
上周,我们通过上篇的技术详解、中篇的方案介绍,逐步揭开了 ExponTech 华瑞指数云AI原生KV Cache Storage 实现超20倍提升AI推理效率的核心逻辑。今天,该系列下篇重磅收官,用真实数据为技术实力盖章。
从技术原理到落地方案,再到实测验证,完整闭环解锁AI推理高效落地路径。关注华瑞指数云,获取更多AI原生技术的实战干货与前沿洞察!
内容回顾:
上篇:AI系列专题 | 上篇:揭秘AI原生KV Cache Storage如何实现超20倍AI推理加速
中篇:AI系列专题 | 中篇:揭秘AI原生KV Cache Storage如何实现超20倍AI推理加速

为了实战验证WQS KV Cache Storage对AI推理系统性能的加速效果,近日华瑞指数云携手合作伙伴英伟达,超擎数智,DaoCloud进行了联合测试。
结果显示,基于该方案的推理性能显著提升:在中等长度上下文(约10K tokens)的典型场景中,首Token响应时间大幅缩短为原来的1/20,吞吐量更是实现20倍提升。这一成果为 KV Cache 分层存储方案在生产环境的稳定落地,以及长上下文场景下大模型推理的规模化应用,奠定了坚实基础。
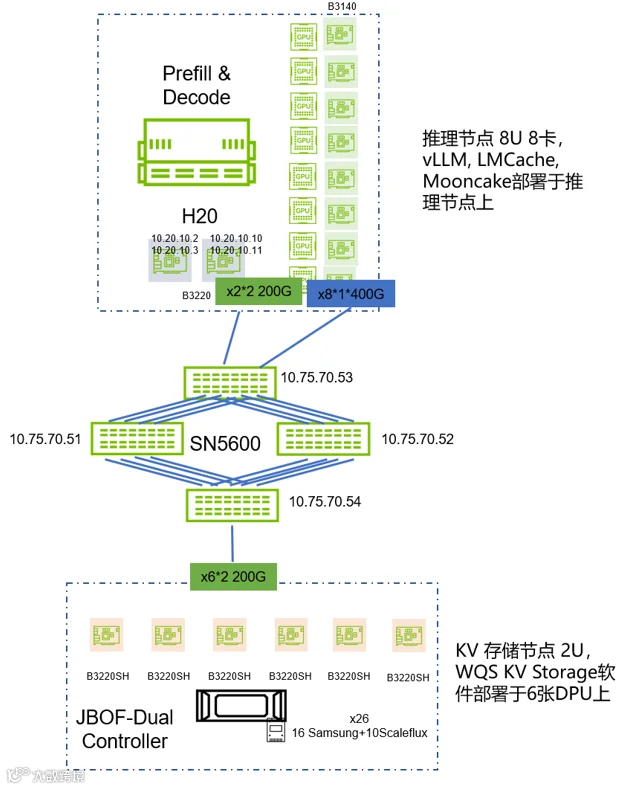
推理节点:
超擎CQ7688-L*1:搭载 NVIDIA H20 GPU,8U,8卡 NVLink,8U空间内搭载 1 块NVIDIA Hopper架构HGX-8GPU模组,系统支持4.0Tbps网络带宽,包含8张东西向400Gbps Bluefield-3 SuperNIC加上2 张南北向 400Gps BlueField-3 DPU
网络设备:
ROCE 交换机*4:采用支持RoCEv2的NVIDIA第五代Spectrum以太网交换机SN5600,计算网络和存储网络均采用 SN5600 进行组网
存储设备:
JBOF盘框*1,2U,盘框本身没有配置CPU和内存,没有处理能力,盘框内插入6张英伟达Bluefield-3 DPU卡,每个DPU提供200Gbps*2 RoCE网络带宽,共总配置26块NVMe SSD硬盘
存储软件:
华瑞指数云AI 原生KV Cache Storage WQS,运行于存储设备内的6张DPU内,组成了一个 6 节点的分布式KV Storage集群
推理框架:
vLLM + LMCache + Mooncake
模型:
DeepSeek-R1-0528
测试环境选型说明:
网络方面,采用4台英伟达Spectrum-X 交换机组成一个2层的 RoCE 网络, 验证大规模组网时的拥塞控制能力,该组网足以扩展至连接上千台推理服务器节点及分布式存储节点,构建大规模的推理集群。
存储方面,采用极简硬件配置,2U节点就可以起步,同时又可以无限扩展。WQS KV Cache Storage软件运行于DPU内,每个DPU仅配置16 核48G内存,验证WQS的极简部署能力和对系统资源的极致利用。
