
ScaleFlux, AIC, and ExponTech demonstrate amazing storage performance with NVIDIA BlueField-3 DPUs
Recapping from Part 1:
In Part 1, we explored the initial performance benchmarks of the AIC F2026 AI Inference Server, highlighting its scalability and efficiency with two DPUs. The AIC F2026 AI Inference Server integrates up to 26 ScaleFlux CSD5000 NVMe SSDs together with up to 8 NVIDIA BlueField-3 Data Processing Units (DPUs) in a 2U system to provide the high throughput, low latency, and scalability needed to keep up with AI workloads.
In the first round of testing with only 2 DPUs populated in the F2026, the teams demonstrated the system’s ability to scale performance as more compute servers were connected to the storage array. (See the full details in the blog “Prepping for the Future Demands of AI Inference Reasoning: Part 1”)
We also promised further testing of the system under additional scenarios. Building upon those findings, Part 2 delves deeper into advanced testing scenarios, including comprehensive storage performance evaluations and MLPerf benchmarking, to assess the system’s capabilities under varied and demanding AI workloads.

Test Set Up
ExponTech, in collaboration with NVIDIA, ScaleFlux, and AIC, performed a series of performance tests on the AIC F2026.
Hardware:
Storage Server: One AIC F2026 Inference Server populated with 26 ScaleFlux CSD5000 SSDs and four BlueField-3 DPUs. The ScaleFlux SSDs incorporate in-line data compression engines to perform line-rate data compression & decompression. The NVIDIA DPUs provided up to 1600Gbps network bandwidth.
Networking: In the test environment, four NVIDIA Spectrum-X switches were selected to form a Layer 2 network, primarily to simulate large-scale networking and to verify whether the RoCE network can effectively handle congestion. Additionally, the test aimed to ensure that the storage software can maintain stable storage performance and low latency in large-scale networking scenarios.
Compute Server: A standard 2U server populated with four NVIDIA BlueField-3 DPUs, providing 800Gbps network bandwidth and running the ExponTech WADP storage software,on the DPUs.. The storage software and network traffic were managed by the DPUs, keeping the compute server’s GPUs free for training or inference tasks. Since the storage I/O is handled by the DPUs, the compute server’s CPU and memory resources are also available for running applications.
Software:
ExponTech next-gen distributed storage software, WADP, a unified data platform, was running on the DPUs in the F2026 Inference AI Server. WADP simultaneously supports transactional data such as databases that require ultra-high IOPS and ultra-low latency, and large-scale AI data, that demand massive capacity, ultra-high throughput, and high metadata performance.
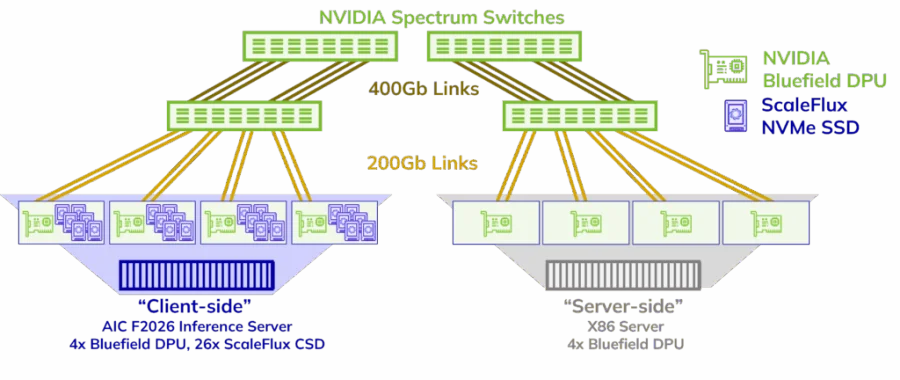
Both JBOF and compute servers can be independently scaled and more JBOF or compute servers can be added as needed to form a large-scale, storage-compute separation cluster for on-demand AI training and inference
Testing Round 1 – Basic Storage Performance
Using FIO running on the compute server, the team gathered read and write performance results for various I/O block sizes (4K, 128K, 1MB). The first performance test was configured with the compute server populated with a single DPU. The second run populated the compute server with four DPUs. In both cases, the storage server had four DPUs and 26 SSDs.
The results are consistent with the results from Part 1, with the storage server performance scaling nearly linearly with the number of DPUs in the topology. Increasing the DPUs in the F2026 enabled greater utilization of the potential SSD bandwidth and IOPs. Increasing the number of DPUs on the compute server enabled greater utilization of the F2026 performance. The Spectrum switches provided a consistently low-latency data path between the compute and storage servers.
