
【AI一周大事件】由陆兮科技根据公开信息整理,盘点每周人工智能、大语言模型、AI应用等领域的政策热点、行业趋势与学术动态。
北京时间3月19日凌晨,在年度GTC大会上,英伟达(Nvidia)首席执行官黄仁勋宣布推出AI超级芯片——Blackwell GB200,将于今年晚些时候发货。
GB200采用新一代AI GPU(图形处理器)Blackwell,是英伟达A100/H100系列AI GPU的继任者。在大语言模型推理工作负载方面,Blackwell的性能相比H100 GPU提升了30倍,能耗却降低了25倍。亚马逊、谷歌、微软和甲骨文将是首批合作伙伴。
此外,黄仁勋还在GTC大会推出了新一款服务软件NIM,下一代AI超级计算机、英伟达Project GR00T 人形机器人基础模型,并宣布扩大与比亚迪等中国车企合作。
“Hopper已经非常出色了,但我们需要更强大的GPU。”黄仁勋在GTC大会上表示。


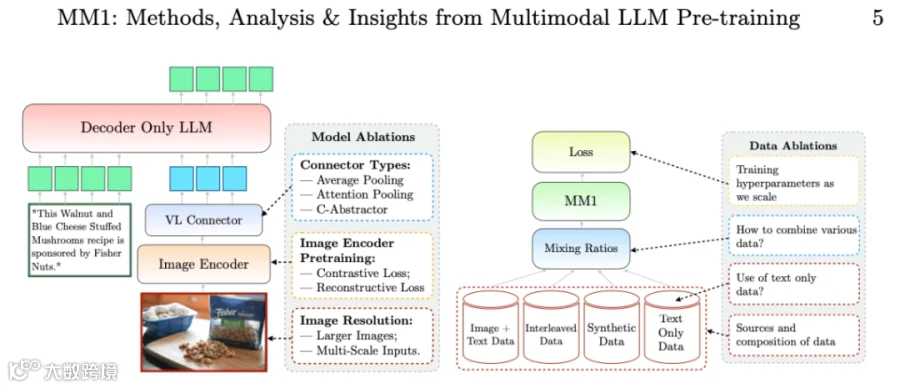
近日,苹果公司研发团队发布了一篇论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》,首次公布了多模态大模型MM1,展示了该公司在AI方面的进展与实力。
据悉,MM1最高参数量为300亿,该模型支持增强的上下文学习和多图像推理,在一些多模态基准测试中有较好表现。
北京时间3月18日,马斯克旗下 AI 初创公司 xAI 宣布,其研发的大模型Grok-1正式对外开源开放,用户可直接通过磁链下载基本模型权重和网络架构信息。
xAI表示,Grok-1 是一个由 xAI 2023 年 10 月使用基于 JAX 和 Rust 的自定义训练堆栈、从头开始训练的3140亿参数的混合专家(MOE)模型,远超OpenAI的GPT模型。而此次开源的模型是 Grok-1 预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微调。

近日,挪威银行 CEO Nicolai Tangen 与微软 CEO Satya Nadella 进行了一场关于科技、企业文化、个人成长和未来趋势的讨论。微软首席执行官萨蒂亚•纳德拉表示,混合现实、人工智能和量子计算是未来数年“塑造”世界的三种开创性技术。
当天早些时候,微软还展示了一款使用人工智能与用户互动的聊天机器人“Ruuh”。目前它已经被应用在Skype和脸书上。历时9月,现在“Ruuh”已经有超过1700万次的谈话记录。

