赵晓平1,3, 徐文波1, 刘涛2, 邵凡2
(1.南京信息工程大学 计算机学院,江苏 南京 210044; 2.南京信息工程大学 自动化学院,江苏 南京 210044;3.南京信息工程大学 数字取证教育部工程研究中心,江苏 南京 210044)
doi:10.19708/j.ckjs.2022.11.327
引用格式:
赵晓平,徐文波,刘涛,等.基于迁移学习的小样本齿轮箱故障诊断方法[J].测控技术,2023,42(6):52-62.
摘要
实际工程场景中齿轮箱受工况、环境等因素影响,数据难以满足特征分布相同、训练数据充足等条件,如何在变工况情况下对齿轮故障进行诊断是故障诊断领域一大难点。为此,提出了一种结合Logistic混沌麻雀搜索优化算法(LSSA)与深度置信网络(DBN)的智能故障诊断方法,即LSSADBN。首先,将时域振动信号进行快速傅里叶变换(FFT)转换为频域信号作为训练数据集,运用Logistic混沌映射对SSA种群进行初始化,采用LSSA方法对训练数据集进行DBN结构寻优;使用最优结构DBN对源域训练集进行预训练,并加入少量目标域样本用于反向权重调优,最终实现在小样本情况下对目标域齿轮箱健康状况的准确识别。实验对比结果证明,LSSADBN方法在模型调优阶段具有更快的收敛速度,且针对不同的目标域进行迁移时都具备较高的准确率,LSSADBN方法的研究对小样本情况下的齿轮箱故障诊断具有一定的应用价值。
关键词
齿轮箱;麻雀优化算法;深度置信网络;小样本;迁移学习
齿轮箱作为大型机械设备中被广泛运用的集成部件,其保持健康的机体和良好的运转情况是机械设备正常运行的重要保障。因齿轮长期处于连续工作状态且工作环境极其恶劣,故很容易发生故障。据统计,齿轮箱的多个组成元件中,齿轮和轴承的故障发生率最高,分别占总故障率的60%和19%。一旦产生齿轮损坏,轻则使机器发生故障延误生产,重则导致重大事故甚至出现人员伤亡。因此,精准地对齿轮的健康状态做出诊断并及时进行更换,对排除安全隐患具有重大意义。
近年来,通过“数据驱动”方式对模型进行训练的深度学习方法在故障诊断领域取得了极大的成就。然而,基于“数据驱动”的故障诊断方法依赖大量的有标签数据对模型进行训练,而实际工程场景中,对齿轮箱故障振动信号进行采集往往会面临诸多问题:一方面,所采集故障信号的质量优劣取决于传感器的安装位置、机械设备的运行状态等因素,精密仪器难以布置传感器且部分大型机械设备在出现严重故障时,不具备继续运行以进行信号采集的条件;另一方面,出于对生产安全性的考量,机械设备往往不被允许在故障状态下长时间运行,而频繁停机进行故障信号采集不仅延误生产而且会大幅增加设备的运行成本。上述问题导致了健康状态下的振动信号重复率高,某些故障状态的监测数据难以获取,典型故障数据稀少或缺失等问题。在此情况下,普通的故障诊断模型会面临缺少典型故障样本可供模型训练而导致的诊断精度较低、泛化性差等问题。
为解决上述实际工程场景中的问题,国内外专家学者对基于深度迁移学习的故障诊断问题进行了大量研究。现阶段,解决迁移情况下的故障诊断问题需要在网络中添加域适应模块、调整域间距离,以及进行样本迁移、特征迁移等。Guo等提出深层卷积迁移学习网络,利用一维卷积神经网络进行特征提取并结合域自适应模块,同时最大化领域识别错误和最小化概率分布差异,在对6种工况进行迁移的情况下取得了86.3%的平均准确率。Tong等提出了一种在变工况条件下使用的特征转移学习方法以进行领域自适应,减小了边际分布和条件分布,从而获得可转移的数据特征,使得提取的特征具备极强的可分性和聚类性。李俊卿等将振动信号转换为时频图,利用卷积神经网络进行特征提取并保留其底层特征,使用不同样本进行参数微调以实现小样本情况的故障诊断,模型的预测误差低于5%。然而,上述方法在实验中要求源域样本充足,当训练样本不足时,分类精度将有所降低,模型的鲁棒性较为一般。此外,上述模型结构较为复杂,计算量大。
