LUXI SPKING NIGHT
🍺 很放松,but serious 🍺
陆兮开放夜 是一个致力于连接青年研究者与前沿探索的系列沙龙。我们相信,微醺是最好的思考方式。每期我们都会邀请来自不同领域的嘉宾,分享他们的最新思考,在开放、轻松的交流中,最能碰撞出思想的火花。
在刚刚结束的 陆兮开放夜vol.2,我们非常荣幸地邀请到了SIMO WU与XINYU YANG两位博士,带领线上线下近百位参与者,围绕可微物理模拟、智能体系统设计等前沿方向进行分享和深入探讨。
Dr.WU的分享,从他在Meta五年的大规模建模实践与数学物理的理论背景出发,系统回顾了他在可微物理模拟这一前沿领域的探索。Dr.WU深入剖析了当前视觉-语言-机器人模型在物理理解上的瓶颈,并提出通过引入可微物理引擎,将物理规律显式地融入模型训练,以期显著提升机器人学习复杂技能的效率与能力上限。
在分享的最后,Dr.WU进一步提出了一个正在探索中的前瞻性研究框架:通过构建融合物理感知Tokenization与可微模拟的端到端训练路径,旨在增强视觉-语言模型对物理世界的深层理解与预测能力。感兴趣的朋友,可在评论区留下你的想法,或持续关注「陆兮开放夜」后续活动~


大家好,我是SIMO WU。非常感谢陆兮科技的邀请,今天能在这里和大家分享我近期在思考和探索的一些问题。
今天的分享主要分为四个部分:
我的个人背景介绍。
探讨问题的背景和动机。
我提出的一些技术方法细节。
其他正在合作的研究课题。
我的经历分为研究和工业两部分:过去五年我主要在Meta任职,待过两个组。工作内容可以归纳为三大类:
第一件是Modeling(大规模诚信建模)。大概是19、20年的时候,Meta的社交平台包括Facebook、Instagram等都面临着平台内容与用户行为的诚信与隐私问题。我们当时构建了一个具有持续建模能力的神经网络,每天在数十亿级别的用户行为,去识别哪些是异常操作(如身份盗用、灰色产业链),最后模型的识别准确率能做到95%以上。
第二件是做了一个图神经网络中台。我参与构建了一个偏中台的服务,将用户、内容等实体通过图神经网络嵌入到一个统一的知识图谱中。这相当于为所有实体进行了“向量化”,下游系统(如推荐系统)可以利用这些向量之间的相似度,来理解用户兴趣或内容关联——比如两个用户向量接近,说明他们兴趣相似;用户和内容向量接近,说明他可能喜欢这个内容。
最后一件也是最近在做的关于LLM的应用,特别是在推荐系统领域。我们微调了最前沿的Llama模型,有两个主要发现:一个是LLM确实能力强,尤其是处理自然语言类的特征,省掉了很多预处理的工作,而且它还能自己找到“推荐的理由”,可解释性比以前强。但另一个问题是,LLM的成本毕竟很高,在许多场景下,其投入产出比是否合理,还是需要审慎评估的。
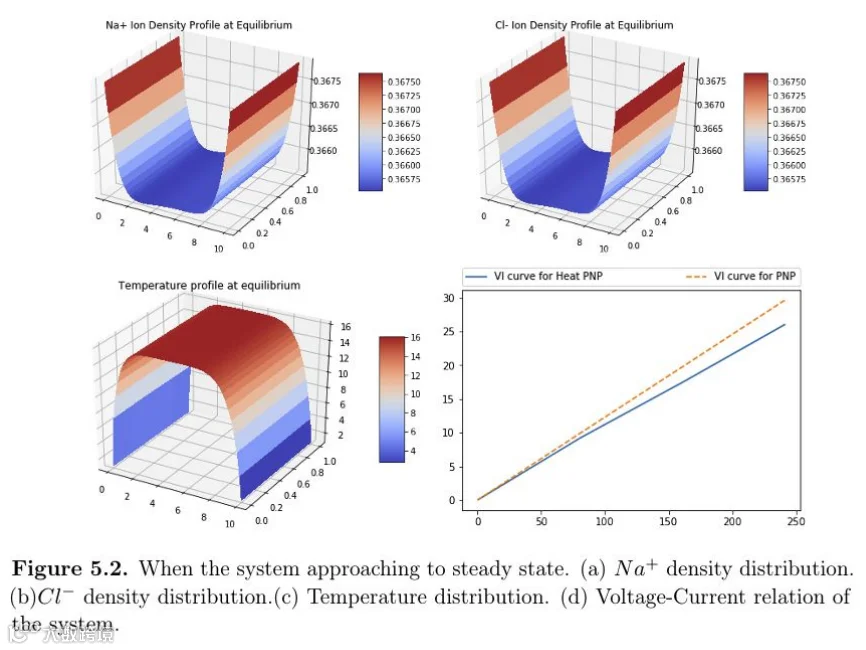
在研究方面,我博士期间的研究属于偏PDE和热力学的范畴。我们找到了一种符合热力学规律的方式,通过定义能量泛函来推导出符合物理定律的PDE。
举个例子,在模拟液体电池时,传统模型会得出线性的伏安曲线。但实际上,带电离子流体运动会产生热,从而非线性地影响电阻。我们的模型从物理机理本身出发,推导出了更符合实际的模型。这套理论不仅能用来推导方程,还能帮助我们设计出更稳定、更收敛的数值求解方案。

