摘要:
阿里云 EMR Serverless StarRocks 是一款全托管、存算分离的湖仓 OLAP 引擎。它原生集成全文检索 + 标量过滤 + 向量近邻搜索的三路融合查询能力,支持在 Paimon / Iceberg / Lance 等开放湖格式上直接进行多模态混合检索,一条 SQL 即可完成"关键词匹配 + 条件约束 + 语义相似"的联合召回。
技术实现:全文通道(倒排索引 + BM25 排序)与向量通道(HNSW / IVFPQ / DiskANN 近邻索引)并行召回,经 RRF(Reciprocal Rank Fusion)/ 加权融合 / 学习排序进行 Re-Rank,并结合标量谓词 In-Filter 深度优化同步执行;检索结果通过列级回写(Partial Update)直接打标回写源表,全程数据不出湖。
核心优势:三路检索在引擎内融合评分排序(而非分别召回再拼接),召回率提升 30% 以上;自研 Native Reader/Writer 湖表读写性能业界领先;一套引擎一套存储,成本对比传统多系统方案降低 60%;Serverless 存算分离按需计费、零闲置成本。
典型场景:自动驾驶 Corner Case 挖掘与训练数据集构建、多模态电商搜索、RAG 知识库增强、内容安全审核、医疗影像检索。

01
AI 团队在海量非结构化数据中筛选训练数据集时,一次查询往往同时包含三个维度的需求:
|
|
|
|
以自动驾驶场景为例,算法工程师的典型需求是:
"从历史路采数据中,找到描述里提到 'construction zone' 的、天气为暴雨、道路类型为城市道路的、与当前误判场景视觉上最相似的 Top-100 张图片,打标后直接送去训练。"
传统方案需要三套系统协作:Elasticsearch 管全文、向量数据库管相似度、分析引擎管标量过滤,数据在三者之间反复搬运,链路长、一致性难保障,结果拼接后还可能凑不满 K 条。
阿里云 EMR Serverless StarRocks 的方案:一个引擎、一条 SQL、一次完成全部动作。
02
1. 整体架构
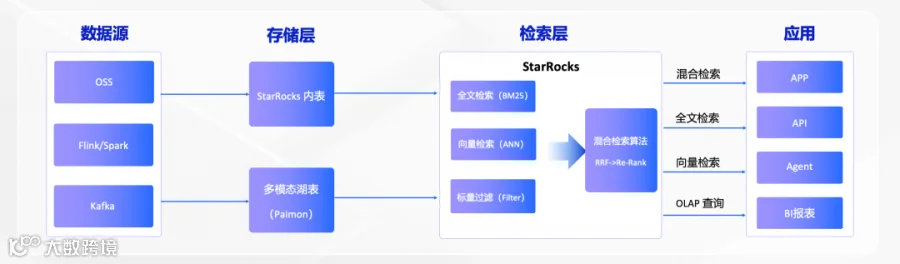
图 1:从数据源到应用的多模态混合检索整体架构
2. 三种检索能力详解
3. 检索融合算法:RRF → Re-Rank
传统方案将三路检索分别执行后在应用层拼接,StarRocks 则在引擎内部完成融合:
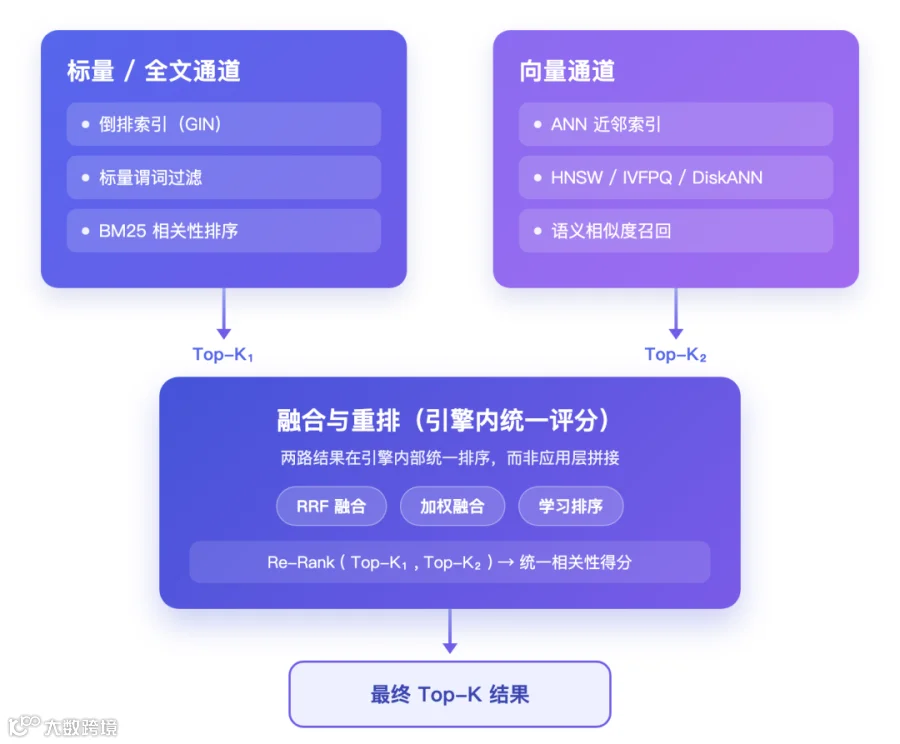
图 2:两路并行召回 → 引擎内 RRF 融合重排 → 最终 Top-K
4. 关键技术差异(vs 分别召回再拼接的方案)
03
1. 在 Paimon 湖表上创建三种索引
-- 创建 Paimon 湖表CREATE TABLE ai_dataset.scene_data (id BIGINT,path STRING, -- OSS 图片路径description STRING, -- 场景描述文本weather STRING, -- 天气标签road_type STRING, -- 道路类型time_of_day STRING, -- 时段has_pedestrian BOOLEAN, -- 是否包含行人speed DOUBLE, -- 车速scene_tag STRING, -- 场景标签embedding ARRAY<FLOAT> -- 图片向量(1024维)) USING paimonTBLPROPERTIES ('row-tracking.enabled' = 'true','data-evolution.enabled' = 'true');-- 向量索引:支持 HNSW / IVFPQ / DiskANNCREATE INDEX idx_vec ON ai_dataset.scene_data (embedding)USING VECTOR ("index_type" = "HNSW","dim" = "1024","metric_type" = "cosine");-- 全文索引:倒排索引 + BM25 排序CREATE INDEX idx_desc ON ai_dataset.scene_data (description)USING GIN;-- 标量索引:加速高频过滤字段CREATE INDEX idx_weather ON ai_dataset.scene_data (weather) USING BITMAP;CREATE INDEX idx_road ON ai_dataset.scene_data (road_type) USING BITMAP;
