

中国建投原创文章
中国建投直接投资部
作者:乔林
本文3383字,阅读时间8分钟
近两个月来,全球投资界最热门的概念之一,莫过于“HBM”(高带宽内存芯片)。AI大模型的训练和推理都高度依赖HBM,英伟达CEO黄仁勋曾公开表示,当前最主要的供应链瓶颈正是HBM内存,其次才是台积电的CoWoS先进封装产能。这也解释了为何全球HBM龙头企业SK海力士在短短两年多时间内市值增长十倍。
然而,一家名为Cerebras的年轻公司近日宣称,大模型不再需要HBM了。
这家公司并非空口无凭。5月14日,Cerebras在纳斯达克上市,当日市值逼近千亿美元。历史上,仅有Meta等少数顶级科技企业曾取得这般成绩,Cerebras也成为2019年Uber上市以来最大的科技IPO。值得注意的是,小特朗普和OpenAI CEO奥特曼都是其重要投资人。
那么,Cerebras究竟做了些什么?本文尝试用通俗易懂的方式,拆解这一技术领域,帮助读者理解其背后的逻辑与影响。
一
为什么HBM对于大模型推理和训练如此重要?

先来理解HBM的重要性,才能看清Cerebras带来的变化。
可以做一个简化的比喻:大模型的训练,好比一群建筑工人在有限的市中心空地上(GPU)盖楼房(大模型),同时需要持续不断地将建筑材料(数据)运送到现场。AI服务器面临的核心难题在于,GPU计算速度太快,而数据传输速度跟不上,导致GPU经常处于“等数据”的状态。
理想情况下,如果所有材料都能堆在工人手边,效率自然最高。但问题在于,芯片面积有限,无法容纳那么多数据缓存。目前的做法是,在芯片内部设置高速SRAM(静态随机存储器)作为临时堆放点,工人可以自行取用。但SRAM容量太小,只能存放极少数据。于是,又在芯片旁边划出一小块空地,建一个临时仓库(DRAM,动态随机存储器),并雇佣搬运工不停地在仓库和工地之间运输数据。
过去十余年,这一领域的技术突破主要围绕如何提升数据传输效率展开。解决方案主要有两条:一是把仓库“叠起来”,工程师们发明了堆叠技术,将多层DRAM堆叠在一起,即HBM,并用数千个微米级的TSV(硅通孔)垂直连接,实现多层仓库之间的快速运输;二是多雇佣搬运工,建立多个数据传输通道,形成高带宽。
这些步骤看似简单,但实际在芯片纳米尺度上存在大量技术难关,例如通孔不能有气泡、数千条线路高速传输时互不干扰、堆叠导致散热难度指数级上升、堆叠层数越多良率下降越快等。三星和SK海力士联合研发4年才做出首个HBM样品,这也是两家公司占据全球近80%市场份额、建立深厚技术壁垒的原因。当前主流AI芯片的架构,本质上就是一块GPU周围堆叠一圈HBM,后者向前者不断输送数据。
而Cerebras提出,不再需要HBM了。
二
Cerebras做了什么?

