
点击蓝字

关注我们

“名者,实之宾也。”
作者|听雨
编辑|云舒
出品|极新出海
2026年5月最后一周,OpenRouter发布的全球大模型周度调用榜单,抛出了一组震动行业的数字:当期全球大模型总调用量达23.4T Tokens,榜单前十中中国模型独占六席。DeepSeek V4 Flash以3.11T Tokens的周调用量登顶榜首,腾讯Hy3 preview以3.03T Tokens紧随其后位列第二。
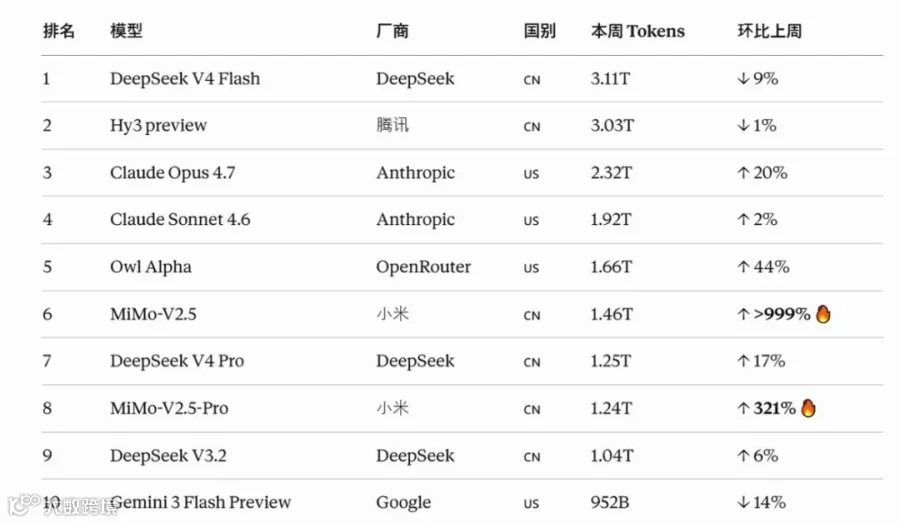
整体统计下来,DeepSeek、腾讯、小米、阿里、MiniMax等厂商的中国模型,合计贡献了平台超52%的Token调用流量,在调用规模上实现全面领先。而在2025年初,中国模型在该平台的周调用量占比仅为15%,短短一年间,整体调用规模增长了39倍。
这组一路走高的数字,勾勒出一个极具冲击力的叙事:全球AI算力中心正在向中国转移。
但调用量增长和算力中心转移,根本不能直接画等号。把Token消耗的统计数字拆解开来看,里面掺杂着语言特性、产品交互逻辑、商业模式差异的多重变量。单靠调用量这一个指标就判定全球AI格局已变,结论下得太过轻率。
语言本身带来的Token计量偏差
拿Token调用量做跨地区横向对比,第一个绕不开的现实是:表达同样的语义,不同语言生成的Token数量存在天然的系统性差异。
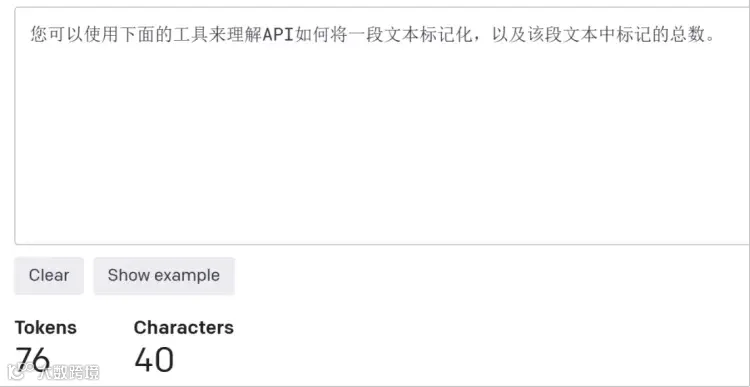
当前主流大模型的分词器,对中文文本的编码效率显著低于英文。一个英文单词分词后通常对应1-2个Token,而未经专项优化的分词方案里,一个中文字符往往要消耗2-3个Token。就拿同一句话举例,英文“You can use the tool below to understand how a piece of text would be tokenized by the API, and the total count of tokens in that piece of text.”需33个Token,而对应的中文“您可以使用下面的工具来理解API如何将一段文本标记化,以及该段文本中标记的总数。”则占用76个Token。行业普遍的经验数据显示,表达同等内容时,中文文本的Token生成量平均是英文的1.5至2倍。