回到今天的主题:视觉-语言-机器人模型,也就是VLA。
在深入探讨VLA之前,我们先回顾一下大语言模型近年来的显著进展:
GPT:基于“预测下一个词”的核心目标,使模型能够学习文本数据的概率分布。
MOE与多模态:通过混合专家模型架构,并结合如CLIP等技术,将图像、文本等多模态信息映射到统一的表示空间。
Scaling Law:模型性能与数据规模、算力投入、参数数量之间的可预测关系。模型性能随着训练数据量、模型参数规模及算力投入的增加而呈现可预测的提升规律。
- RLHF与微调:采用RLHF、SFT等技术对预训练模型进行对齐与优化,以更好地遵循指令和人类偏好。

那VLA和世界模型现在发展到哪一步了呢? 我举几个有代表性的例子:
首先是谷歌Gemini在机器人上的应用。他们展示了如何利用VLA模型的零样本能力直接控制机器人。只需给模型输入机器人视角的图片和任务指令,模型就能输出机械臂的行动轨迹,完成如打开包裹、叠衣服等任务。他们还通过扩散模型,将VLA的潜在空间与机器人的动作空间对齐,实现了更好的效果。这说明,VLA模型本身已经足够强大,可以直接解决一些以前需要复杂技术手段的机器人问题。

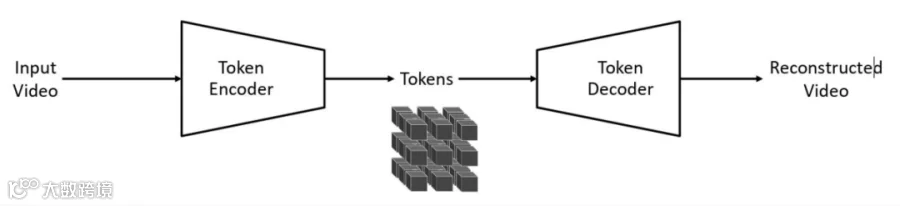
其次是英伟达的两个工作:一个叫Cosmos,这是一个基于视频生成的世界模型。它只学习视频数据,通过一个编码器学习视频信息的tokenization,然后重建视频。这个模型可以被用作世界模型,其核心能力在于对未来进行预测;另一个是Omniverse,它厉害在能低成本、大批量地生成接近真实的虚拟场景,极大地降低了准备机器人训练数据的成本——这两个工作在机器人领域的应用是非常有用的。


传统机器人任务执行通常分为感知、规划、控制三个模块。随着大模型和VLA模型发展,我们可以看到一种趋势:大家都试图将这些任务压缩到一个模型(如VLA)中去完成。
然而,这样做也带来了新的问题:
首先是物理与空间认知太”幼稚。现有的VLA或视频生成模型在训练时,并不关心物理世界的保真度,导致它们对物理规律和空间关系的理解非常初步(它不知道东西掉下去会摔碎,也不知道碰撞要减速)。
二是太慢太贵。大模型直接用于机器人控制,延迟高,成本也高。
三是长链条推理的局限性。受限于视频生成模型对物理世界的理解,生成十几秒视频可能质量还不错,但再长就不太行了,而机器人任务往往需要更长的规划。
那怎么办呢?我觉得一个关键点是“可微性”。

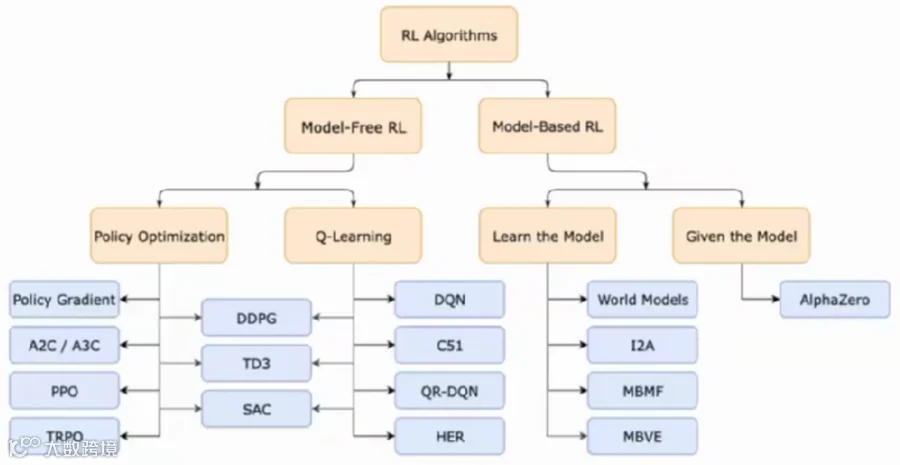
让我们回到机器人策略训练本身。传统主流是用强化学习,其中又分“有模型”和“无模型”:
Model-based RL(基于模型的强化学习):如AlphaZero。智能体对环境(如围棋规则)有清晰的模型,可以预测行动后的结果。这种方式效率高。
Model-free RL(无模型强化学习): 如DQN、PPO。智能体通过大量试错来学习策略,就像你不知道牛顿定律,只能通过不停地左右移动来学习让倒立摆保持平衡。这种方式数据利用效率低,成本也更高。
在机器人领域,一个高效的“模型”就是对物理环境的理解。如果我们能把物理规律做进模型,并且是可微的,那训练效率会高很多。
这里我引用了两篇论文来佐证:第一篇23年的 Diffimimic ,它在可微环境中让机器人只花了5分钟学会后空翻,成功率94%。而24年 OmniH2O 用model-free方式做类似动作需要训练一天。