一张表上同时具备全文、向量、标量三种索引能力,查询时自动协同。
2. 三路融合检索
-- 三路融合:全文关键词 + 标量条件 + 向量相似度,一条 SQL 完成SELECTid, path, description, weather, road_type,approx_cosine_similarity(embedding, @query_vector) AS similarityFROM ai_dataset.scene_dataWHERE description MATCH 'construction zone' -- 全文检索(BM25)AND weather = '暴雨' -- 标量过滤AND road_type = '城市道路' -- 标量过滤AND time_of_day = '夜间' -- 标量过滤ORDER BY similarity DESCLIMIT 100;
执行逻辑:Lake Optimizer 自动将标量条件前置,Bitmap 索引先将候选集从亿级收窄到万级;GIN 索引在候选集上做 BM25 全文匹配;HNSW 索引在过滤后的范围内做向量近邻搜索;RRF 算法将全文分数与向量相似度统一融合排序,返回最终 Top-K。
3. 检索结果直接回写源表
检索完成后,用 Partial Update 直接给命中的记录打标,不触碰其它列:
-- 列级回写:只更新 scene_tag 列,不影响原始数据UPDATE ai_dataset.scene_dataSET scene_tag = 'corner_case_rain_urban_night'WHERE id IN (SELECT idFROM ai_dataset.scene_dataWHERE description MATCH 'construction zone'AND weather = '暴雨'AND road_type = '城市道路'ORDER BY approx_cosine_similarity(embedding, @query_vector) DESCLIMIT 100);
写放大极小,支持多轮迭代打标。下游 Spark 训练任务直接从同一张 Paimon 表读取,数据全程不出湖。
04
感知模型在恶劣天气下表现不佳,需要大量长尾场景数据重训练。但路采数据中这类场景占比极低(< 0.1%),人工逐帧筛选效率极差。以下演示用 阿里云 EMR Serverless StarRocks 完成"选种子图 → 三路混合检索召回 → 打标回写 → 交付训练集"的全链路。
Step 1:路采数据入湖
上游 Spark 通过 AI Function 批量处理路采图片,生成标签和向量后写入 Paimon 湖表:
-- Spark 批量入湖(上游完成)INSERT INTO ai_dataset.scene_dataSELECTmonotonically_increasing_id() AS id,path,ai_query('描述图片中的驾驶场景,包括天气、道路、车辆、行人等要素',service_name => 'qwen-vl-plus', data => content) AS description,ai_query('判断天气:晴天/多云/小雨/暴雨/大雾/雪天',service_name => 'qwen-vl-plus', data => content) AS weather,ai_query('判断道路类型:高速/城市道路/乡村道路',service_name => 'qwen-vl-plus', data => content) AS road_type,ai_query('判断时段:白天/夜间/黄昏',service_name => 'qwen-vl-plus', data => content) AS time_of_day,ai_query('图片中是否包含行人:true/false',service_name => 'qwen-vl-plus', data => content) AS has_pedestrian,NULL AS speed,NULL AS scene_tag,ai_embedding_multimodal(content,service_name => 'tongyi-embedding-vision-plus') AS embeddingFROM read_files('oss://ad-raw/camera_front/2025-*/', suffix => 'jpg,png');