在实际工作场景中,数据很难满足特征分布相同、训练数据充足等条件,所以迁移学习在小样本条件下的应用变得越来越重要。谢旭阳等迁移Inception-V3网络结构,对其全连接层和输出层进行微调,在小样本情况下,采用3种电机振动信号分别作为输入的准确率达到了98.8%、100%、100%。陈仁祥等利用原始信号频谱作为深度置信网络(Deep Belief Network,DBN)输入,逐层更新权重并用少量目标域标记样本对其进行权重微调,在数据不充足情况下可以取得92.8%的诊断准确率。Zhang等在通过预训练得到特征提取器后,在反向传播过程中对特征提取器的非约束自适应层进行参数微调,在多个不同的域迁移诊断任务中的平均准确率达到82.62%。然而,上述方法需要人工对模型各层参数进行设置,十分依赖专家经验,对于不同数据的适用性较差。
针对上述不足,为了解决实际应用中训练样本严重不足以及难以自适应获得模型参数的问题,提出了一种基于混沌麻雀搜索优化算法(Logistic Sparrow Search Algorithm,LSSA)与DBN的迁移学习方法,即LSSADBN故障诊断模型。本方法运用麻雀搜索优化算法(Sparrow Search Algorithm,SSA)对DBN每层的节点数以及预训练和微调(Finetune)过程的学习率进行寻优,在进行SSA的参数设置时,使用Logistic混沌映射对麻雀种群进行初始化,从而使麻雀种群分布更加均匀,在避免陷入局部最优的同时加快优化过程的收敛速度。获得最优节点数和学习率后,使用优化过的DBN对训练集进行预训练,并在反向Finetune过程中加入少量目标域样本进行参数调优,最终完成在小样本情况下对目标域齿轮箱健康状况的准确识别。相较于现有的深度学习故障诊断方法,LSSADBN方法具有3个优点:① 迁移过程根据数据自适应调整网络隐藏层节点数量,避免个人经验对实验结果的误导;② 对工况、设备运转情况改变的敏感度较低,可以有效提高迁移学习情况下的故障诊断准确率;③ 通过少量辅助样本微调模型参数的方式,减轻了模型训练过程中对数据量的依赖。经实验证明,LSSADBN故障诊断模型收敛速度更快,在保证识别准确率的同时可以自适应完成网络超参数调整。
1 理论基础
1.1 迁移学习问题描述
迁移学习是一种适用于多领域多功能的新兴技术,其主要通过对现有的模型、算法等进行微调来实现。迁移学习的运用放宽了机器学习的2个重要要求:① 用于训练的样本与测试样本满足同一条件分布;② 必须具有足量的训练样本才可以获得性能优异的模型。在迁移学习时,源域数据DS往往与目标域任务TT相关性较低,DS主要通过训练解决源域任务TS,其数据量一般较大,而目标域数据DT往往与目标域任务TT相关性较大但数据量较小,即要求DS≠DT,且TS≠TT 。
本文的目标是搭建一种可根据源域DS和目标域DT数据变化,自适应调节超参数的可移植、可迁移模型,利用优化算法求得最优的模型参数后,保留源域、目标域的不变特征,通过少量DT对模型进行参数微调,最终实现源域和目标域分布不同情况下的准确分类,并用以完成小样本情况下的齿轮箱迁移诊断任务。
1.2 LSSA
Logistic混沌映射是一种非线性映射,是混沌映射的典型代表,其映射呈现的结果分布密度相较随机生成更加均匀,表现为无规则的非随机映射,具有很好的遍历性、不可预测性和高度复杂性。
SSA在进行种群初始化时,主要采用随机产生的方式,而初始的种群位置将会影响到搜索算法收敛速度和寻优精度,通过Logistic混沌映射方法对SSA进行种群初始化,可以使种群的初始位置均匀分布。
LSSA优化步骤如下:
① 利用Logistic混沌映射策略初始化种群、迭代次数、捕食者和加入者比例。
② 将种群划分为发现者和加入者。
③ 计算适应度值并排序。
④ 更新发现者位置。
⑤ 更新加入者位置。
⑥ 随机选择侦察者并更新位置。
⑦ 是否满足停止要求,满足则退出并输出结果,否则重复执行步骤③~步骤⑥。
2 LSSADBN故障诊断模型
