
Google Gemini Omni Flash 迎来新进展。6 月 11 日,Google 相关人员在 X 平台表示,Gemini Omni Flash 在图像到视频、文本到视频和视频编辑任务上达到 SOTA 水平,并将很快通过 API 向开发者开放。

Gemini Omni 官方文章配图,来源:Google Blog
此次更新的重点在于 Gemini Omni Flash 覆盖的视频任务范围不再局限于单一的文生视频,而是扩展到多模态输入与编辑能力。

Gemini Omni Flash 覆盖的视频任务范围
核心能力:多模态输入与全任务覆盖
Google DeepMind 模型介绍页面显示,Gemini Omni Flash 在 Video Editing、Text to Video、Image to Video、Reference to Video 等任务上表现突出。其定位明确支持多种输入组合,包括文本、照片、视频和音频,用于生成或编辑视频。
Google 官方博客指出,Gemini Omni 结合了推理与创作能力,允许用户通过多种输入生成高质量视频,并通过对话继续编辑。核心能力包括:
支持文本、照片或视频组合生成视频。
支持最多 5 张照片作为参考生成视频。
提供更便捷的视频编辑功能。
支持通过对话方式调整视频内容。

Gemini Omni 官方演示图,来源:Google DeepMind
流程变革:从单次生成到可编辑对话
与传统视频生成工具相比,Gemini Omni 强调“编辑视频”而非单纯生成。传统流程通常为“输入提示词 - 生成视频 - 不满意重生成”,存在细节难修改、人物场景易漂移等问题。
Gemini Omni 旨在让用户以更自然的方式创作和修改视频。真实创作往往需要调整动作、背景、镜头、人物状态及画面节奏。若每次修改都需重新生成,成本高且难保持一致性。
Gemini Omni Flash 的进展不仅是生成质量提升,更是视频生成能力向可编辑、可对话、可接入 API 方向推进。
生态集成:API 开放与工作流嵌入
Gemini Omni Flash 将通过 API 提供给开发者,这意味着它将成为更多应用、平台和工作流的底层能力。视频生成能力 API 化后,可接入各类产品:
创意工具与内容平台。
广告系统与素材管理系统。
自动化营销与图文视频生产平台。
视频生成将从“单独使用工具”转变为“嵌入具体生产流程”。模型能力的提升正在推动视频生成进入实际工具链。
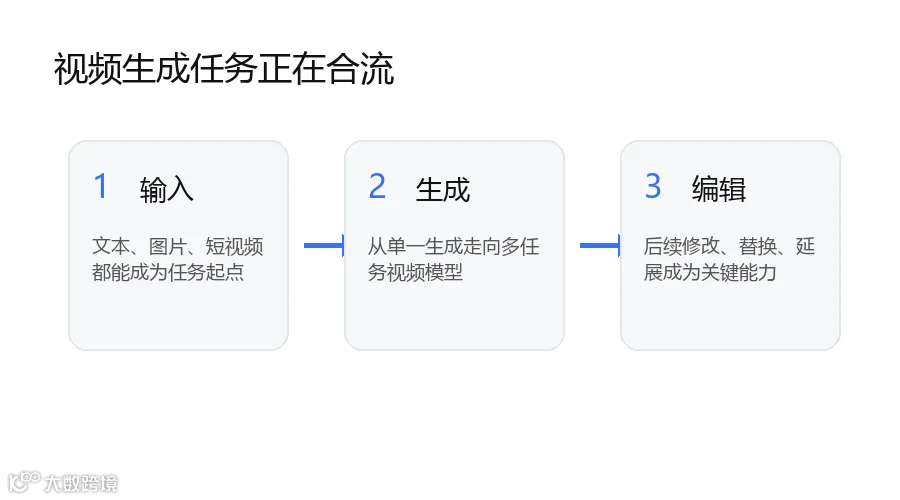
视频模型从单点生成走向多任务工作流
行业影响:静态素材价值重估
对普通内容生产者而言,更现实的变化是静态素材价值的重新放大。
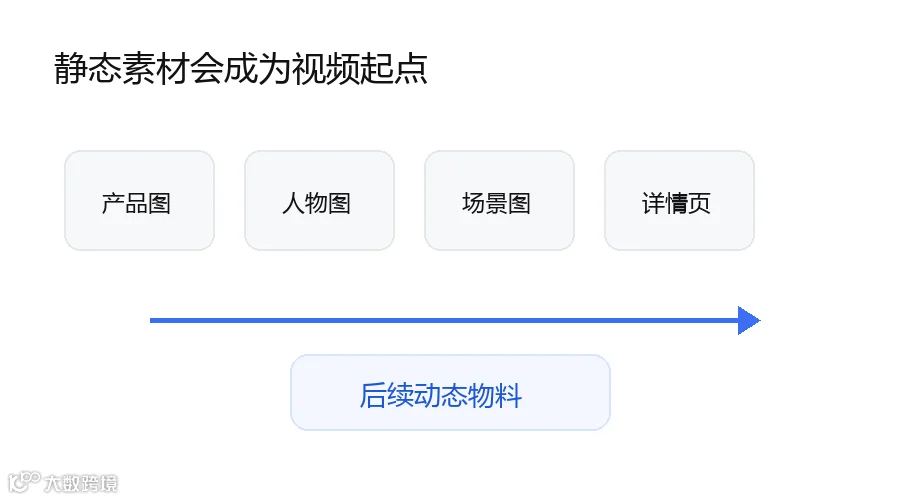
静态素材会成为后续视频生产的起点
随着图像到视频、文本到视频及视频编辑能力的提升,产品图、人物图、详情页图等静态素材将成为视频生产的基础。未来很多视频物料可能不再从拍摄现场开始,而是从整理好的静态素材开始。
对于内容生产者,提前夯实基础视觉资产至关重要。当视频模型继续发展,这些静态图将成为后续动态内容的起点。
未来视频生产的入口,可能不是一台摄像机,而是一批已经整理好的产品图、人物图、场景图和详情页素材。
谁先把静态素材池做厚,谁后续制作动态物料的效率就更高。
信息源:
Google DeepMind Gemini Omni
https://deepmind.google/models/gemini-omni/
Google Blog:Introducing Gemini Omni
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni/
Google 相关动态
https://x.com/OfficialLoganK/status/2065118111360303414