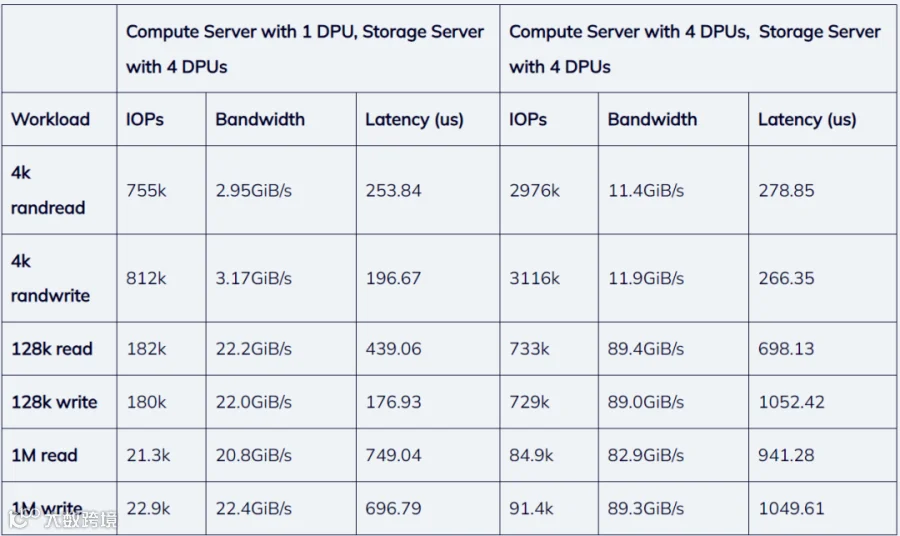
Table 1: FIO Performance Results
Key Observations:
A single compute node connected with a single storage node can achieve a storage bandwidth of nearly 90 GB/s, which is close to the upper limit of the physical bandwidth of the compute node’s NICs
A single compute node scaled from 0.8 to 3.1 million IOPS, nearly linear scaling with the number of DPUs. In both cases, the compute server, not the storage server was the constraint on performance. Considering that the backend and protocol end of the entire storage system run on the cores in the DPUs (which are lower power than traditional x86 CPU cores), the tests fully demonstrated the amazing IO processing efficiency of this solution.
The number of IOPS of the storage system scales linearly proportional to the number of DPUs deployed on the storage nodes, and the IOPS of the system scales linearly with the number of DPUs deployed, indicating that the system has excellent scale-out capabilities.
When the storage system uses a small I/O size, the concurrent high-pressure latency is as low as 266us. For large I/O size, the network bandwidth of the computing nodes saturates, and the latency remains below 1 millisecond.
While the current performance is dependent on the DPU’s processing capacity, this setup allows for targeted DPU upgrades, ensuring that the storage system can scale as needed.
Testing Round 2 – MLPerf
The MLPerf benchmark is a set of tests designed to measure how fast and efficiently computers can run artificial intelligence (AI) tasks. Just like a car might be tested for speed and fuel efficiency, MLPerf evaluates how well computer systems handle jobs like recognizing images, translating languages, or making recommendations—things AI does every day.
Benchmark Background
MLPerf was created by a group of companies and researchers who want to make it easier to compare the performance of different hardware and software setups in a fair, transparent way. It looks at both how quickly a system can train an AI model (learning from data) and how fast it can make predictions once trained (called inference).
These tests are especially useful for businesses and researchers who rely on AI because they show which systems are best suited for their needs. MLPerf also helps hardware makers prove how powerful their technology is. It has become one of the most trusted tools for benchmarking AI performance in the industry.
The MLPerf benchmark suite includes a variety of tests that reflect common real-world AI tasks. For training benchmarks, it includes image classification (how well a system can recognize objects in photos), object detection (identifying and locating items within images), speech recognition (turning audio into text), natural language processing (understanding and generating human language), and recommendation systems (like those used by streaming services).
For inference benchmarks—where AI models make decisions based on what they’ve already learned—MLPerf includes similar tasks, tested across different environments such as data centers, edge devices (like smartphones), and servers. Each test measures how quickly and accurately a system can perform the task under specific conditions.
Testing the F2026 with ScaleFlux SSDs and ExponTech
The team used the same set up of one F2026 and one compute server connected via NVIDIA Spectrum networking. They evaluated the storage system using the MLPerf® Storage Benchmark v1.0, which simulates the I/O demands of AI workloads based on real-world MLPerf Training profiles.
