
为什么 AI 总推荐你的同行?9 大 AI“取材习惯”深度拆解
| 摘要|同样是联网搜索,ChatGPT、Google Gemini、Perplexity、Claude、Kimi、千问等主流 AI 在获取和引用内容的方式上存在显著差异。有的依赖传统搜索排名,有的偏爱直接回答问题的页面,有的重视数据出处,还有的擅长读取 PDF、长文档及多模态信息。外贸企业在开展 GEO(生成式引擎优化)之前,首要任务是厘清不同 AI 模型的“取材偏好”。 |
当前,部分海外采购商寻找供应商的方式已发生转变,不再单纯依赖 Google 搜索结果列表,而是直接向 AI 提问:
| Recommend five reliable control cable manufacturers in China. |
几秒钟内,AI 即可列出推荐名单。
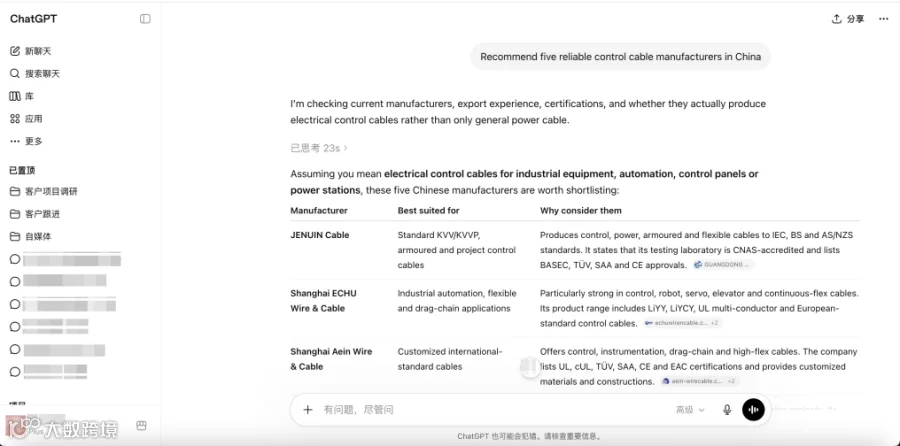
对采购商而言,效率显著提升;但对工厂而言,一个现实问题随之而来:为什么 AI 推荐了同行,却遗漏了你?
这并非完全取决于工厂规模或 Google 排名。许多被 AI 提及的企业,未必是行业巨头,也未必所有关键词排名靠前,但它们往往具备一个共同点:公开信息更清晰、具体,且便于 AI 读取、验证和引用。
基于对 ChatGPT、Google Gemini、Perplexity、Claude、Bing Copilot、千问、Kimi、百度 AI 搜索、豆包和 DeepSeek 等产品公开机制的梳理,可以发现不同 AI 虽均具备“联网搜索”能力,但其“取材习惯”各不相同。
一、什么是 AI 的“取材习惯”?
目前尚无大模型公司公开完整的网站名单、引用权重及排序算法。本文所述的“取材习惯”主要基于以下三个维度:
- 平台公开的搜索爬虫和联网检索机制;
- 平台展示的网页、文档和多模态处理能力;
- 基于常见搜索表现总结的内容适配方向。
需明确的是,这不是所谓的"AI 排名公式”,也不存在“按特定格式写作必被推荐”的捷径。GEO 的核心价值在于提高企业内容被发现、读懂、验证和引用的概率。
二、AI 获取网站内容的三条路径
1. 模型训练阶段接触
大模型训练数据涵盖公开网页、书籍、论文、代码及授权数据等。但企业通常无法确认自身网站是否进入训练库、哪些页面被使用、数据更新频率及回答问题时是否会被提及。因此,外贸企业不应将 GEO 策略完全押注于“进入训练库”。
2. 进入 AI 或搜索引擎索引
部分 AI 通过搜索爬虫或搜索引擎索引发现网页,这与传统 SEO 联系最为紧密。例如:
- ChatGPT 拥有面向搜索的网页抓取机制;
- Google AI 建立在 Google 搜索体系之上;
- Bing Copilot 依赖 Bing 搜索;
- Perplexity 和 Claude 具备面向搜索或用户访问的网页工具。
3. 用户提问后临时读取
AI 在回答特定问题时,可能临时打开网页提取正文并组织答案。因此,企业不仅应关注"AI 是否爬过我的网站”,更应思考:“当采购商提问时,AI 能否找到、打开并读懂我的页面?”
