
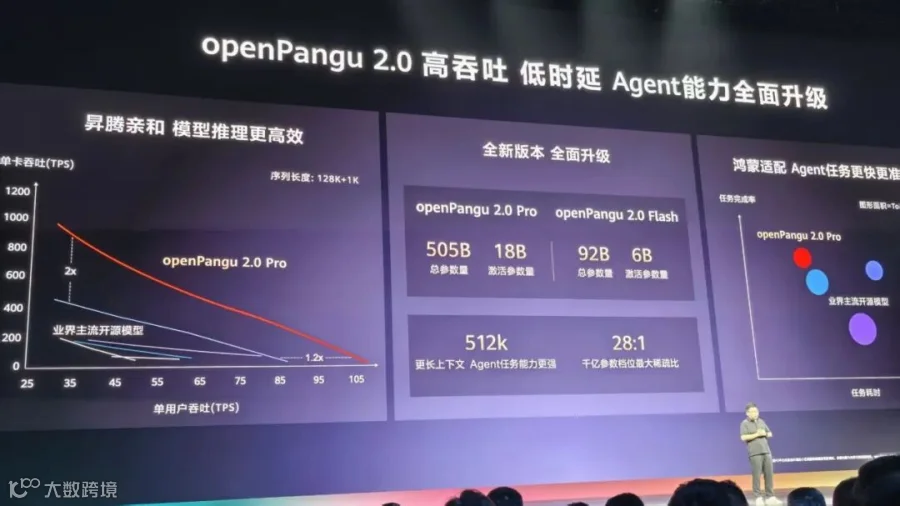
在华为开发者大会(HDC 2026)上,华为常务董事、终端 BG 董事长余承东正式发布开源盘古 openPangu 2.0 大模型,并立下誓言:将带领盘古大模型从中国第一迈向世界第一。
余承东坦言,此前盘古大模型因多种原因表现未达预期,“这不应该”。他于去年国庆前夕接手该项目,决心带领团队实现赶超。
盘古 openPangu 2.0 发布背后的战略考量
针对为何未发布万亿参数规模模型的问题,余承东指出,美国厂商拥有更充足的算力资源,而华为昇腾算力需优先支持国内企业需求,自身预留算力有限,暂无法满足万亿参数模型的训练需求。

回顾:2025 年盘古大模型抄袭风波
此次发布之际,外界难免联想到去年华为遭遇的抄袭争议。2025 年 6 月 30 日,华为开源了包括"盘古 Embedded 7B"、"盘古 Pro MoE"等一系列大模型及基于昇腾的推理技术。
同年 7 月初,一场关于模型参数相似性的技术风波将华为推向舆论中心,引发了对国产大模型创新底线与开源伦理的广泛讨论。
导火索:0.927 的模型参数相似度
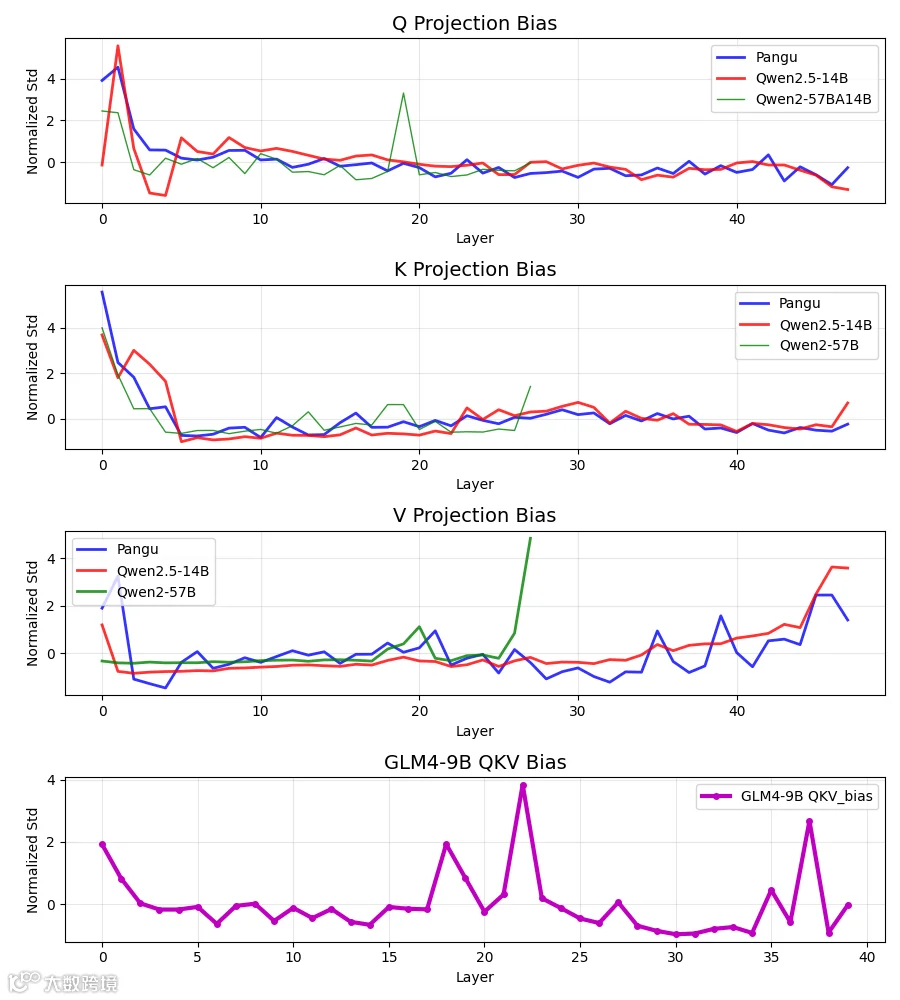
事件起源于名为"LLM-Fingerprint"的研究报告。2025 年 7 月 4 日,研究者通过“模型指纹”技术比对发现,华为盘古 Pro MoE 模型与阿里 Qwen-2.5 14B 模型的注意力层参数相似度高达 0.927,远超行业公认的 0.7 阈值,且部分模块呈现逐层复现特征。
更引人注目的是,盘古模型开源仓库中曾保留"Copyright 2024 Alibaba Group"字样,这一细节被外界视为“实锤”,迅速引爆舆论。

争议核心:技术参考还是参数套壳?
业内观点:“这不像参考,更像迁移。”
