


机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效提高学习效率。
——百度百科
鸢尾花种类预测
作为机器学习的标志性练习项目,在这个项目里我们学习后的模型可以根据鸢尾花的四个特征(花萼的长和宽、花瓣的长和宽)来判别鸢尾花的种类:setosa,versicolor,virginnica。(虽然不懂什么意思,总之就是有三个种类。)

接下来,跟我一起来做做看吧!
环境准备
基本步骤

代码实现

结果分析

算法原理
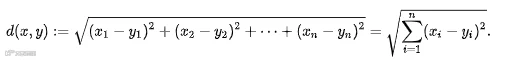
学习总结

HR++
产品顾问→
马上咨询

推荐阅读


点击图片查看原文

点击图片查看原文


你“在看”我吗?
