
首先 Neo4j 是一个图数据库管理系统,应该是知名度最广的开源图数据库,由「Neo4j, Inc.」公司开发。
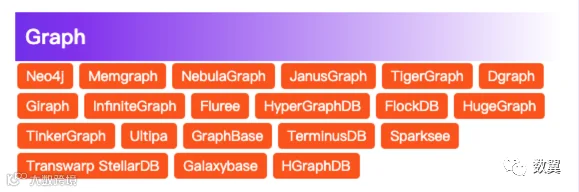
从我们之前维护的数据库知识图谱中可以看到,图数据库分类下还是有很多产品的:
名字由来
Google Group 上有一个帖子问『Neo4j 这个名字是是什么意思』, 4j 肯定是 『for Java』的意思, Neo 有人说可能是参考黑客帝国的角色 Neo。
I think "Neo" is a reference to the Matrix character.
也有人说是「物之新生」或者「物联引擎」:
"Neo" has also been transcribed to "New Energy for Objects" and "Network Engine for Objects" :)
我也只是好奇八卦一下,名字怎么来的并不影响咱们后面的使用。
Neo4j vs AuraDB vs Cypher
「Neo4j Inc」 公司的数据库产品叫 《Neo4j Graph Database[1]》也就是我们常说的 Neo4j 数据库, 也叫 Neo4j DBMS。

除了 Neo4j 数据库,Neo4j 公司还开发了新的产品 《Neo4j AuraDB[2]》。这是一个完全托管的云服务,相当于 Neo4j DBMS 的 SaaS 版本。

Neo4j 公司另外一个最重要的产品就是 《Cypher[3]》, 这是 Neo4j 数据库的查询语言,他的作用就相当于 SQL 之于关系数据库。

下载安装