LSSADBN故障诊断方法通过源域信号对DBN进行预训练,训练过程中使用Logistic算法对DBN的结构超参数进行优化,并使用少量目标域信号对DBN进行权重优化,以实现变工况下的故障诊断。LSSADBN诊断模型如图1所示。
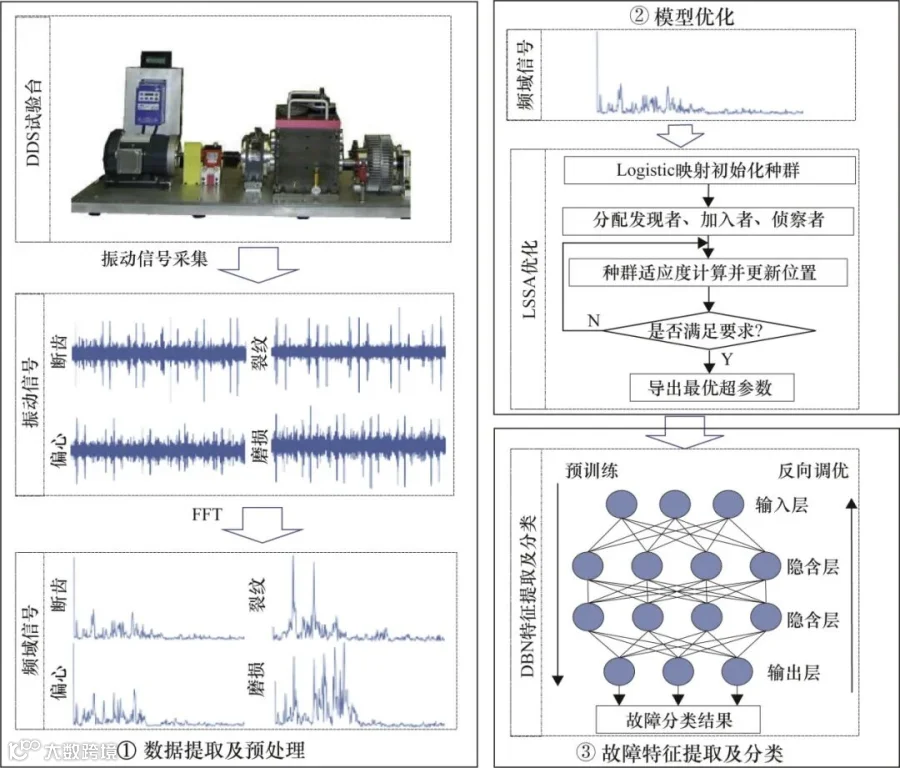
图1 LSSADBN诊断模型
LSSADBN诊断模型共包括数据提取及预处理、模型优化、故障特征提取及分类3个阶段。其中,数据提取及预处理阶段采用由传动系统故障诊断模拟器(Drivetrain Diagnostics Simulator,DDS)试验台采集的振动信号,通过快速傅里叶变换(Fast Fourier Transform,FFT)将时域信号转换为频域信号;模型优化通过LSSA参数寻优实现;故障特征提取及分类阶段利用LSSA寻优得到的超参数构建DBN,并通过少量辅助样本微调权重来完成故障诊断工作。
2.1 模型优化
在使用DBN模型对源域数据进行预训练前,通过LSSA优化算法对DBN各层的最优节点数以及预训练和Finetune过程中的学习率进行寻优。Logistic混沌映射是一个二次多项式映射。Logistic混沌映射的迭代过程为
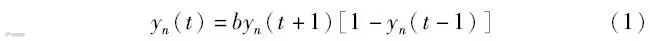
式中:yn∈[0,1];t为当前迭代次数;参数b的取值范围为1≤b≤4,b决定了Logistic混沌映射的演变过程。当参数b增大时,映射序列的取值范围也增大,使得映射分布更加均匀。Logistic混沌映射根据参数b的取值在[0,1]区间的映射范围如图2所示。从图2可以看出,当b取值为4时,系统处于完全混沌状态,此时映射分布均匀性达到顶峰。
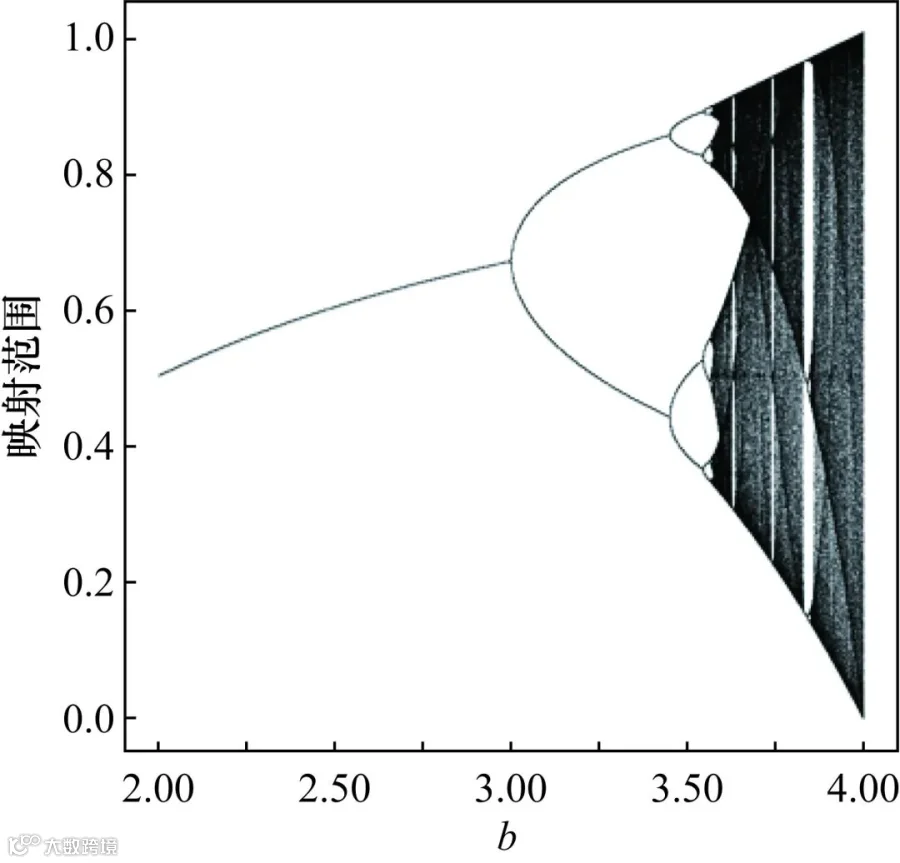
图2 Logistic混沌映射示意图
SSA将麻雀的种群分为发现者和加入者,发现者和加入者的角色可以交换但比例恒定。发现者在种群中主要负责寻找食物,同时也引导种群成员进入更好的觅食区域并提供更好的觅食方向;加入者利用发现者的信息前往更好的位置获取食物。发现者相比加入者拥有更好的适应度值,其位置更新规则为
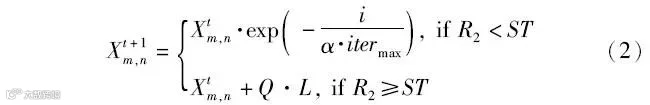
式中:Xm,n为第m只麻雀在第n维中的位置,n=1,2,…,d,d为解的维度;itermax为最大迭代次数;t为迭代次数;α为(0,1)之间的一个随机数;R2为寻优过程的预警值,R2∈(0,1];ST为寻优过程的安全值,ST∈[0.5,1];Q为服从正态分布的随机数;L为一个1行d列的矩阵,其内部所有元素都为1。此外,LSSA设置影响种群搜索方向的捕食者,当R2<ST时,说明未发现捕食者,发现者引导种群前往有更好适应度值的区域进行搜索;当R2≥ST时,说明发现捕食者,整体麻雀转向安全区域进行搜索。加入者时刻监视着发现者,根据发现者适应度值的优劣决定是否更新位置,更新规则为
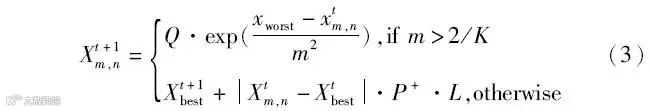
式中:Xworst为目前适应度最差的麻雀所在位置;Xtbest为当前迭代次数下的最优位置;P为一个1行d列的矩阵,其所有元素随机赋值为1或-1;K为麻雀种群的数量;当m>2/K时,说明当前加入者处于饥饿状态,需要去其他区域搜寻食物。
麻雀种群中随机产生侦察者,其数量占种群数量m的10%~20%,其位置更新为
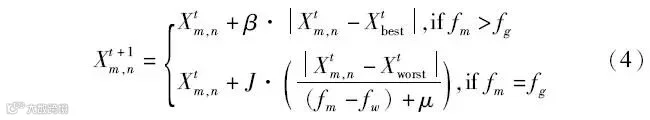
式中:β为步长参数,β∈(0,1),符合正态分布;J为种群的移动方向,J∈[-1,1];fm为当前个体的适应度值;fg为最佳适应度值;fw为最差适应度值;μ为极小常数,防止分母为0。
LSSA优化算法通过不断计算适应度值并排序、更新发现者与加入者位置、选择侦察者并更新位置等操作,在搜索空间内寻找到最优的节点个数和学习率。
2.2 故障特征提取及分类