关键区别在于,Diffimimic将牛顿力学方程显式地编码进了可微环境,动作和结果之间是连续、可导的;而后者只能靠猜和试。
所以我的观察是:可微性越高,训练效率越高。
理想情况下,训练结合VLA的机器人策略需要一个端到端可微的环境,包括物理模拟和渲染。不过现实中,可微和精确常常是矛盾的。

我对比了几个主流的机器人模拟器,在精确性(Accuracy)和可微性(Differentiability)之间做了一个权衡谱:
Isaac Gym: 位于光谱左侧,在可微性上做了妥协,但保留了高精确性和卓越的性能优化,支持大规模并行训练,是目前应用的主流。
Brax: 位于中间。
DiffTaichi / Nimble: 位于光谱右侧,通过解析或编译期技术实现了完全可微,但精度和适用场景又受限。
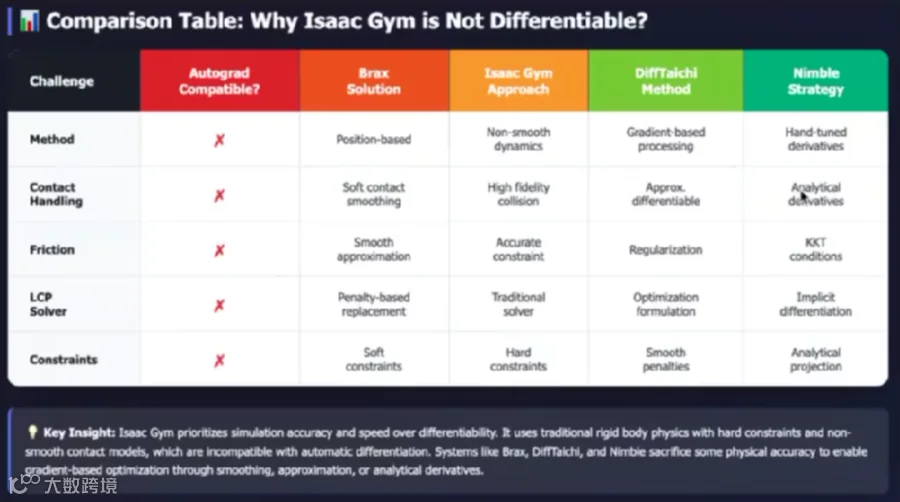
业界已意识到这个问题,例如Mujoco被谷歌收购后底层换用了可微的Jax,未来模拟器可能会向可微性方向进一步发展。

那么,如何增强VLA模型对物理世界的理解?这里有两个代表性工作思路:
TriVLA:在快(处理即时任务)、慢(负责动作生成)双系统VLA基础上,加入第三个系统——基于扩散模型的视频渲染世界模型,用于预测未来帧,以期增强对物理规律的理解。
General Physics Transformer:一个声称的物理世界基座大模型。输入可用PDE描述的物理现象视频,在Tokenization阶段特殊处理,计算时空偏导数,通过时空Transformer提取信息,最后馈入一个固定的数值积分器生成输出。它试图用Transformer架构学习物理规律的时间导数。
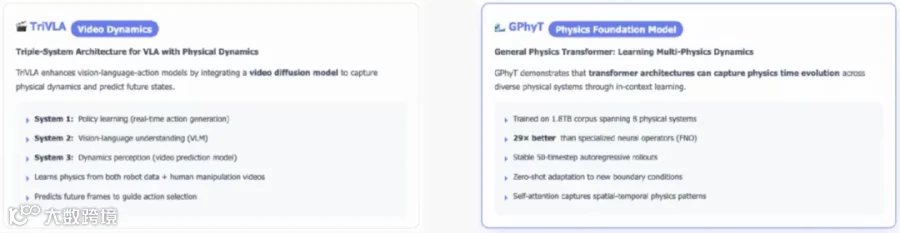