如果大家想在本地开发测试使用 Neo4j 那就不要在官网点击「免费试用」, 直接打开Neo4j 下载中心[4], 点击下载即可:
不过注意, Neo4j Desktop 虽然把所有的工具都包含进去了,非常方便,但是它并不适合生产环境使用。
Neo4j Desktop is not suited for production environments.
安装过程我就不说了,选择合适的版本一路点下去就行。安装之后就有 Neo4j 程序的启动图标。

软件使用
打开 Desktop 就可以看到应用程序界面:
左上角的三个图标分别是「项目」、「数据库」和「应用」。
第一个功能是「项目」,Neo4j Desktop 安装好之后会自带一个默认的样例项目,里面有一个电影数据库。
点击启动按钮可以启动这个数据库,启动之后我们看到数据库的状态是 Active:
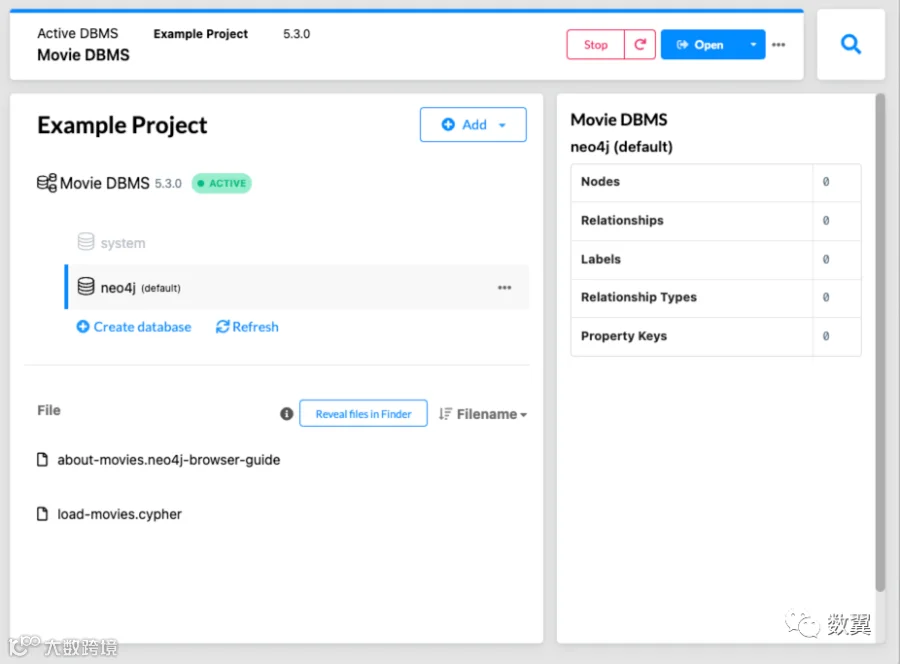
点击右上角的 『Open』 按钮,会默认新窗口打开 Neo4pj Browser,这是一个 GUI 的客户端工具,你可以通过它查看数据库链接信息、服务状态,还可以执行命令。
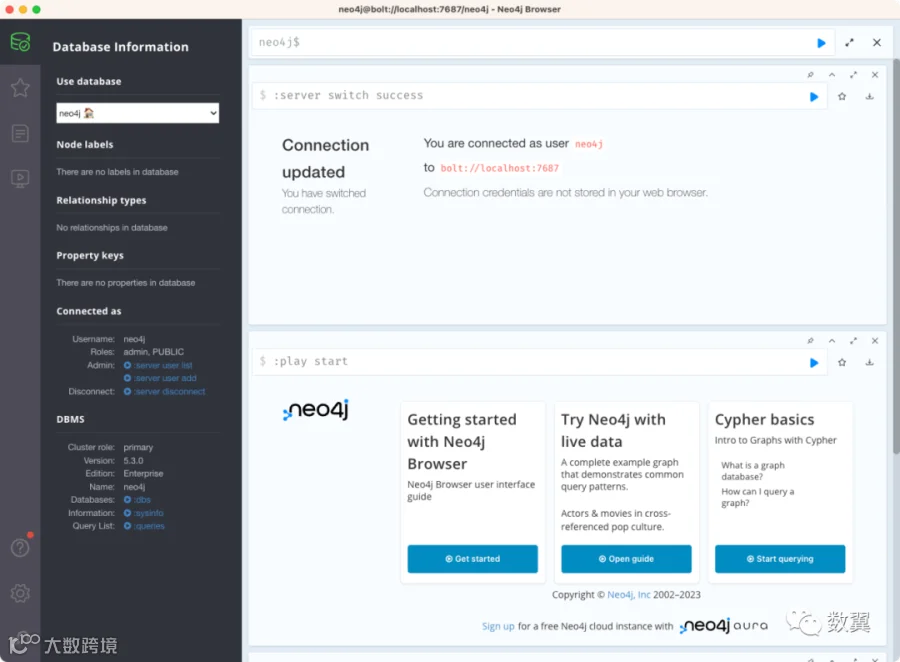
我们先从左侧收藏里面执行下 Hello World,然后返回数据:
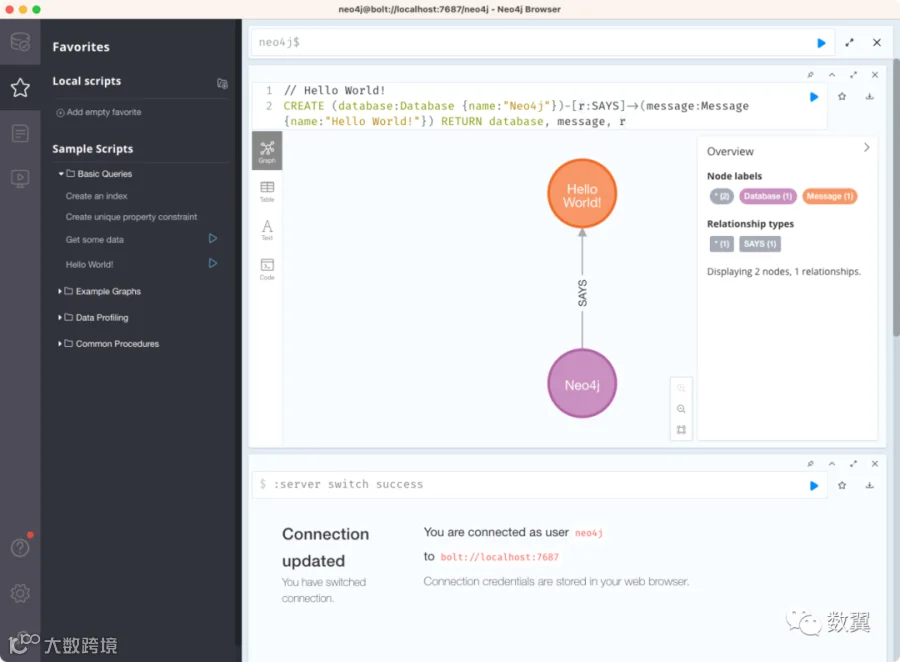
命令如下,你也可以拷贝或者手输命令在执行框里面点击执行。具体 Cypher 代码语法含义我们等到后面讲 Cypher 语言的时候再讲。
// Hello World!
