
![]() |卓越的全球化语言服务供应商
|卓越的全球化语言服务供应商
十年前,Google Translate 发布。当时,这项服务背后的核心算法还是基于短语的机器翻译。
而十年后的今天,更先进的神经网络机器翻译( Neural Machine Translation)技术已经使得翻译系统的速度和准确度有了大幅提升。Google 发现,在多个样本的翻译中,神经网络机器翻译系统将误差降低了 55%-85%甚至以上。
虽然成就喜人,但这对研究人员来说却远远不够。在他们看来,NMT 领域还有太多可提升的空间。
近日,来自 Google Brain 的四位研究人员 Denny Britz , Anna Goldie , Thang Luong, Quoc Le 就由 NMT 训练成本太高这一问题出发,对 NMT 架构的超参数进行了大规模分析,并且对建立和扩展 NMT 构架提出了一些新颖观点和实用建议。研究人员表示,学界还未有过类似的研究。
同时,该论文也已提交了今年的 ACL 大会(Association for Computational Linguistics)。
以下是为部分论文内容。
摘要
在过去几年里,基于神经机器翻译(NMT)技术的产品系统被越来越多部署在终端客户端中,NMT 本身也因此获得了巨大进步。但目前,NMT 构架还存在着一个很大的缺点,即训练它们的成本太高,尤其是 GPU 的收敛时间,有时会达到几天到数周不等。这就使得穷举超参数搜索(exhaustive hyperparameter search)的成本和其他常见神经网络结构一样,让人望而却步。
为此,我们首次对 NMT 架构的超参数进行了大规模分析。我们报告了数百次实验测试的经验结果和方差数(variance numbers),这相当于在标准 WMT 英译德任务上运行超过250,000 GPU 小时数的效果。从实验结果中,我们提出了有关建立和扩展 NMT 构架的创新观点,也提供了一些实用建议。
作为此次研究成果的一部分,我们也发布了一个开源的 NMT 框架,让研究员们能轻松使用该新技术,并得出最新试验结果。
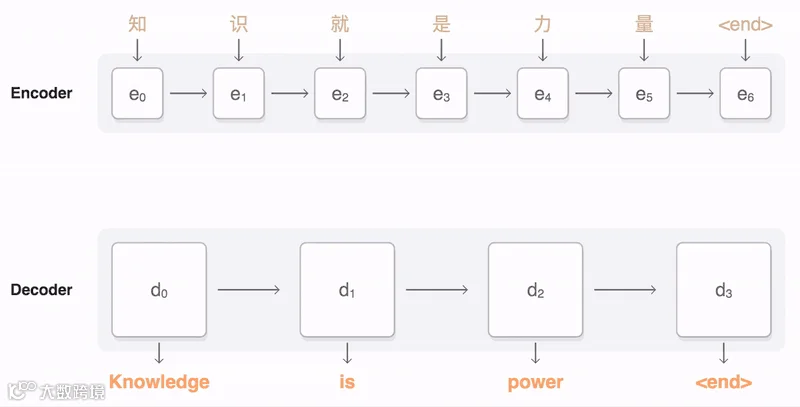
研究结论
在研究过程中,我们通过梳理关键因素,以获得最新的实验结果。
有些研究人员可能并不认为“集束搜索调节(beam search tuning)和大多数架构变化同等重要”,以及“使用了当前优化技术的深度模型并不总是优于浅度模型”等说法,但通过实验,我们为这类说法给出了实验证据。
以下是实验收获总结:
使用 2048 维的大型嵌入(embeddings)有最优实验结果,不过优势不大;仅有 128 维的小型嵌入似乎也有足够的能力去捕捉绝大多数必要的语义信息。
LSTM Cell 始终比 GRU Cell 表现得好。
2-4 层的双向编码器性能最佳。更深层的编码器在训练中不如2-4层的稳定,这一点表现得很明显。不过,如果能接受高质量得优化,更深层的编码器也很有潜力。
深度 4 层解码器略优于较浅层的解码器。残差连接在训练 8 层的解码器时不可或缺,而且,密集的残差连接能使鲁棒性有额外增加。
把额外的关注度参数化(Parameterized additive attention),会产生总体最优结果。
有一个调适良好、具有长度罚分(length penalty)的集束搜索(beam search)很关键。5-10集束宽度搭配1.0长度罚分的工作效果好像不错。
我们还强调了几个重要的研究课题,包括:
高效利用嵌入参数
注意机制(attention mechanisms)作为加权跳过连接(weighted skip connections),而不是记忆单元的角色作用,
深度循环网络需要更好的优化方法,
超参数变化(hyperparameter variations)还需要更具稳健性的集束搜索。
点击“阅读原文”查看完整论文
原文来源:雷锋网