三、9 大 AI“取材习惯”总览
| AI 工具 | 更依赖什么 | 更容易使用的内容 | 外贸企业重点 |
|---|---|---|---|
| ChatGPT | 搜索结果、公开网页、可直接读取的页面 | 能直接回答问题的采购指南、对比、FAQ | 把答案写清楚,减少空泛宣传 |
| Google Gemini / AI Overview | Google 搜索索引与质量系统 | 已收录、有搜索基础、有原创经验的内容 | SEO 基础、主题内容群、原创数据 |
| Perplexity | 多来源搜索与引用 | 有结论、有数据、有出处的页面 | 参数、标准、检测依据、来源说明 |
| Claude | 搜索、网页访问、长上下文 | 完整、严谨、有条件和边界的内容 | 技术指南、白皮书、复杂选型 |
| Bing Copilot | Bing 搜索索引 | 标题清楚、表格明确、更新及时的页面 | Bing 收录、IndexNow、表格和 FAQ |
| 千问 | 问题改写、多轮和多源检索 | 中英文名称完整、图片视频配合的内容 | 产品别名、应用词、多语言资料 |
| Kimi | 网页提取、长文本和文档 | 容易转成纯文字、结构清楚的内容 | HTML 正文、PDF、技术文档 |
| 百度 AI 搜索 | 百度搜索体系和中文内容 | 中文网页、企业信息、新闻、图片视频 | 中文主体信息和中文产品介绍 |
| 豆包 / DeepSeek | 受版本、联网工具和具体产品影响 | 网页、文档及多模态公开资料 | 先做好通用 SEO 和内容基础 |
综上所述,GEO 并非为每个 AI 单独撰写一套文章,而是将同一套企业资料完善化,使其能被不同 AI 高效识别和利用。
四、模拟测试:同一采购问题,不同 AI 如何寻找答案?
| 说明:以下为基于各平台公开机制和常见表现设计的模拟案例,旨在展示不同 AI 可能的取材路径,不代表某次真实搜索结果。正式发布实测数据时,应以当天实际搜索为准。 |
假设采购商提问:Recommend reliable push pull control cable manufacturers in China.
| AI 工具 | 模拟搜索表现 | 更可能采用的来源 |
|---|---|---|
| ChatGPT | 先解释判断工厂可靠性的标准,再列出企业名单 | 企业官网、供应商指南、第三方公司介绍 |
| Google Gemini | 将问题拆解为厂家、OEM 能力、质量认证和应用领域分别搜索 | Google 已收录的产品页、文章、目录和视频 |
| Perplexity | 直接给出供应商名单,并为每家公司附带引用来源 | 官网、B2B 目录、企业数据库、行业媒体 |
| Claude | 先提醒“可靠”需结合认证、产能和场景判断,再给出候选 | 技术页面、公司能力说明、长篇采购指南 |
| 千问 | 同时扩展“控制拉索、推拉索、Bowden Cable"等中英文名称 | 中英文官网、企业平台、图片和视频 |
| Kimi | 读取企业介绍、PDF 目录和产品详情后进行归纳 | 长文本页面、PDF 产品手册、技术文档 |
该案例表明,不同 AI 不会简单复制搜索结果第一页,而是会改写问题、拆分子问题、搜索别名、对比来源、读取文档并寻找数据支撑。仅写着“我们是专业制造商”的首页难以满足 diverse 的取材需求。
五、ChatGPT:偏好“可直接放入答案”的内容
面对"How do I choose a reliable FRP grating manufacturer in China?"这类问题,ChatGPT 需要的不是空洞的企业简介,而是能直接解答采购疑虑的内容,如:如何判断可靠性、检查哪些参数、树脂类型区别、承载能力验证、报告要求及打样周期等。
ChatGPT 的核心习惯
倾向于寻找能直接回答用户问题的内容片段:
- 一个小标题对应一个问题;
- 标题下直接给出结论;
- 参数和事实融入正文;
- 关键信息避免仅存在于图片中;
- 减少“高品质、服务全球”等空泛表述。
例如,将"Fast delivery"具体化为"Standard samples are normally completed within 7 days, while the typical lead time for bulk orders is 20–30 days",更易被准确提取。
六、Google Gemini:信赖搜索体系认可的内容
Google AI Overview 和 AI Mode 建立在 Google 搜索体系之上,因此 Google GEO 的基础仍是 SEO。若页面长期未被收录或网站质量低,很难获得稳定引用。
Google 的核心习惯
偏好已有搜索基础且能覆盖多个相关问题的网站,尤其看重:
- 工厂真实测试与一手数据;
- 实际项目案例与生产经验;
- 原创图片和视频;
- 技术人员的专业判断。
Google AI 常将复杂问题拆解为子问题搜索,因此产品内容应形成完整的内容群,而非孤立页面。
七、Perplexity:不仅要答案,更要出处