推理节点方面,由于资源有限,本次测试只配置了 1 台 8 卡服务器,但整体部署方案及测试采用了 Prefill 与 Decode 分离(PD 分离)的方式 —— 本次测试中,P 节点和 D 节点运行在同一物理节点,逻辑上实现 PD 分离;若环境中有多台推理服务器,可轻松切换为物理层面的 PD 分离。同时,方案结合张量并行技术,能够支持多台推理节点组成推理集群并行工作。
压测方法:
使用 vLLM 提供的 bench 命令来进行压测
使用随机生成的数据集,可以指定输入长度。在测试过程中,分别指定上下文长度为100,1k,10k,50k,100k,以模拟不同业务场景下的不同上下文长度
使用随机生成的数据集,但在多轮测试中使用相同的随机种子,保证每轮请求的prompt相同,以验证KV Cache命中效果。意味着从测试的第二轮对话开始,理论上应该100%命中KV Cache。在真实多轮对话业务场景中,根据一些业界的论文和实践数据,可以Cache下来的KV向量约在50%~90%之间,也就是说有50%~90%的Token可以命中KV Cache(如果历史Token的KV向量都很好的保存下来并且可以检索到的话),可节省50%~90%的重复运算,大幅度减少了算力浪费
测试场景1:Prefill Only, 使用400Gbps网络
在推理服务器上部署Prefill节点,只测试Prefill的流程,即只测试到模型输出第1个token为止。在推理服务器上配置只使用1张400Gbps网卡访问WQS KV Cache Storage。
一些主要的配置参数如下:
vLLM 通用参数:TP=8,关闭前缀缓存,以减少vLLM内存Cache对测试的干扰
使用LMCacheConnectorV1
(--tensor-parallel-size8--no-enable-prefix-caching--disable-log-requests-kv-transfer-config'{"kv_connector":"LMCacheConnectorV1","kv_role":"kv_both"}')
LMCache:chunk_size=256, max_local_cpu_size=100.0
--max-concurrency 16
--random-input-len100,1k,10k,50k,100k
--random-output-len 1
--num-prompts 50
--seed $SEED
Mooncake配置8G内存,给Mooncake配置很小的内存,主要也是为了尽量排除Mooncake内存Cache的干扰,更好的验证分布式KV Cache Storage的加速效果
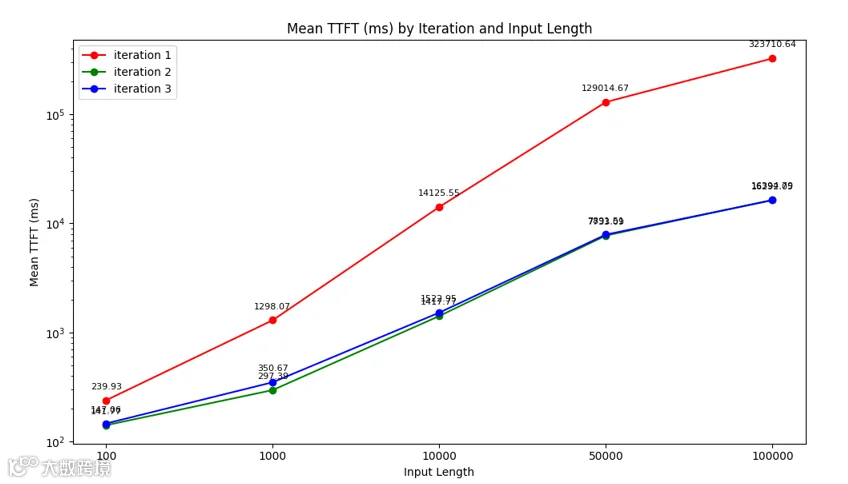
WQS 测试结果(TTFT) Prefill Only, 400Gps网络