Spark 写入完成后,StarRocks 通过 Native Reader 直接读取同一份 Paimon 数据,无需同步。
Step 2:选种子图
从已知的误判案例中选取典型种子,作为向量检索的查询锚点:
-- 找到那次典型误判帧的 embedding,作为种子SELECT embeddingFROM ai_dataset.scene_dataWHERE path = 'oss://ad-raw/camera_front/2025-10-15/frame_003812.jpg';
Step 3:三路混合检索召回
以种子图为锚点,同时用全文关键词、标量标签、向量相似度三路召回:
-- 召回"描述中提到施工区 + 暴雨 + 城市道路 + 有行人"的最相似 Top-200SELECT id, path, description, weather, road_type, has_pedestrian,approx_cosine_similarity(embedding, @seed_embedding) AS similarityFROM ai_dataset.scene_dataWHERE description MATCH 'construction' -- 全文:描述中提到施工AND weather = '暴雨' -- 标量:暴雨天气AND road_type = '城市道路' -- 标量:城市道路AND has_pedestrian = true -- 标量:有行人ORDER BY similarity DESCLIMIT 200;
为什么 In-Filter 在这里至关重要:传统方案先取向量 Top-200,再过滤标量条件,暴雨 + 城市道路 + 有行人可能只占 2%,过滤后只剩 4 条。In-Filter 在向量搜索过程中同步执行标量过滤,保证结果一定满 200 条。
Step 4:批量多场景召回 + 打标回写
一次作业批量召回多种 Corner Case,直接打标回写源表:
-- 场景1:暴雨 + 施工区 + 夜间UPDATE ai_dataset.scene_dataSET scene_tag = 'rain_construction_night'WHERE id IN (SELECT id FROM ai_dataset.scene_dataWHERE description MATCH 'construction'AND weather = '暴雨' AND time_of_day = '夜间'ORDER BY approx_cosine_similarity(embedding, @seed_1) DESCLIMIT 200);-- 场景2:大雾 + 高速 + 有行人UPDATE ai_dataset.scene_dataSET scene_tag = 'fog_highway_pedestrian'WHERE id IN (SELECT id FROM ai_dataset.scene_dataWHERE description MATCH 'highway'AND weather = '大雾' AND has_pedestrian = trueORDER BY approx_cosine_similarity(embedding, @seed_2) DESCLIMIT 200);-- 场景3:雪天 + 乡村道路UPDATE ai_dataset.scene_dataSET scene_tag = 'snow_rural'WHERE id IN (SELECT id FROM ai_dataset.scene_dataWHERE weather = '雪天' AND road_type = '乡村道路'ORDER BY approx_cosine_similarity(embedding, @seed_3) DESCLIMIT 300);
