
知识图谱是什么
知识图谱是人工智能领域的一个分支(交叉分支), 主要研究如何将现实世界中的知识以结构化的方式表示和存储,并通过图形数据库进行管理和访问。
知识图谱历史
为了解决传统搜索引擎的局限性,Google 在 2012年提出知识图谱。以解决传统搜索引擎只能根据关键词进行匹配, 无法理解用户的查询意图,因此无法提供准确和有价值的搜索结果的问题。
2012年,Google知识图谱语义网络包含超过570亿个对象,超过18亿个介绍,这些不同的对象之间有链接关系,用来理解搜索关键词的含义。
在谷歌于2012年发布知识图谱之前,Tim Berners-Lee于2006年就提出了Linked Data,是一种万维网数据上创建语义关联的方法。
更早之前,语义链网络(Semantic Link Network)已经开始了系统性的研究, 目标是创立一个自组织的语义互联方法来表达知识支持智能应用, 系统性的理论和方法作为专著发表于2004年。
知识图谱使用场景

知识图谱学科具有广泛的应用前景,包括:
• 语义搜索:知识图谱可以帮助搜索引擎理解用户的查询意图,并从知识库中检索出与查询相关的知识,从而提供更准确和更有价值的搜索结果。
• 自然语言问答:知识图谱可以帮助机器理解用户的自然语言问句,并从知识库中检索出与问句相关的知识,从而生成准确和全面的问答结果。
• 智能客服:知识图谱可以帮助智能客服系统理解用户的查询,并从知识库中检索出与查询相关的知识,从而为用户提供更专业和更有帮助的服务。
• 推荐系统:知识图谱可以帮助推荐系统更好地理解用户的兴趣,并从知识库中检索出与用户兴趣相关的商品或服务,从而为用户提供更个性化的推荐。
• 金融风控:知识图谱可以帮助金融机构更好地识别和预防金融风险,如欺诈、洗钱等。
• 医疗诊断:知识图谱可以帮助医生更好地理解患者的病情,并从知识库中检索出与病情相关的知识,从而为患者提供更准确和更有效的诊断和治疗方案。
• 法律服务:知识图谱可以帮助律师更好地理解法律条文,并从知识库中检索出与法律相关的知识,从而为客户提供更专业和更有针对性的法律服务。
• 教育培训:知识图谱可以帮助教师更好地理解教学内容,并从知识库中检索出与教学相关的知识,从而为学生提供更有效的教学。
• 产品研发:知识图谱可以帮助企业更好地了解市场需求,并从知识库中检索出与产品相关的知识,从而开发出更符合用户需求的产品。
• 科学研究:知识图谱可以帮助科学家更好地理解科学理论,并从知识库中检索出与研究相关的知识,从而推动科学研究的发展。
热门的知识图谱
不同公司开发了许多不同类型的知识图谱,用于不同的目的。虽然许多公司使用内部或较小的知识图谱来实现在线功能, 但一些最大的知识图谱正在被世界各地的许多人使用。下面列出了 Microsoft、Google、Facebook、IBM 和 eBay 迄今为止一些最大的知识图谱。 来源[1]
• 谷歌:知识图谱被用作跨谷歌设备的大规模分类功能,并直接嵌入到搜索引擎中。