为消除组成部件耦合性对实验的影响并解决高质量样本数据量较小的问题,选用具有强大的特征提取能力且能够自适应地发现更多高质量故障特征的DBN来进行故障特征的提取。DBN可以看作是多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)的顺序堆叠。
设置模型参数为δ=(W,aV,bH),其中W为各层的连接权值;aV为可见层结构的偏置值;bH为隐藏层结构的偏置值。故可用P(V,H;δ)表示可见层V和隐藏层H的联合概率分布,使用能量函数En(V,H;δ)对其进行表示可得:
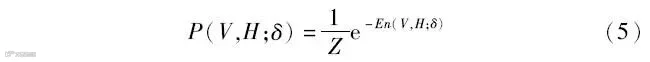
式中:Z为归一化因子,且Z=∑V,He-En(V,H;δ),由此可得模型关于可见层V的边缘分布P(V;δ)为
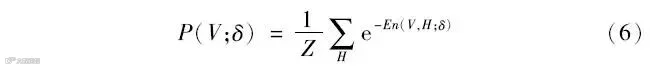
令一个RBM中有m个隐藏层单元和n个可见层单元,隐藏层单元和可见层的激活状态为二值变量,即对任意x、y,有Hx∈{0,1},Vy∈{0,1},Hx为隐藏层中第x个单元的状态,Vy为可见层中第y个单元的状态。则可得单个RBM系统中包含的能量为
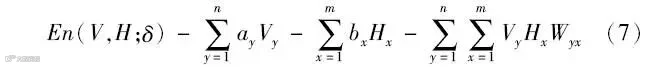
式中:Wyx为第y个可见层单元和第x个隐藏层单元间的连接权重,根据能量函数分别求得可见层和隐藏层的条件概率分布后,根据式(8)与式(9)计算RBM的权值更新,可得:
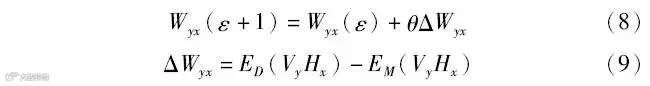
式中:ε为RBM的迭代次数;θ为RBM的学习率;ED和EM分别为模型训练时训练集中观测数据的期望和模型所确定分布的期望,从而不断更新RBM的权值并在获得最优模型参数后,对数据集进行特征提取以供诊断模型分类使用。DBN由数个RBM顺序堆叠组成,DBN结构如图3所示。
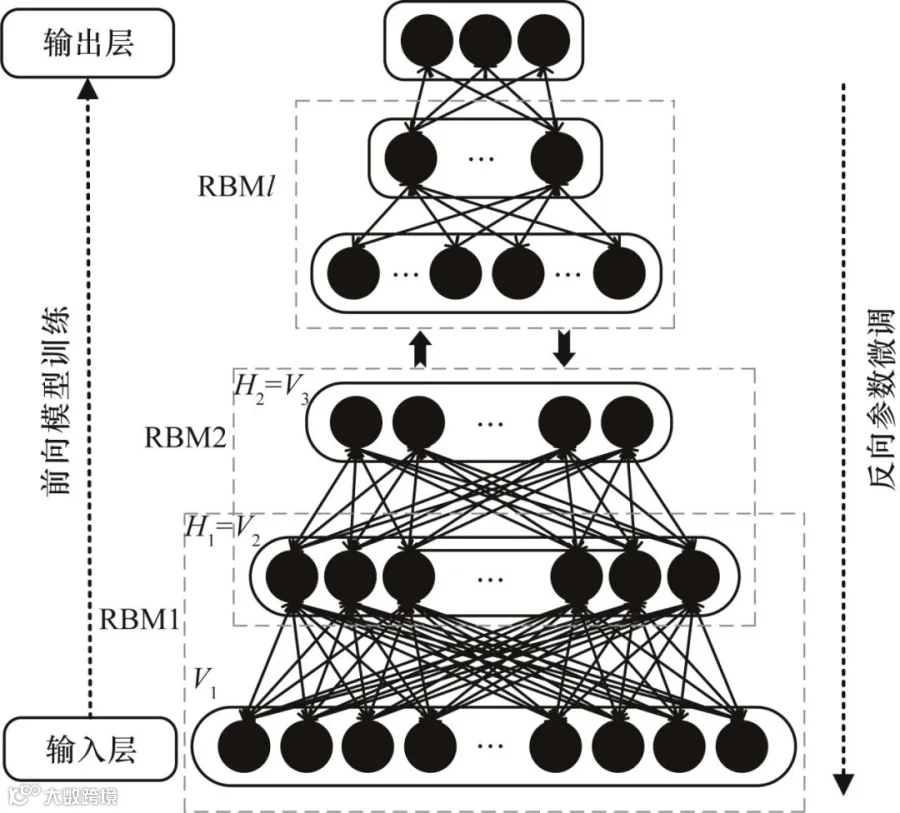
图3 DBN结构
由图3可知,DBN模型的训练过程分为2个部分:前向训练和反向参数微调。
① 前向模型训练。对输入数据进行特征提取,获得每一层的最优参数和特征,并输出至下一层,确保特征向量映射到不同的特征空间时能尽可能多地保留特征信息。这一过程中,前一隐藏层的输出H即为下一可见层的输入V,即Hm=Vn,其中m={1,2,…,l},且n=m+1。
② 反向参数微调。反向参数微调有监督地训练实体关系分类器。每层RBM确保其层内权值对于该层的特征映射可以达到最优。这一过程中,前一可见层的输出V即为下一隐藏层的输入H,即Vn=Hm,其中n={1,2,…,l+1},且m=n+1。
2.3 LSSADBN故障诊断流程
基于LSSADBN的小样本迁移学习故障诊断流程如图4所示,主要包括数据提取及预处理、模型优化和故障特征提取及分类3个阶段。
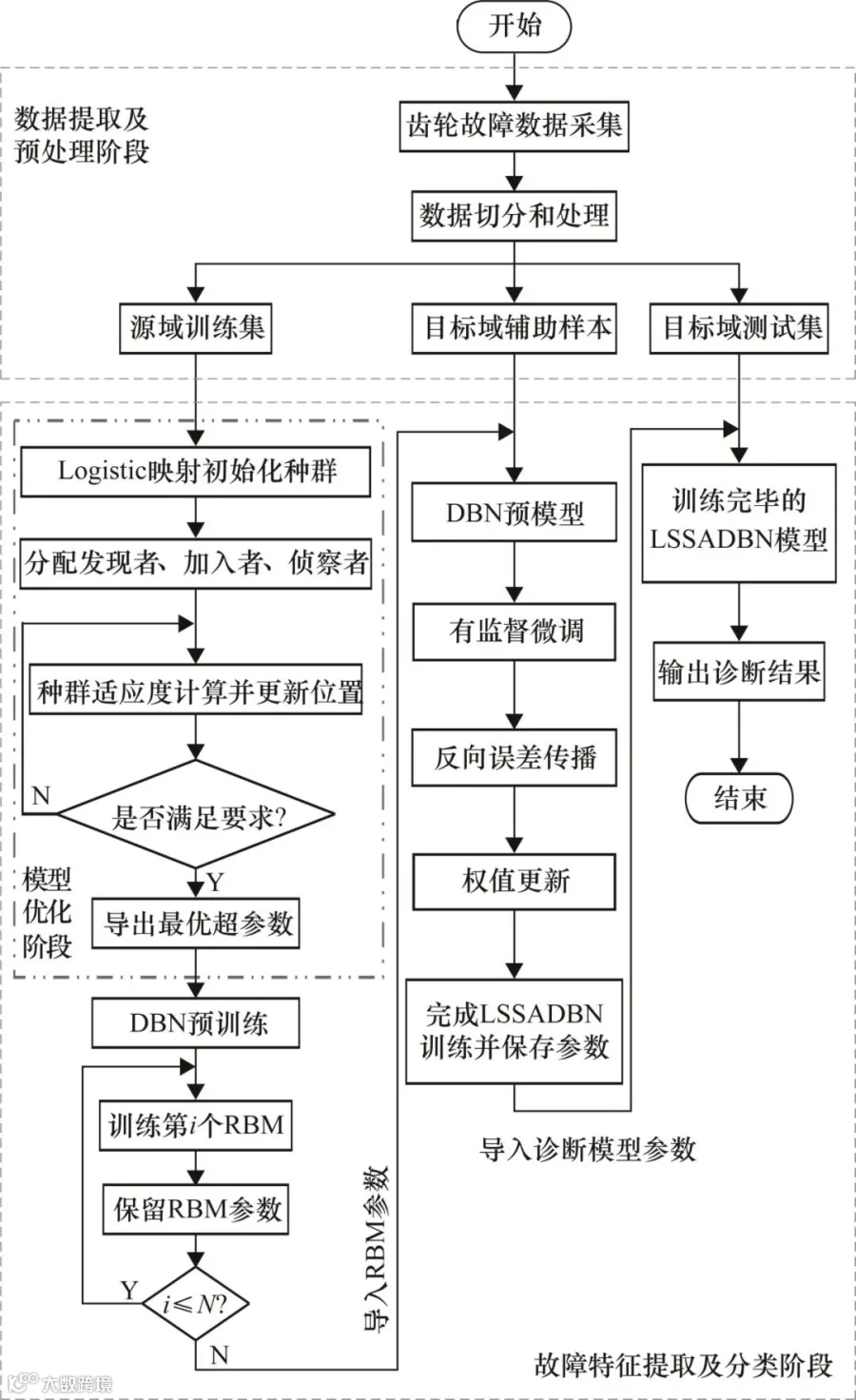
图4 基于LSSADBN的小样本迁移学习故障诊断流程图
① 数据提取及预处理。实验选用DDS试验台采集的齿轮箱齿轮故障的振动信号数据,考虑到数据存在采样点密集、故障特征不明显和信息冗余严重等问题,需要对采集的数据样本进行预处理。由于本实验所使用数据集为非平稳信号,所以数据集需要在频域方面进行处理。同时考虑到设备运行中可能需要实时检测,故本实验选用FFT将时域信号转换为频域信号,相比于其他转换方式,这种方式可以大幅提高处理速度,更快速地得出结果。数据集的切分与处理过程如图4中数据提取及预处理阶段所示。
② 模型优化。在对DBN故障诊断模型进行预训练前,需要对其各层节点数、预训练过程和Finetune过程中的学习率等超参数进行设置。然而,依靠个人经验对模型超参数进行设置往往不能得到很好的结果,考虑到LSSA算法收敛速度快且寻优效果优异,故选择LSSA算法对模型超参数进行寻优。LSSA算法通过Logistic混淆映射方法对麻雀种群位置进行初始化,使得种群的初始分布位置更加均匀;随后按照比例设定发现者、加入者、侦察者数量,不断计算个体适应度值并更新位置,直至搜寻到符合优化要求的超参数解。模型优化过程如图4中模型优化阶段所示。