CREATE (database:Database {name:"Neo4j"})-[r:SAYS]->(message:Message {name:"Hello World!"}) RETURN database, message, r上述代码创建了一个具有 Database 标签的节点,一个 Message 标签的节点,以及一个 SAYS 类型的边,并返回。
() 表示一个节点,
()-[]->() 表示一个边
: 冒号前面表示
变量,冒号后面来表示
节点标签 或者
边类型
图数据库
为什么用图数据库
现实中的很多场景天然就是以图的概念存储的,比如人和人之间的关系,每个人有自己的定义和属性,人与人之间会有各种可能的关系。
这样的场景用传统的关系型数据库存储的话,无论是从数据结构设计,还是最终的查询性能上都有很多的损耗,此时图数据库就能很好的满足这些场景。
图数据库的组成
像我们之前《构建个人知识图谱》文章里提到的一样,图数据库有三个概念来表示数据:节点、关系和属性。节点和关系又组成了经典的三元组关系:节点-关系-节点,节点和关系上都可以有自己的属性。
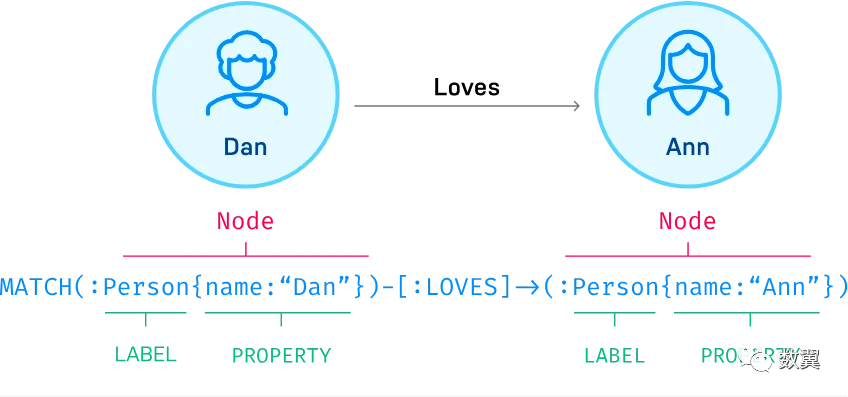
节点
节点可以用 labels 标记, 比如动物、软件、公司、网站、书籍 等都可以作为 「标签」,在《构建个人知识图谱》系列中我们称之为「类型」。。
不同的标签在 Neo4j 的工具会被显示成不同的颜色。
节点可以保存任意数量的属性,当然也可以没有属性。比如张三这个节点,可能有 姓名、性别、名族、年龄等众多属性。
作为数据库节点还可以有一些约束性质的属性。比如 姓名不能为空、身份证号不能重复等。
关系
Neo4j 的关系是有方向的,用于连接两个节点。关系也可以有自己的类型和属性。
每个节点的关系数量也是不受限制的,而且我们还可以通过正向或者逆向的方向来查找节点。
数据建模
我们动手开始所有项目和数据库之前,第一件事情肯定是建模。所谓建模就是描述清楚你要做事情的结构, 有哪些数据、数据之间的结构是什么。对这些模型胸有成竹,后面做事情才可以游刃有余。