Partial Update 只写 scene_tag 这一列,写放大极小。多轮迭代打标不影响原始数据。
Step 5:训练集质量分析
利用 StarRocks 的 OLAP 分析能力,直接在同一张表上做训练集质量评估:
-- 各场景召回数量与相似度分布SELECTscene_tag,COUNT(*) AS sample_count,AVG(approx_cosine_similarity(embedding, @seed_1)) AS avg_similarity,MIN(approx_cosine_similarity(embedding, @seed_1)) AS min_similarityFROM ai_dataset.scene_dataWHERE scene_tag IS NOT NULLGROUP BY scene_tagORDER BY sample_count DESC;-- 检查是否有标签冲突(同一张图被多个场景命中)SELECT id, path, COUNT(DISTINCT scene_tag) AS tag_countFROM ai_dataset.scene_dataWHERE scene_tag IS NOT NULLGROUP BY id, pathHAVING tag_count > 1;
Step 6:下游直接消费
下游 Spark 训练任务直接读取同一张 Paimon 表,按 scene_tag 筛选训练数据:
-- Spark 下游直接消费(无需数据搬运)SELECT * FROM ai_dataset.scene_dataWHERE scene_tag IN ('rain_construction_night', 'fog_highway_pedestrian', 'snow_rural');
全链路闭环:Spark 写入 → StarRocks 检索打标 → Spark 消费训练,数据始终在同一张 Paimon 表上,零搬运、零冗余副本。
05
1. 业务背景
在大模型时代,企业真正稀缺的不再是算力,而是“能持续供给高质量训练与检索数据的底层数据平台”。无论是自动驾驶的路采图像、电商的商品图文、内容平台的音视频,还是金融风控的单据影像,几乎每一个做 AI 的团队都会遇到同一组难题:原始数据以图片、文本、音视频等多模态形式散落在对象存储中,规模动辄数十亿;而模型训练、RAG 知识库、智能体(Agent)应用又需要从中反复筛选、加工出一个个高质量子集——这意味着对同一份数据要不断地做“语义检索 + 标签过滤 + 相似召回”,并把结果沉淀回去复用。
在以往的架构实践中,为了兼顾结构化查询、全文检索及向量相似度匹配等不同需求,数据往往需要在对象存储、搜索引擎、专用检索引擎及数仓等多个系统间流转和同步。这种多系统协同的模式容易带来数据冗余、存储成本上升、链路复杂以及维护口径不一致等挑战,导致 AI 工程师大量时间耗在“搬数据、对数据”而非“用数据”上。这正是阿里集团 AI Data 平台要解决的核心问题——它承担两大目标:为大模型训练准备数据、为上层 AI 应用提供高质量数据,并据此提出了四条硬性要求:
低成本:避免一份数据多处冗余存储带来的成本膨胀;
一份数据:训练、检索、分析共享同一份湖上数据,杜绝多副本与口径漂移;
开放性:基于开放湖格式,避免被任何单一系统或厂商锁定;
准实时:数据写入后能尽快被检索和消费,支撑快速迭代的数据闭环。
在选型上,阿里云 EMR Serverless StarRocks + DLF Paimon 架构此前已在阿里集团多个核心业务大规模落地并验证了稳定性与性价比。AI Data 团队的判断是:与其为 AI 多模态场景另起炉灶引入一套新系统,不如复用同一套成熟技术栈,把它从结构化 BI 分析自然延伸到多模态混合检索。这样既能沿用既有的运维体系、数据资产和工程经验,又能让 BI 分析、AI 应用、Data Agent 三类负载统一架构、共享一份数据——这也是任何希望低成本构建 AI 数据底座的企业都可以借鉴的路径。
2. 技术架构
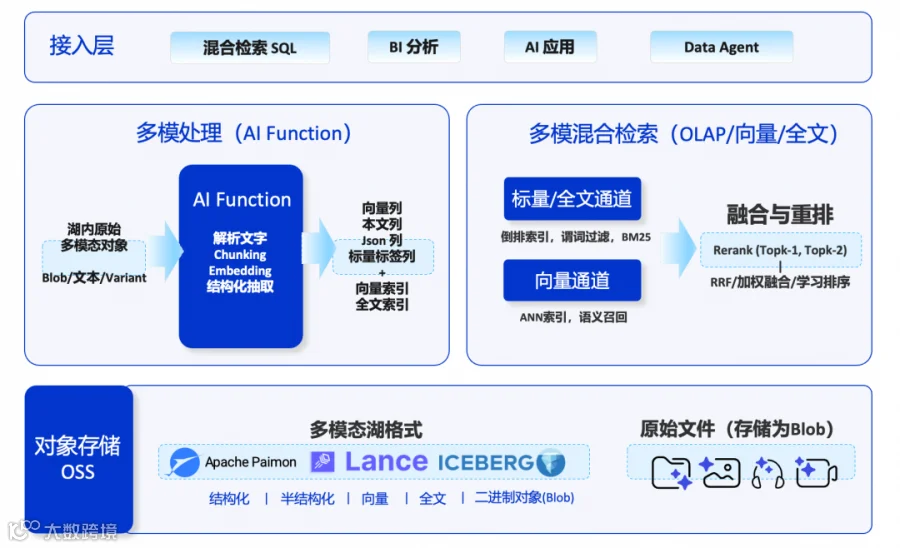 图 3:AI Data 多模态数据湖与混合检索技术架构
