

随着 AI 模型从基础聊天机器人演进为复杂多轮智能体工作流,行业正遭遇前所未有的可扩展性难题。基础模型参数规模突破万亿,上下文窗口扩展至数百万 Token,人工智能的预训练、后训练与测试三大扩展定律,共同推动计算密集型推理需求激增。智能体已不再是无状态交互工具,而是依赖对话历史、工具调用记录及中间结果的 “长期记忆体”—— 这些信息需在多服务间共享,并随时间推移反复访问,彻底重塑了 KV Cache 的技术定位。
在 Transformer 架构模型中,这种 “长期记忆” 以推理上下文(即 KV Cache)的形式落地。KV Cache 通过缓存注意力机制的 KV 中间向量,避免新 Token 生成时重复计算历史序列,将自回归生成的计算复杂度从 O (n²) 降至 O (n),成为 AI 推理效率的核心支柱。正如 NVIDIA在发布会上说明的:继 “推理(Reasoning)” 驱动上一轮 5 倍 Token 增长后,“Agentic AI” 作为下一个核心趋势,预计将推动 Token 使用量实现 50 倍的爆炸式增长。为精准理解用户意图,模型上下文窗口正从数千 Token 扩展至数百万 Token,直接导致 KV Cache 容量需求线性增长。更关键的是,历史上下文的重新计算开销增长远超线性,因此高效复用已生成的 KV Cache 成为性能优化的关键。而随着序列长度增加,KV Cache 需在长会话中保持持久性,并支持跨推理服务共享,使其成为兼具特殊二元性的 AI 原生数据:
性能核心性:KV Cache 的访问时延直接决定推理响应速度,共享效率影响集群算力利用率,是平衡 AI 服务体验与成本控制的核心变量
数据暂态性:与不可丢失的企业核心数据不同,KV Cache 属于派生数据,即便丢失也可通过重新计算恢复,无需传统存储的高持久性与冗余保护机制
传统 AI 存储体系分为四级:
G1(GPU HBM):纳秒级访问,适配活跃 KV Cache
G2(系统 DRAM):10-100 纳秒级访问,用于 KV 暂存与溢出
G3(本地 SSD / 机架级存储):微秒级访问,支撑温态 KV 复用
G4(共享对象 / 文件存储):毫秒级访问,存储冷态或共享 KV 上下文
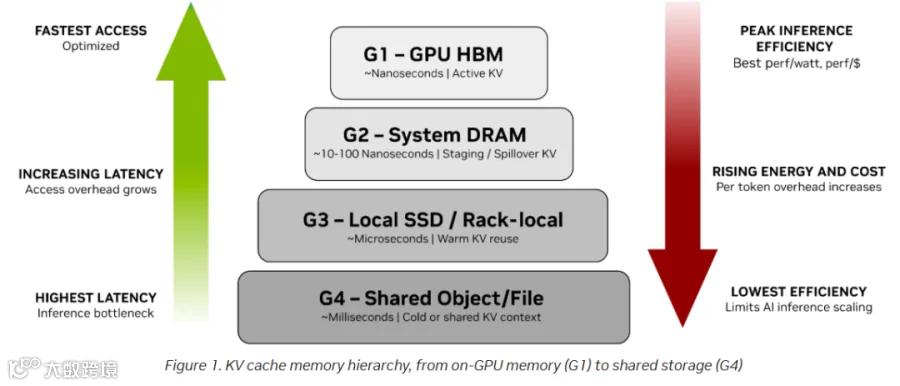
图 1 KV Cache 存储的四级层级结构
G1 聚焦访问速度优化,G3、G4 则侧重持久性保障。随着上下文增长,KV Cache 会迅速耗尽本地存储容量(G1-G3),被迫将部分数据迁移至企业级存储(G4),这会带来不可接受的开销,导致成本与功耗飙升。如图 1 所示,KV Cache 离 GPU 越远,访问成本越高:
顶层的 GPU HBM(G1)提供纳秒级访问速度与最高效率,是 Token 生成所需活跃 KV Cache 的理想载体
当上下文超出 HBM 物理极限,KV Cache 扩展至系统 DRAM(G2)和本地 / 机架式存储(G3),此时访问延迟增加,单 Token 能耗与成本同步上升
底层的共享对象 / 文件存储(G4)虽提供大容量与持久性,但毫秒级延迟导致推理效率极低,仅适用于冷数据或共享数据,若用于活跃 KV Cache 会直接限制 AI 扩展的成本效益
KV Cache 访问延迟与推理系统效率高度绑定:随着推理上下文远离 GPU,访问延迟、能耗及单 Token 成本同步上升,整体效率持续下降。性能优化型内存与容量优化型存储之间的鸿沟日益扩大,迫使 AI 基础设施团队重新思考 KV Cache 的存储范式 —— 亟需一个专为 AI 原生数据设计的专用存储层,既打破通用存储的冗余束缚,又填补传统层级的性能空白,而 NVIDIA ICMS 正是这一范式重构的核心成果。
