摩尔定律
摩尔定律最早由英特尔创始人之一戈登·摩尔(Gordon Moore)提出,是对行业发展轨迹的观察和预测。其核心内容是:当价格不变时,集成电路上可容纳的元器件数目约每隔18–24个月便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的性能,将每隔18–24个月翻一倍以上。
曾就职于英特尔的首席架构师 Bob Colwell 曾预测,2020年可能是摩尔定律最早的终结时间,这主要是基于对物理极限的判断。当晶体管栅极长度(可通俗理解为电流通道的“开关”宽度)缩小到例如3纳米级别时,其绝缘层可能仅有几个原子层厚。电子会因量子力学中的“隧穿效应”直接穿过本应绝缘的栅极,导致电流泄漏。这使得晶体管无法可靠地开启和关闭,开关性能下降,功耗增加,可靠性难以保证。
然而,人们对于算力的追求不会就此停止。半导体行业的所有企业都在思考如何能在提供更多算力的同时,降低成本和能耗。
单片芯片还是芯粒?
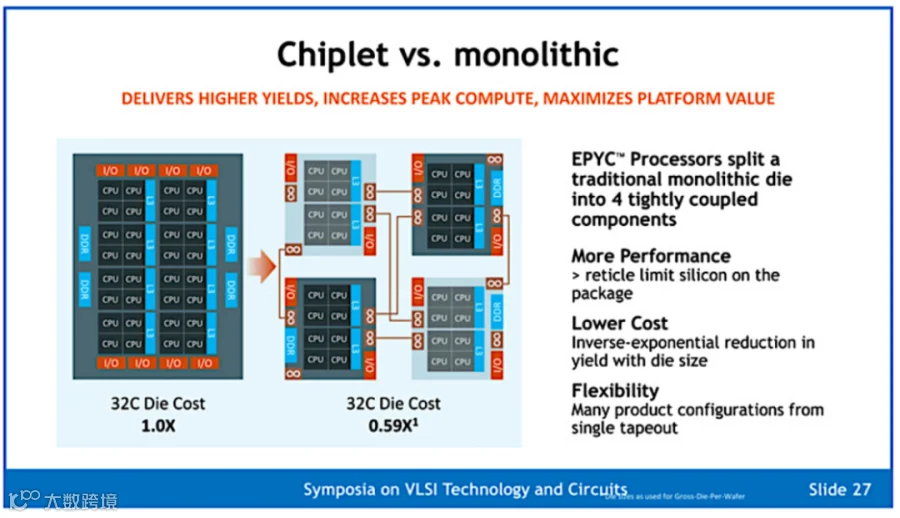
传统芯片制作采用“单片芯片(Monolithic Chip)”模式,即将所有计算核心、缓存、控制器等部件都集成到一块大的硅晶圆上,形成单一芯片。这要求整个芯片完美无缺,任何微小缺陷都可能导致整个芯片报废,因此芯片越复杂,制造难度越高,良率越低,成本也越高。
“芯粒(Chiplet)”提供了另一种芯片制造路径。AMD 是该技术的主要推动者和商业化应用的先行者,其做法是将大型芯片拆分成多个更小的、功能独立的“芯粒”,分别采用最适合的工艺制造,最后通过先进封装技术集成在一起。芯片组能够提供与顶级单片芯片几乎相同的性能,但价格可以便宜40%。这是因为如果生产过程中出现故障,企业不必扔掉整个芯片,只需丢弃一个或几个芯粒即可。这种路径因此具有更高的良率、更强的灵活度和更低的成本。
这又是一个“创新者窘境”的经典案例。成功的成熟企业往往过于专注倾听现有客户的需求,不断进行“渐进式创新”,却忽略了那些最初性能较低、利润较薄、市场较小的“颠覆性创新”。当这些颠覆性技术逐渐改进并最终满足主流市场需求时,原有企业便难以招架。
回想大约2014年,当许多人还认为芯粒战略是个糟糕主意时,AMD 却毅然选择了这条道路。如今,英特尔和英伟达都在转向芯粒技术,但 AMD 在这方面已经深耕近十年。在此期间,AMD 所积累的无数业务流程、企业文化要素和集体智慧,将成为其未来发展的宝贵财富。