图 3:AI Data 多模态数据湖与混合检索技术架构
3. 业务价值
4. 全链路数据流
1. 湖内原始对象(OSS 上的 Blob / 文本 / Variant)→ AI Function 自动处理(解析文字、Chunking、Embedding、结构化抽取)
2. 生成向量列、文本列、JSON 列、标量标签列,同步构建向量索引和全文索引
3. 混合检索 SQL 通过标量 / 全文通道 + 向量通道并行召回,RRF 融合重排
4. 检索结果通过 Partial Update 直接打标回写源湖表
5. 下游 BI 分析 / AI 应用 / Data Agent 直接消费同一份数据
06
1. 多模态电商搜索
用户上传穿搭图片,同时输入文字描述"通勤风 连衣裙":
SELECT product_id, title, price, image_url,approx_cosine_similarity(embedding, @image_vector) AS visual_simFROM mall.productsWHERE description MATCH '通勤 连衣裙' -- 全文:匹配商品描述关键词AND category = '女装' -- 标量:品类AND price BETWEEN 200 AND 800 -- 标量:价格区间AND stock_qty > 0 -- 标量:有库存ORDER BY visual_sim DESCLIMIT 20;
返回的商品既"看得懂文字"、又"看得像图片"、还"买得到"。
2. RAG 知识库实时问答
企业知识库中按语义、关键词和权限三重条件检索最相关文档片段:
SELECT chunk_id, title, content,approx_cosine_similarity(embedding, @question_vector) AS relevanceFROM kb.doc_chunksWHERE content MATCH '退款流程 发票' -- 全文:关键词命中AND dept IN ('财务部', '客服部') -- 标量:知识域限定AND access_level <= 2 -- 标量:权限过滤AND publish_date >= '2025-01-01' -- 标量:时效性ORDER BY relevance DESCLIMIT 5;
一条 SQL 返回"语义最相关 + 关键词命中 + 有权限 + 时效内"的知识片段,直接交给 LLM 生成回答。
3. 内容安全:违规内容相似检索
发现一条违规内容后,从历史库中快速定位同类内容:
SELECT content_id, content_type, risk_level,approx_cosine_similarity(embedding, @violation_vector) AS similarityFROM safety.content_poolWHERE description MATCH @violation_keywords -- 全文:违规关键词AND content_type = 'image' -- 标量:内容类型AND status = 'published' -- 标量:仍在线的内容ORDER BY similarity DESCLIMIT 50;
4. 医疗影像:相似病例检索
医生从历史影像库中检索相似病例,同时约束临床条件:
SELECT case_id, patient_age, diagnosis, report_summary,approx_cosine_similarity(embedding, @current_scan) AS similarityFROM medical.imaging_casesWHERE report_summary MATCH '结节 磨玻璃' -- 全文:报告关键词AND body_part = '肺部' -- 标量:检查部位AND diagnosis_category = '疑似恶性' -- 标量:诊断分类ORDER BY similarity DESCLIMIT 10;
03
阿里云 EMR Serverless 同时提供 StarRocks 和 Spark 两种引擎的混合检索能力,二者互补:
最佳组合——数据不出湖的全链路闭环