TTFT(首 Token 响应时长)是本次测试关注的主要指标。上图中的横坐标是不同的输入序列长度,纵坐标是TTFT时长(ms),红线是iteration 1,此时KV Cache中没有历史数据,反映的是没有使用KV Cache时的TTFT指标,绿线和蓝线是iteration 2和iteration 3, 此时,KV Cache中已经缓存了历史序列中的tokens的KV向量值,推理框架通过复用 KV Cache 中的KV向量,消除了 Prefill 阶段重新计算所有tokens的算力消耗和时长,极大的降低了TTFT;
具体来说,当输入序列的长度在1000个token时,使用WQS KV Cache Storage做推理加速,能够把TTFT降到300ms左右,不使用KV Cache时的TTFT是1300ms,TTFT下降为原来的约1/4; 当输入序列的长度在100k时,使用WQS KV Cache Storage做推理加速,TTFT 在16s左右,而不使用KV Cache时的TTFT是323s左右,WQS KV Cache把TTFT降低为原来的约1/20。
输入序列(上下文长度)越长,并发量越大(batch size越大),外置的KV Cache Storage带来的加速效率越明显,因为输入序列的长度和推理请求并发量越大,推理系统产生的KV向量值越多,远远超过GPU显存和主机内存能够存储的容量,这时外置的超大容量空间的KV Cache Storage就更能发挥其价值。同时,外置的KV Cache Storage能够实现KV向量的持久化存储和全局共享,有助于AI推理系统支持更长的上下文,简化AI推理任务的调度,大幅提升KV Cache的命中率。
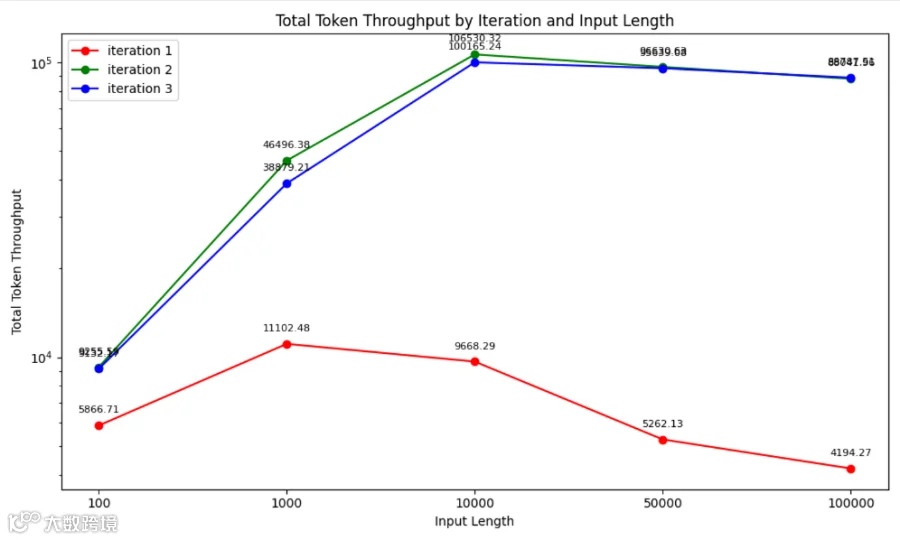
WQS 测试结果(Total token throughput) Prefill Only, 400Gps网络
Total token throughput(总体的 token 吞吐量)是指AI推理系统每秒能够处理和产生的Token数,token的吞吐量实际上是与Token的响应时延成反比的。随着首 Token 的响应时长TTFT的降低,系统的Token吞吐量会上升。
上图中的横坐标是不同的输入序列长度,纵坐标是推理系统每秒处理和产生的Token个数。当输入序列长度为1000时,WQS把推理系统的Token吞吐量由11102提升到了40000多,提升4倍;当输入序列长度为100k时,WQS把推理系统的Token吞吐量由4194提升到了近90000,提升20多倍。
AI推理系统本质上就是一个Token的计算和生产工厂,其生产率和经济效益本质就是由Token吞吐量来衡量的。因此,当采用WQS KV Cache Storage能够大幅度提升Token吞吐量时,就是大幅度提升了AI推理系统的产量,可以非常直观的提升经济效益!