白板数据建模法
Neo4j 官方推荐白板建模法,白板建模法:就是直接在白板(黑板当然也行)上绘制想要的模型和关系,然后照搬的图数据库中即可。
比如我们想围绕李小龙先生进行一个图谱数据建设,第一步就可以列出实体:
我后面直接用绘图软件画图来模拟白板。
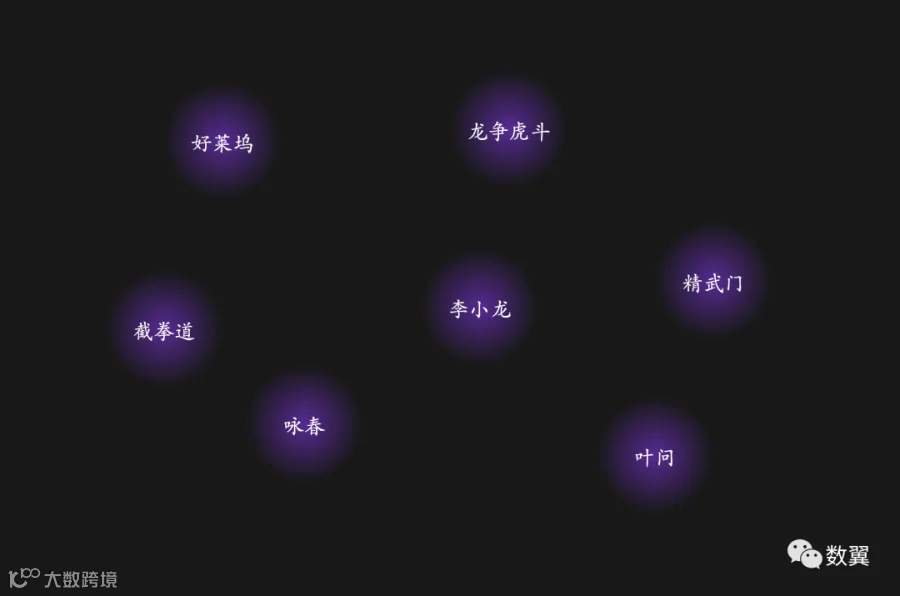
然后绘制好连线,可能是这样子:
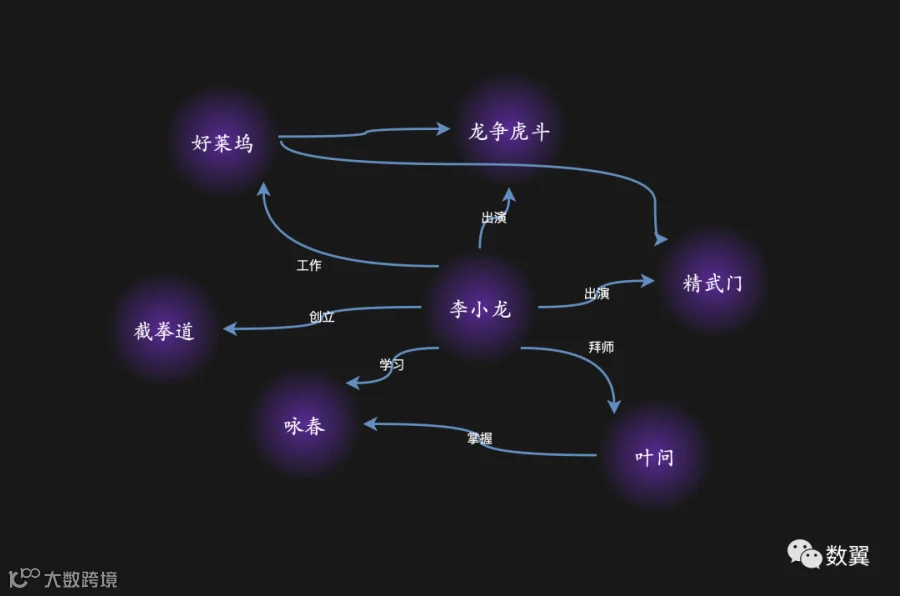
一般来说,主要的连线在白板上绘制实体的时候已经绘制好了。
下一步,添加标签和节点属性,我们用不同颜色表示不同类型的节点(标签),一个节点可能有多种类型标签, 同时完善节点和关系的属性,当然别忘了关系也有自己的关系类型哦。
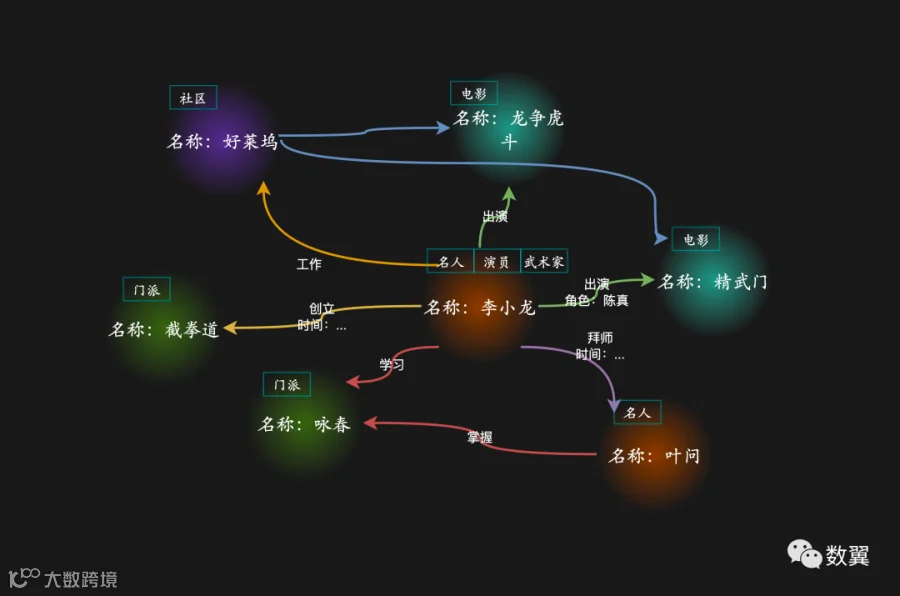
最后一步就是把我们刚刚梳理的关系原样录入图数据库了。
建模步骤
我们再画一个例子,一步步看下怎么样从零开始图数据库的建模。
场景描述
首先我们描述下我们的需求,这次我们换个需求,关注下西游记:
金角大王和银角大王两个妖怪是兄弟俩,他们都想吃唐僧这个和尚的肉。
提取节点
比如可以从上面的场景描述中提取如下节点:
• 金角大王
• 银角大王
• 唐僧
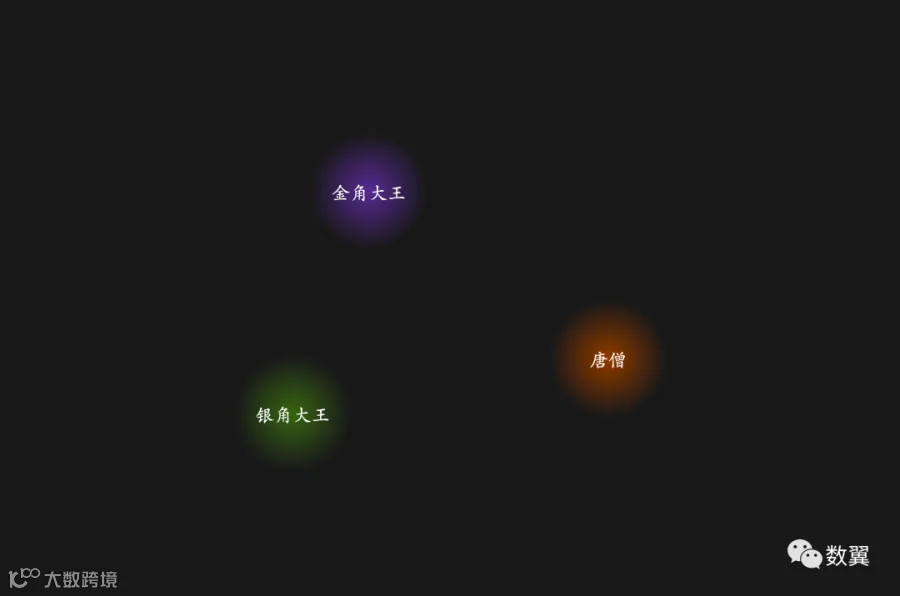
金角大王和
银角大王这两个
妖怪,
唐僧 是个
和尚。
妖怪以及
和尚这个
职业,在我们的场景中更偏向是一种类型,这类节点、和类型(/属性)定位不清楚的
名词否作为节点我们后面单独讨论。
提取节点标签
前面提到,一个节点可能有多个标签,这些标签可以为节点进行分类或分组。比如按照对按照职业或者身份进行分组,可能有「教师」、 「学生」、「演员」、「工程师」、「历史学家」等等很多标签,同时一个人也可以兼顾不同的身份。
金角大王和银角大王两个妖怪是兄弟俩,他们都想吃唐僧这个和尚的肉。
这样的话,上面场景我们可以提取出如下标签:
• 妖怪
• 和尚

定义关系