换句话说,就算中美用户每天提出的问题数量完全一致、承载的语义信息量完全对等,中国市场统计出的Token调用量也会系统性高出一截。这部分增量和使用强度、技术领先性无关,只是语言结构在现有分词算法下的天然差异。
全球调用量排名默认将Token作为等价计量单位,这个前提本身就值得商榷。当统计的基础在跨语言场景下失去了公平可比性,排名传递的信号强度自然要打折扣。
长上下文设计放大了调用量数字
抛开语言特性,国内产品对长上下文的设计偏好,是推高Token消耗的另一个核心因素。
先厘清一个很实际的区别:用户一次性提交十个问题,只要求模型回答其中一个,和单独只提问这一个问题相比,模型的输出并不相同,后者的可用性往往更高。
大模型的推理机制里,所有输入内容都会进入上下文窗口参与注意力计算。即便用户明确要求只回答某一个问题,剩下九个问题依然会作为背景信息影响输出分布。部分场景下,额外的上下文能提供消歧线索,帮模型更精准地锁定用户意图;但更多时候,无关信息会稀释注意力权重,导致答案偏离核心,甚至生成幻觉内容。单独提问时输入信息干净、指向明确,模型输出的答案通常更聚焦、更可靠。
国内市场的AI应用普遍主打多轮对话能力和长上下文体验,绝大多数产品都会完整保留会话历史,每次提交新问题时一同传给模型,以此实现对话的记忆连贯性。这种设计提升了用户体验,但也让单次调用的Token消耗量远高于单轮短上下文场景。美国市场则有所不同,其API调用中相当比例来自企业级应用的单次任务型请求,上下文长度可控,Token消耗结构也更精简。
两边交互范式的差异,让同一张全球调用量榜单上,中国侧的数据被长上下文策略结构性放大。这里的调用量高低,更多反映的是产品路线选择的不同,而非算力绝对规模的高下。
电力消耗是更难粉饰的硬标尺
既然Token调用量不足以证明算力中心转移,那什么指标更靠谱?电力消耗是一个很难粉饰的硬约束。
大模型从训练到推理的全生命周期,都在消耗巨量电力。一次千亿参数模型的完整训练,耗电量可达数千兆瓦时,相当于一个中型城镇数小时的用电总量。推理阶段单次调用的能耗远低于训练,但乘以日均数万亿次的调用规模后,累计电力消耗往往会超过训练环节。这些电力需求必须由物理世界的数据中心来支撑,没法通过调整统计口径人为增减。

