【灵思导读】龙虾终于能画图了!阿里Wan2.7-Image刚刚上线,捏脸可深入骨相、首创「调色盘」、3K超长文字写满A4纸不混乱,还能接入OpenClaw实现一句话出图。
养虾人激动不已!今天,龙虾终于学会了图像生成。
捏脸能到骨相级别,调色精准到HEX色号,文字渲染一次能写满整页A4纸,编辑时指哪改哪,喂入9张参考图后人物面容依然稳定。
够震撼吧?先来看这组示例。
同一段提示词,只变动外貌描述,生成了五张截然不同的面孔——

正面半身人像,一位【外貌的设定】的男性乐队主唱在舞台上演出,单手握住立麦,头微微后仰嘶吼,汗水从额头滑到下颌线,汗湿的黑色碎发贴在前额和鬓角,穿一件被汗浸透的黑色背心,锁骨和手臂肌肉线条清晰,舞台顶光从正上方打下来形成强烈的明暗对比,背景是模糊的彩色舞台灯光和烟雾,摇滚现场抓拍风格,高ISO颗粒感,85mm镜头。
从浓密络腮胡、青涩娃娃脸,到微胖身材、深棕黑色皮肤,主体保持了一致性。

同一个舞台,同一束顶光,却出现了五张完全不同的人脸!
背后的强大模型,是阿里4月1日刚刚推出的Wan2.7-Image,一个将图像生成与编辑能力融为一体的新模型,同时支持作为Skills接入OpenClaw。
通俗地说:你的龙虾,现在不仅能聊天、写代码、运行自动化,还能作图。而且画得相当出色。
千人千面,告别AI脸
「活人感」是一种微妙的真实,恰恰是AI生图最难掌握的地方。
打开任一图文平台,满眼都是同质化的「塑料AI脸」。比例完美的五官、毫无瑕疵的鸡蛋肌,以及空洞呆滞的眼神。
这些被算法培养出的「标准脸」,美得没有破绽,却如同流水线上批量生产的偶像练习生。
千人一面,缺乏灵魂。
Wan2.7-Image的解决方式,是将生成粒度细化到「骨相」与「皮相」的微观层级。一句简单的描述,就能实现从骨骼结构、眼眸深浅到五官细节的全方位定制。
你可以精确要求生成鹅蛋脸、圆脸、方脸或长方脸。
正面半身人像,一位25岁的东亚女性,【脸型的设定】,自然光线,眼神直视镜头,黑色直发披肩,穿白色圆领T恤,背景纯色浅灰,写实摄影风格,35mm镜头,浅景深。
鹅蛋脸、圆脸、方脸
这种「捏脸」还能进一步延伸到眼部细节的微调。杏仁眼、圆眼、丹凤眼,一句话就能定制。
一张超近距离面部特写,画面只截取眉毛到鼻尖的范围,一位25岁东亚女性,【眼睛的设定】,皮肤细腻有毛孔质感,自然光从正面柔和打入,没有妆容,素颜,睫毛根根分明,虹膜深棕色可见纹理,眼角有一颗小痣,背景完全虚化为奶白色,微距摄影风格,100mm微距镜头,超高清。
杏仁眼、丹凤眼、眯缝眼
整个人的面容通过一句话即可把握。千人千面,尽在一句话中。
这正是「活人感」的本质:不完美,但真实。
首创「调色盘」,色彩不再是盲盒
在设计师看来,颜色就是精准的空间坐标。
一句「暖橙色调」,对不同AI可能产生差异悬殊的结果:有时是莫兰迪的土橙色,有时是梵高向日葵的明黄色,有时又会偏向秋日夕阳的深红色。
这种「色彩盲盒」般的随机性,设计师根本无法交付。在严格的品牌视觉系统面前,1%的色差就意味着无效产出。
因此,Wan2.7-Image在业内首创「调色盘」功能,将色彩控制权还给创作者。
用户可以通过HEX色号,一键提取或输入参考图中的各种颜色及占比,自由调整颜色的数量和比例,自定义配色方案。
从马蒂斯浓郁的红色系、梵高明快的黄色系,到毕加索清冷的蓝色系,都能参考生成同色系的图片。