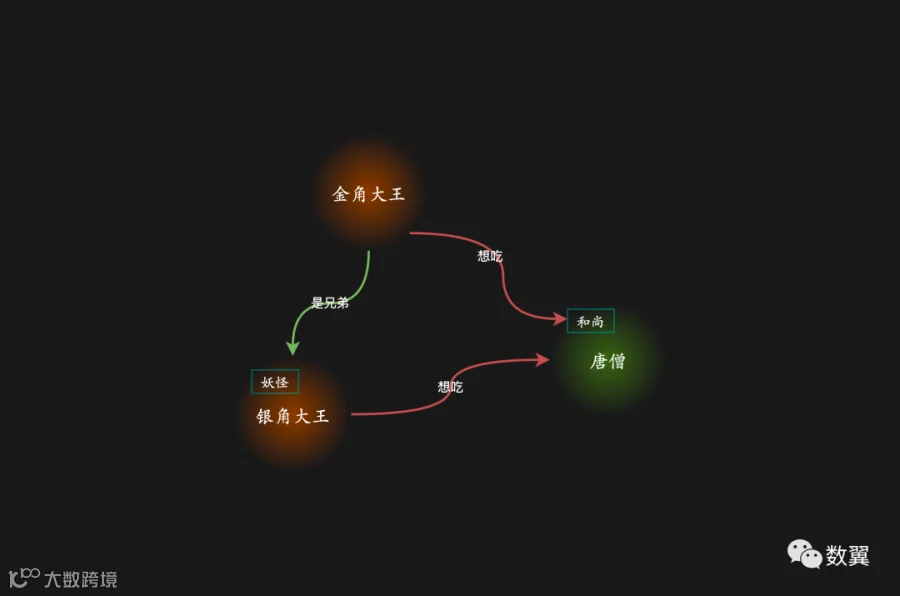
现在我们有了数据主体,但是这些主体目前还是孤零零的个体,因为还缺少了图数据库中的一个重要部分:『关系』。
关系允许我们链接两个节点,它有一个源节点、带箭头的方向以及一个目标节点,同时关系也有自己的名字(动作),以及他们自己的属性。
金角大王和银角大王两个妖怪是兄弟俩,他们都想吃唐僧这个和尚的肉。
在上面这个场景中我们可以找到关系:
• 金角大王和银角大王是兄弟
• 他们想吃唐僧
「师兄弟」和「想吃唐僧」这两个动作就是我们说的关系了。
定义属性
简单来说,我们已经完成了图数据库的定义,因为画出来的图已经有模有样了。但是有时候为了存储更多的信息,更准确的描述实体,我们往往还需要定义属性。
属性是可以存储在节点或关系上的数据的名称/值对。常见的数据类型都可以作为属性值:
• 字符
• 整数、小数
• 布尔
• 日期和时间
我们对于节点本身的任何疑问都可以变成属性来设计:
• 金角大王几岁了
• 银角大王身高多少
• 金角大王的真身是什么
• 唐僧是男是女
• 唐僧多少斤
• 唐僧生日是哪天
• 唐僧什么时候当和尚的
• ...
只要你有问有答,他就可以作为一个属性。
创建模型
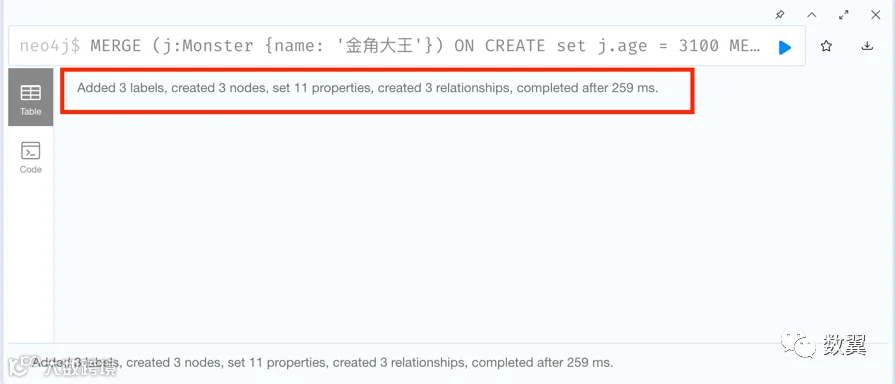
创建模型需要使用 Cypher 语句,刚刚的西游记三人组我们使用 MERGE 字据来创建数据模型。在 Neo4j Browser 中运行以下代码:
MERGE (j:Monster {name: '金角大王'})
ON CREATE set j.age = 3100
MERGE (y:Monster {name: '银角大王'})
ON CREATE set y.age = 2800
MERGE (t:Monk {title: '唐僧'})
ON CREATE set t.height = 182
MERGE (j)-[rel1:IS_BROTHER]->(y)
ON CREATE SET rel1.since = '-2023'