在半导体行业,一个研发周期长达数年,一旦技术路线选错,即使有最优秀的工程师,也可能满盘皆输。因此,必须有人决定未来5年的战略,并且公司必须做正确的技术押注。
AMD的收购
近些年,AMD 巨资收购了 Pensando 和 Xilinx,那么这次他们又在赌什么呢?我非常认可 Antonio Linares 的观点:AMD 在构建一套更完整的“智能数据中心”生态。与其从 CPU(处理通用计算)和 GPU(处理图形/AI 计算)的视角来理解芯片公司,不如从“计算是什么”的角度来思考。计算的本质是让数据在电路中流动、计算,并从数据中得出有用结论,比如 AI 预测。
Pensando
先从 Pensando 说起。随着“物联网”发展,越来越多的设备(如手机、传感器、汽车、家电)可以连接到互联网,产生海量数据。这些数据需要被处理(用 CPU/GPU 计算)来提升生产力,比如优化工厂生产、预测用户行为等。但 CPU/GPU 的性能再强,如果它们孤立运行,缺乏高效的网络和系统支持,也无法充分发挥作用。它们需要一个“高度连接、能自我优化”的环境,这个环境就像一个“超级大脑”,能高效管理数据流动、自动调整资源,让 CPU/GPU 的计算能力最大化。
想象一下,一个电商网站(大型应用程序)是一幢大房子,所有功能(购物、支付、库存管理)都集中在里面。而微服务架构则是将这幢房子拆分成许多小公寓,每个公寓负责一个具体任务,比如购物逻辑在一个公寓,数据库在另一个,支付系统在第三个。这些小公寓通过网络互相通信、协作完成整体工作。这些拆分后的小公寓,就叫做微服务。
微服务架构的普及标志着数据中心从2010年起发生了一次重大变革。2010年以前,数据中心是“裸机”模式:服务器是实打实的物理机,主要处理南北向流量,即客户从外部(北)访问数据中心(南)获取数据。
但随着云计算的兴起和服务器虚拟化技术的成熟,应用被拆分成微服务,使系统更灵活、更容易扩展和维护——因为更新时只需调整一个小部分,而不用改动整个系统。然而,这种变化也带来了一个意想不到的副作用:内部通信流量急剧增加。
继续用房子比喻:南北向流量像是客户从大门进出取东西(外部流量);东西向流量则像是小公寓之间互相串门交流(内部流量)。例如,购物公寓要查询数据库“库存还有吗?”,数据库再询问支付系统“钱够吗?”,这些内部通信就是东西向流量。
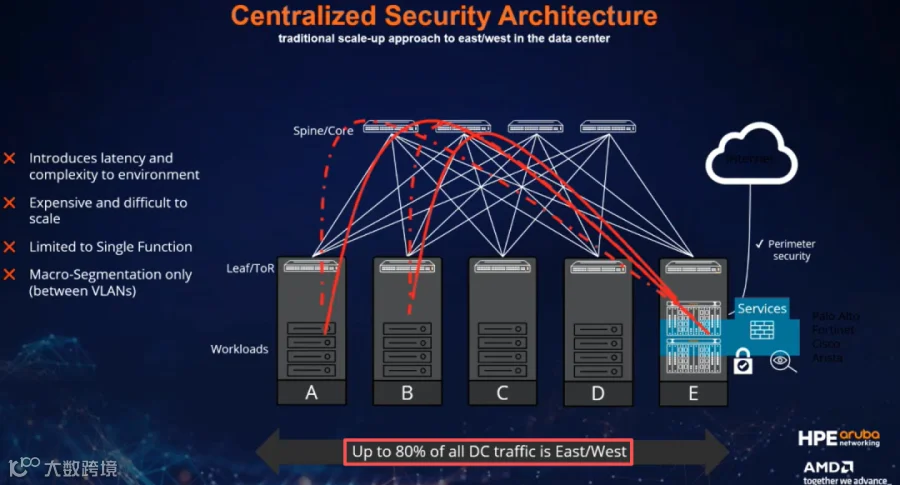