既然现有AI芯片的核心工作围绕数据传输展开,Cerebras的解决方案是:别传输了,把数据全部放在计算核心旁边。回到上面的比喻,就是成倍扩大建设用地,把所有材料都堆在楼下,自然就不再需要仓库(HBM)了。SRAM的特点是紧挨计算核心,传输速度极快,但面积数倍于DRAM。那么,把芯片做大,多用SRAM,问题不就解决了吗?
事情并没有这么简单。
如果如此容易,Cerebras就不会成为破局者。近几十年来,芯片工艺的发展路径一直是朝着“小芯片拼装”(chiplet)模式演进:在一大块晶圆上制造出几百块图案完全相同的小芯片,然后切割成独立的小芯片。这样做的根本原因在于,晶圆不可能完美无瑕。
整个晶圆制造过程需要数千道工序、历时数月,即便在洁净度极高的先进晶圆厂,也无法做到零缺陷。任何微尘、材料缺陷、光刻误差都可能导致芯片失效。如果一整块晶圆就是一个芯片,那么任何一点瑕疵就会导致整颗芯片报废,且芯片面积越大,良率下降越快。而采用小芯片拼装工艺,即使部分芯片损坏,其余芯片仍然可以独立使用。
而Cerebras的方案恰恰相反:严格来说,是以一整块矩形晶圆为一颗芯片,将大量大容量超高速SRAM直接做到晶圆上,而它服务的核心既不是GPU也不是CPU,而是一种定制的数据流处理器。通俗理解就是:把无数个极小的、高度定制化的处理器,以GPU的超大规模并行方式,密密麻麻地平铺在一整块晶圆上,让大量SRAM紧挨着这些处理器运送数据,从而彻底解决传统AI芯片的数据传输瓶颈。
Cerebras推出的WSE芯片与目前最大的GPU芯片对比
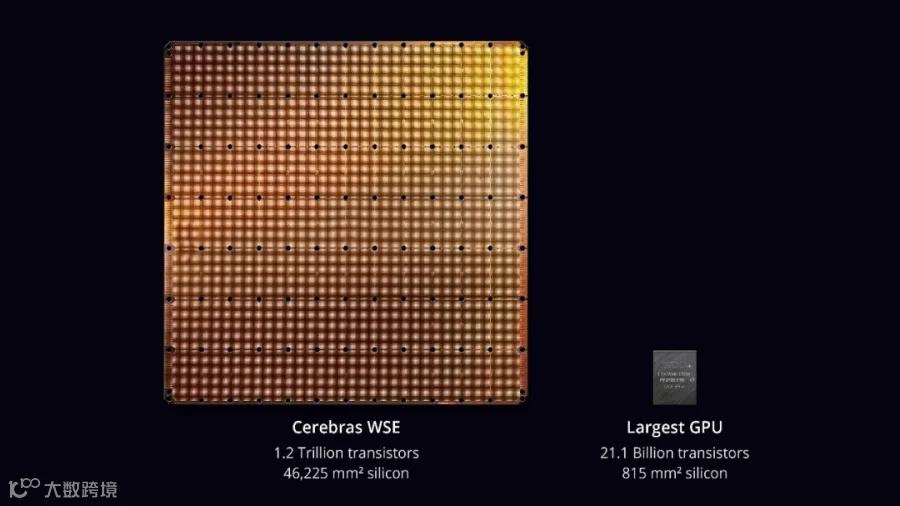
资料来源:Cerebras招股说明书
三
Cerebras的芯片有哪些开创性突破?

首先,如何解决大晶圆不可避免的缺陷问题?Cerebras的答案是“冗余设计+可绕行互联”。简单来说,在大晶圆上预留大量冗余计算核心和冗余通信路径,如果某一小块出现故障,系统会自动绕行。这是其芯片能够实现商业化量产的核心原因。
其次,Cerebras的芯片架构在制造上面临诸多技术挑战。例如光刻机的曝光限制——由于光罩尺寸有限,如此大的芯片无法一次曝光完成,需要通过晶圆拼接曝光,不同区域之间要实现纳米级精确对齐。
再如供电和散热问题:一整片晶圆的电压和电流波动巨大且分布不均,晶圆中心容易形成热岛,导致性能下降和时钟不稳定。Cerebras采用了特殊液冷方案和分布式功耗管理等措施来应对。尽管Cerebras是一家芯片设计公司,但为了解决这些困难,它需要联合晶圆制造厂商台积电提供一整套成熟解决方案。
Cerebras的成就并不在于“做大芯片”这个想法,而在于“让超大芯片还能稳定工作”。其WSE芯片已经迭代三代,成功销售给美国国家实验室、全球超算中心、OpenAI、亚马逊云服务、阿斯利康、阿联酋AI中心等多个政府机构和大型企业。由于极低的延迟特性,该芯片在AI推理领域相比传统AI芯片具有明显优势。
四
Cerebras会动摇谁的根基?