• Facebook:发展人物、事件和想法之间的联系,主要关注与社交网络相关的新闻、人物和事件。
• IBM:为其他公司和/或行业开发内部知识图提供框架。
• 易趣:目前正在开发一个知识图,其功能是提供用户和网站上提供的产品之间的连接。
知识图谱交叉学科
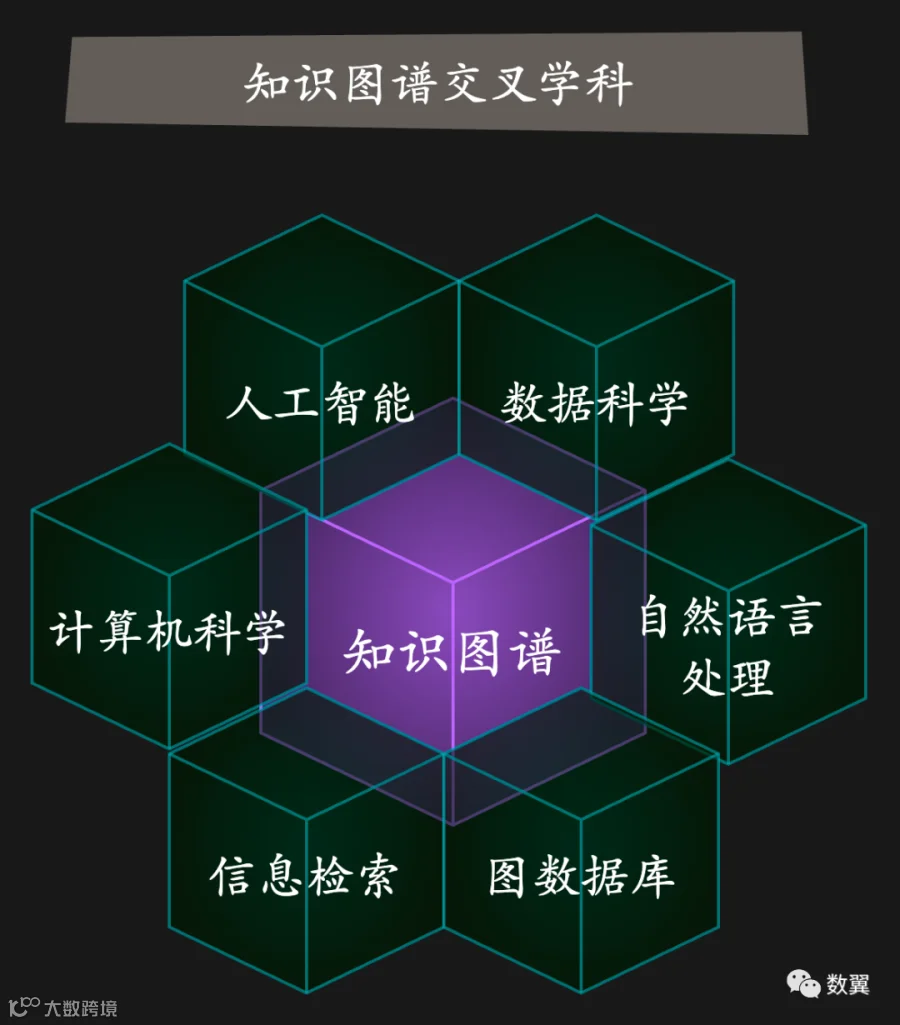
知识图谱学科是一个多学科交叉的学科,主要包括以下专业分支:
• 计算机科学:计算机科学是知识图谱的基础,主要研究知识图谱的表示、构建、推理和应用等技术。
• 人工智能:人工智能是知识图谱的重要支撑,主要研究知识图谱在人工智能领域的应用,如语义搜索、自然语言处理、机器学习等。
• 数据科学:数据科学是知识图谱的重要工具,主要研究知识图谱从多源异构数据中抽取知识的方法。
• 自然语言处理:自然语言处理是知识图谱的重要应用,主要研究知识图谱在自然语言理解和生成方面的应用。
• 图数据库:图数据库是知识图谱的存储和访问平台,主要研究知识图谱在图数据库中的存储和查询方法。
• 信息检索:信息检索是知识图谱的重要应用,主要研究知识图谱在信息检索方面的应用。
这六个学科与知识图谱的具体关系:
计算机科学
计算机科学是知识图谱的基础,主要研究知识图谱的表示、构建、推理和应用等技术。知识图谱的表示方法涉及到图论、数据结构、符号逻辑等计算机科学领域的理论和方法。知识图谱的构建方法涉及到自然语言处理、机器学习等计算机科学领域的技术。知识图谱的推理方法涉及到逻辑学、人工智能等计算机科学领域的理论。知识图谱的应用涉及到语义搜索、自然语言问答、推荐系统等计算机科学领域的应用。
人工智能
人工智能是知识图谱的重要支撑,主要研究知识图谱在人工智能领域的应用,如语义搜索、自然语言处理、机器学习等。知识图谱可以为人工智能提供丰富的知识资源,帮助人工智能系统更好地理解和处理信息。
数据科学
数据科学是知识图谱的重要工具,主要研究知识图谱从多源异构数据中抽取知识的方法。知识图谱可以从多源异构数据中抽取知识,而数据科学为知识图谱提供了抽取知识的方法和工具。
自然语言处理
自然语言处理是知识图谱的重要应用,主要研究知识图谱在自然语言理解和生成方面的应用。知识图谱可以为自然语言处理提供丰富的知识资源,帮助自然语言处理系统更好地理解和处理自然语言。
图数据库
图数据库是知识图谱的存储和访问平台,主要研究知识图谱在图数据库中的存储和查询方法。知识图谱可以存储在图数据库中,而图数据库为知识图谱提供了高效的存储和查询方法。
信息检索
信息检索是知识图谱的重要应用,主要研究知识图谱在信息检索方面的应用。知识图谱可以为信息检索提供更准确和更有价值的搜索结果
基本概念
知识图谱是结构化的语义知识库,用于以 符号形式描述物理世界中的概念及其相互关系。其基本组成单位是 「实体-关系-实体」三元组,以及 实体及其相关「属性-值」对,实体间通过关系相互联结,构成网状的知识结构。