③ 故障特征提取及分类。将寻优得到的各层节点数和超参数导入到DBN模型中,使用DDS试验台采集到的经过FFT转换的振动信号对模型进行预训练,从而获得迁移学习预模型。在反向权重微调过程中,加入少量目标域辅助样本进行有监督权重微调,通过反向误差传播对特征参数进行进一步微调,最终构建完成在小样本情况下的迁移学习故障诊断模型。具体诊断流程如图4中故障特征提取及分类阶段所示。
3 实验分析
为验证所构建的LSSADBN模型在小样本情况下对不同工况的迁移学习能力,本实验选用真实的齿轮箱故障振动信号数据,数据采集自Spectra Quest公司制造的DDS,DDS试验台如图5所示。从图5可以看出DDS动力传动试验台从左至右依次由驱动电机、转速调节器、信号采集卡、齿轮箱、磁粉制动器和负载调节器组成。图5中详细展示了齿轮箱内部的细节图,本实验通过更换齿轮箱内部的齿轮,采集了3种不同负载下的6种齿轮状态,分别是1种正常状态(Normal)齿轮和5种故障状态齿轮,故障状态分别为断齿(Broken)、裂纹(Crack)、偏心(Eccentric)、缺齿(Miss)、磨损(Wear)。

图5 DDS试验台
3.1 数据预处理
本实验通过调节负载电压、更换齿轮箱内部各种不同健康状态的齿轮以验证LSSADBN在不同工况下对故障的诊断能力。实验通过人工加工制造出5种齿轮故障(断齿、磨损、偏心、缺齿、裂纹),其中断齿与缺齿的区别为:断齿齿轮的某个轮齿只有部分缺损,而缺齿齿轮的某个轮齿从齿根圆的位置全部缺失。图6展示了5种齿轮故障状态的细节图,具体故障位置用红圈画出。

图6 故障齿轮细节图
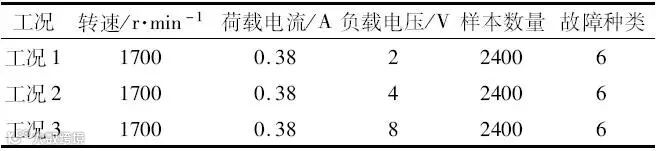
为了使采集到的齿轮故障数据更具多样性和普遍性,能够包含同种故障在不同负载下的样本数据,实验中对齿轮的转速、负载等进行了设置。为模拟在不同工况下的齿轮箱运转情况,本实验设置了3种不同工作负载(负载电压分别为2 V、4 V和8 V),设置转速恒定为1700 r/min。实验中采用单向加速度的传感器获得齿轮故障振动信号,设置采样时长为20 s,采样频率为20 kHz,累计得到3种工况下共18个振动信号文件,单个振动信号文件的采样点数为409600个。根据采样频率和采样时长,在确保单个样本中包含至少一个完整振动周期的情况下,保留400000个样本点,按照每1000个点为一段进行切分,每个故障类型可以得到400个样本。每种工况得到6种健康状态(1种正常状态和5种故障状态)共2400个样本,合计得到3种工况样本7200个。数据集切分情况、试验台运转状况、样本数量等信息如表1所示。
表1 数据集切分方式表
本实验选用FFT对数据进行预处理,将时域信号转换为频域信号处理。经过FFT预处理后的数据故障特征明显且有效减少了数据冗余。图7为在转速恒定为1700 r/min时,齿轮出现断齿情况后在3种不同负载下的振动信号和频域信号图,对比图7(a)、图7(b)和图7(c)可以发现,即便转速相同且属于同种齿轮故障,其振动信号和频域信号所展示出来的频谱能量以及频谱结构存在明显的不同,在变负载情况下对齿轮故障进行正确诊断是故障诊断领域一大难点。
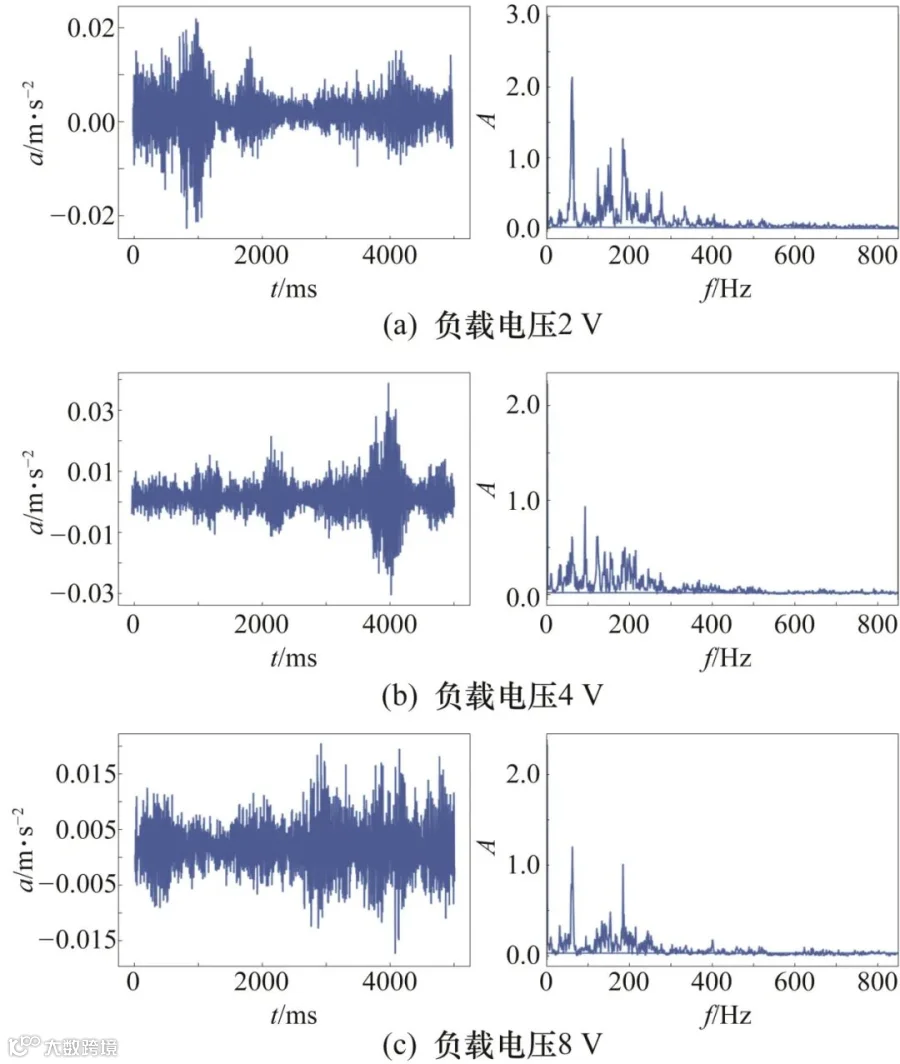
图7 不同负载下齿轮振动信号和频域信号
3.2 超参数寻优
LSSADBN模型在对DBN结构参数、模型训练超参数进行设置前,使用LSSA优化搜索算法对DBN的各层节点数、模型预训练学习率和反向权值Finetune过程的学习率进行寻优。本小节设置遗传算法(Genetic Algorithm,GA)和普通SSA算法的对比实验以证明普通SSA算法可以获得更好的适应度值;设置使用不同初始化算法的SSA方法进行对比实验以证明LSSA算法在寻优结果和寻优速度上的优势。