测试场景2:Prefill + Decode PD分离,使用400Gbps网络
受物理测试设备所限,本次测试在相同的推理服务器上同时部署Prefill节点和Decode节点,按PD分离的方式进行并行分布式推理。Prefill节点产生的KV Cache写入WQS KV Cache Storage,Decode节点从WQS KV Cache Storage读取Prefill节点的KV Cache数据。也就是说Prefill节点与Decode节点之间的KV Cache传输,不是走P2P transfer的方式,而是通过WQS KV Cache Storage的全局共享能力来完成。
一些主要的配置参数如下:
vLLM 通用参数:TP=8,关闭前缀缓存,以减少vLLM内存Cache对测试的干扰
使用LMCacheConnectorV1
(--tensor-parallel-size8--no-enable-prefix-caching--disable-log-requests-kv-transfer-config'{"kv_connector":"LMCacheConnectorV1","kv_role":"kv_both"}')
LMCache:chunk_size=256, max_local_cpu_size=0.0
--max-concurrency 16
--random-input-len100,1k,10k,50k,100k
--random-output-len 20
--num-prompts 20
--seed $SEED
Mooncake配置8G内存,给Mooncake配置很小的内存,主要也是为了尽量排除Mooncake内存Cache的干扰,更好的验证分布式KV Cache Storage的加速效果
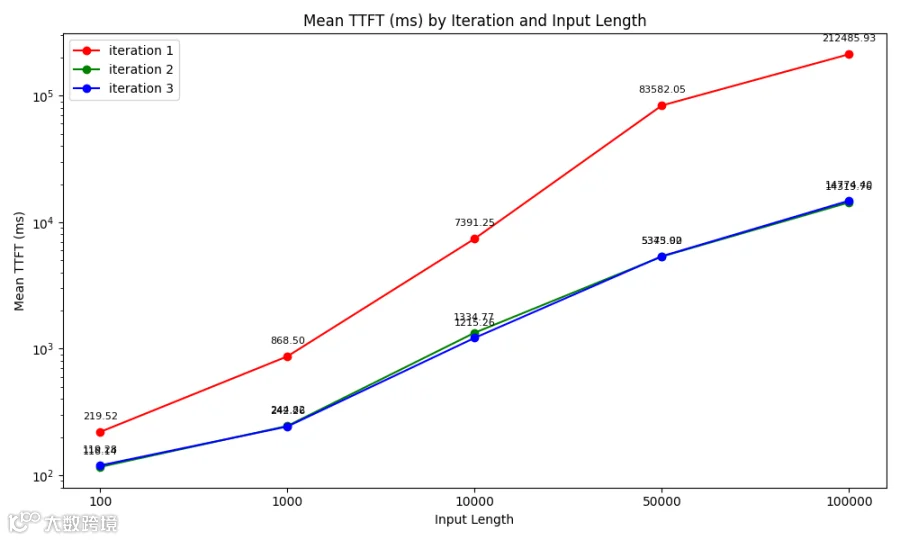
WQS 测试结果(TTFT) Prefill + Decode PD分离, 400Gps网络
Prefill + Decode PD分离推理场景,WQS KV Cache(绿线和蓝线)相比不使用KV Cache(红线),把TTFT下降至原来的约1/3.5到1/15。