万相网页版已内置完整的调色盘交互,三步完成:
第一步,点击底部工具栏的「调色盘」按钮,弹出配色面板。系统预置了「蓝调」「热情」「马卡龙」「莫兰迪」等多种推荐配色方案,直接选用即可。
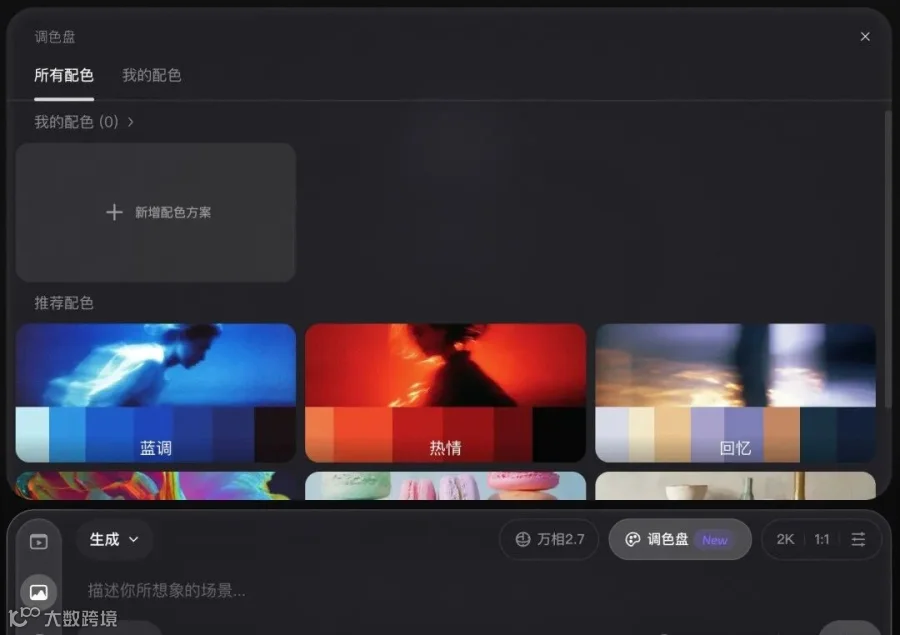
第二步,如需自定义:点击「新增配色方案」,然后点击「从图片提取配色」,上传任意参考图,系统会自动提取主色及占比。颜色数量可通过加减号增删,比例可拖动色块边界自由调整。
第三步,确认配色后返回主界面,调色盘已挂载到工具栏。输入场景描述,点击生成,输出的图片将严格遵循你定义的色彩方案。
有了这套流程,世界名画的独特色彩从此触手可及。
梵高《星月夜》中那热烈奔放、盘旋交织的蓝黄撞色,由Wan2.7-Image提取八种颜色,并重构于现代都市中。
可以看到,在这座灯火通明的城市里,点缀的正是星月夜中的色调。

一座现代城市的天际线夜景,高楼大厦的灯光倒映在平静的江面上,远处有一座跨江大桥,天空中有几朵流动的云,电影感构图,宽幅画面,油画质感。
又或者,将莫奈《日出·印象》中的蓝灰色调与太阳迸发出的柔和橙黄,映射到另一个物理空间中。
Wan2.7-Image把莫奈的色彩DNA植入到每个元素中,让江南水乡也带上了印象派的滤镜。
一座江南水乡古镇的清晨,石拱桥横跨窄河,两岸是白墙黛瓦的老房子,河面有薄雾弥漫,一条乌篷船静泊在桥下,柔和的晨光从东方透过来,摄影质感,35mm镜头。

同样,还可以把一张AI艺术画的色调,一键迁移到「大裤衩」的建筑艺术构图中。

3K超长文本,生图告别「文盲」时代
在AI图像生成的「顽疾清单」中,文本渲染始终位居榜首。
一旦字数超过几个词,AI的表现就开始失控:字母变形、笔画断裂、汉字错位,甚至整段文字莫名消失。
Wan2.7-Image对这一顽疾发起了正面攻克。它实现了对超长文字、表格、复杂公式的印刷级渲染,支持业内最长的3K Tokens文字输入,可以写满整页A4纸。

一张大学高等数学期末考试试卷,白色纸张,印刷体黑色文字,包含以下内容:
一、选择题(每题5分,共20分)
函数 f(x) = (x²-1)/(x-1) 在 x=1 处的极限为: A. 0 B. 1 C. 2 D. 不存在
若 ∫₀¹ f(x)dx = 3,则 ∫₀¹ 2f(x)dx = A. 3 B. 6 C. 9 D. 12
二、计算题(每题15分,共30分)
求不定积分 ∫ x²·eˣ dx
计算二重积分 ∬_D (x²+y²) dxdy,其中D为 x²+y²≤4
三、证明题(25分) 用ε-δ语言证明:lim(x→2) (3x-1) = 5
四、应用题(25分) 设曲线 y = x³ - 3x + 2,求该曲线在区间[-2, 2]上与x轴围成的面积。
标准A4纸排版,页眉印「XX大学 2024-2025学年第一学期期末考试」,页脚印「第1页 共2页」。
积分号、求和号、ε-δ语言,无一出错。
甚至多语言文字同屏输出,也难不倒Wan2.7-Image。