NVIDIA ICMS 平台以 BlueField-4 DPU 为核心,搭建专为 KV Cache 优化的存储架构,填补传统内存层级的性能鸿沟,重新定义 AI 推理存储体系。当前 AI 推理上下文存储的核心矛盾,在于 KV Cache 数据的独特性质与传统通用存储系统 IO 处理范式的不兼容。
传统通用存储堆栈运行于 CPU 控制器,需消耗大量 IO 资源用于元数据管理、数据复制及后台一致性检查等功能,而这些功能对于瞬态可重构的 KV Cache 并非必要,反而会牺牲能效。KV Cache 与企业级数据的本质区别在于其瞬态性与可重算性,无需为长期存储设计的持久性、冗余性及全面数据保护机制。将传统存储系统应用于 KV Cache,本质是架构性谬误 —— 会引入不必要的开销,增加延迟与功耗,降低推理效率。
因此,NVIDIA 推出全新架构的推理上下文内存存储平台,构建完全集成的专用存储基础设施,其核心目标明确:在速度快但容量有限的 GPU 内存(G1)与容量大但延迟高的传统共享存储(G4)之间,搭建一座专为大规模推理 KV Cache 设计的技术桥梁。
1. 内存层级革新:新增 G3.5 专属 KV 存储层
传统 AI 存储的四级架构中,G3(本地 SSD)与 G4(共享对象 / 文件存储)存在明显的性能与能力断层:G3 性能较好但容量有限、无法扩展,且仅支持单推理节点本地读写,不具备 KV 数据全局共享能力;G4 容量大、可扩展且支持多节点共享,但非为 KV Cache 专属设计,IO 冗余多、性能不足。
ICMS 恰好在此二者之间新增 G3.5 层 —— 基于 BlueField-4 DPU 的RDMA以太网连接闪存层,专门承载 “温态 KV Cache”(需复用但非实时活跃的数据),精准平衡容量、时延与成本三大核心需求。该层级将 KV Cache 这类 AI 原生数据视为 “轻语义、可重算、延迟敏感” 的独立负载,在 G3/G4 基础上构建全新 KV Cache 存储层,实现推理场景的专属优化。
2. 核心设计理念
ICMS 的核心创新,是将 KV Cache 定义为独立的 AI 原生数据类。这类数据具有瞬态性、时延敏感性与可重算性,无需通用存储的持久性、冗余保护等冗余功能。通过 BlueField-4 DPU 的硬件加速与高效调度,ICMS 实现 KV Cache 的跨节点共享与低时延访问,目标达成 “5 倍 TPS 提升 + 5 倍能效优化”,支撑百万 Token 级长上下文推理。
ICMS 的引入彻底优化系统 KV Cache 管理流程:通过将延迟敏感但无需持久化的 KV Cache 卸载至 G3.5 层,实现智能数据分工:
G3.5 层:专注处理和共享活跃可复用的 KV Cache
G4 层:解放为专属持久化数据存储层,专注处理非活跃多轮对话状态、查询历史、日志等需长期保存的数据
这一设计不仅减轻了 G4 层的容量与带宽压力,更实现资源精准分配。正如 NVIDIA CEO 黄仁勋在CES 2026的演讲上强调:KV Cache 处理已成为 “极其重要的” 工作负载,其需求规模足以催生 “新的存储层级”,并有望成长为 “巨大的存储市场”。
3. 架构核心组件
BlueField-4 DPU:提供 800Gb/s 连接速度、64 核 Grace CPU 及硬件加速引擎,可卸载 KV Cache 的 IO 与管理开销,避免占用主机 CPU 资源