MERGE (j)-[rel2:WANT_EAT]->(t)
ON CREATE SET rel2.desire = 4, rel2.possibility = 0
MERGE (y)-[rel3:WANT_EAT]->(t)
ON CREATE SET rel3.desire = 3, rel3.possibility = 0
MERGE ... ON CREATE ... 表示查找节点,如果不存在则创建并设置属性
可以看到提示创建成功:
接着我们执行查询验证下:
// Get some data
MATCH (n1)-[r]->(n2) RETURN r, n1, n2 LIMIT 25
MATCH ()-[]->() RETURN ... 表示查找所有关系,并返回关系中的节点和边
可以看到查询结果:
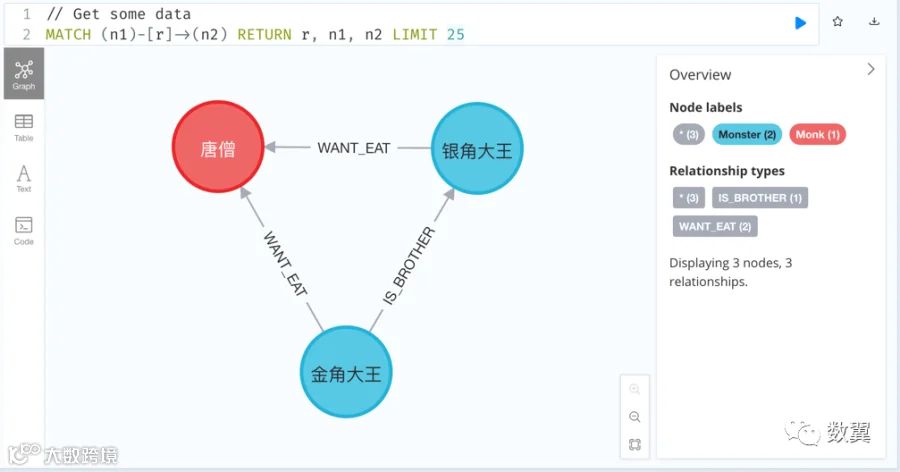
点击「金角大王」节点,可以看到节点标签和属性(其他节点以同样):金角大王是一个 Monster,年龄是 3100 岁,名字叫金角大王。
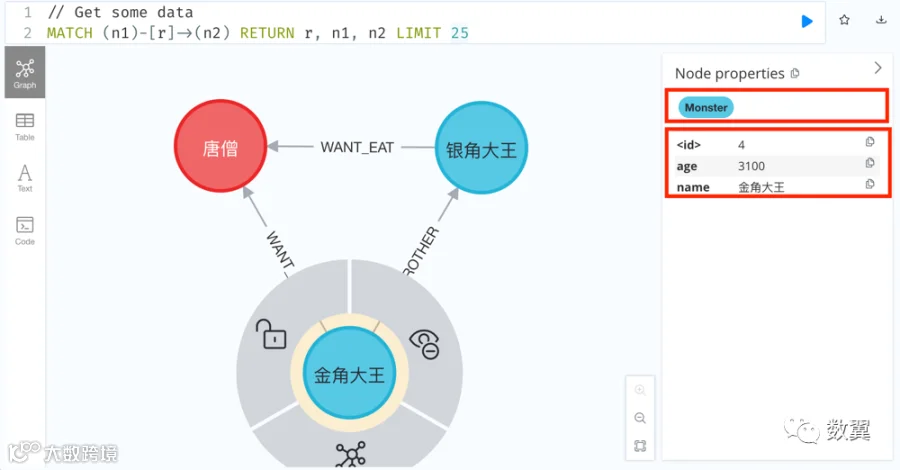
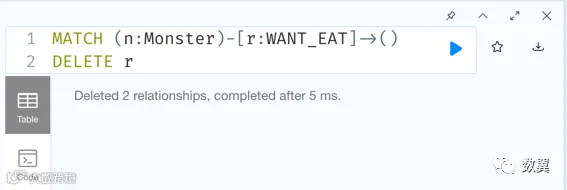
我们先删除妖怪想吃唐僧 这些边:
MATCH (n:Monster)-[r:WANT_EAT]->()
DELETE r提示成功删除两条边:
然后删除唐僧这个和尚,执行下面语句:
MATCH (n:Monk {title: '唐僧'})
DELETE n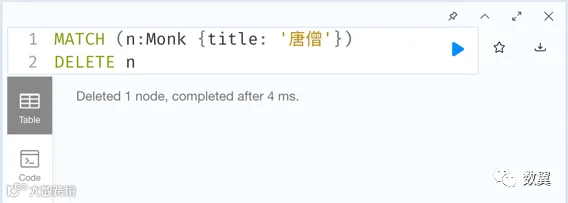
以及兄弟这条边:
MATCH (n:Monster)-[r:IS_BROTHER]->()
DELETE r删除所有妖怪:
MATCH (n:Monster)
DELETE n中文标签
我们刚才用 Monk Moster WANT_EAT IS_BROWSER 这些英文单词来表示节点和边,有人可能耗时是不是标签只能用英文?