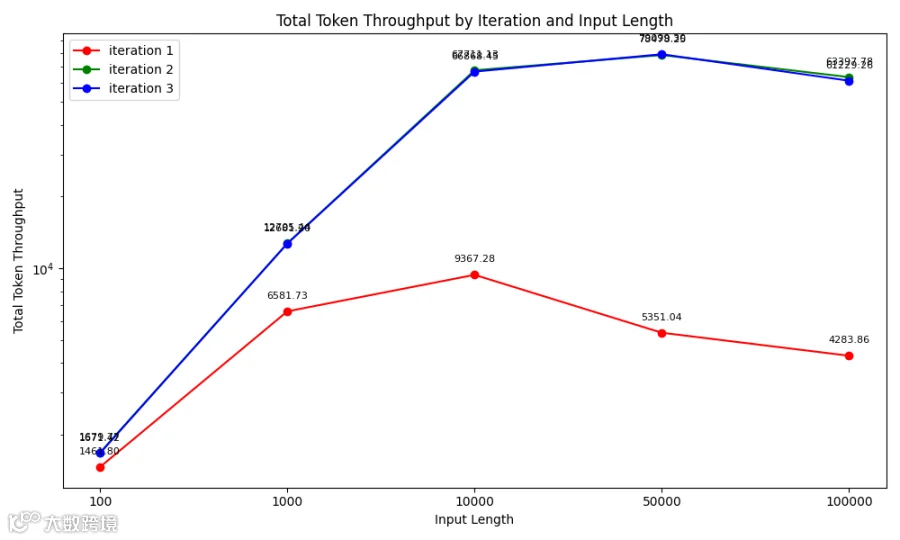
WQS 测试结果(Total Token Thoughput) Prefill + Decode PD分离, 400Gps网络
Prefill + Decode PD分离推理场景,WQS KV Cache(绿线和蓝线)相比不使用KV Cache(红线),把推理系统的Token吞吐量提升了约2倍到14倍。
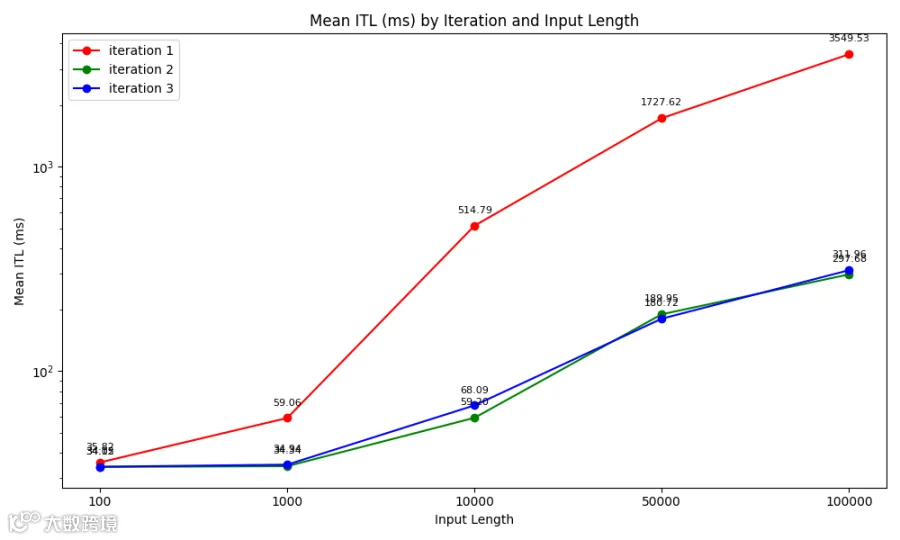
WQS 测试结果(ITL) Prefill + Decode PD分离, 400Gps网络
ITL(Inter-Token Latency)是指Decode阶段连续两个输出 Token 之间的间隔时间。Prefill + Decode PD分离推理场景,WQS KV Cache(绿线和蓝线)相比不使用KV Cache(红线),把推理系统的ITL降低至原来的1/2到1/12。
测试场景3:Prefill Only, 使用800Gbps网络
与测试场景1类似,唯一的区别是在推理服务器上配置使用2张400Gbps网卡,一共800Gbps带宽访问WQS KV Cache Storage。
经过测试发现,使用800Gbps网络访问WQS KV Cache存储,推理系统体现出来的TTFT, Token Throughput等性能指标与使用400Gbps时是基本一致,没有提升。
经过诊断分析,本次测试使用的WQS KV Cache Storage,2U节点可以提供180GB/s(1440Gbps)的读写带宽,WQS KV存储本身没有达到性能瓶颈。然后通过流量监测,发现vLLM+LMCache+Mooncake的推理框架层从单个推理节点下发给KV Cache存储的流量峰值只有300Gbps~350Gbps左右,因此是推理框架往外置的KV Cache存储池的读写带宽有限导致的瓶颈。在后续的工作中,将协同推理框架层进一步优化端到端的流量带宽,预期可以达到更高的从单推理节点到KV Cache存储集群的带宽,从而实现更好的推理加速效率,此处不再详述。
