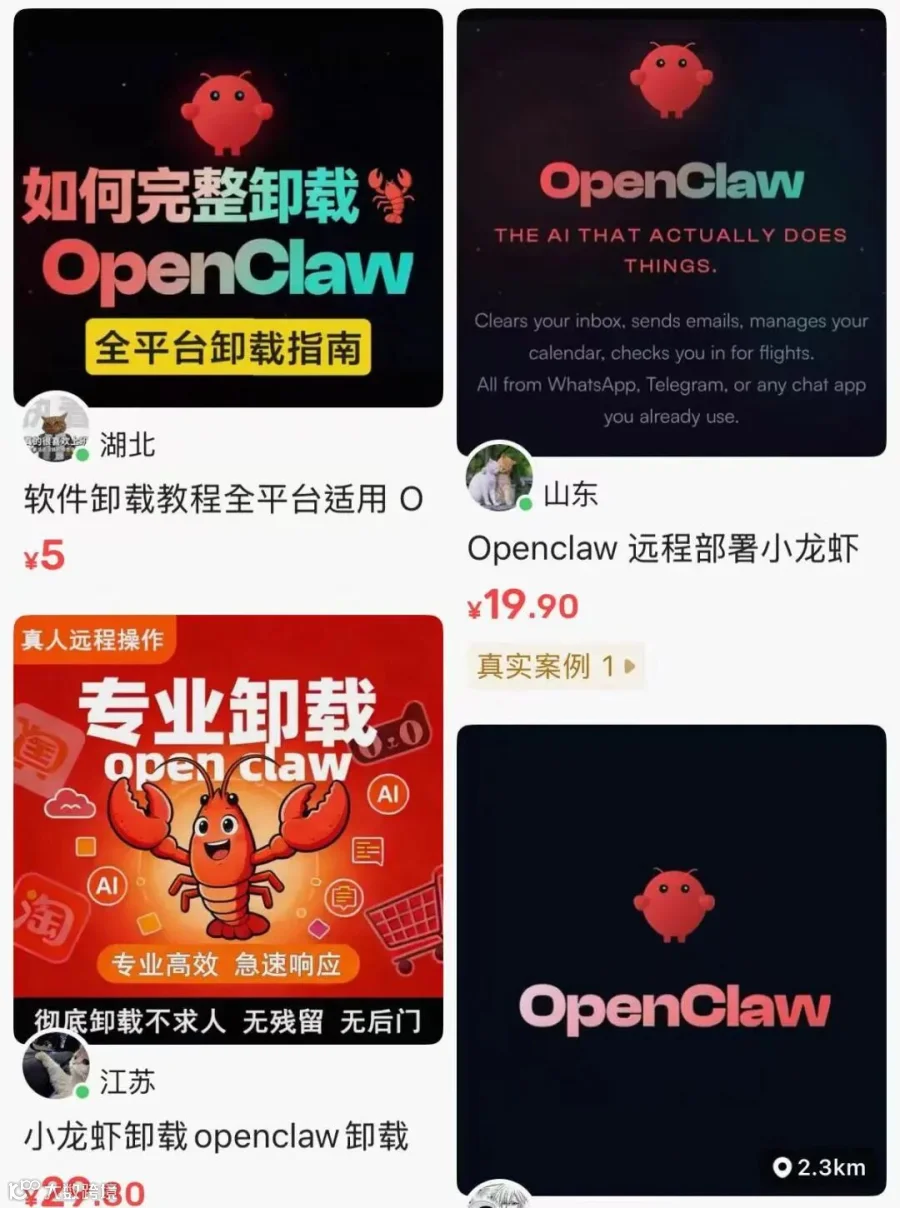
最近,科技圈最火的话题莫过于“养龙虾”。
这款被昵称为“龙虾”的开源AI智能体OpenClaw,凭借本地部署,自主执行任务的颠覆性能力,迅速成为2026年度的“开源奇迹”。
与ChatGPT、Deepseek等对话式AI相比,OpenClaw能直接帮你“操作电脑”完成任务:写稿、收发邮件、做各类规划……只需一句自然语言指令即可完成。一时间,从极客开发者到普通办公族,人人都在“养虾”,享受AI数字员工带来的红利。