当然不是,中文标签 Neo4j 也是支持的。
用英文标签纯粹是为了在写查询和程序的时候可以不切换输入法,并且大小写可以区分边和、节点。
我们改一下建模语句,先创建节点河边:
MERGE (j:妖怪 {姓名: '金角大王'})
ON CREATE set j.年龄 = 3100
MERGE (y:妖怪 {姓名: '银角大王'})
ON CREATE set y.年龄 = 2800
MERGE (t:和尚 {姓名: '唐僧'})
ON CREATE set t.身高 = 182
MERGE (j)-[rel1:是兄弟]->(y)
ON CREATE SET rel1.自从 = '-2023'
MERGE (j)-[rel2:想吃]->(t)
ON CREATE SET rel2.程度 = 4, rel2.可能性 = 0
MERGE (y)-[rel3:想吃]->(t)
ON CREATE SET rel3.程度 = 3, rel3.可能性 = 0然后查询返回:
// Query
MATCH (n1)-[r]->(n2) RETURN r, n1, n2 LIMIT 25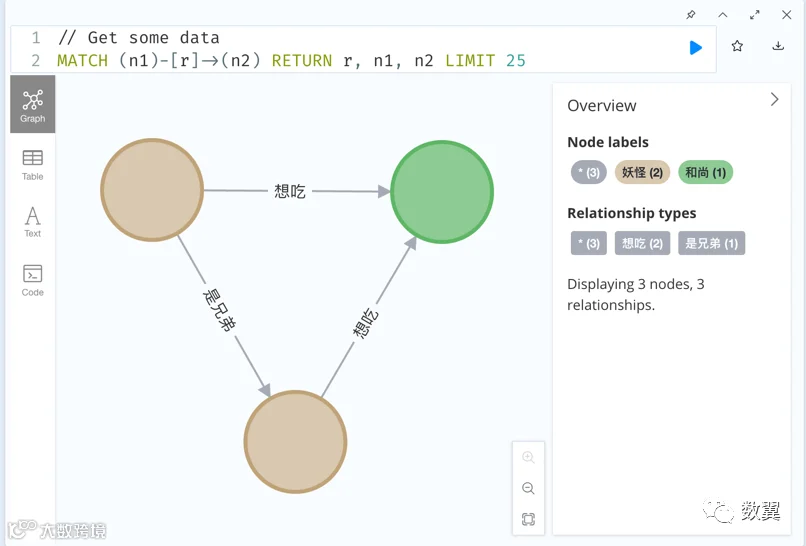
但是这样有一个问题,Neo4j 不知道哪个节点是节点名称,所以建议 title 和 name 属性使用英文,其他的属性可以根据需要使用中文或者英文。当然你也可以在 Neo4j Browser 里面进行设置节点名称使用哪个属性。
模型设计
我们熟悉了基本的建模流程之后,再回来考虑刚刚抛出的问题:节点上的内容应该怎么建模?
我们前面有一个例子是说「妖怪」和「和尚」这两个身份,当时我们是使用标签来表示的。其实还有两种表示方法:使用属性和节点。
使用属性表示的时候,他么都有一个统一的属性名字在区分,我们再扩展一下身份,唐僧不仅是谁和尚还是人,看看怎么表示:
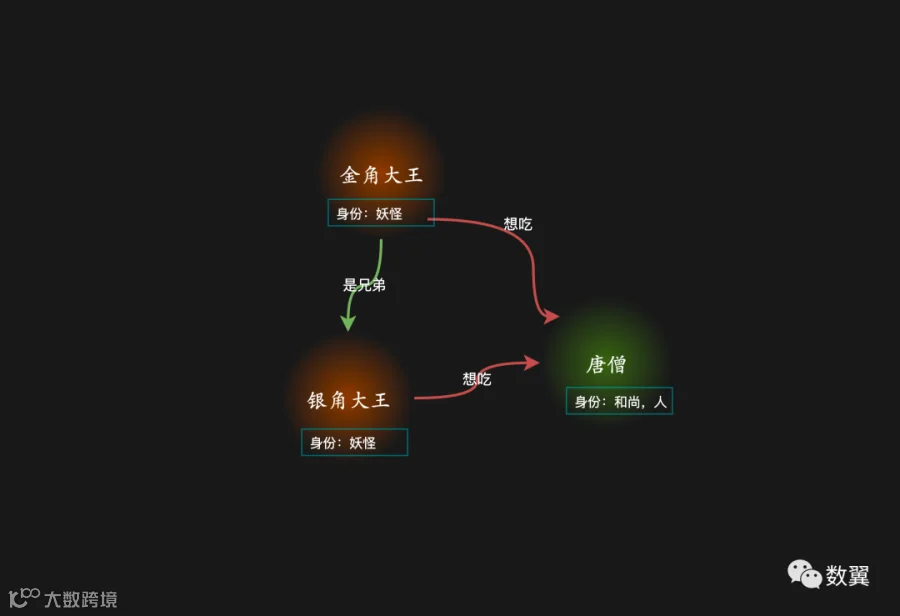
当然也可以用节点来表示:
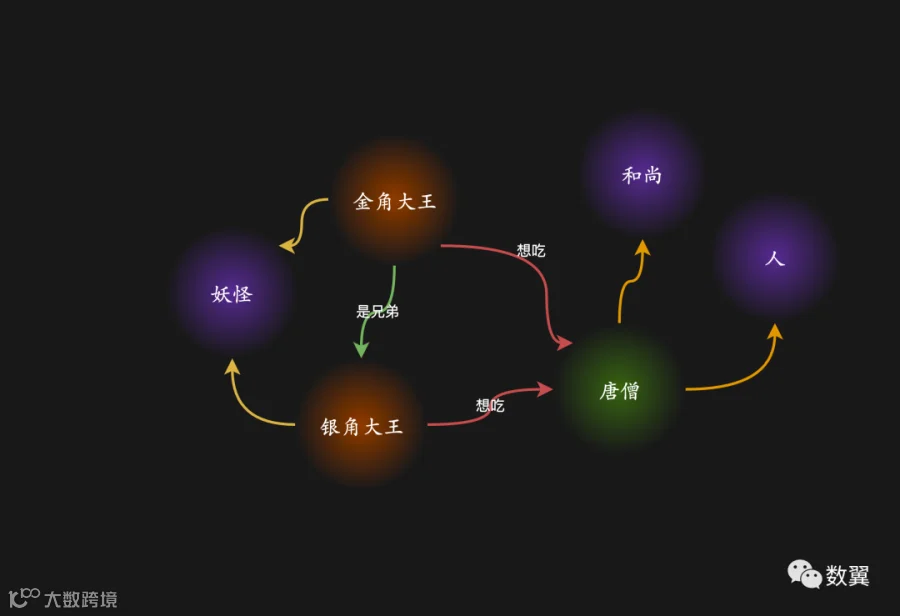
这三种方式没有优劣,最终还是看你对这些数据的使用和组织方式,怎么维护和查询方便就怎么定义。
复杂的数据结构
看到这里,你可能觉得你已经掌握了 Neo4j 图数据库的建模,足矣应对你的使用需求。
大多数时候是这样的,但是我还是有几个小技巧来教给你。