知识图谱的特点
• 结构化:知识图谱将知识以结构化的形式表示,这使得知识更加容易理解和处理。
• 语义化:知识图谱将知识以语义化的形式表示,这使得知识更加准确和有用。
• 关联性:知识图谱将知识之间的关系表示出来,这使得知识更加完整和丰富。
知识图谱学科的主要研究内容包括:
• 知识表示:如何将现实世界中的知识以符号形式表示,并建立实体、关系和属性之间的联系。
• 知识构建:如何从多源异构的数据中抽取知识,并构建出准确和完整的知识图谱。
• 知识推理:如何在知识图谱中进行推理,从而获得新的知识。
• 知识应用:如何将知识图谱应用于实际问题的解决。
RDF
介绍三元组数据表示的话,不得不顺便提一下 RDF 框架[2]。
万维网联盟 ( W3C ) 维护 RDF 标准,包括不同格式的基本概念、语义和规范。
RDF 是一种关于资源的陈述的标准方法。RDF 语句由三个部分组成,称为三元组:
• 主题是由三元组描述的资源。
• 谓语描述主语和宾语之间的关系。
• 客体是与主体相关的资源。
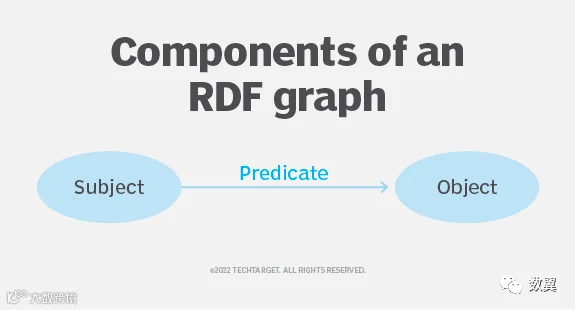
主体和客体是代表事物的节点。谓词是一条弧,因为它表示节点之间的关系。
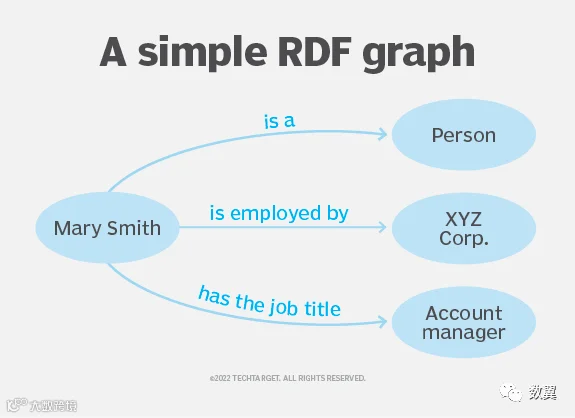
RDF 三元组的每个组成部分(主语、谓语和宾语)都可以表示为 URI 或 IRI。URI 可以是指向 Web 资源的 URL,也可以包含任意数据。
关于同一实体的多个 RDF 语句都将是 RDF 三元组。它们具有相同的主语,但谓语和宾语不同。当从这些三元组构建 RDF 图时,主题可以显示一次,多个箭头从主题分支出来,代表不同的谓词和不同的对象。
• Turtle 是 RDF 语句最流行的文本语法。W3C 将其描述为“紧凑且自然的文本形式”,其中包括常用模式的缩写。
• JSON-LD 使用 RDF 语句的 JSON 语法。
• N-Triples 是 Turtle 语法的子集,旨在成为 RDF 语句的更简单的基于文本的格式,以提高编写语句的人员的易用性。更简单的格式还使程序更容易创建和解析 RDF 语句。
构建知识图谱
知识图谱的构建是一个复杂的过程,主要包括以下几个步骤:
• 数据收集:收集知识图谱所需的数据,包括文本数据、代码数据、图像数据等。
• 数据清洗:对收集到的数据进行清洗,去除噪声和错误数据。
• 数据抽取:从数据中抽取出知识,包括实体、关系和属性。
• 数据融合:将来自不同来源的数据进行融合,形成统一的知识图谱。
• 数据质量评估:对构建好的知识图谱进行质量评估,识别和修正错误数据。