一张极具电影感的写实照片,展示一位优雅的中国女子,身穿精致的汉服风格深蓝色提花夹克(金丝祥云刺绣)和米色褶皱长裙,头发整齐地盘在脑后,插着一根精致的发钗。她正坐在一张古朴的深色木桌前,专注地阅读一本封面标有「WORLD LITERATURE」和中文「世界文学」古籍。 桌上堆放着两摞多语言书籍,书脊清晰可见,标有「Oxford English Dictionary」、「现代汉语词典」、和「DEUTSCHE GRAMMATIK」等字样。在她面前,一本打开的笔记本上摆放着一支精致的钢笔,笔记本上写满了手写笔记。在桌子的左侧,两个古董地球仪(一个显示欧洲,一个显示亚洲)摆放有序。 背景是两个巨大的、堆满数千本多语言书籍的实木书架,书籍摆放整齐。一个大型的中式木窗位于左侧,透过窗户可以看到一个宁静的竹林花园和远处的树叶。窗玻璃旁墙上清晰地贴着一个挂轴,上面写着四个中文大字:「学无止境」。 自然的晨光从窗户洒进来,照亮了场景,营造出温暖、宁静的氛围。视角是眼平视,捕捉了女子和环境的丰富细节。电影级画质,自然胶片颗粒。

一位面带微笑的、不同族裔的五人小组,在阿姆斯特丹繁忙的、铺有石板的步行市场街道上,面向镜头,肩并肩站成一排。从左到右:一位老年中国女性,穿着传统的丝绸图案夹克,双手拿着一个木牌,上面用白色汉字写着「你好!」;一位年轻的日本男性,戴着眼镜,穿着米色连帽衫,拿着一个纸板标志,上面用黑色日文写着「こんにちは」;一位年轻的法国女性,戴着黑色贝雷帽,穿着条纹衬衫,拿着一个纸板标志,上面用黑色法文写着「bonjour!」;一位年轻的印度男性,戴着深蓝色头巾,穿着米色突尼克衫,拿着一个纸板标志,上面用黑色印地语写着「नमस्ते!」;一位年轻的非裔女性,留着蓬松的卷发,穿着色彩鲜艳的图案上衣,拿着一个纸板标志,上面用黑色葡萄牙语写着「Olá」。背景是典型的荷兰运河房屋、一辆行驶中的阿姆斯特丹有轨电车、色彩鲜艳的街道旗帜和繁忙的市场摊位,柔和的日光,景深较浅。
AI绘图的「文盲」时代,由此终结。
交互式编辑,指哪打哪
生图能力再强,创作者最终仍需要编辑。而AI的编辑能力,长期以来是一块烫手的短板。
用过传统AI修图的人,或许都经历过一种绝望:改一下背景颜色,主体人物的服装也变了;稍微调整一下嘴角,整个面部结构崩塌重建。AI不理解「局部修改」的边界,把不该改的地方也改了,妥妥的「效率黑洞」。
Wan2.7-Image用「精准框」的交互方式解决了这个问题。在指定区域内完成元素添加、对齐、移动元素或logo,框外的内容丝毫不变。
举个例子,精准框选图中的大雁,并输入指令:将图中框选的大雁移动到虚框位置,并且姿势变成站在屋檐上。
被框选的大雁,已经落到了屋檐上,图中的其余部分都被「完美锁定」,未受任何干扰。
更令人惊叹的是,Wan2.7-Image智能地将大雁缩小,使其符合透视原理,完美融入远景建筑物的比例。

大雁的姿态也从「展开双翼飞翔」切换为「收起翅膀直立栖息」,整个画面过渡非常自然。
这种指哪打哪的「交互式编辑」,让AI终于从「不可控的艺术家」变成了「听话的执行搭档」。
最多9图参考,主体统一不走形
多人场景一直是AI生图的重灾区。角色一多,脸就崩,风格就飘。
Wan2.7-Image支持最多9张图片作为参考源,多张参考图喂进去,人物长相、风格、光影全锁定,输出结果在视觉上高度统一。
做电商的朋友们真的有福了。只需上传一张参考图,Wan2.7-Image就能带着同一个模特在全球各地「瞬移」,不管环境怎么变,主体人物的长相、神态都稳定如初。
上一秒身着波西米亚长裙,漫步在马尔代夫的细软沙滩,下一秒已身处巴黎街头慵懒地喝着咖啡。
从高级商务范到东京潮流街拍,再到健身房的运动风,切换得游刃有余。
不止人物。
五双完全不同的鞋子,Wan2.7-Image也能完美揉进同一张画幅,无变形、无违和。这才是电商人梦寐以求的生成器。