图 4:Spark 离线写入 → StarRocks 在线检索打标 → Spark 下游消费,全程同一份湖数据
08
1. 三路融合,行业领先
全文(BM25)+ 标量 + 向量在引擎内部经 RRF / 加权融合 / 学习排序统一评分,非分别召回再拼接。In-Filter 深度优化保证标量过滤与向量检索同步执行,召回率提升 30% 以上,结果数量可控。
2. One Data,数据不出湖
直读直写 Paimon / Iceberg / Lance 湖表,检索结果通过 Partial Update 直接回写源表。上游 Spark 写入、StarRocks 检索、下游训练消费,全程在同一份数据上完成,零搬运、零冗余副本。一套引擎一套存储,成本对比传统方案降低 60%。
3. 湖上读写,业界领先
自研 Native Reader/Writer 直接解析湖表文件,配合 Lake Optimizer 针对文件布局定制查询规划,多级缓存 + 智能预取,开放湖格式上的读写性能保持领先。
4. 多模态数据原生支持
支持 Paimon / Lance / Iceberg 等主流湖格式,统一存储结构化、半结构化、向量、全文、二进制对象(Blob)五种数据形态。AI Function 直接在湖内完成解析、Chunking、Embedding、结构化抽取,无需外部 Pipeline。
5. Serverless 存算分离,按需付费
计算资源按查询负载弹性伸缩,无任务时零计算费用。索引随数据存储在湖上,扩缩容无需重建。
09
1. 前置条件
2. 三步完成混合检索
-- Step 1: 建表CREATE TABLE my_db.docs (doc_id BIGINT,title STRING,content STRING,category STRING,embedding ARRAY<FLOAT>) USING paimon;-- Step 2: 建索引CREATE INDEX idx_vec ON my_db.docs (embedding)USING VECTOR ("index_type"="HNSW", "dim"="768", "metric_type"="cosine");CREATE INDEX idx_ft ON my_db.docs (content) USING GIN;CREATE INDEX idx_cat ON my_db.docs (category) USING BITMAP;-- Step 3: 三路融合检索SELECT doc_id, title,approx_cosine_similarity(embedding, @query_vector) AS scoreFROM my_db.docsWHERE content MATCH '退款 发票'AND category = '财务'ORDER BY score DESCLIMIT 10;
常见问题(FAQ)
Q1:三路融合检索的性能如何?
A:得益于 In-Filter 优化和 Lake Optimizer,标量条件前置大幅收窄搜索范围后再做全文匹配和向量运算,亿级数据混合检索通常在亚秒 ~ 秒级完成。
Q2:支持哪些向量索引算法?
A:支持 HNSW、IVFPQ、DiskANN 等主流算法。HNSW 适合高召回率场景,IVFPQ 适合超大规模向量(内存受限),DiskANN 适合磁盘存储的大规模向量检索。
Q3:全文检索支持哪些语言?
A:支持中文和英文分词,可通过 GIN 索引配置分词器。中文默认使用 jieba 分词,英文使用标准分词器。
Q4:支持哪些湖表格式?
A:支持 Apache Paimon、Apache Iceberg、Lance 等主流开放湖格式,统一存储结构化数据、向量、全文、半结构化数据和 Blob 对象。
Q5:Partial Update 回写会影响其他列或其他引擎的读取吗?
A:不会。Partial Update 只更新指定列,不触碰原始数据列。回写后其他引擎(如 Spark)立即可见更新结果,数据一致性由湖表事务机制保障。
欢迎加入 EMR Serverless StarRocks 客户交流钉钉群,在群直播回放中查看完整直播的 demo 演示,第一时间获取产品最新动态,并与阿里云专家、开发者们一起交流 Agentic Lakehouse 的实践。