目前,美国在AI相关数据中心的电力总装机量和清洁能源配套上依然保持领先。公开数据显示,2025年美国主要云厂商的数据中心总电力容量已超过20吉瓦,并且大规模签约了核电、地热等基荷清洁能源。中国近年在内蒙古、贵州、甘肃等地加速建设算力枢纽,电力容量增长很快,但在绿电比例、电网稳定性和跨区域调度能力上仍有短板。更贴近事实的判断是:中国AI推理环节的电力消耗增速已经超过美国,但绝对总量还没有实现反超。
电力流向的真实分布,比Token计数更贴近算力资源的地理布局。看电用在了哪里,才知道算力中心真正落在哪里。
低价策略与推理优化的路线分野
Token调用量的飙升,除了语言和交互因素,还受到价格信号的直接刺激。
过去两年,国内大模型市场陷入激烈的价格竞争。部分头部厂商把模型推理单价压到了每百万Token不足1.5元人民币,而同期美国主流模型的API定价,普遍维持在每百万Token1.5至3美元的区间。按汇率折算,国内的Token单价仅为美国市场的十分之一甚至更低。
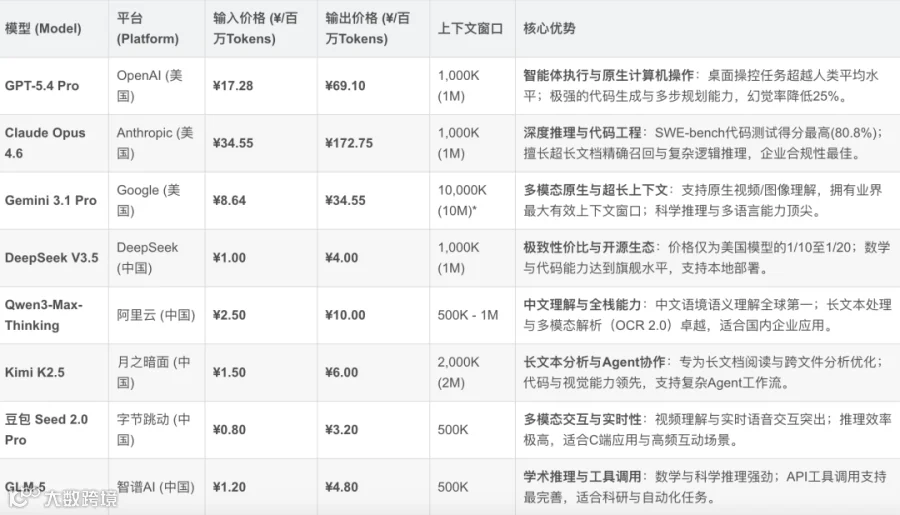
这种低价策略大幅降低了调用门槛。开发者可以用极低的成本做高频测试和规模化部署,大量对成本敏感的调用需求被释放出来,直接推高了国内的Token消耗总量。但低价的另一面,是利润空间的压缩和模型服务可持续性的考验。国内厂商能承受低价,很大程度上依赖模型压缩与推理优化技术的突破,其中最核心的指标就是推理阶段的内存占用率。
同等参数规模下,部分国产模型通过量化、剪枝和注意力机制优化,将推理内存占用控制在美国主流模型的70%至85%,低了15%到30%。更低的内存占用意味着单张GPU可以承载更高的并发请求,直接摊薄了单位算力的服务成本。这是中国团队在工程化层面做出的实打实的进展。
但这种优势只集中在推理效率环节。训练侧,美国依然掌握着超大规模集群、先进互联技术和前沿模型架构的主导权。推理领先和训练领先是两条不同的战线,调用量数据能印证前者,却覆盖不了后者。
未完成的转移与字节的赌注
至此可以得出一个更审慎的判断:“全球AI算力中心正在向中国转移”这个命题,目前只在推理算力的增量分布上成立。训练算力的制高点、底层芯片的供应安全、前沿模型的迭代方向——这些构成算力中心内核的要素,还没有发生实质性转移。
字节跳动宣布的700亿美元AI基础设施投入计划,正是在这个缺口上落子。这个数字超过了阿里巴巴和腾讯在AI领域的投入总和,也逼近美国四大云厂商各自的年度资本支出规模。字节的目标不局限于打造某一款超级应用,而是试图搭建一张覆盖全球的分布式算力网络。当推理需求持续爆发,谁掌握了最密集、成本最低的算力节点,谁就能在下一阶段的AI生态竞争中占据规则制定的主动权。
这是一场从应用层繁荣向基础设施层话语权跃迁的尝试,但挑战同样现实:先进芯片的获取渠道持续收窄,海外数据中心的本土化运营面临合规与地缘双重风险,全球开发者生态的信任建设需要长周期的投入。
调用量数据的反超释放了一个信号,它的价值在于引发行业关注,而非宣告终局。真正的算力中心转移,需要电力、芯片、生态和商业回报四个齿轮同时咬合,眼下距离那一刻还有相当长的距离。

关注「极新出海」,与我们一同追踪中国AI企业全球化的每一次技术输出、产品落地与资本动向。