测试场景4 Prefill Only, 与高性能分布式文件系统(DFS)做KV Cache的方案对比
在本次测试环境中,也同时测试了某存储大厂基于其高性能分布式文件存储实现的KV Cache方案(以下简称DFS),DFS的测试与WQS测试场景1的测试配置和过程基本一致,使用了相同的8卡 H20推理服务器,相同的网络配置,基本相同的测试参数,但是在存储硬件上有如下区别:
DFS使用了3台高配的存储服务器组成分布式文件系统集群。而WQS只使用了1台2U的JBOF+6张DPU,JBOF自身无CPU和内存,WQS完全运行于DPU内,每张DPU是16核48G内存,其使用的物理资源要远少于DFS方案。
现在将WQS以及DFS的测试结果放到一张图上做一下对比分析:
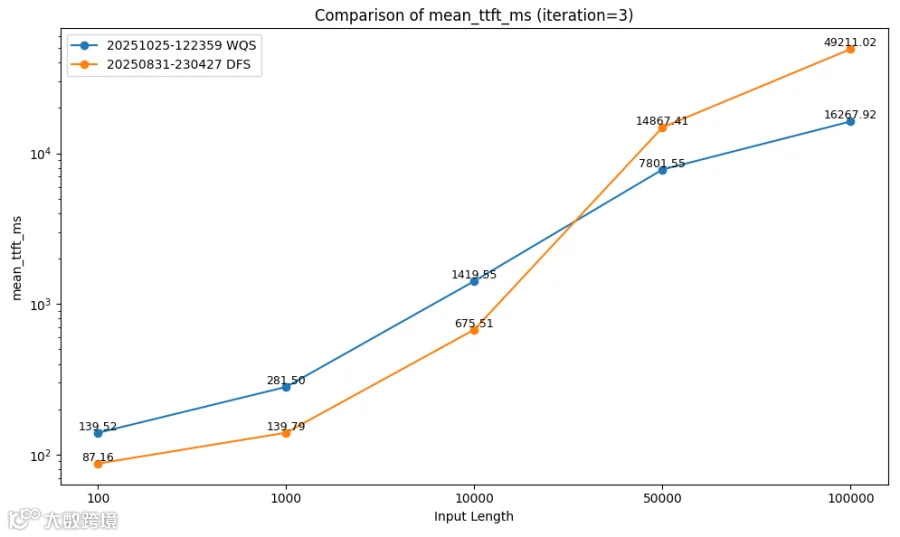
TTFT对比:WQS 400Gbps (蓝线) vs. DFS 400Gbps(橙线)
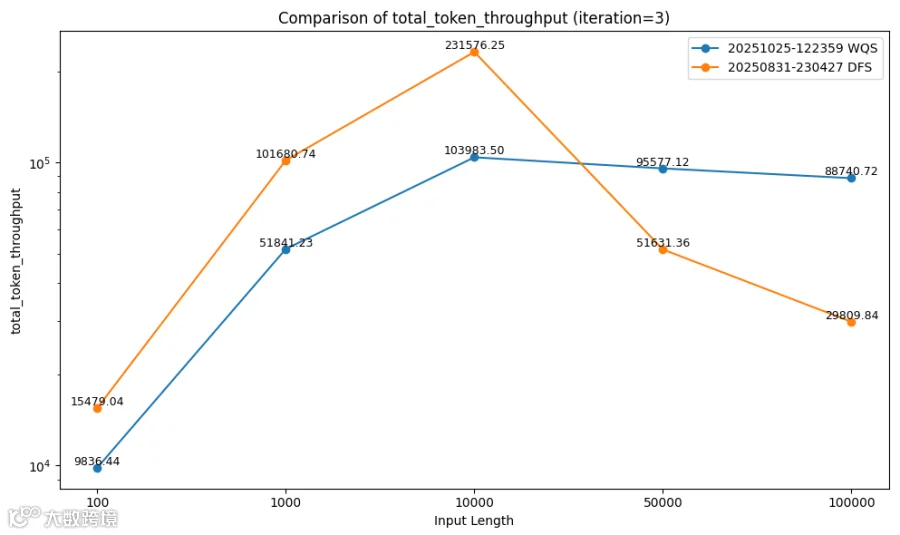
Token Throughput对比:WQS 400Gbps (蓝线) vs. DFS 400Gbps(橙线)
从以上性能对比图上可以看到,WQS在序列长度>20K之后,TTFT及Token Throughput性能对DFS开始有明显优势,在序列长度为100K时,WQS方案的TTFT为16267.92ms, 而DFS方案的TTFT为49211.02ms,WQS把TTFT时延缩短为DFS的1/3;WQS方案的Token Throughput为88740.72,而DFS方案的Token Throughput为29809.84,WQS把Token Throughput提升为DFS的3倍。在小序列长度时,DFS的测试数据比WQS要好一些,分析可能是由于内存缓存配置或推理框架配置不同带来的性能差异,此时KV Cache的容量不大,大量的KV向量在内存即可命中,外置分布式存储池的优势没有充分发挥。
这个对比测试,验证了WQS采用原生KV接口+原生分布式KV Storage实现KV Cache相较于传统存储厂家基于高性能分布式文件系统实现KV Cache方案的优势:WQS在吞吐量,时延以及存储资源占用和消耗等方面均有优势,尤其是在中大规模推理集群,长上下文,长prompts序列等场景下将有显著优势。