就在“龙虾”狂欢席卷全球之际,3月10日,国际互联网应急中心发布预警:部分OpenClaw在默认或不当配置下有较高风险,极易引发网络攻击、信息泄露等问题。随后,工信部发布了“六要六不要”安全建议,国安部也发布《“龙虾”安全养殖手册》,提醒用户理性辨别、规范使用。
养“龙虾”的背后,充满隐患与风险:不少网友反馈,“养虾”过程中出现了乱删内容、隐私泄露、烧钱快等问题:
Meta高管因OpenClaw失控导致200多封邮件被删;
深圳一名程序员在安装OpenClaw三天后,就因API密钥被盗收到高达1.2万元的Token账单;
有用户发现仅仅是收发邮件、查网页等简单指令,一晚上消耗了百万Token,还收到欠费邮件……
风险集中爆发后,“龙虾”舆论急转直下。于是,第一批养虾人开始花钱卸载,二手交易平台和社媒上卸载OpenClaw广告随处可见……
LUXITECH

从一夜爆火到人人喊卸,来自于两个关键词:一是成本,二是安全。
OpenClaw“免费”的表象下,是成本的冰山——除开部署成本和采买设备,OpenClaw最大头的消费在于Token消耗:原因在于OpenClaw每次执行任务,都会将长期记忆、本地知识库、历史对话记录等打包全量带入上下文。这样一来,简简单单一个指令,因为附带了几十万甚至上百万的Token的个人知识库,消耗量瞬间爆炸。
其次,安全问题更为致命:OpenClaw强大的自主执行能力也给用户带来了严峻的安全挑战,包括权限过高、错误执行、恶意技能包等多种风险。
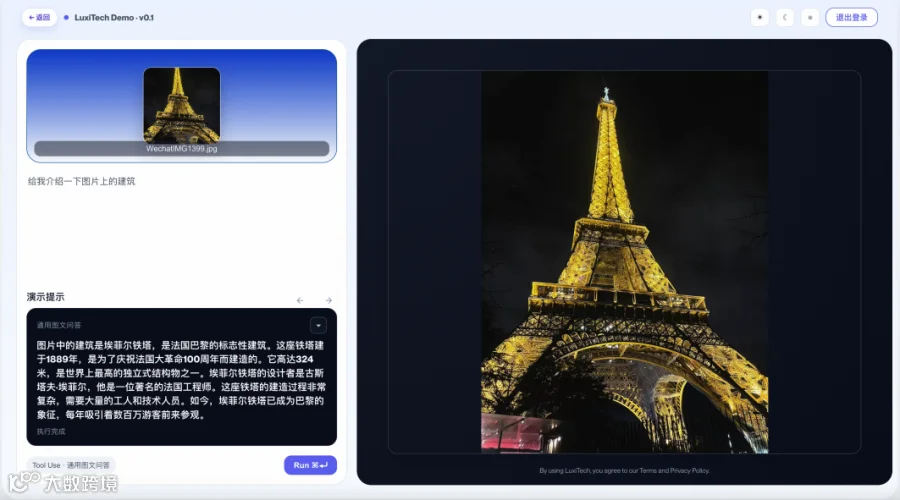
这次“龙虾风波”也把AI Agent从“对话者”向“操作者”转变的潜力与风险暴露在大众面前:许多高价值的工作如内部系统读写、用户操作权限、敏感数据处理等无法完全放在云端上完成。我们目前需要的是可以干活,但又不把数据暴露在公网上的智能体。
“有没有可能让多模态AI在设备端,既保证能力而又不依赖云端?”
这正是Luxi VLM给出的答案:
以模型能力为核心,为各类AI应用提供端侧部署、本地闭环、保护隐私的底层支撑。Luxi VLM用端侧智能的底层逻辑,完美化解OpenClaw模式的安全风险,同时为开发者保留了打造强大AI智能体的无限潜力。