Perplexity 的特点是为回答附上来源,因此它不仅需要答案,还需要适合标注出处的页面,包含产品参数、性能对比、行业标准、检测报告、市场数据及选型表等。
Perplexity 的核心习惯
偏好有明确结论、具体数据且可追溯来源的内容,如温度范围、材料等级、公差、测试时间、MOQ、打样周期、标准编号及数据更新时间等。提供数据来源、测试方法、标准名称及审核人员等信息,有助于在用户点击来源后建立信任,从而转化询盘。
八、Claude:关注条件、边界与完整上下文
Claude 擅长处理长文档、复杂解释和多步骤分析。它不只关注结论,更重视结论成立的条件、例外情况、适用范围及潜在风险。
Claude 的核心习惯
不满足于单一结论,重视完整、严谨且有边界的解释,包括适用条件、对比对象、成本因素及选择边界。例如,不应简单断言某种树脂“永远最好”,而应说明其在特定环境下的优势及在其他场景下的局限性。
九、Bing Copilot:偏爱结构清晰、更新及时的页面
Bing 体系强调清晰的小标题、参数表格、FAQ、案例数据及页面更新时间。适合的内容结构包括产品定义、参数表、优缺点、应用场景、型号对比等。
Bing 的核心习惯
易于理解可快速扫描、比较和更新的页面。产品标准、交期和参数变更后应及时更新,陈旧信息会影响 AI 回答的准确性。建议利用 Bing Webmaster Tools、XML Sitemap 及 IndexNow 等技术手段。
十、千问:喜欢改写问题并进行多源搜索
千问的联网检索不限于用户原句,常会先改写问题,再从多角度查找资料。例如搜索“中国靠谱控制电缆厂家”时,系统可能同时检索中英文名称、行业俗称、产品简称及应用设备等。
千问的核心习惯
重视产品名称、同义词、应用词及中英文信息的关联。若网站仅使用单一名称,AI 建立的产品关联将较弱。建议覆盖 Bowden Cable、Push Pull Cable、Mechanical Control Cable 等多种表达。
十一、Kimi:页面转为纯文字后仍需易读
Kimi 擅长读取网页、长文档和 PDF,常将内容转换为纯文字结构处理。若页面依赖复杂脚本加载、核心内容藏在轮播图或参数全为图片,AI 将难以理解。
Kimi 的核心习惯
去掉图片、动画和样式后,正文依然清晰才是真正的"AI 友好”。建议提供长篇技术文章、清晰的 HTML 正文、可复制的 PDF 及分层明确的文档。可将页面复制到纯文本工具中自检,确保内容顺序合理。
十二、百度、豆包、DeepSeek:规则未明时的应对策略
相比国际主流模型,部分国内 AI 的抓取规则尚未完全公开,且受模型版本、联网工具及地区因素影响较大。但可以确定的是,它们正加强对中英文网页、PDF、多模态信息及结构化数据的处理能力。
企业无需为每个国内 AI 单独制作内容,只需夯实通用基础:
- 保持中英文公司名称一致;
- 完善产品名称和别名;
- 确保网站正常收录且正文可读;
- 为图片和视频添加文字说明;
- 保证 PDF 可复制;
- 统一官网与第三方平台信息。
十三、B2B 外贸企业内容调整建议
1. 核心产品独立建站
避免将几十种产品堆砌在一个页面,每个重点产品应有独立的名称、参数、应用及 FAQ 页面。
2. 关键信息写入正文
材质、尺寸、MOQ、打样周期、交期、定制范围、检测方法及执行标准等关键信息应直接写入网页正文,而非仅存在于图片或 PDF 中。
3. 围绕采购问题创作
内容不应仅围绕关键词,更应回答“怎么选、怎么比、怎么验、怎么定制、有何风险及故障处理”等实际问题。
4. 增加真实经验与一手数据
展示设备数量、生产能力、测试数据、项目案例、生产流程及技术人员观点,增强可信度。
5. 同步建设多模态内容
将工厂能力转化为官网页面、技术文章、YouTube 视频、短视频、产品图片及 PDF 手册等多种形式。
6. 保持全网信息一致
统一中英文公司名称、品牌、域名、地址、主营产品及联系方式,确保官网、LinkedIn、YouTube 及 B2B 平台信息无冲突。
结语
GEO 并非神秘莫测,无需盲目追求 llms.txt 或批量生产 AI 文章。主流 AI 的核心需求其实非常朴素:
- Google 看重已收录且有真实价值的内容;
- ChatGPT 需要能直接回答问题的内容;
- Perplexity 偏好有数据、有出处的内容;
- Claude 关注完整、严谨且有边界的解释;
- Bing 理解结构清晰、更新及时的页面;
- 千问重视问题改写、多语言及多源检索;
- Kimi 适合读取结构清晰的长文本和文档。
AI 真正需要的不是营销口号,而是公开、清楚、具体、可信且方便机器读取的企业信息。外贸网站的下一阶段目标,不仅是让客户找到你,更是要让 AI 在找到你之后,能够真正读懂你。
许多网站未被 AI 推荐,往往是因为企业身份模糊、产品页面空洞、参数依据不足、重要信息隐藏过深或全网信息不一致。相比盲目量产内容,优先解决这些基础问题更为有效。
建议立即尝试在 ChatGPT、DeepSeek 或千问中输入:“推荐几家中国可靠的 [你的核心产品] 制造商”,观察 AI 是否提及你的公司。若未提及,请分析其推荐的同行及引用页面,找出差距所在。很多时候,差距不在于工厂规模,而在于同行已将自己说清楚,而你的网站还没有。