑着跑着就偏离了目标
解法:三平面分立架构 + 草稿纸看板
- 执行调度平面:采用 DAG 结构,只记录任务状态与执行流,不掺杂自然语言叙事与业务参数。
- 机械参数平面:严格键值的结构化字典,是业务 API 入参的唯一可审计来源。
- 叙事对齐平面:采用自然语言记录“目标与进展”,作为防漂移的“防波堤”,包含三个核心:
- 锚(Anchor):锁定用户的原始最终目标,无论中间跳转多少轮,均以此校准。
- 账(Ledger):里程碑台账,结构化纪要“做到了哪一步”、“确认了什么”。
- 集(Collection):投影工作集。每一步只给 AI 投影当前该看的、最小的上下文集合,降低检索开销。
第八关:从 Demo 到产线,如何合规治理?
痛点:能写代码不等于能交付系统,谁来对 AI 的生产出错负责?
解法:可观测性 + 来源坐标 + 团队的两条纪律
- 纪律一:角色规则前置,别等出事再通过 Prompt 去补,必须写进 Skill 或 agent.md。
- 纪律二:实行 Pre-task gating。在 AI 动手写代码前,强迫其先进行评估,说出“要做好这件事,还需要补充什么信息、明确哪些问题”。不评估,不准写代码。