我认为,物理定律(如F=ma)不应仅通过海量数据“艰难”地学习,而应让模型更“聪明”地掌握。
我的想法是分两步走:
第一步,做物理感知的Tokenization。在预训练好的世界模型(如视频生成模型)前,增加一个物理Tokenization模块。该模块能从输入图像中识别物体,并估计其物理属性(位置、速度、受力等)。这样,除了视觉Token,我们还拥有了物理Token。
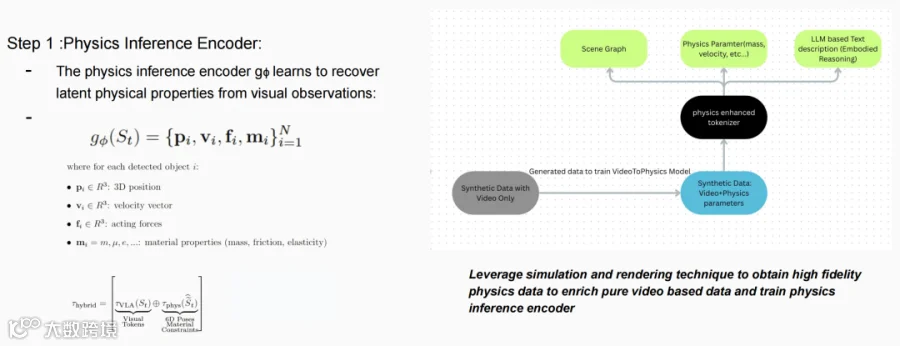
第二步,搭一座可微物理模拟的“桥”。利用一个可微的物理模拟器,将上一步得到的物理Token(作为初始参数)输入其中,进行物理规律的推演和预测;然后将推演结果渲染回像素空间,与原始世界模型一起进行协同训练。
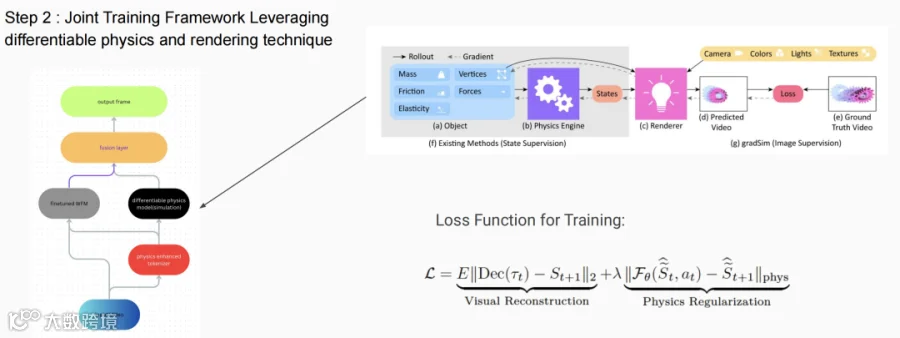
训练目标有两个:视觉重建损失与物理正则化损失。前者确保模型在像素空间的输出具备高度的视觉逼真度;后者则在有物理真值数据时,为物理状态的预测提供监督,保障其准确性。简而言之,我们既关心它生成的画面真不真,也关心它预测的物理状态准不准。
当然,这套框架要跑通,前提是整个链路——从输入视频,经过物理Token化和可微物理模拟,到输出视频——是端到端可微的。
我的分享就到这里,谢谢大家。


吴博士您好,非常感谢您的精彩分享!我主要研究类脑大模型和存算一体芯片,同时也做机器人相关方向。您刚才提到将世界模型与大模型结合以理解物理世界,这给了我很大启发。
我的问题是:我们能否利用大模型和世界模型,对机器人领域中轮胎打滑和漂移这类复杂的物理现象进行建模?因为目前基于数学概率的传统模型(如卡尔曼滤波)很难准确预测打滑。您在这方面有什么建议或经验可以分享吗?

您这个问题提得非常精准。确实,在现有的模拟环境中,摩擦、打滑这类处于物理边界的行为,由于其不连续性,是所有模拟器处理得都不好的地方。
如果想让世界模型学习这种行为,我目前能想到的有两种思路:
第一种是仿效大模型的常规做法——缺什么数据就补什么数据。也就是说,如果我们能大规模采集或合成车辆轮胎与地面摩擦、打滑的真实或仿真视频,然后暴力地对世界模型进行针对性训练,可能会有效果。当然,这本身工程量和成本会非常高。
第二种思路是,如果我们有其他更可靠的、非神经网络的物理仿真模型或PDE模型能够生成这类数据,或许可以采用“师生学习”的框架,用这些精准的物理模型作为“老师”,来指导世界模型这个“学生”进行学习。
这只是我当下的一些直观想法,供你参考。

我是在想,能不能模拟人脑的处理方式?因为人在走路脚打滑时,自己能立刻感知到,而且知道这一步的位移或速度没有按预期增加。但对于一个机器人或模型来说,它很难自知“什么时候发生了打滑”。所以,是不是应该引入更多传感器(比如监测轮速突然增加,或地面摩擦力骤减)来反馈这个信息?

那么我想问一个follow question:您认为需要哪些具体的传感器?或者说,需要哪些参数/需要测量哪些物理量才能准确地定义和检测“打滑”这个现象?

这个…我其实还没有深入研究到这一步。

那我换个方式问,您想解决这个问题的最终目标是什么?是为了单纯地识别出打滑现象,还是为了在打滑发生之后,如何更好地调整控制策略以恢复稳定?