WQS采用的原生KV接口+原生分布式KV Storage的实现方式还有一个优势:具备极高的小IO随机读写性能,同时还能达到大带宽。而高性能分布式文件系统,尤其是并行文件系统,在架构上了强化了大IO大带宽能力,而处理小IO随机读写的能力就比较差。KV Cache针对KV向量的读写,本质上是一种中小IO的随机读写,因此WQS更加适合KV Cache的IO特征,推理框架因此可以把KV Blocks组织成更小的块(即一个Block中包含更少个数的Token), 从而有更多的命中前缀缓存的机会,可以很好的提升KV Cache的命中率。在本次测试中,由于测试用例的设计是KV Cache缓存全命中,采用的是很大的KV Block(1个Block包含256个Token),因此测试结果未能体现WQS在小IO随机读写上面的优势,这个有待在后续的测试中进行验证。
本次实战测试,验证了WQS KV Cache Storage在AI推理优化和加速方面的显著价值。测试结果表明,WQS最高可以将AI推理系统的TTFT降低至原来的1/20,Token吞吐量提升超过20倍。同时也验证了华瑞指数云原生KV Cache Storage相较于基于传统存储方案实现KV Cache部署的巨大优势。实战数据证明,使用AI推理集群的同时,如果配置部署和使用KV Cache Storage,将带来显而易见的推理性能优化,大幅降低推理时延,提升Token吞吐量,减少推理算力消耗,获得可观的经济效益。
欢迎部署和使用AI推理服务器和集群的企业客户,智算中心,算力服务商等与华瑞指数云团队联系,进行联合测试和生产实战。
也欢迎专注于AI推理系统优化,熟悉AI推理框架的团队与华瑞指数云团队联系,共同进行技术创新合作,进一步实现AI推理框架到外置KV Cache存储的全路径流量优化,流水线预加载,内存融合共享,HBM经KV接口直通外置KV存储等。
华瑞指数云ExponTech AI 系列专题内容将持续更新,敬请关注!
AI系列专题 | 上篇:揭秘AI原生KV Cache Storage如何实现超20倍AI推理加速