更厉害的是,Wan2.7-Image还能一口气生成多达12张逻辑连贯的图像序列。
下面这个测试中,它连续生成八张图,构成了一个完整的小故事,角色特征始终如一,几乎没有偏差。
请生成一组8张逻辑连贯的电影分镜序列,讲述以下故事:一个穿黑色风衣的年轻女性深夜走进一家无人便利店,她从货架上拿了一杯泡面,坐在窗边等热水,窗外开始下雨,她看着雨发呆,手机屏幕亮了一下她没接,泡面泡好了她开始吃,最后一张是她吃完走出便利店撑开伞消失在雨夜街道尽头。全程无对白,电影感构图,每张画面的机位和景别有变化(远景、中景、特写交替),统一冷青色调,35mm胶片质感。
从「单帧」到「时序」,分镜脚本、PPT系列配图、电商模特套图、多视角建筑方案,都可以批量交付。AI生成从「逐张抽卡」迈入「序列化生产」。
六边形战士是怎么练成的
实测看完了,拆解底层。
Wan2.7-Image凭什么做到上面这些?五大功能的背后,每一项都指向算法架构与训练数据上的深层变革。
先看硬指标。
在人类偏好盲测中,Wan2.7-Image的文生图能力超过GPT Image 1.5和国内主流模型,在文本渲染、照片级成像和世界知识三个指标上,逼近Nano Banana Pro,堪称国内最强生图模型。
再看能力面。
Wan2.7-Image支持交互式编辑(文字编辑、空间变换、内容生成和替换),多图像生成能力覆盖时尚美容、平面设计等多领域,堪称六边形战士。
那么关键问题来了:它为什么不只会生图,还更懂图?
答案藏在三层技术栈里。
第一层,数据。
超大规模的异构数据底座,不仅涵盖全域品类的视觉素材,还整合了理解类数据。模型不是只看过图,它还「读」过图。
第二层,架构。
Wan2.7-Image采用生成与理解统一的模型架构,在共享的潜在空间内完成语义映射。文字紧挨着画面,模型不需要费力去猜文字对应的画面,它本来就知道。
第三层,训练。
训练流程中引入了多模态指令(文字+图片混合输入),让模型实现了从单纯的像素拟合到底层语义认知的跨越。配合多维精细标注体系(按布局、文字、光影、拍摄角度、用途等维度标注)和分阶段训练策略,模型在长尾场景下依然稳得住。
同步上线的还有Wan2.7-Image-pro,基于更大规模数据和模型尺寸训练而成,构图更稳,语义理解更精准。追求极致效果的用户,可以直接上Pro版。
三步接入龙虾,让它替你画图
这一次,Wan2.7-Image同步支持作为Skills接入OpenClaw。
那么,具体该怎么接?
万相网页版左下角已经挂上了「龙虾」图标,简单三步一键完成接入——
第一步,在你的「龙虾」里通过对话安装Skills,直接发一句:
帮我安装Wan-skills https://github.com/Wan-Video/Wan-skills
第二步,按照提示告诉「龙虾」阿里云百炼API Key。
第三步,用对话开启「龙虾」生图体验。
接入之后,即可立刻体验Wan2.7-Image生图魔法了。
上面实测中,捏脸、调色、长文本渲染、精准编辑、多主体一致性,全部可以通过龙虾的对话界面触达。
这才是AI生图真正该有的样子:深度嵌入你已有的工作流,成为一个随叫随到的「设计师」。
每个人手里,都握着遥控器
回看Wan2.7-Image的五项核心能力,它做的事说到底就一件:把创作的控制权,从算法的随机性里夺回来,交还给人。
一个十人规模的短剧团队,过去最头疼的是「预生产」阶段。角色长什么样,分镜怎么画,特效预演怎么做,每一步都是时间和钱。现在,千人千面的捏脸加上组图生成,角色设定、动作参考、视觉方案可以在正式开机前全部跑通。试错成本从「天」压缩到「小时」。
一个做穿搭号的自媒体博主,日常最大的消耗不是选品,而是配图。封面图的风格要统一,OOTD的场景要多变,系列内容的视觉调性不能跑偏。现在一段精确的提示词加一个调色盘,品牌视觉的一致性就有了保障。
一个中小电商商家,一件商品需要数十张素材图。传统摄影外包的成本和周期让人望而却步。多主体一致性加上组图生成,单张模特图可以裂变为覆盖不同场景、不同卖点的完整素材库,上新周期大幅缩短。
从「千篇一律」到「千人千面」,从「盲盒抽卡」到「精准微操」。
AI生图这件事,第一次真正由你说了算。
———— END ————
灵思极智旗下“极智系列”三款AI智能应用

关注后,两步置顶服务号,可第一时间收到灵思极智推文!