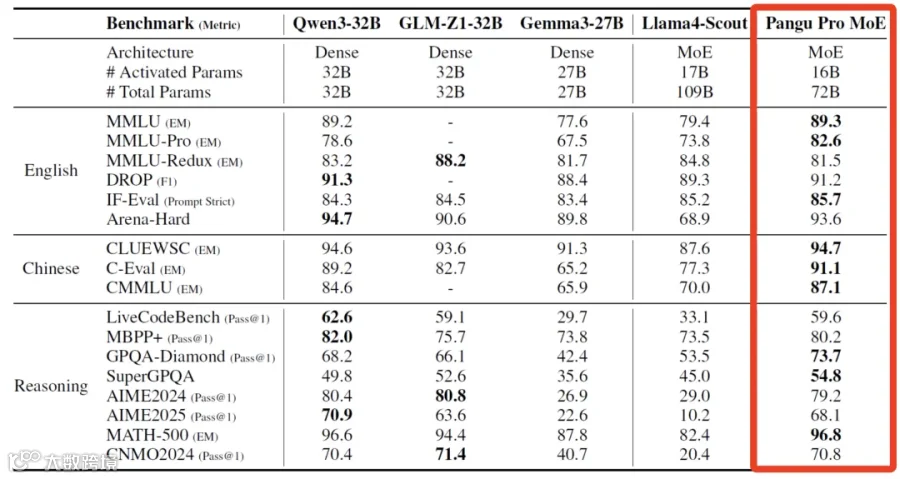
华为方面随后强调合规。诺亚方舟实验室声明称,盘古 Pro MoE 基于昇腾芯片自主研发,其架构创新性体现在提出了"MoGE"(分组混合专家)机制。
声明主要强调两点:第一,该模型是基于昇腾硬件平台开发训练的基础大模型,并非基于其他厂商模型增量训练而来,且在架构设计上有关键创新;第二,部分基础组件代码参考了业界开源实践,但严格遵循开源许可证要求,并清晰标注了版权声明。

然而,外界质疑声并未平息,焦点集中在以下三方面:
1. 参数结构过于相似,超出合理范围
研究者指出,两模型不仅在 Attention 层参数分布上极度相似,甚至连模块名称、类名都未作修改,部分结构可逐层对齐。这被视为直接迁移模型参数并稍作修饰,而非简单的代码复用。
2. 违反 Apache 2.0 商用合规条款
尽管华为辩称遵守协议,但 Apache 2.0 协议明确要求:若用于商用,必须在说明中注明变更内容及原始来源。华为在实际发布与宣传中未履行此义务,涉嫌违规。
3. 拒绝公开训练细节
与阿里公开数据集和训练日志不同,华为至今未公布关键的训练数据来源与过程,也拒绝提供第三方复现路径,这与其“自主研发”的主张相矛盾。
爆料升级:内部员工实名控诉
在官方声明发布后不久,一位疑似盘古项目组内部员工于 2025 年 7 月 6 日凌晨在社交媒体发布长文,直指多个模型存在“套壳续训”问题,揭露了项目内部的混乱与技术造假。
核心观点:团队里面有坏人!
爆料称,由于初期算力有限且效果未达预期,内部压力剧增,导致“小模型实验室”多次通过套壳竞品换取成果。相关 Github 仓库中出现了详细指控。

图源:Github
1. 套壳造假,135B V2 并非自研
所谓盘古 135B V2 实为基于 Qwen 1.5 续训改造,代码中甚至保留"Qwen"类名。通过“扩层 + 改名”伪装为自研,实际技术含量低,却被包装成重大突破。
