
4月25日,KMind联合创始人于开丞参加第八届万物生长大会,分享主题演讲《未来的AI互联-人人都是数据的主人》。以下为演讲全文,略有删改。

大家下午好!很荣幸今天在这里代表半个宇宙,也代表西湖大学做一个我们对未来的畅想,未来的AI互联。
此时此刻,应着万物生长大会的主题,大家提到了“生长”这个词,我们也在想,互联网发展到了现在这个阶段,在下一个阶段我们有怎样的生长,看到一个新的机会,可能也应着我们的slogan—“人人都是数据的主人”。
如果谈到未来,可能先要看一下现在互联网的发展模式。互联网从1990年左右诞生到现在,极大程度上便利了大家的生活,以前我们买一个东西可能需要线下去访问一个商店,后来进入从以淘宝为代表的电商时代,打开一个手机就可以直接找到对应的商品,互联网从非常大的程度上在现代生活里提供了相当大的便利。但是现在我们发现当我们的需求和商店的需求都在和中心节点进行交互的时候,会有一件自然而然的事情产生,那就是所有的信息都是通过互联网中心节点进行交互,也就意味着产生的数据,包括我们上传的图片、使用记录,都被记录在这些中心节点当中。
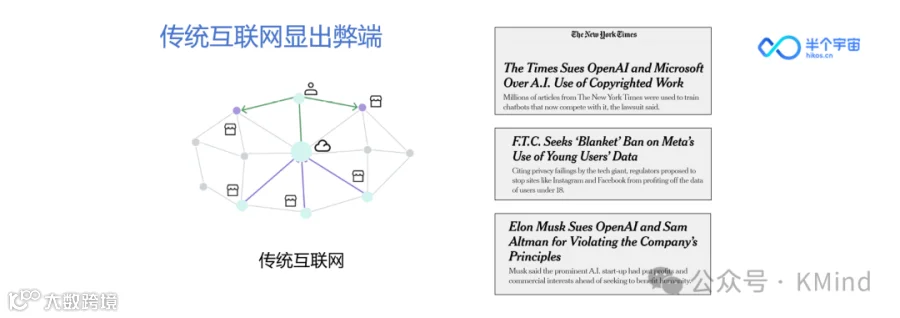
这本身是没有问题的,直到最近我们发现人工智能的一个重大的突破,ChatGPT,它可能会产生另外一个潜在的新现象。右边的这张图(上图)是同一个新闻的三个不同的表征,就是说我们在美国会发现《纽约时报》在去年年底起诉了OpenAI,原因就是说它认为OpenAI在没有经过准确的获取下,用了《纽约时报》的语料去训练了ChatGPT,从而使ChatGPT获得了非常好的语言表征能力。我想,这就是一定程度上,我们能够看得到的一个潜在的事情,我们产生的数据,最终的价值并没有服务于产生数据的用户自己。《纽约时报》作为一个非常大的报社,可以以集团的名义去起诉OpenAI,但是我们普通人又怎样去守护我们数据的价值和利益呢?
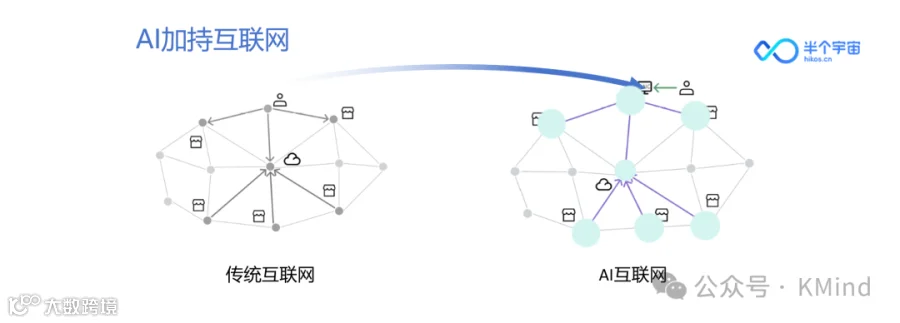
在这个时候,我们就认为在另外一个情况下,GPT以及它衍生的大模型产物,在很大程度上让我们看到了未来的一种可能性。如果我们在未来有一天,可以用智能体的方式去加持我们,是否我们个人作为用户自己,就可以让数据的价值从互联网的中心节点转移到自己的手中。
为了实现这样的目的,我们畅想了这个未来的愿景,就是说现在的互联网时代,我们可能还是以大的中心节点方式变成了如果未来有一天智能体可以帮助我们去世界上获取我们所需要的信息,并且它可以用一种聪明的方式,不暴露我们自己需求的方式去获取这些信息,是否就能做到未来的那种状态。也是因为这一点,我们希望有一天我们可以把这些数据产生的价值在大模型的帮助之下,让它回归到每一个使用网络的个体当中。
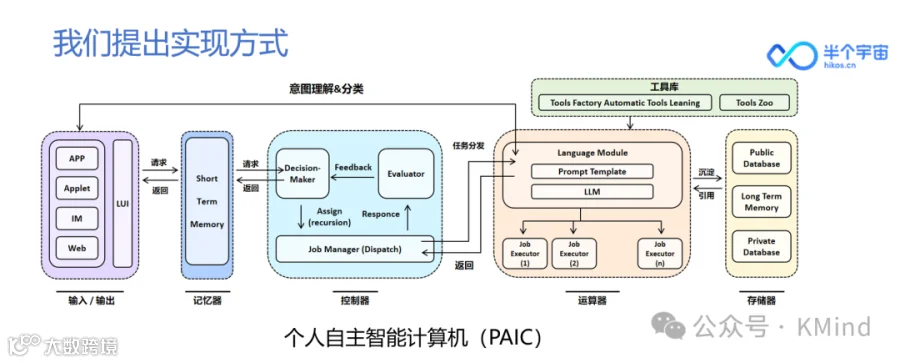