这不仅仅是流量的增加,更是流量类型的转变。东西向流量的增多,意味着数据中心不再是一个简单的仓库,而更像一个生态系统:服务之间依赖复杂,一个小问题可能引发连锁反应,影响整个系统。过去管理南北向流量可能只需设置防火墙“堵住大门”;而现在管理东西向流量,则需要管理交通信号灯、监控摄像头、修路等。运维人员必须手动配置和监控成千上万的服务,规模扩展时挑战更大。
AMD 收购的 Pensando 正是为了应对这种复杂性。Pensando 有一款 DPU(数据处理单元),设计用于卸载数据中心的网络、存储和安全任务。它将这类“琐碎”工作从传统的 CPU/GPU 中分离出来,让主计算资源专注于高价值计算,如 AI 训练。
但对 Pensando 来说,其产品不只是硬件。Pensando 约90%的工程师是软件工程师,他们构建了一个完整的软件栈,覆盖从企业到云的各种需求。Pensando 提出过“状态化(statefulness)”理念,即系统或服务能够“记住”并跟踪之前的交互、上下文和历史信息,而不是每次处理请求都像“失忆”一样从零开始。这种“记忆”能力让数据中心能更智能地处理复杂流量(尤其是东西向流量),从而简化管理、提升效率。状态化意味着数据中心能“记住”自身的运行状态,AMD 强调,这能“杀死复杂度”。
在 AMD Pensando 的框架下,数据中心在处理南北向(外部进出)和东西向(内部服务间)流量时生成的海量元数据,是通过 DPU 硬件及其配套的状态化软件服务来实现的。这个过程的核心在于 DPU 的“状态化”设计——它不只是被动传输数据,而是主动监控、记录和分析流量,从而产生有价值的元数据。这些元数据可用于训练机器学习算法,帮助数据中心实现智能化、自动化运维,最终化解微服务带来的复杂度,让数据中心像一个能够“自愈”的智能系统。
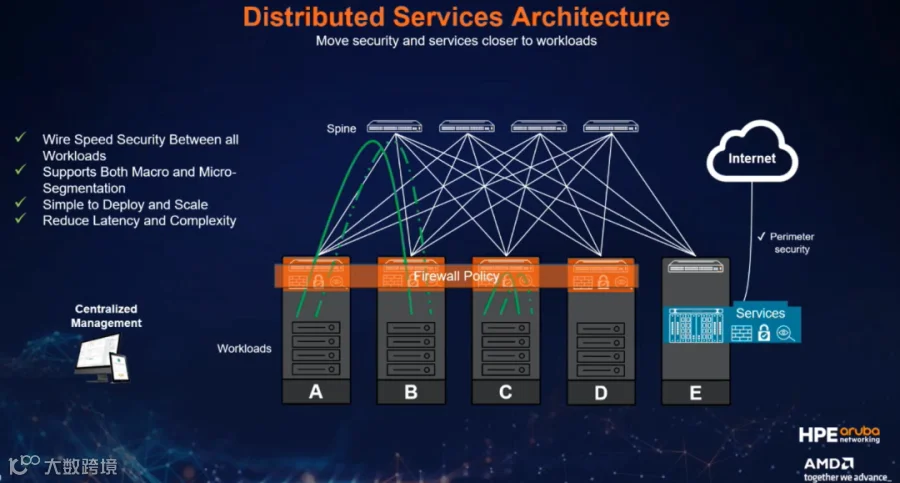
Xilinx
那 Xilinx 又能给 AMD 带来什么呢?Xilinx 专注于制造 FPGA,一种可重构电路的芯片。FPGA 非常灵活,无需从头制造新芯片,只需编写代码,就能让 FPGA 变成所需的“定制工具”。与 FPGA 类似的是 ASIC 芯片,ASIC 可视为定制芯片,适合大规模量产,但灵活性稍差。不过,无论是 ASIC 还是 FPGA,在执行 AI 模型推理方面都比 GPU 更具优势。