更偏向后者。比如在机器人建图时,一旦轮子打滑,整个定位和地图就会产生严重偏差,我们需要解决这个问题。

我明白了。这可能就与控制理论更相关了。比如可以参考经典的PID控制器思想:它通过计算误差的比例、积分和微分来实时调整输出。或许可以朝这个方向探索,设计一个能根据打滑产生的“误差”实时进行动作修正的机制。更深层的方案,我目前也没有特别成熟的想法。
LUXI
Scholar

吴博士您好!您今天主要探讨了构建端到端可微的VLA来学习物理定律。
我的问题是,让模型学习这些物理定律,主要能解决哪些具体场景的问题?是能提升模型的泛化性能,还是能让它在执行特定任务时表现更好?

我认为主要有两点:
第一,极大地提升训练效率。就像我前面举的机器人后空翻的例子,在可微的、融入了物理规律的环境里训练,只需要5分钟,而不是一整天。在机器人领域,采集真实数据非常昂贵,如果我们能通过物理原理让模型更“聪明”地学习,就能用少得多的数据和算力达到同样的效果。
第二,是解锁更复杂、更灵巧的任务。不知道大家有没有注意到,现在看到的机器人演示,大多是像打拳、后空翻这种“自己玩”的项目。但为什么很少有机器人打球或者踢球的demo?
再比如,现在机器人抓取杯子,通常是把手做成一个环,去套杯子的把手。而人类可以很自然地用两根手指捏住杯壁,靠摩擦力就拿起来了。这其中的差距,很大程度上就是因为现在的控制算法缺乏对物理交互(如精确的力、摩擦、预测物体运动)的深入理解和模拟。
让模型掌握物理定律,正是为了突破这些瓶颈,让机器人能完成更高阶、更需要与动态环境交互的任务。

所以,是不是可以理解为:因为直接训练VLA的数据不足,且帧率可能也不够高,导致模型难以隐式地学会所有物理规律。所以我们才需要显式定义的方法引入物理信息,从另一条路径来辅助解决这个问题?

对的,完全正确。而且有些数据很难通过真机直接采集:比如,你想让一个人形机器人学后空翻,你不可能抱着它教它翻。它必须通过其他方式(比如在模拟环境中利用物理规律)来学习这个技能。因此,对物理的理解和模拟的缺失,严重限制了当前机器人所能应用的场景边界。
LUXI
Scholar
Dr.YANG的分享聚焦于大模型推理的效率与可靠性问题。作为近期公布的亚马逊AI博士奖学金获得者,Dr.YANG在本期带来其团队在ICLR与NeurIPS上发表的两项工作:APE 与 Multiverse。前者通过在输入端并行处理文本,将检索增强生成的推理速度提升了数倍;后者创新性地让模型在单一架构内实现了动态并行生成,从而在保证效果的同时,将长链条推理任务的执行速度提升近一倍,为构建下一代高效智能体框架提供了新的技术路径。


大家好,我是XINYU YANG,目前在卡内基梅隆大学读博士第三年。非常感谢陆兮的邀请!
今天想分享我们近期在ICLR和NeurIPS上发表的两项工作,主题是如何构建一个可靠、高效、动态的推理与智能体框架。核心思路是通过数据、模型、系统和硬件的协同设计来解决真实场景中的问题。
首先,谈谈我对今天大模型,或者说基础模型的理解。我认为它可以看作由四个层次组合而成:
最顶层是数据层,比如文本、图像、视频等;
往下是模型层,包括语言模型、多模态模型等;
再往下是系统层,像vLLM、SGLang这样的推理框架;
最下层是硬件层,比如GPU、NPU这些AI加速器。
这四层共同构成了当今大模型的基础。
在传统的AI设计中,模型算法往往是根据数据特性来设计的。例如,针对图像的局部相关性和空间不变性,我们有了卷积神经网络(CNN);针对序列数据的时序依赖性,我们有了循环神经网络(RNN)。
但今天我们发现,注意力机制成了主流。它可以被看作一个没有偏置的软连接矩阵,能够通用地建模各种数据关系,非常灵活。比如这里有五个词,注意力就能建模任意两个词之间的关系,CNN和RNN能做的事,它理论上都能模拟。
但注意力也有问题。比如双向注意力,就像在扩散模型里用的,它能保证全局一致性,但计算量太大了,是O(n³)的复杂度,生成很慢。
那怎么办呢?大家又转向了单向注意力,就是自回归模型。它通过一个因果掩码,把联合分布拆成了条件分布,一个一个词往外蹦。这样做的好处是,我们可以用上KV缓存,把计算复杂度从O(n³)降到了O(n²)。
但这样就有了新问题。