Spectrum-X 以太网:提供低时延、高带宽的 RDMA 连接,保障大规模共享 KV Cache 时的稳定访问
NVIDIA DOCA 框架:提供关键底层 API,引入专门的 KV 通信与存储层,首次将上下文缓存(Context Cache)列为 “一等公民” 资源,配合 BlueField-4 DPU 实现最优数据传输
4. 关键实现路径
(1)系统级协同创新
ICMS 并非单一产品,而是全新架构理念,其实现依赖 NVIDIA 多类创新软硬件组件的深度协同:
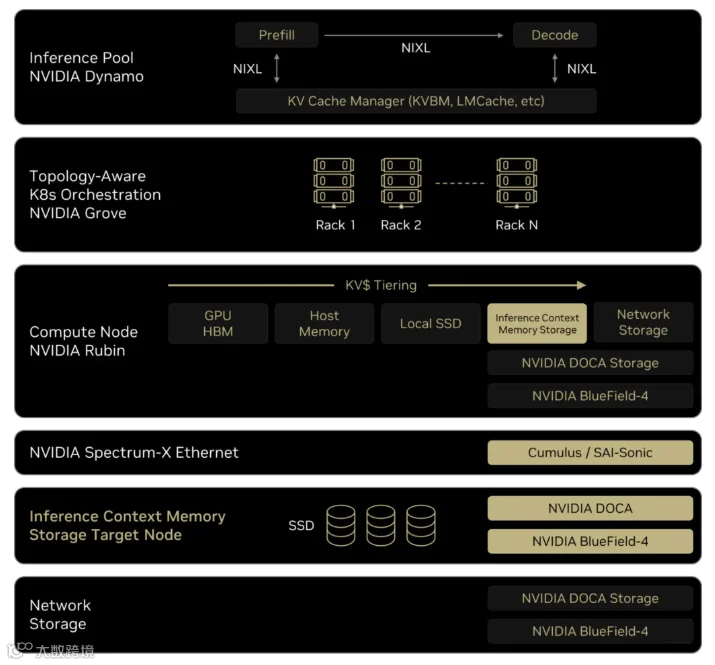
图 2 推理上下文存储在 NVIDIA Robin 平台中的位置
推理层:NVIDIA Dynamo 与 NIXL 负责管理预填充(prefill)、解码(decode)及 KV 缓存,同时协调共享上下文访问;其下的拓扑感知编排层基于 NVIDIA Grove 技术,结合 KV 缓存局部性(KV locality)在机架间分配工作负载,确保工作负载跨节点迁移时仍能持续复用上下文
计算节点层:KV 缓存分层(KV tiering)覆盖 GPU 高带宽内存(HBM)、主机内存、本地固态硬盘(SSD)、ICMS 及网络存储,为编排器提供连续的容量与延迟目标区间,支撑上下文存储调度
网络连接层:Spectrum-X 以太网作为核心连接枢纽,将 Rubin 计算节点与 BlueField-4 ICMS 目标节点相连,提供持续低延迟、高效的网络传输能力,将闪存支持的上下文内存(context memory)无缝集成至同一套 AI 优化网络架构(AI-optimized fabric),同时支撑模型训练与推理任务。
该架构通过 BlueField-4 加速 KV I/O 操作与控制平面流程,覆盖 Rubin 计算节点的 DPU 及 ICMS DPU,既降低对主机 CPU 的依赖,又最大限度减少序列化开销与主机内存拷贝。Spectrum-X 以太网提供 AI 优化的 RDMA 网络架构,实现 ICMS 闪存池与 GPU 节点的无缝连接,保障可预测的低延迟、高带宽通信。
NVIDIA DOCA 框架进一步引入 KV 通信与存储层,将上下文缓存列为 KV 管理、共享与调度的 “一等公民” 资源,充分利用 KV 数据块的独特属性与推理访问模式。DOCA 框架与推理框架深度对接,通过 BlueField-4 实现 KV 缓存与底层闪存介质的高效读写传输。这种无状态、可扩展的设计,既契合 AI 原生 KV 缓存策略,又借助 NIXL 与 Dynamo 实现 AI 节点间的高级共享,提升推理性能。DOCA 框架支持开放接口,适配更广泛的编排调度需求,为存储合作伙伴提供灵活性,使其推理解决方案可覆盖 G3.5 级上下文存储层
Spectrum-X 以太网作为高性能网络架构,为 AI 原生 KV 缓存提供基于 RDMA 的访问能力,支撑 NVIDIA 推理上下文内存存储平台的高效数据共享与检索。该以太网专为 AI 场景打造,规模化部署下仍能提供可预测的低延迟、高带宽连接 —— 通过高级拥塞控制、自适应路由及优化的无损 RoCE 协议,在高负载场景下最大限度降低延迟抖动、尾部延迟与数据包丢失
(2) 基于网络互联的大容量闪存存储层
需明确的是,ICMS 虽然名为“推理上下文内存存储”,名称中的 “内存”,指为 KV Cache 这类缓存数据提供内存级(显存级)的大容量扩展空间,而非指采用 DRAM 内存作为存储介质。