超边和中间点
还是拿西游记中金角大王和唐僧的故事来举例,如果我们要查询下他们什么时候初次见面的怎么办?
这个时候我们就可以用「超边」或者说是「中间节点」这个技术来进行建模。
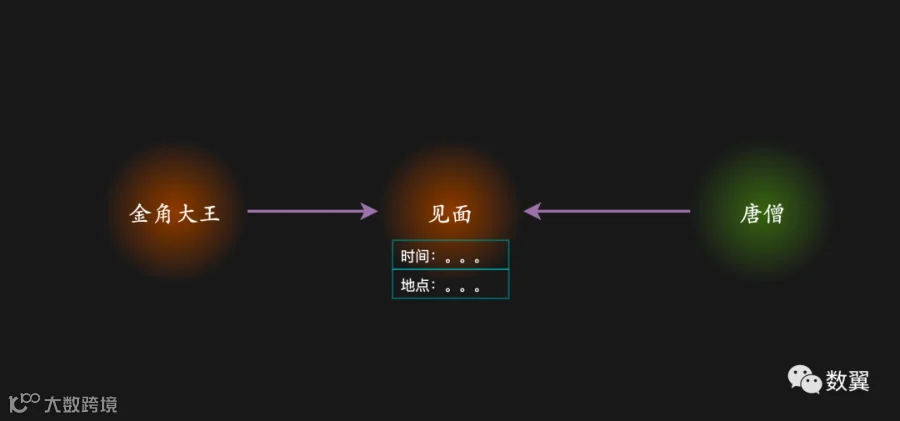
日期事件
我们扩展一下,这个中间节点不只有一次,或者是周期性发生的,比如学生每个学期的开学、打工人每天的打卡, 西游记里面唐僧的十次转世投胎,而对于「开学」、「打开」、「转世」这些事情有公共的属性,但是每次发生又有独立的属性。
此时我们可以把这个事件本身作为一个节点,每次事件发生也作为一个节点,就既能满足通用型查询、又能满足个性事件查询。
索引
图数据库和关系数据库一样也有索引的概念。合理的运用索引能很好的提升搜索性能。Neo4j 可以为节点和边创建索引,支持下面索引类型:
• 范围索引
• Lookup 索引
• 文本索引
• 点索引
• 全文索引。
对索引有兴趣的可以查看官方的 索引和搜索性能[6]文档。
结语
图数据库很强大,我们做设计的时候对其基本概念有一个完整的了解很有必要,了解了这些之后再我们应用的时候一些更高级的概念时, 结合我们之前的工程知识就变得信手拈来了, 比如 Cypher 查询、子查询、条件匹配、函数的使用、查询调优等等。
最后希望大家都能在图数据库的世界里尽情遨游。
引用链接
[1] Neo4j Graph Database: https://neo4j.com/product/neo4j-graph-database/[2] Neo4j AuraDB: https://neo4j.com/cloud/platform/aura-graph-database/[3] Cypher: https://neo4j.com/product/cypher-graph-query-language/[4] Neo4j 下载中心: https://neo4j.com/download/[5] Neo4j 容器安装文档: https://neo4j.com/docs/operations-manual/current/docker/introduction/[6] 索引和搜索性能: https://neo4j.com/docs/cypher-manual/current/indexes-for-search-performance/