首先,序列建模能力有限。现实中的数据关系往往是稀疏的、有结构的,不是简单的一条序列。你硬把它压成序列,会引入错误关系,导致模型出现幻觉。
其次,硬件利用率太低。自回归模型虽然理论复杂度低了,但它必须一个一个词生成,根本没法并行。
所以你会发现,它的实际生成速度并没有理论提升那么多;反而,一些扩散模型用的双向注意力,虽然算得多,但因为能并行,在某些场景下反而更快。这就很矛盾了。
因此,我们思考,能否有一种动态的建模方式,能同时兼顾数据特性和硬件优势?
我们发现,在如今的推理和智能体任务中,大家其实已经在用拼模型的方式来模拟这种动态性,比如用LangChain这类框架,把好几个模型拼在一起,让它们互相调用。
但这带来了相应的挑战:
1.效果:每个模型单独被训练,而整个系统无法进行端到端的梯度回传。
2.效率:不同的模型在交流时需重新计算同样的文本对应的不同KV Cache。

所以,我们探索的核心问题就是:能否在单一模型内部,原生地实现这种动态建模能力?
简单说就是,我给你一个结构,你这个模型自己就能在这个结构里把事情做完,不用来回调用别的模型。
我们的答案是肯定的,并由此产生了两个主要工作。

第一个工作是去年在ICLR上发表的,我们提出了Adaptive Parallel Encoding(APE)。它的核心思想是,在输入端做并行。
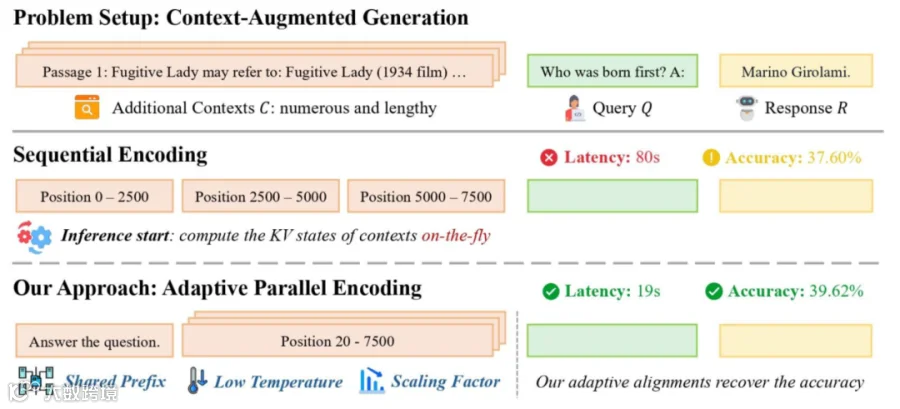
传统方法里,要处理多个上下文,比如做检索增强,会把它们拼成一条长序列塞给模型。这就有个著名的“长文本问题”,计算复杂度是平方级的。
我们的做法是,在输入的时候,就把不同的文本当作独立的部分,形成一个串并联图的结构。这样,不同的文本在输入时就是独立的,我们可以预先处理好每条文本的KV缓存,推理的时候直接加载。
这样,我们不仅能避免平方复杂度,还能预先处理每条独立文本,所以我们在推理时直接加载其KV缓存,实现了“Prefill阶段近乎零开销”。最终,我们在保持模型性能的同时,将端到端的推理速度提升了4.5倍。
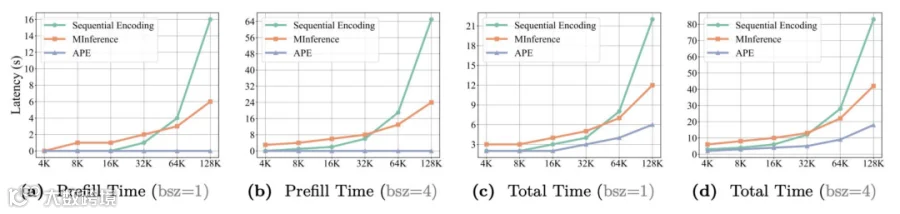