2. 高层默许,举报被压
团队原计划向业务集团(BCG)举报,但被领导拦下。多位高层知情后仍默许,原因是“政绩优先”,对外宣传重于技术真实。
3. “小模型实验室”抢功抄袭
该实验室多次直接拿主团队代码、数据或外部模型(如 Qwen、DeepSeek)进行微调,便对外宣称是“盘古 Pro"等新产品,被内部戏称为“点鼠标实验室”。
4. 实干团队被边缘,骨干流失
真正从头训练的 135B V3(Pangu Ultra)因无 Loss Spike 而被长期压制,成果遭掠夺,导致团队士气崩溃,大量核心骨干离职。
5. 逆淘汰环境形成
内部形成了“造假有前途,实干被边缘”的氛围,致使真正技术人员失望离场。
华为盘古不是做不成,是被人做坏了。如果你还在问国产大模型为何起不来,也许这就是答案。
国产模型信任危机:创新被营销取代
盘古事件之所以引发震荡,不仅在于是否“抄袭”,更在于它挑战了国产 AI 的根基:我们是否真有能力自主构建大模型?在算力紧张背景下,“拿来主义”披上“技术自研”外衣,不仅误导公众,更损害了对真正技术积累者的尊重。
“开源不是不讲规矩,自主更不能靠偷换概念。”
某些团队通过“套壳 + 微调 + 改名”迅速打造看似强大的模型,掩盖了真实技术差距,这可能挤压了真正探索底层技术路径团队的生存空间。
信任崩塌并非首次:华为技术争议前史
盘古事件并非孤例,华为近年来在“自研”标签下多次卷入争议:
-
2003 年:被思科起诉抄袭路由器代码,最终和解; -
2016 年:Polar 码宣传为自研,实为购自土耳其教授; -
2021 年:鸿蒙被揭为安卓 AOSP 魔改版,遭遇“套壳”质疑; -
2024 年:Atlas 模型参数与 LLaMA2 高度相似,引发讨论。
这些历史积累的争议,正在逐步侵蚀华为“技术自研”的可信度。盘古事件或许只是压垮信任的一根稻草。