通过对 ICMS 架构与容量的分析,其本质是基于闪存(NAND SSD)构建的分布式 SSD 池,由 BlueField-4 DPU 完成 SSD 介质的高速读写,DPU 之间通过 Spectrum-X RDMA(RoCE)网络互联。NVIDIA 发布会上,NVIDIA CEO 黄仁勋明确提到 Robin 平台给每颗 GPU 可提供 16TB 上下文存储空间 —— 这一容量较 GPU 显存放大约 100 倍,若采用 DRAM 实现成本极高,并且有限的机架/机箱空间也放不下如此之多的DRAM, 而高速大容量 SSD 介质是兼顾性能与成本的最优选择。
(3)AI 原生存储软件堆栈
ICMS 采用 AI 原生软件堆栈,实现上下文 KV Cache 的组织、调度与高速读写,核心组件包括:
NVIDIA Dynamo:KV Block 管理器,将 KV Cache 从 GPU 内存(G1)扩展至 CPU 内存(G2)及持久层(G3/G4),本质是多层级 KV Cache 调度与管理中枢。ICMS 作为 Dynamo 的 G3.5 新层级,在一定程度上可直接替代原有 G3,且提供更大容量与全局 KV Cache 共享能力。Dynamo 负责决策 KV Block 在 G1/G2/G3/G4 的存储位置,BlueField-4 与存储 OS 软件负责执行决策(包括空间分配、层级间智能流动、高并发 IO 读写等)
DOCA / NIXL:在 DPU 上将 KV Cache 定义为 “原生数据类型”,通过 DOCA 框架 + NIXL 库,实现 BlueField-4 上的 KV Cache 加速共享与数据路径优化,消除复杂元数据开销。简单来说,DOCA/NIXL 使 KV Cache 成为 DPU 的 “一等公民”,不再是依附于文件系统 / 对象存储的 key/value 文件,而是独立的 KV 专属空间
分布式存储软件(Storage OS):NVIDIA 采用生态合作模式,由存储厂商基于 BlueField-4 构建新一代 AI 原生存储平台。该分布式存储软件并非传统分布式文件系统或对象存储,而是专为 AI 上下文、KV Cache 数据原生设计 —— 数据访问无需传统冗长协议栈与复杂元数据体系,通过 BlueField-4 DPU 运行 Storage Stack,借助 RDMA 网络 + GPU Direct Storage 技术,实现 GPU ↔ DPU ↔ SSD 的高效 IO 路径
WQS 与 ICMS 的五大核心契合点:
天生适配的技术协同
WQS (WiDE Query Storage)是华瑞指数云自主研发的 AI 原生 KV Cache Storage 产品,其设计理念与技术架构与 NVIDIA ICMS 平台高度契合,且已在 BlueField-3 DPU 上完成实战验证,具备无缝迁移至 BlueField-4 生态与 ICMS 架构体系的天然优势。
1. 技术理念契合:精准定位 AI 原生数据类型
ICMS 的核心思路是打破 “将 KV Cache 强行纳入通用存储体系” 的传统模式,明确其 AI 原生数据属性,摒弃冗余的功能、元数据及存储协议栈,以降低时延与能耗。
WQS 面向 AI 原生设计,领先于同行在行业内践行这一理念:采用原生 KV 接口 + 分布式 KV 存储引擎,直接管理分布式 SSD 资源,KV Block 无需封装为文件,彻底摆脱分布式文件系统的目录树元数据、文件协议栈等冗余体系。这种设计使 IO 路径极致精简,完美匹配 KV Cache 中小 IO 随机读写的核心需求。实测数据显示,序列长度 100K 时,WQS 的 TTFT(首 Token 响应时延)仅为基于高性能文件系统方案的 1/3,Token 吞吐量提升 3 倍。