光输入并行还不够,生成的时候能不能也并行?这就是我们今年在NeurIPS上的工作——Multiverse Model。
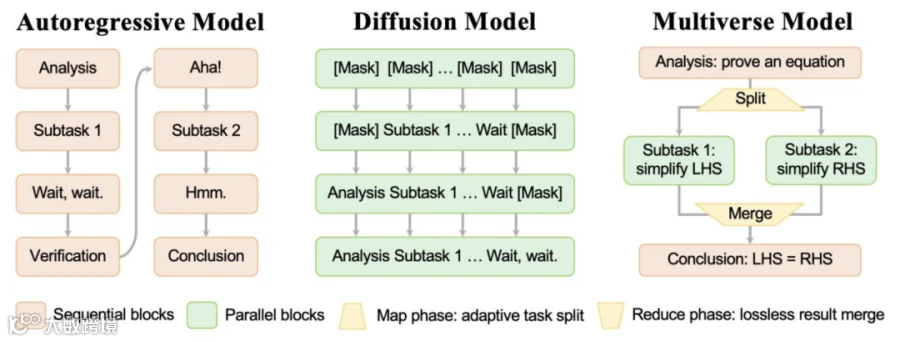
这个模型支持在生成过程中动态地进行并行生成。它可以先做一个规划,然后同时分裂出多个子任务并行执行,最后再合并结果,整个过程在一个模型内完成。
我们当时用32B参数的模型,在真实的推理任务上,达到了和自回归模型差不多的性能,但推理速度快了将近一倍。
我们是怎么办到的呢?我们借鉴了编译器的思想,设计了一套基于特殊控制Token的控制流。
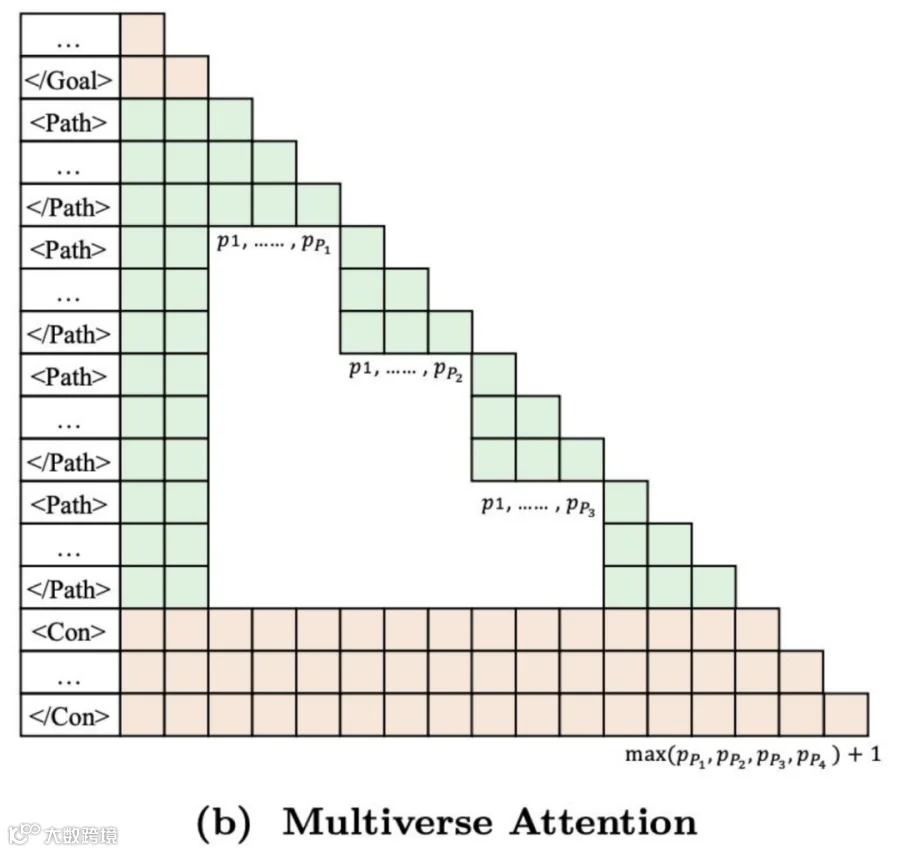
比如模型想并行生成时,它会先吐出一个 [Parallel] Token,然后输出一个 [Goal] ,里面是它的并行计划,比如要分两条路。系统看到这个,就知道要开两个分支并行生成了。等两个分支都生成完了,模型再用 [Conclusion] 把信息合并起来,回到主分支。

这两个工作都基于同一种核心的串并联图注意力机制。它的关键在于,并行分支之间在计算注意力时是相互独立的,这既降低了计算量,又天然支持并行训练。

概念起来很美好对吧?但实现起来挑战巨大。
要实现Multiverse模型,我们面临三大挑战:
第一,数据从哪里来?需要结构化数据,但现有训练数据都是非结构化的。
第二,模型怎么训练?自回归模型本身不支持这种动态生成。
第三,系统怎么支持?现有推理引擎不支持动态并行度切换。
我们通过协同设计解决了这些问题:
数据方面,我们设计了一套自动化流程,利用大模型(比如GPT-4)将普通的推理链改写成Multiverse需要的结构化数据,全程无需人工标注。