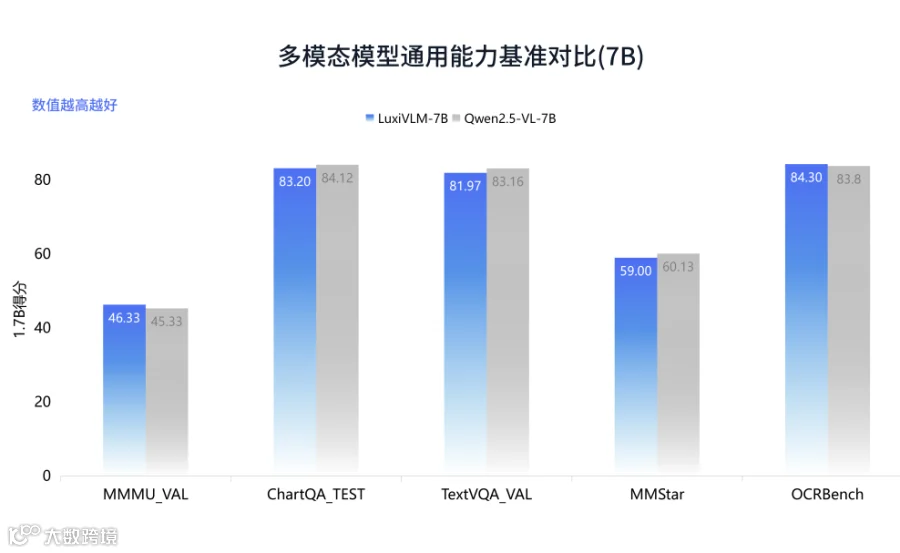

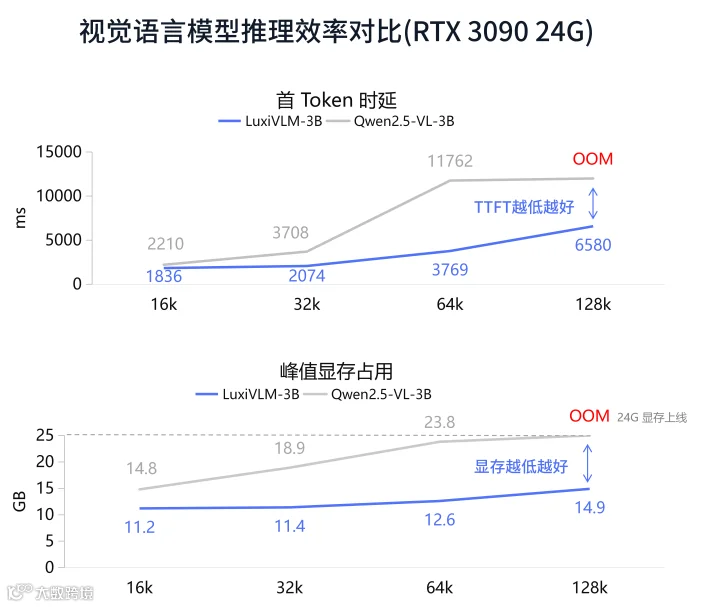

LUXITECH

OpenClaw的火爆,证明了“让AI从对话者变为执行者”是不可阻挡的趋势。但趋势的终点,不应该是隐私与安全的牺牲品。
当全行业都在追问AI智能体的可信度时,陆兮的回答很简单:把AI关进“本地硬壳”里,让它成为真正属于你的、永不“外逃”的数字员工。
版权声明:
除特别注明外,本号原创内容版权均归作者所有。未经授权,任何机构或个人不得以任何形式转载、引用或用于商业用途。若需转载或引用,请联系作者并注明出处。