2. 存储层级契合:精准对接 G3.5 层定位
ICMS 的 G3.5 层专门承载温态 KV Cache,平衡容量、时延与成本。WQS 的三级分层设计(L1-L3)精准匹配这一定位:
L1 层(GPU HBM):存储实时活跃 Token 的 KV Block,WQS 通过统一 Block ID 实现与外置存储的逻辑映射,确保 HBM 与外部存储的 KV Block 形态一致,无格式转换开销
L2 层(主机内存):可灵活配置为 KV 数据暂存区或传输通道,例如推理服务器内存不足时,仅作为 HBM 与 SSD 之间的桥梁
L3 层(WQS 分布式 SSD 池):作为核心存储层,承载非最活跃但需复用的 KV Cache(如多轮对话历史、系统提示词),通过 RDMA、GPU Direct Storage(GDS)技术实现微秒级访问(高并发访问时延 < 200us),且支持容量无限扩展,是 ICMS G3.5 层的理想载体
3. 硬件适配契合:DPU 原生运行 + 高速互联
ICMS 的性能核心依赖 BlueField-4 DPU,要求存储软件能把许多IO和网络处理有关的能力卸载到DPU内运行,甚至是能够全量轻量化运行于 DPU 内,且兼容 RDMA、GDS 等高速互联技术。WQS 在 DPU 适配性上具备天然优势:
DPU 原生部署:WQS 整个分布式KV软件栈可以 100% 运行于 BlueField-3 DPU 内,最小部署仅需 “单节点 16 核 + 48G 内存”,无需独立元数据盘,支持 RoCE 及 IB 网络,资源占用极致精简,可无缝迁移至 BlueField-4 环境。在 BlueField-4 支持下,基于 SSD 的分布式 KV Cache 层可完全脱离主机 CPU 与内存,无需配置专门的存储服务器,实现软硬件全栈 AI 原生设计与运行
高速互联兼容:深度支持 RDMA 零拷贝、GDS 等技术 ——GDS 模式下,KV 数据可从 GPU HBM 直接通过 RDMA 写入外置 SSD,无需经过主机内存,IO 路径时延再降 30% 以上,与 BlueField-4 的高速互联能力完全匹配
4. 性能目标契合:低时延、高吞吐与线性扩展
ICMS 的核心性能目标明确:5倍 TPS 提升、5倍能效优化,同时支持 PB 级容量扩展与百万 Token 长上下文推理。这与 WQS 的实测性能及设计目标高度吻合:
低时延:KV Block 按 “数百 KB~ 数 MB” 组织(对应数个至数十个 Token),外置 SSD 池的高并发读写时延 < 200us;通过 “KV Cache 流水线技术”(并行计算新 Token KV、加载下一层 KV、写入上一层 KV),可将 KV 加载时间隐藏在计算过程中,实际有效时延 < 10us,满足 ICMS G3.5 层的微秒级时延要求
高吞吐:在随机中小 IO(几十 KB 至几百 KB)读写场景下,存储吞吐量可逼近物理网络带宽,远超分布式文件系统性能
线性扩展:支持 “节点扩容 = 容量 + 带宽同步扩展”—— 单 2U 节点可提供 180GB/s(1440Gbps)读写带宽,新增存储节点即可实现带宽线速提升,匹配 ICMS 的 PB 级集群容量需求
5. 生态兼容契合:框架对接与集群调度
ICMS 并非孤立存储方案,而是与 NVIDIA Dynamo(推理框架)、NIXL(推理传输库)、Grove(拓扑编排工具)深度协同,要求存储层兼容主流 AI 推理框架,支持集群级并发访问。WQS 在生态兼容性上完全满足这一需求:
框架无缝对接:原生实现与 vLLM、SGLang、LMCache、Mooncake、Dynamo 等主流推理框架的接口适配,用户无需修改业务代码即可将 KV Cache 卸载至 WQS;同时兼容 NVIDIA H20、H100、H200 等主流 GPU 及 DeepSeek、Llama3 等大模型
大规模集群支持:支持 “千卡级推理集群” 的并发读写,通过全局统一的 KV Block 映射机制,实现跨 GPU、跨节点的 KV Cache 零拷贝共享,实测可节省 50%~90% 的重复计算量,与 ICMS “跨节点共享提升集群效率” 的目标完全一致
成本协同优化:通过将 KV Cache 从 GPU 显存卸载至 SSD池,以存储 IO 替代 GPU 重复计算,可节省 60% 的 GPU 卡成本
WQS 的技术优势源于其 AI 原生架构设计,从接口、存储、调度等多维度优化,确保与 ICMS 架构的深度协同。
1. 原生 KV 架构:摆脱文件系统束缚
WQS 摒弃传统分布式文件系统的冗余体系,采用原生 KV 接口直接管理 SSD 存储资源。KV Block 通过统一 Block ID 实现跨存储层的快速定位与读写,无需格式转换与文件封装,IO 路径精简度提升数倍。这种设计完美适配 KV Cache 中小 IO 随机读写的特征,在长上下文场景下优势尤为突出。
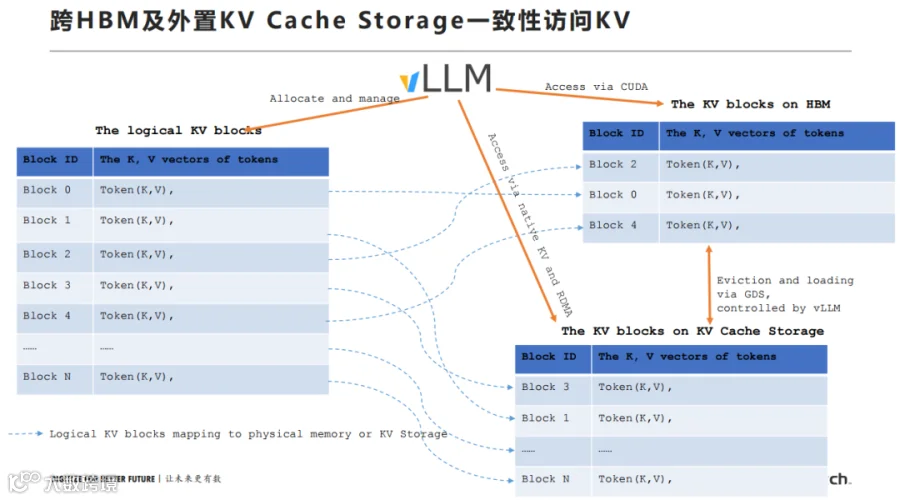
图 3 WQS 实现原生 KV 读写
2. 全局共享与弹性扩展
WQS 搭建全局统一的分布式 KV Cache 池,支持跨节点、跨 GPU 的 KV Block 共享,重复前缀请求可实现零拷贝复用。通过增加存储节点,可实现 KV Cache 空间无限扩展(支持 PB 级容量),同时存储带宽同步线性提升,满足大规模集群推理需求。
3. 极简部署与广泛兼容
WQS 系统资源消耗低,最小部署仅需单节点 16 核 48G 内存,无需独立元数据盘,全用户态运行不依赖内核。支持普通服务器硬件、RoCE 及 IB 网络,可轻松实现安装部署与在线升级。
4. 与其他方案的差异化优势
相较于基于文件系统的分布式 KV Cache 方案,WQS 基于AI原生设计的技术优势显著:

AI系列专题 | 揭秘AI原生KV Cache Storage如何实现超20倍AI推理加速(上篇)
AI系列专题 | 中篇:揭秘AI原生KV Cache Storage如何实现超20倍AI推理加速
AI系列专题 | 下篇:揭秘AI原生KV Cache Storage如何实现超20倍AI推理加速
华瑞指数云 WQS 与 NVIDIA ICMS 的契合,本质是 “AI 原生存储需求” 与 “数据场景化” 的精准匹配 ——ICMS 定义了 “G3.5 层 + DPU 加速” 的架构方向,而 WQS 通过 “原生 KV + DPU 部署 + 分层调度” 的技术落地,成为该方向的理想实现载体。
二者协同不仅带来 “时延降低 1/20 + 吞吐量提升 20 倍” 的性能飞跃,更推动 AI 推理存储从 “被动扩容” 转向 “主动优化”,为百万 Token 长上下文、千卡级集群推理提供可规模化落地的技术路径。AI 推理的效率革命,始于 KV Cache 的存储革新,而 WQS 与 NVIDIA ICMS 的技术协同,正为这场革命注入强劲动力,推动 AI 基础设施迈入 “原生 KV 实现推理加速与上下文全局共享” 的新时代。