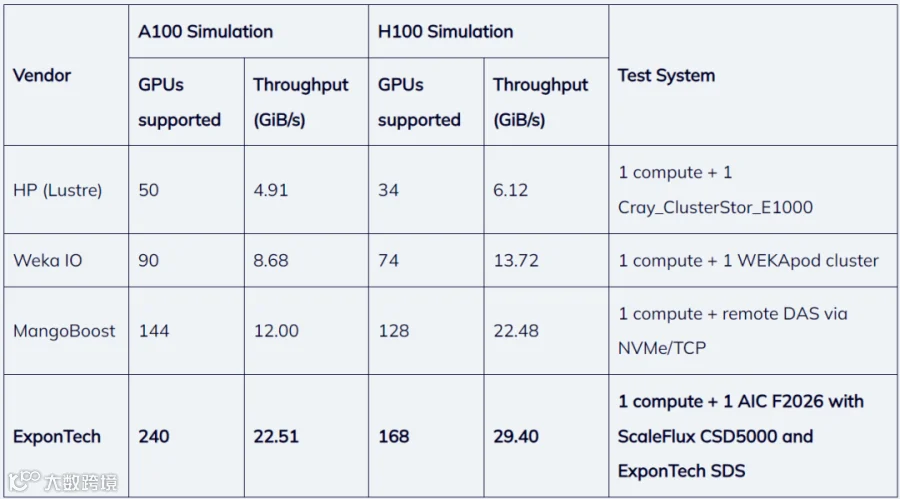
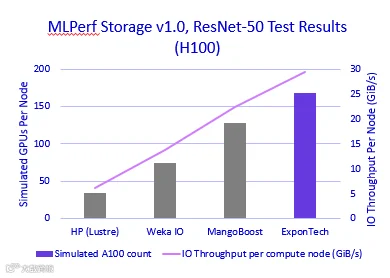
Using the ResNet-50 trace, the storage solution achieved performance equivalent to supporting 240 simulated NVIDIA A100 GPUs, sustaining 22.5 GiB/s of read throughput. The performance also supported 168 simulated NVIDIA H100 GPUs with a sustained 29.4GiB/s throughput. This result demonstrates the array’s ability to deliver consistent high-bandwidth data access, meeting the intense data ingestion requirements of large-scale AI training.
In describing the test results, ExponTech CTO, Yuzhong Cao, noted that “the limited capability of the compute server in the test configuration constrained the results far below the capability of the storage system. With more compute clients or a more powerful compute node, the storage system would score even higher!”
Table 2, MLPerf Storage v1.0 Test Results (ResNet-50 model)
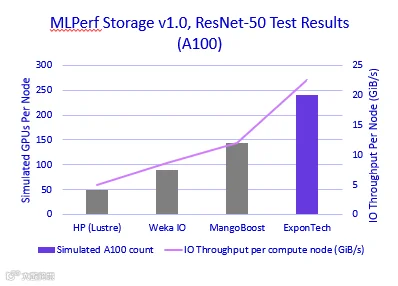
Key Takeaways
Outstanding overall throughput, latency, and scalability from the combination of AIC system expertise with ScaleFlux CSD5000 NVMe SSDs, NVIDIA BlueField-3 DPUs, and ExponTech software.
Ultra-high density with 26 drives per 2U array.
Transparent data compression and decompression in the CSD5000 can multiply the raw storage capacity and storage efficiency without consuming additional system resources or impacting performance.
Excellent solution for all AI pipeline scenarios such as data collection, data preparation, and RAG.
Strong parallel scalability, storage nodes and computing nodes can be independently added, scaling the storage performance and capacity proportionally.
High reliability and maintainability with the redundant hardware design inside the JBOF to ensure reliability.
It supports RoCE-based ultra-large-scale networking, adopts RoCE dynamic routing and fine-grained load balancing to achieve better congestion control, efficient bandwidth, low jitter and ultra-low latency in large-scale networking based on standard Ethernet.
需要建设AI集群的合作伙伴和客户如果对本方案感兴趣,
欢迎与我们联系进行进一步的交流和测试。
电话:400-100-5719
媒体报道 | 36氪专访华瑞指数云:SDS进入2.0时代,渐进式迭代以10年为周期
“颠覆·挑战·极致”华瑞指数云ExponTech WDS新一代产品重新定义企业存储和数据架构