在构建知识图谱时,需要注意以下几个方面:
• 数据质量:数据质量是知识图谱的关键,需要对数据进行严格的清洗和验证。
• 知识表示:知识的表示方式会影响知识图谱的应用效果,需要选择合适的知识表示方法。
• 知识融合:来自不同来源的数据可能会存在冲突,需要进行合理的融合。
• 知识更新:知识图谱是不断变化的,需要定期进行更新。
数据收集
知识图谱数据收集是指收集构建知识图谱所需的数据,包括文本数据、代码数据、图像数据等。数据收集是知识图谱构建的第一步,也是非常重要的一步。

数据来源
知识图谱数据可以从以下几个方面收集:
• 公开数据:包括政府数据、企业数据、学术数据等。
• 社交媒体数据:包括微博、微信、知乎等平台的数据。
• 用户生成数据:包括用户评论、问答、博客等数据。
• 机器生成数据:包括自动生成的文本、代码、图像等数据。
数据收集的方法

知识图谱数据收集的方法可以分为以下几类:
• 爬虫:通过爬虫技术从互联网上爬取数据。
• API:通过API接口从数据源直接获取数据。
• 人工收集:通过人工的方式收集数据。
知识图谱数据收集的工具
目前,有许多知识图谱数据收集工具可供选择,包括:
• Scrapy:一个开源的爬虫框架,可以用于爬取网页数据。
• Beautiful Soup:一个Python库,可以用于解析网页数据。
• API SDK:各种应用程序或者数据源提供的API接口。
• 人工收集工具:如Google表格、Excel等。
• 定制工具:根据定制企业或者个人需求定制工具。
数据清洗
知识图谱数据清洗是指对收集到的数据进行清洗,去除噪声和错误数据。数据清洗是知识图谱构建的关键步骤,是确保知识图谱质量的重要保障。

数据清洗的目的
数据清洗的目的是:
• 去除噪声:噪声是指数据中的无效信息,会影响知识图谱的准确性。
• 纠正错误:错误数据会导致知识图谱的错误,需要进行纠正。
• 规范数据格式:数据格式不规范会影响知识图谱的处理效率。
数据清洗的步骤