在对GA算法和SSA算法进行对比实验时,需要对GA算法进行参数设定,设定GA算法最小染色体长度为6,染色体数量为5,交叉概率为0.5,变异概率为0.5,寻优次数为40次。此外,还需要对待优化DBN超参数进行界限设定,依据现有算法和经验,设定预训练和反向调优学习率的寻优上界和寻优下界为0.001和0.1,模型动量设置为0.1~1。同时,为了确保结果能够收敛,预训练迭代次数的寻优上界和下界分别为1和20,反向权值调优迭代次数的寻优上界和下界分别为1和100。使用GA算法与普通SSA算法对DBN超参数进行寻优的适应度函数结果如图8所示。从图8可以看出,GA算法在迭代至第17次的时候收敛,求得的最优适应度值为0.05628;而SSA在迭代至第30次时收敛,求得的最优适应度值为0.03125。SSA算法相较于广泛使用的GA算法,可以获得更优的适应度值,对不同数据最优值的拟合程度更强。
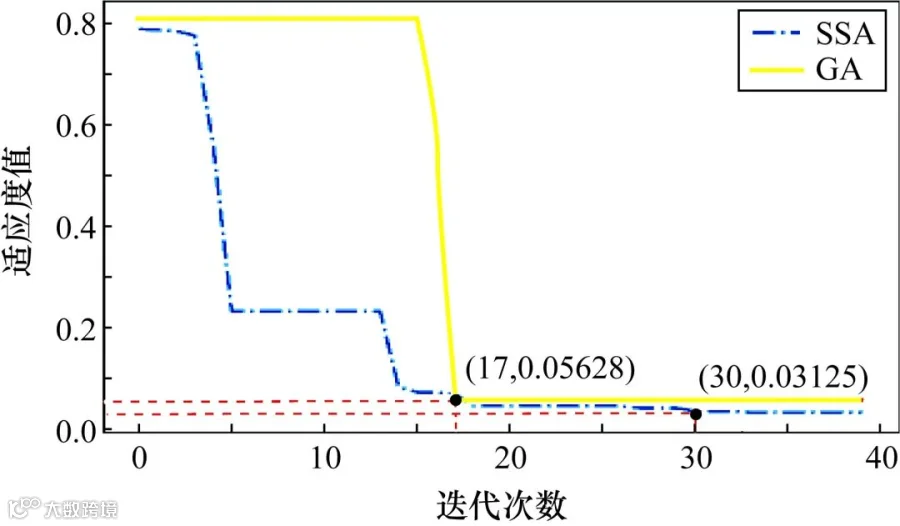
图8 GA算法与普通SSA算法适应度曲线
在对通过不同混沌映射方法进行初始化的SSA算法适应度值进行对比实验时,设置模型优化隐藏层层数为4,优化维度为8(2个学习率,2个迭代次数,4个隐藏层层数),SSA种群数量为20,寻优次数为40次,发现者比例为20%。DBN超参数寻优的界限不变,实验中使用了Logistic、Circle、Sine和Tent共4种混沌映射方式对SSA进行初始化,其对DBN的超参数寻优结果如图9所示。使用Logistic、Circle、Sine和Tent混沌映射进行初始化的最优适应度值分别为0.0229、0.0396、0.0271、0.03125。从图9可以看出,除了Circle混沌映射方法,其余混沌映射方法均在迭代满20次前求得最优的适应度值。其中,使用Logistic混沌映射进行初始化求得的适应度最优。结合图8和图9可知,使用Logistic混沌映射对SSA算法进行初始化后,可以在更少的迭代次数下获得更优的适应度值。
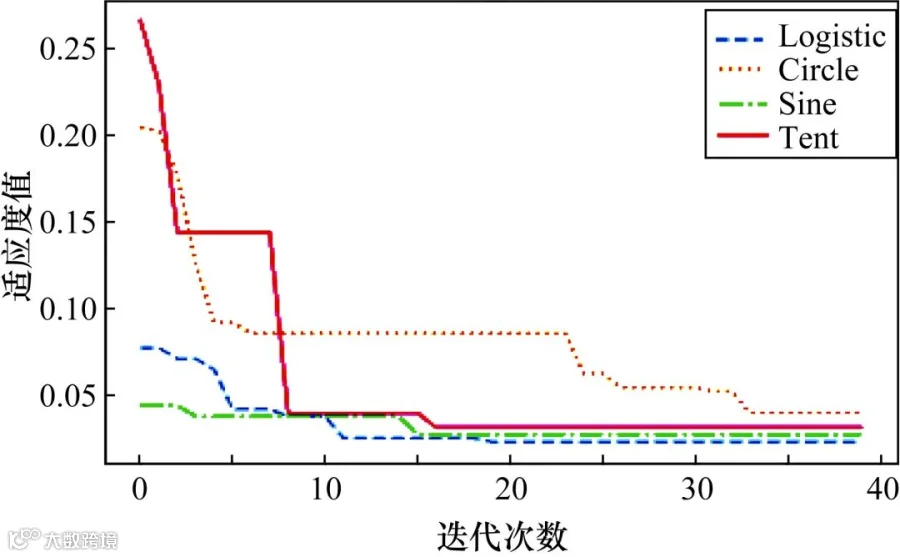
图9 多种初始化方法适应度曲线
通过LSSA优化算法对DBN进行寻优可得DBN的网络结构和最优学习率等超参数,具体寻优结果如表2所示。
表2 寻优结果表

3.3 实验结果与对比分析
3.3.1 LSSADBN特征提取能力分析
将寻优得到的最优DBN的网络结构以及预训练、反向权值微调学习率等超参数导入到DBN模型中进行故障诊断。为验证经过LSSA算法优化的DBN是否具备优秀的特征提取能力,本实验使用t-分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)方法将提取的多维特征进行降维后,投影至二维空间以进行可视化分析,若投影后特征可分性好,则说明通过LSSA算法寻得的DBN结构具备优秀的特征提取能力。实验中通过LSSADBN进行特征提取的降维可视化结果如图10所示。
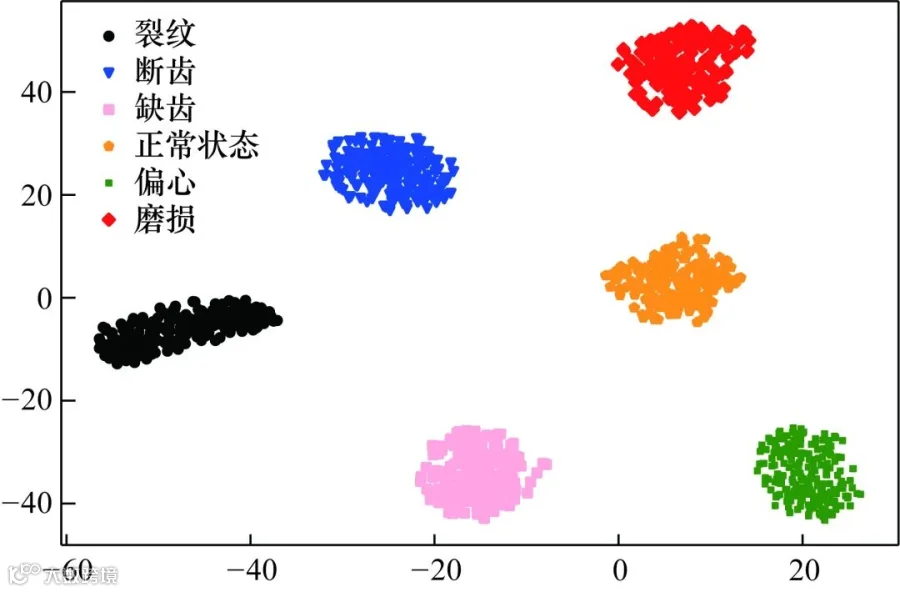
图10 LSSADBN特征提取可视化
特征提取过程参照文献,并将文中所用DBN作为对比结构。DBN各层结构节点数为512-100-50-6,学习率α为0.05,动量设置为0.9。该方法将样本信号输入网络,逐层更新网络的参数获得其分布式特征表达,得到基于辅助标记样本的DBN预模型,再用少量的目标标记样本微调DBN预模型的网络权重和偏置值。通过该对比网络进行特征提取的降维可视化结果如图11所示。
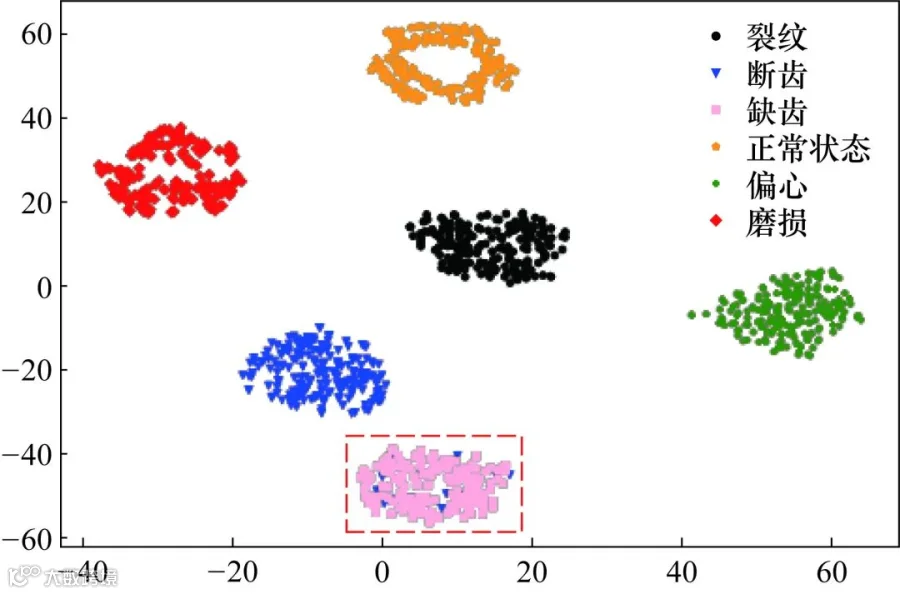
图11 对比网络特征提取可视化
对比图10和图11可知,本文所提出的LSSADBN网络对于包括1种正常状态和5种故障状态在内的6种齿轮健康状态的特征可分性极好,特征分类无混淆,而对比网络在区分缺齿与断齿两类相近故障状态时,特征分类界限不清晰,存在误分,误分情况如图11中红色虚线框所示。由此可见,通过优化算法自适应调整模型参数的LSSADBN模型与通过经验设置模型参数的模型相比,可以更好地提取故障特征。