简单来说,AI 如同一个数学机器,有两个主要方向:
-
向前执行 Forward propagation(推理) -
向后学习 Backward propagation(训练)
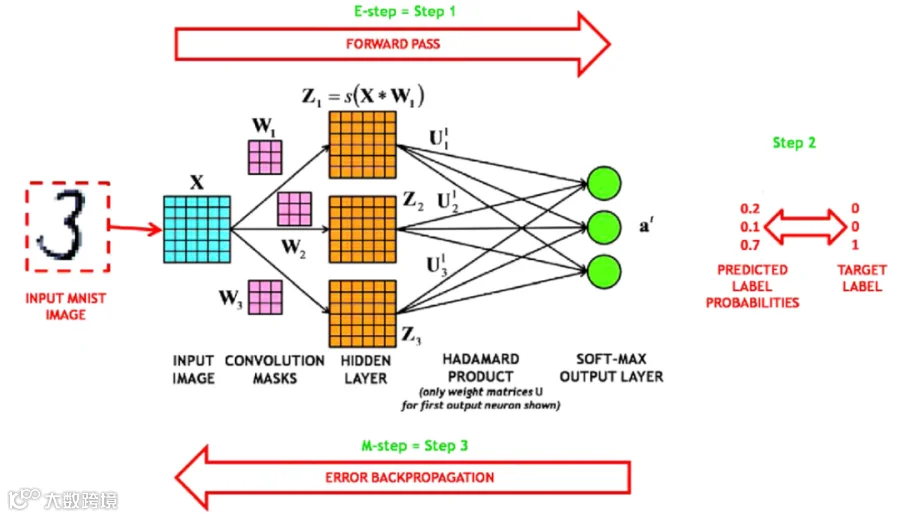
在向前执行中,数据通过神经网络向前传递,它对数据执行大量的乘法和加法运算(高中线性代数)。它通过为每个操作分配权重来赋予某些操作比其他操作更高的重要性。
在向后学习中,神经网络计算其错误的程度(将输出与标签进行比较),并反向工作以改变它分配给向前执行过程中每个操作的权重。
向前执行正是 FPGA 所擅长的,因为仅需加速线性代数计算;向后学习(训练)则需要处理复杂的多元微积分,而这是 GPU 的优势领域。GPU 擅长训练,但推理才是未来市场的大头。一旦我们用数据训练出一个 AI 模型,只有能够以合适的成本进行推理,这个模型才能真正发挥作用。FPGA 在推理方面更省钱、更灵活,能低成本适应不同的 AI 模型。
想象一下,如果数据中心是一个大型建筑工地,正在建设一座高楼大厦。CPU 就像工地的项目经理,负责整体规划、调度资源、处理杂事,但不擅长“大规模重复劳动”。GPU 就像一队大型挖掘机,专门处理“大规模、重复性强”的重活
,它们并行工作极快,因为可以多台同时作业,短时间完成大量任务,但不够灵活:挖掘机只能挖土,不能轻易变成起重机。FPGA 则像一批乐高积木,可以通过软件“编程”随时变形:一会儿变成挖掘机,一会儿变成起重机,一会儿变成测量仪等。它不擅长重型任务,但在“特定、重复但不那么复杂”的任务上非常高效。
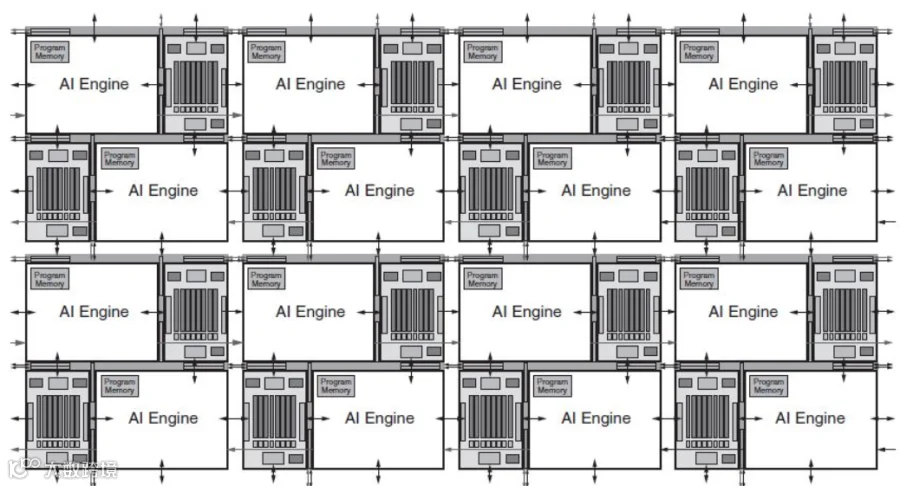
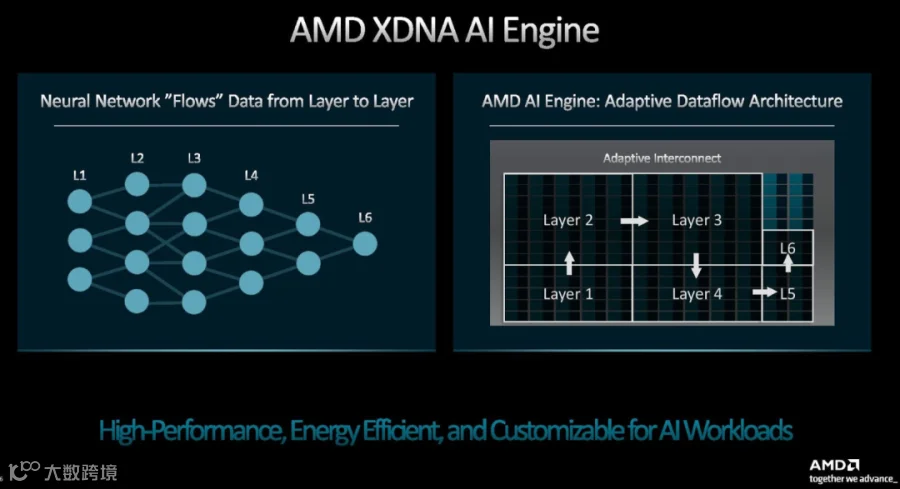
现实中,当 CPU 遇到海量数据(如 AI 计算)时,会变慢或需要协助。GPU 擅长图形渲染和 AI 训练,也能做 AI 推理,但由于其设计较为“重型”,在很多场景下会浪费电力。FPGA 是可编程硬件,能通过代码改变电路结构,擅长 AI 推理(如矩阵计算),比 GPU 更省电、更快,还能适应不同的 AI 模型(比如从图像识别切换到视频分析,无需更换设备)。AMD 在2022年收购 Xilinx 后,宣布将 Xilinx 的 FPGA 技术 AI Engine 集成到其 CPU 产品线,并于2024年推出 Ryzen AI 系列。