本文讨论了如何构建高性能的多模态大语言模型(MLLM)。作者特别研究了各种架构组件和数据选择的重要性。
通过对图像编码器、视觉语言连接器和各种预训练数据选择进行仔细和全面的消融研究,本文最终确定了几个关键的设计经验。例如,对于大规模多模态预训练,使用仔细组合的图像-标题、交错图像-文本和纯文本数据对于在多种基准上(相比其他已发布的预训练结果)实现最先进(SOTA)的 few shot 结果至关重要。
此外,作者表明图像编码器、图像分辨率和图像 token 数具有重大影响,而视觉-语言连接器设计的重要性相对可以忽略不计。
通过扩展所提出的方案,研究者构建了 MM1,这是一个最多 30B 参数的多模态模型系列,由密集模型和专家混合 (MoE) 变体组成,它们在预训练指标中处于最先进(SOTA)水平,并在一系列既定的多模态基准测试中进行监督式微调后实现了竞争性能。
这项工作介绍了 Gemma,一个轻量级、最先进的开放模型系列,由用于创建 Gemini 模型的研究和技术构建而成。
Gemma 模型在语言理解、推理和安全方面的学术基准上表现出了强劲的性能。研究者发布了两种规模的模型(2B 和 7B),并提供了预训练和微调的检查点。
Gemma 在 18 个基于文本的任务中的 11 个上优于类似大小的开放模型,作者对模型的安全和责任方面进行了全面评估,并详细描述了模型开发。并表明负责任地发布 LLMs 对于提高前沿模型的安全性以及实现下一波 LLM 创新至关重要。
大型语言模型(LLMs)通常会在数十亿个 token 上进行预训练,一般只有在新数据可用时才会重新开始该过程。而更有效的解决方案是持续预训练这些模型,与重新训练相比,可以节省大量计算量。
然而,新数据引起的分布变化通常会导致先前数据的性能下降或对新数据的适应性较差。
在这项工作中,研究者证明了学习率(LR)重新加热、LR 重新衰减和先前数据重播的简单可扩展组合,足以匹配所有可用数据从头开始完全重新训练的性能(通过最终损失和语言模型评估基准来衡量)。
具体来说,研究者展示了两个常用的 LLM 预训练数据集之间弱但现实的分布偏移(英语→英语),以及在具有大数据集大小(数千亿 token)的 405M 参数模型尺度上的更强分布偏移(英语→德语)。选择弱但现实的偏移进行更大规模的实验,作者还发现,本文的持续学习策略与 10B 参数 LLM 的重新训练基线相匹配。
这些结果表明,LLMs 可以通过简单且可扩展的持续学习策略成功更新,仅使用一小部分计算即可匹配重新训练基线。
最后,受之前工作的启发,作者提出了余弦学习率计划的替代方案,有助于规避 LR 重新加热引起的遗忘,并且不受固定 token 预算的约束。
哪些系统/有机体是有意识的?迫切需要新的意识测试(C 测试)。关于意识在人类发育过程中何时产生、何时因神经系统疾病和脑损伤而丧失以及意识如何在非人类物种中分布,一直存在不确定性。
人工智能 (AI)、神经类器官和异种机器人技术的最新快速发展进一步放大了这种需求。尽管近年来提出了许多 C 测试,但大多数用途有限,目前我们还没有针对许多最关键人群的 C 测试。
本文确定了开发 C 测试的任何尝试所面临的挑战,提出了此类测试的多维分类,并确定了可用于验证它们的策略。
意识状态(存在于一种感觉的状态)似乎既丰富又充满细节,并且难以形容或难以完全描述或回忆。尤其是不可言喻(ineffability)的问题,是哲学中一个长期存在的问题,它在一定程度上引发了解释性差距:认为意识不能被简化为潜在的物理过程。
在这里,研究者提供了关于意识的丰富性和不可言喻性的信息论动力系统视角。在本文所提出的框架中,意识体验的丰富性对应于意识状态下的信息量,而不可描述性对应于在不同处理阶段丢失的信息量。
作者描述了工作记忆中的吸引子动态如何导致我们原始经验的贫乏回忆,语言的离散符号性质如何不足以描述经验的丰富和高维结构,以及两个个体认知功能的相似性如何改善了彼此经验的交流。
参考资料:
1.https://baijiahao.baidu.com/s?id=1794117002630358832&wfr=spider&for=pc
2.https://www.tmtpost.com/6960213.html
3.https://www.thepaper.cn/newsDetail_forward_26719427
4.https://baijiahao.baidu.com/s?id=1793777172445366126&wfr=spider&for=pc
5.https://www.nbd.com.cn/articles/2024-03-19/3285468.html
6.https://new.qq.com/rain/a/20240316A01H6K00
7.https://mp.weixin.qq.com/s/u0cUQ1THbt4GegV-eg52cg
(*本文内容由网络公开信息整理而成,不代表陆兮科技官方立场;图片来源于网络,侵权立删)
.END.