3.3.2 DBN诊断效果受样本影响分析
为证明目标域训练样本数量大小对DBN模型训练效果的影响,分别在目标域工况1~工况3(具体工况设置如表1所示)下,从每类故障的400个样本中挑选少量、不同数量的故障样本分别作为训练集,对模型进行训练,并对6类健康状态进行分类。LSSADBN模型根据LSSA算法得出的最优结果进行参数设置:设置隐藏层层数为4层,4层隐藏节点数为[452,382,268,44],根据故障类型设置输出层节点数为6,预训练学习率为0.00134112,反向权值调优学习率为0.00267396。LSSADBN模型在非迁移情况下,选取不同训练样本数量的诊断准确率如图12所示。
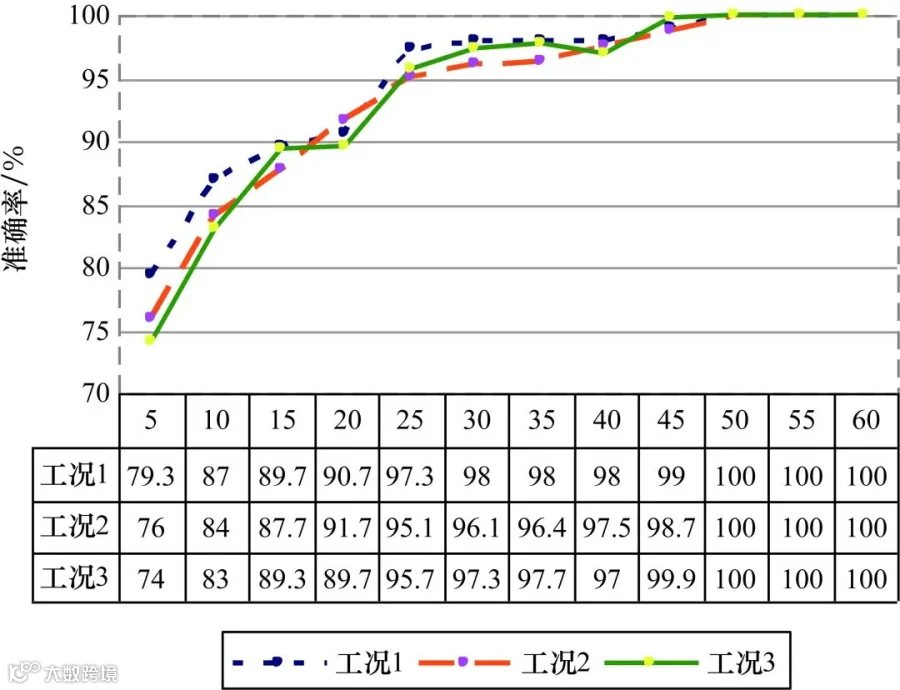
图12 LSSADBN选取不同训练样本数量的诊断准确率
选用文献的DBN超参数进行对比,设置对比网络的结构为512-100-50-6,学习率α为0.05,动量设置为0.9,其在非迁移情况下,选取不同训练样本数量的诊断准确率如图13所示。
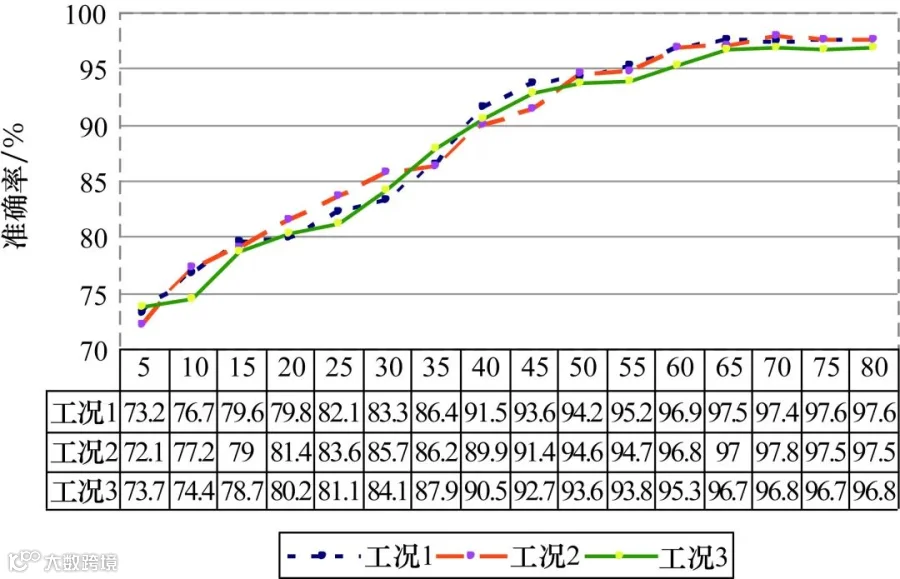
图13 对比实验诊断准确率
对比图12和图13可以发现,无论是LSSADBN还是对比模型,当训练样本数量不满足DBN训练要求时,诊断效果皆不佳。当训练样本数量满足网络训练要求时,诊断准确率提升显著。其中,LSSADBN在训练样本每类仅5个时,诊断准确率最高可以达到79.33%,高于对比实验的73.7%。在3种工况下,当提供的每类训练样本达到50个时,LSSADBN模型可以达到100%的诊断准确率;而对比实验的诊断准确率收敛于每类训练样本达到65个时,且3种工况下的最高准确率仅97.8%。综上,通过LSSA算法寻优得到的故障诊断模型具有更快的收敛速度、更好的寻优结果和更高的分类准确率。
3.3.3 LSSADBN迁移能力分析
为验证所提出的LSSADBN模型在小样本情况下能否准确进行故障诊断任务,本实验采集了3种不同工况(负载电压2 V、负载电压4 V、负载电压8 V)数据样本。实验拟定以4 V负载电压样本作为源域数据,2 V和8 V负载电压样本作为目标域数据。针对单类源域样本数量为400个情况,设定3种目标域小样本数量:20个目标域辅助样本、40个目标域辅助样本、60个目标域辅助样本。
根据LSSA优化算法求得的最优DBN网络结构,设置DBN隐藏层节点数为[382,268,452,44],最终输出6种健康状态;设置LSSADBN模型预训练的学习率为0.00134112,反向权值调优过程的学习率为0.00267396,不设置学习率衰减;预训练过程设置每个RBM进行2次Gibbs采样,batch_size设置为64,选用交叉熵损失函数CrossEntropyLoss和Adam优化器。反向参数Finetune过程超参数设置与预训练过程相同。将工况2(负载电压4 V)故障数据作为源域训练样本,少量工况1(负载电压2 V)作为目标域样本用作辅助样本,对LSSADBN模型进行反向权重微调后,对目标域进行故障诊断的诊断结果混淆矩阵如图14所示。
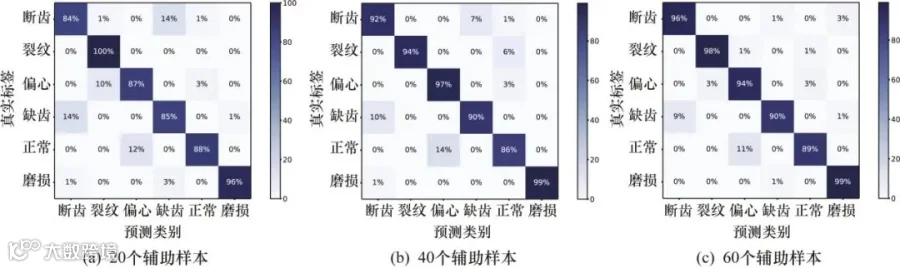
图14 PETA数据集中行人图像的属性标签组合示例
在图14中,横坐标为模型预测的类别,纵坐标为测试样本的真实标签,横纵坐标的交点值为预测的准确率。从图14(a)可以看出,在仅仅使用20个目标域数据作为辅助样本参与训练后,模型对工况1各种齿轮故障的分类准确率最优可达100%,最差可达84%,平均准确率达到了90%。由图14(b)和图14(c)可知,当分别增加目标域辅助样本到40个和60个时,模型的平均分类准确率分别可以达到93%和94.3%。此外,可以观察到模型存在的不足为:无论添加20个、40个或者60个辅助样本,模型针对不同负载下齿轮箱故障,对缺齿与断齿、正常与偏心两对齿轮健康状态的区分能力较差,缺齿与断齿、正常与偏心的误分概率最高均达到了14%,其余故障类型的误分概率均不超过10%,且多数保持在1%~3%之间。经研究资料、查阅文献,分析造成该情况的原因可能是在变负载情况下,以上4类故障特征分布差异较小,这增大了区分难度。为解决上述问题,可以考虑使用深度度量学习方法,或者对损失函数进行改进,加大这类相似特征之间的分布差异以提高区分度。这一情况为进一步的研究学习提供了新的方向。