基于这个愿景,我们提出了一个实现的方式,叫做个人自主智能计算机的平台,这张图片(下图)稍微有点复杂,但是本质上我们的平台就是在做下面这件事情。右边是这个平台可能具备的大概元素,基于冯诺依曼的架构为基础,从输入到输出,这完全是和正常计算机非常类似的。可能与现在的计算机强调的CPU不同,我们在新的架构里,希望大模型里在我们新的PAIC架构里作为了一个中央处理器,可以让大语言模型自如地按照用户定义的意志去处理各种不同复杂的数据任务。以及最后我们希望这个PAIC可以在云端部署,不需要像AI硬件一样,一定要把大模型放在本地化部署,这是一件非常困难的事情,我们希望它也可以提供一种在云端部署的环境,可以提供这种可扩张的定制化功能。

如果我们能够提出这样的一套架构,本质上还是希望能够帮助用户怎么样去更好地、更高效地处理自己的数据。很多人在问我一件事情,做一个大模型不就可以了吗?为什么不做另外一个大模型去处理我们所有的事情?针对这一点,我们有一个自己的小小考量,最近有一个说法,如果在全世界的人都用同一个中央大模型处理自己的信息,本质上就是给统一的人类社会达到了一个统一的意志,这个超级智能可能会比所有其他智能体加起来的能力都要强大,这件事情从另外一个角度来讲,是一件非常令人恐惧的事情。
我们这边可能更多的是希望能通过不同的技术,通过刚刚说到的PAIC架构,能实现的是在大模型的底层技术层,可以自由灵活地切换到不同的大模型技术上,从而让用户可以比较放心地把数据交到这个架构上,因为它会把任务拆解成不同的子任务之后,自然而然的,可能也就不存在完整的数据直接上传到大模型里的泄露问题,从而一定程度上来缓解这个事情。
在我们提出这个架构之后,发现有另外一件事情可以顺手做到,这件事情就是我们另外一个大家在用大模型时谈到的幻觉问题。虽然说我们没有办法完全解决幻觉的问题,因为幻觉的产生如果从原理上来讲,是因为它是一个统计学模型,统计学模型就一定是会有概率会失败的,所以从很多维度来讲,幻觉问题是无法根除的。但是我们会发现,在大模型时代里来讲,幻觉的表现上来看就是用户的输入和之前的内容产生了一些矛盾,或者说它没有办法完全跟随我们的指令,没有办法和已有世界的物理知识进行交互。
为了应对这件事情,我们的出发点就是这件事情,原因是大模型是连接主义这种概念设计的一种统计学模型,它一定会有一定的问题。反过来讲,前面的报告嘉宾也讲到了,自古以来,从象棋开始,一直以来有一套专家系统,一套符号主义的东西。这套符号主义的内容就是一个完全可以经过多轮校验的准确知识,那么我们是否可以把这两个连接主义和符号主义进行一个结合,从而实现新型的事情。
举例来说,这是我们下面要放的例子,如果我们把一个西游记的片段直接丢给一个大模型,问它在西游记的这段话里,孙悟空出现了多少次。经由新型的计算机架构之后,首先可以把这段文字变成一个类似于知识图谱一样的图结构的表征,在这里面每个孙悟空的节点都会被准确的符号主义的形式保留在那里,这样就可以用一些简单的规则知道,精准地数出来这个任务,幻觉问题会得到极大的缓解。我们可能在这里面就叫了它“神经符号主义”这个新名词。也就是说,我们希望未来可以将知识图谱这种用户转化为可验证的图结构,实现降低技术幻觉的模型。
有一个例子,请观看视频。
我们把刚刚数西游记的这个例子给大家展示一下,首先可以键入一段简单的文字,然后它会很快地把文字转化成可以验证的图。这张图里可以看到每一个节点是人物关系,我们可以准确地数出来这段话里孙悟空出现了31次,但是如果我们把这一段话放到任何一个其他的大模型里,可能就没有办法每一次都准确地数到31次。