熟悉芯片行业生态的人可能会产生疑问:Cerebras是否会动摇英伟达+SK海力士+三星+美光这一产业路线的龙头企业?毕竟,它不再需要GPU和HBM,而且商业化路径已经跑通。
从当前行业现状来看,二者并未形成直接竞争,也不存在替代的可能性。
Cerebras芯片单颗成本远高于英伟达AI芯片,受限于制造成本高昂、良率偏低、量产规模有限,在相当长一段时间内只能定位高端市场,服务对成本敏感度较低、对推理速度要求较高的客户。
同时,其采用全新软件架构,而当前AI行业基本已通用CUDA生态和英伟达工具链,二者开发者生态差异巨大,客户迁移成本极高。此外,由于其散热要求高,Cerebras芯片需要配备特殊液冷、供电、机架和互连系统,相当于构建一个全新的数据中心。这些因素都决定了Cerebras芯片现阶段难以全面铺开。
可以认为,Cerebras的目标并非通用GPU市场。从其优劣势来看,它更像是AI时代的超级计算机路线,在部分应用场景中可以最大化其优势。
短期来看,资本市场目前也验证了这一判断:Cerebras上市后,英伟达、SK海力士等“GPU+HBM”传统技术路线的龙头企业,股价基本未受到明显影响。现在谈“颠覆”为时尚早,顶多可以视作“将传统的以GPU+HBM为唯一解决方案的AI生态,撕开了一个裂缝”。至于这一“裂缝”后续如何演化,值得投资者持续关注和思考。
五
对投资人的启示

从投资视角看,Cerebras更值得关注的,或许是其背后所反映的产业趋势变化。
第一,HBM产业链仍大有可为。 尽管Cerebras现阶段并未动摇传统英伟达生态在AI训练推理中的主导地位,但这并不意味着HBM路线没有更大发展空间。一种可能的趋势是,AI芯片路线开始分化为两条:一条是英伟达代表的GPU+HBM路线,另一条是更大SRAM、更少数据搬运的大系统路线。
第二,推理市场值得更多关注。 Cerebras之所以获得资本市场认可,核心在于它没有与英伟达在大模型训练领域正面竞争,而是主打大规模、极致速度的推理。当前训练市场格局基本固化,但推理市场才刚刚起步。随着智能体(Agent)、长文本、实时语音和多模态应用的爆发,推理算力的消耗将呈指数级增长。未来在算力芯片、中间件、网络优化乃至边缘算力等领域的投资,可以更多关注“推理能效比”和“低延迟”方面的绝对优势。
第三,芯片设计公司的系统级交付能力日益重要。 Cerebras销售的并非一块块可以插入别人服务器的芯片,而是集成了散热、供电、组网甚至自身云服务的整体硬件超算系统。纯芯片设计初创公司的生存空间正被龙头企业挤压,未来评估芯片或硬件项目时,应重点考察其“系统级交付”能力,而非仅仅关注跑分性能。创始人需要围绕软硬一体化系统如何降低客户部署门槛、如何兼容PyTorch等软件生态进行清晰论述,这往往是硬件估值的溢价来源。
第四,先进封装的重要性持续提升。 Cerebras的芯片对晶圆级封装提出了大量新的技术要求。先进封装已不再是简单的“后道工艺”,而是开始成为“决定芯片架构边界”的核心能力。封装正在成为系统设计的一部分,逐步摆脱其“低附加值”的传统定位。在高密度互联、热管理等子领域,新兴企业可能面临广阔的增长空间,“芯片设计”与“封装设计”的融合或许才刚刚开始。
Cerebras的成功,为AI芯片领域提供了一条全新的技术路径。虽然短期内它难以撼动现有巨头的主导地位,但对于科技行业观察者和投资者而言,理解其技术创新思路以及背后的产业演进趋势,有助于更清晰地把握未来算力基础设施的演进脉络。
图片来源:unsplash.com/pexels.com