数据清洗可以分为以下几个步骤:
• 数据预处理:对数据进行预处理,如去除空值、重复数据等。
• 数据校验:对数据进行校验,如检查数据类型、格式等。
• 数据清理:对数据进行清理,如去除噪声、错误数据等。
• 数据合并:将来自不同来源的数据进行合并。
• 数据验证:对清洗后的数据进行验证,确保数据质量。
数据清洗常见问题
在进行知识图谱数据清洗时,可能会遇到以下常见问题:
• 数据量大:知识图谱数据量通常很大,数据清洗需要花费大量的时间和精力。
• 数据复杂:知识图谱数据通常比较复杂,需要使用多种方法进行清洗。
• 数据更新:知识图谱数据是不断变化的,需要定期进行数据清洗。
为了解决这些问题,可以使用以下方法:
• 自动化清洗:使用自动化工具进行数据清洗,可以提高数据清洗的效率。
• 数据分割:将数据分割成多个小数据集,可以降低数据清洗的难度。
• 人工干预:对于复杂的数据,可以使用人工干预的方式进行清洗。
知识图谱数据清洗是一项重要的基础工作,通过有效的数据清洗,可以确保知识图谱的质量,提高知识图谱的应用效果。
数据抽取
知识图谱数据提取是指从数据中抽取出知识,包括实体、关系和属性。数据提取是知识图谱构建的关键步骤,是构建出高质量知识图谱的重要保障。

数据提取的目的
数据提取的目的是:
• 从数据中抽取出知识,包括实体、关系和属性。
• 将知识表示为结构化的数据,以便于存储和管理。
• 确保知识的准确性和完整性。
数据提取的步骤

数据提取可以分为以下几个步骤:
• 数据预处理:对数据进行预处理,如去除噪声、错误数据等。
• 实体识别:识别数据中的实体。
• 关系抽取:抽取数据中的关系。
• 属性抽取:抽取数据中的属性。
• 数据验证:对抽取出的数据进行验证,确保数据质量。
知识融合
知识图谱知识融合是指将来自不同来源的知识图谱进行融合,形成统一的知识图谱。知识融合可以提高知识图谱的准确性、完整性和一致性,为知识图谱的应用提供更好的支持。

知识融合的目的
知识融合的目的是:
• 提高知识图谱的准确性:通过融合来自不同来源的知识,可以弥补单个知识图谱的不足,提高知识图谱的准确性。
• 提高知识图谱的完整性:通过融合来自不同来源的知识,可以扩展知识图谱的范围,提高知识图谱的完整性。
• 提高知识图谱的一致性:通过融合来自不同来源的知识,可以消除知识图谱中的冲突,提高知识图谱的一致性。
数据质量评估
知识图谱数据质量评估是指对知识图谱中的数据进行评估,以确保数据的准确性、完整性和一致性。数据质量评估是知识图谱构建和应用的重要环节,是保证知识图谱质量的重要保障。

知识图谱数据质量评估的目的
知识图谱数据质量评估的目的是:
• 识别和修正知识图谱中的数据错误。
• 提高知识图谱的准确性、完整性和一致性。
• 为知识图谱的应用提供保障。
知识图谱数据质量评估的维度
知识图谱数据质量评估可以从以下几个维度进行:
• 准确性:数据是否正确,是否符合事实。
• 完整性:数据是否全面,是否包含了所有需要的信息。
• 一致性:数据是否相互矛盾,是否符合语义。
• 可用性:数据是否易于理解和使用。
结语
文章介绍了知识图谱的基本知识,以及构建知识图谱的流程。
整体来说构建知识图谱还是很复杂的事情,但是对我特定垂直细分领域,或者个人知识图谱来说,反倒没那么复杂, 系列后续文章跟大家介绍如何从头开始构建一个个人知识图谱。
参考:
• https://wordlift.io/blog/en/entity/knowledge-graph/[3]
• https://www.analyticssteps.com/blogs/what-knowledge-graph[4]
引用链接
[1] 来源: https://wordlift.io/blog/en/entity/knowledge-graph/[2] RDF 框架: https://www.techtarget.com/searchapparchitecture/definition/Resource-Description-Framework-RDF[3]: https://wordlift.io/blog/en/entity/knowledge-graph/[4]: https://www.analyticssteps.com/blogs/what-knowledge-graph
--- END ---