说到这里,刚刚提到的是如何准确地、可控地、可信地把个人数据按照个人意志进行处理,刚刚展示的片断只是一种能力的展示,因为它本质上就是连接主义和符号主义的结合。那么,符号主义的这个过程完全可以通过各个不同用户的需求而进行定制,之后就可以实现数据精准控制的能力。
下面,我们一个未来的畅想,就是说如果未来有一天,在计算机网络里的节点,如果有越来越多的用户数量的增加,PAIC的使用量也好,或者说其他的大模型使用量也罢,这样的增加就构成了一个新型的神经网络架构,这个架构就是一个很简单的事情。在我们原来的例子里,刚刚说每一个小人边上可能会有一个人工助理助手,这样的人工助理助手越来越多的情况下,助手和助手之间甚至是可以进行互联的,从而完成一个可以去人化的高效信息传递的过程,这也是我们可能会认为未来互联网的一种表征形态。
用这种新的架构,也可以实现本地的数据加密,以及信息源头的直接交互,以及最终我们希望能够给个人用户带来的价值也就是如此。以刚才买东西的例子为例,如果今天我们想买一罐奶粉,一是去问线下的商店超市,二是去云端互联平台,找一些商品信息。整个范式来讲,就是一种人找信息的范式,在大量的时间里都是我们主动去搜寻不同的信息,自己进行一个汇总。但是在互联网时代下,有一件比较麻烦的事情,就是在这种大量的用户节点产生大量数据的前提之下,一个人已经很难去处理网上所有的相关信息了。比如说,我们打开一个购物网站,输奶粉,可能有一两万条不同的奶粉信息,作为人类个体怎么可能把所有的网站信息都浏览完毕呢?这是不可能发生的事情。那么,必然我们只能更相信平台推荐给我们的信息,这些信息里往往就会混杂一些或许不符合我们需要的信息。
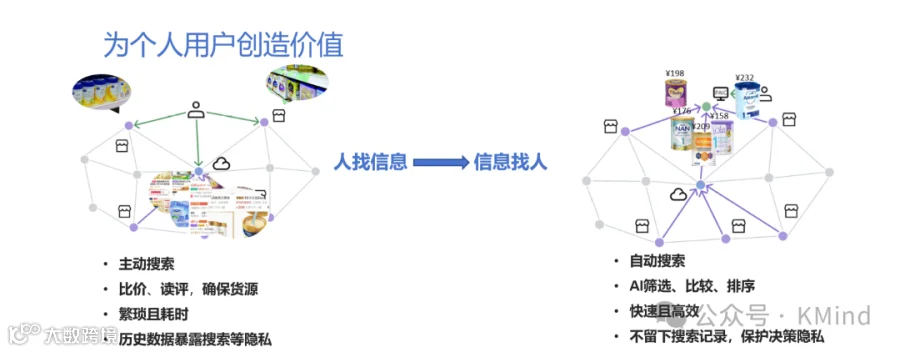
在新的时代下,我们更期望的是未来有一天,人找信息的范式从主动搜索,去比价、去确保货源、去阅读,繁琐而耗时的状态,变成一种新型的信息找人的范式。在这个范式里,只需要和助理、和AI计算机说一声,它会根据我们所指定的网站找到我们所需要的各种信息,甚至未来有一天可以帮我们打电话问隔壁的商店是否有货。我们作为用户,最终进行阅读和比较,就可以实现一种自动的搜索,并且用AI的筛选比较和排序,非常快速且高效。而且通过一些技术手段,我们也可以不留下搜索记录,保护我们自己的决策隐私。
这里面有一个最核心的消息,也是我们对最近这件事情的期待,就是我们希望能把这种搜索,原来只能存在于大型的互联网节点的技术,真正地带到我们的个人手里,让我们也能享受到AI带来的一些技术上的红利。
最后,我们最终的愿景是让数据为个人创造价值。
谢谢大家!
于开丞个人简介:
西湖大学助理教授、特聘研究员,人工智能企业KMind联合创始人兼首席科学家
香港大学工学学士、瑞士洛桑联邦理工大学计算与通讯科学理学博士、高通创新基金(欧洲当年仅 4 人)获得者,于国际著名期刊、会议发表十余篇论文;2021年以阿里星人才项目加盟达摩院自动驾驶实验室;2022年入选杭州市海外高层次引才计划;2023年加盟西湖大学担任助理教授、博导,组建自主智能实验室(AutoLab),并作为联合创始人兼首席科学家联合创立人工智能企业KMind。