算法方面,我们设计了Multiverse Attention机制,让不同路径之间的计算独立。而且它和传统自回归模型(Causal Attention)的注意力差异很小,因此我们仅用3小时的监督微调,就能把一个普通模型变成性能强大的Multiverse模型。
系统方面,我们在工业级引擎SGLang的基础上,重写了一个 Multiverse Engine。它能在生成时实时解析那些控制Token,动态地切换并行模式。用户只需替换引擎,就能无缝享受到动态推理带来的加速。
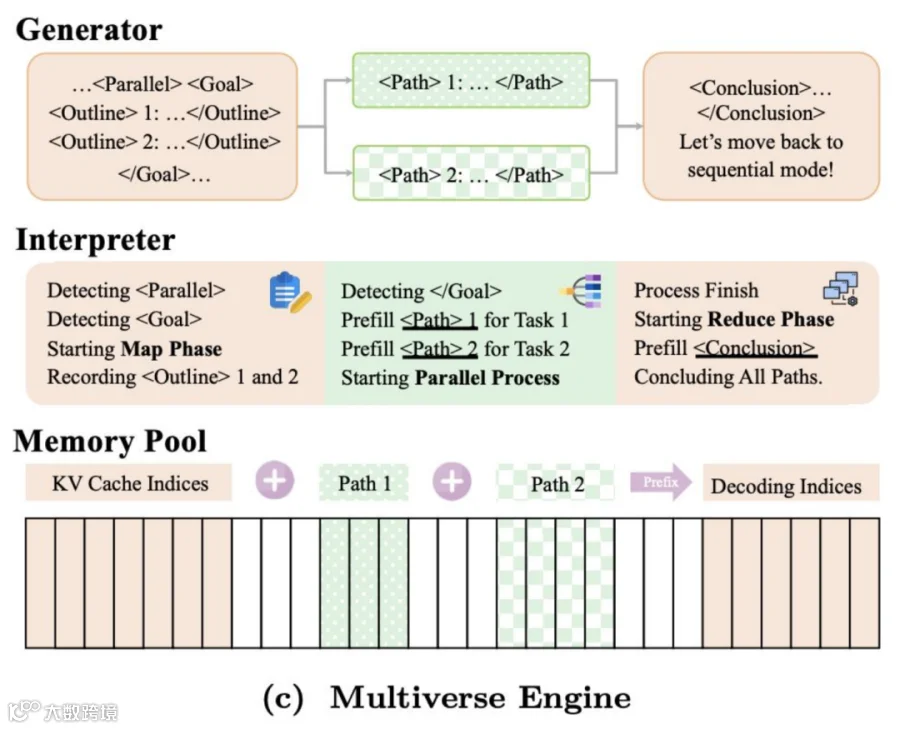

最后和大家同步一下我们近期在做的两个重点工作,主要围绕 APE 和 Multiverse 在系统层面的深度优化。
在APE方面,我们构建了新一代智能体搜索系统。通过将数据库信息预处理为KV Cache并分级存储,实现了超过2倍的加速,能高效处理长文本检索。
在Multiverse方面,我们升级了推理引擎,使其能支持任意有向无环图的动态生成。新引擎具备三大优势:
灵活:支持用户自定义工作流。
高效:通过优化调度与缓存,吞吐量超越现有引擎。
可靠:通过约束解码,杜绝结构性错误。
这两大系统将于近期开源,旨在为推理和智能体应用提供原生的、工业级的结构化支持。
此外,我们也在持续推进前沿探索,主要聚焦于四个方向:
把结构从串并联图扩展到了通用的有向无环图(DAG),这样就能支持更复杂的智能体工作流。
引入了强化学习,让模型自主探索最优的结构,而不仅仅是从数据中蒸馏。
将工具调用更深度地集成到系统中,实现工具的并行与异步处理。
持续研究如何为不同场景高效生成高质量的结构化训练数据。
以上就是我今天分享的主要内容,谢谢大家。


Multiverse在任务间是并行的,但每个任务内部还是自回归的,我这样理解对吗?

对的。我们实现的是任务级别的并行。每个子任务内部,推理过程仍然是顺序的自回归生成。但多个独立的子任务之间,可以实现并行执行。

除了算法上的并行,在GPU硬件上这些分支也是真正同时运行的吗?

是的。多个分支会在GPU上同时运行。而且得益于Prefix KV缓存的共享,这些分支不需要重复加载相同的上下文,显著降低了内存读写开销,提升了整体计算效率。
LUXI
Scholar

您这项工作是否意味着,我们以后可以不用在Coze或LangChain上设计工作流,而是用您的模型端到端完成?

可以这么理解。我们的目标是让模型原生具备动态规划和工作流执行能力。无论是用户预设的静态工作流,还是模型动态生成的规划,Multiverse都能在单一模型内部完成端到端的执行,从而避免多模型组合带来的效率损失和误差累积。

如果模型未训练过某些工具调用(如导航),能否支持?

这取决于它的基座模型有没有这个能力。如果基座模型本身支持工具调用,经过我们训练后,它依然支持;如果基座模型就不会,那需要先在数据里教它。这和训练普通自回归模型是一样的道理。
LUXI
Scholar

ChatGPT也支持多分支生成,Multiverse与它的区别是?

ChatGPT是树结构生成,多个分支中只能选一个继续,本质仍是自回归。我们支持多分支并行执行与合并,适用于需同时完成多个子任务的场景。
LUXI
Scholar

您提到的“前缀”具体指什么?是Prompt吗?

前缀是模型已生成的结构化内容,包括Prompt和之前的推理过程。它在并行分支中共享,作为后续生成的上下文。

能在并行分支里调用外部工具吗?

可以,这也是我们正在做的。在我们的框架下,不同的分支可以并行地、异步地去调用工具,然后等结果回来再继续,这能极大提升智能体任务的效率。
本期陆兮开放夜学术分享会沙龙
在线上线下的热烈交流中圆满结束🎉
感谢Dr.WU和Dr.YANG带来的深度分享
以及所有参与者的积极互动
探索的脚步永不停止
欢迎在评论区继续留言讨论
分享您的见解
我们下期活动再见🍻
往期 回顾