3.3.4 LSSADBN对比实验分析
本实验设置了2种机器学习方法和1种迁移学习方法进行多次实验对比,以验证LSSADBN与各类模型相比,均有着更加优异的诊断表现。
设置传统机器学习方法时,选用K-最近邻算法(K-Nearest Neighbor,KNN)、支持向量机(Support Vector Machine,SVM)作为对比实验与LSSADBN进行诊断效果比较。对KNN进行超参数设定时,调用sklearn库并通过网格搜索设置K近邻数为5,距离度量方法选用欧式距离,每个样本的近邻样本权重定义为uniform。对SVM进行超参数设定时,设定惩罚系数C为1,核函数为linear。KNN与SVM的5次实验下的平均分类准确率如表3所示。从表3可以看出,传统的机器学习方法在进行变工况故障诊断时表现不佳,两种方法的最高准确率仅80.2%,KNN与SVM在针对高噪声、大数据量的样本时,不能很好地进行故障诊断工作。
表3 KNN与SVM诊断平均分类准确率
单位:%
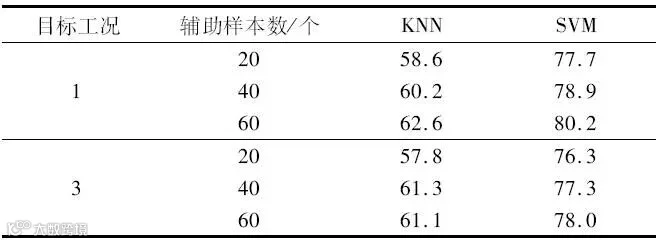
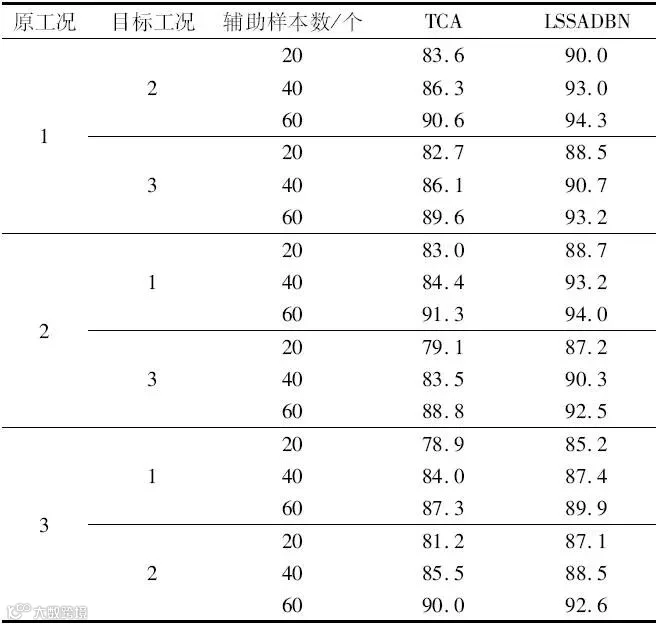
设置迁移学习算法时,选用迁移成分分析(Transfer Component Analysis, TCA)对实验数据进行诊断。TCA将分布不同的源域和目标域数据映射到高维再生核希尔伯特空间中,不断缩小源域与目标域距离以保留其内部属性,并以最大均值差异算法来衡量源域和目标域的距离。TCA方法和LSSADBN算法在3种工况之间互相迁移,共进行6组实验,每组实验5次的结果取平均值,得到准确率如表4所示。结合表3和表4可知,本文所提出的LSSADBN方法与传统机器学习方法和迁移学习方法相比,具有更好的诊断表现。在添加60个目标域样本进行权重微调后,LSSADBN对源域为工况1、目标域为工况2的诊断准确率最高可达94.3%。综上所述,本文提出的LSSADBN算法对数据特征有着极其优异的特征提取能力,并且可以在小样本情况下完成变工况迁移学习故障诊断任务。
表4 TCA与LSSADBN诊断平均准确率
单位:%
4 结论
本文提出的LSSADBN模型由LSSA寻优算法和DBN组成。针对不同的数据,采用LSSA算法对DBN网络中的超参数进行自适应寻优并搭建拥有最优网络结构的DBN,通过源域数据对LSSADBN进行预训练,添加少量目标域样本用于反向权重微调,完成小样本情况下的变工况故障诊断工作。实验结果表明:
① LSSA优化算法相较于传统的优化算法,可以求得更优的适应度值来获得更好的寻优结果,并且通过Logistic混沌映射进行初始化后,优化了种群分布,大幅加快了模型的收敛速度。
② 通过LSSA优化算法寻优而搭建的DBN具备极其优秀的特征提取能力,能够在较少的迭代次数下,准确地完成故障诊断工作。
③ 所搭建的LSSADBN模型相较于其他传统机器学习方法(KNN、SVM)与迁移学习方法(TCA)等,采用添加少量辅助样本进行权重微调的方式,能够在变工况情况下获得更好的诊断结果。
综上所述,LSSADBN故障诊断模型能够完成小样本情况下的变工况故障诊断任务,通过LSSA优化算法根据不同数据自适应调整模型超参数,可应用的范围更广且鲁棒性强,为变工况情况下目标域训练数据不足而导致的特征学习不充分问题提供了新的解决路线。
END
热点文章 (向上滑动阅览)
期刊动态 (向上滑动阅览)
关于2023年中国航空工业技术装备工程协年会征文的通知
期刊目录 (向上滑动阅览)