【灵思导读】全网震动!《生化危机》女主角跨界写代码,用Claude打造出全球顶尖的AI记忆系统,拿下史上首个满分。每年只需0.7美元,就能让大模型拥有永久记忆。
真是罕见!好莱坞顶级明星也开始写代码了。
这几天,一个名为MemPalace的开源「AI记忆系统」火爆全网,被公认为最强的记忆AI。
最令人意外的是,其核心开发者名单里,竟然出现了一位国际巨星——
曾出演《第五元素》、《生化危机》的女主角米拉·乔沃维奇。
白天,她拍完戏、走完Miu Miu时装秀、安顿好孩子;深夜,便沉浸于「氛围编程」中。
她和工程师好友Ben Sigman一起,借助Claude协作,将这个明星项目开源。
在公认最严苛的长期记忆基准LongMemEval上,MemPalace以500道题全部答对的空前成绩,拿下全球首个满分。
如今,该项目在GitHub上已狂揽17.9k星,Fork数高达2k。
GitHub地址:https://github.com/milla-jovovich/mempalace
顶流巨星成功跨界转型!
巨星跨界,联手Claude打造爆款AI
MemPalace的诞生带有些许偶然。
半年前,相交20多年的老友、资深工程师Ben Sigman首次向Milla介绍了Claude Code。
作为热爱写作的创作者,她立刻意识到:这个工具能将自己脑中天马行空的想法,变成实际运行的代码。
但在尝试开发一款大型游戏时,她撞上了一堵「无形的墙」。
Milla发现,AI虽然强大,但缺少「灵魂」与「积淀」——
AI只能掌握已有过的事。真正创造出独一无二、与众不同的东西的,是使用它的人类。
没有我们的想象力和永不满足的好奇心,AI只不过是个搜索引擎而已。
这番话并非空谈,而是她开发中遇到的真实痛点:
每次与AI开始新对话,之前讨论过的设计、推翻过的方案、尝试过的失败思路,全被清空。
于是,Milla敏锐地意识到,解决AI的长期记忆问题,甚至比游戏项目本身更加关键。
她和Ben Sigman决定转向,将这件「挡路的事」做成了一个独立项目。
Milla以「架构师」身份重塑逻辑,Ben则用代码将设计落地。
两人联手打磨6个月,最终这套名为「记忆宫殿」的系统——MemPalace正式诞生。
那么,MemPalace到底是什么?
「记忆宫殿」问世,满分刷新SOTA
其名灵感来源于两千年前的古希腊。
当时,古希腊演说家用一种叫「记忆术」的方法背诵长篇演讲——
将每段内容「存放」在不同房间里,演讲时只需在脑中走一遍宫殿,内容便被逐一调出。
因此,MemPalace借鉴「记忆宫殿」技巧,将数据「结构化」,并构建出一个虚拟空间:
每个项目、每个人、每个主题,都是宫殿里的一座「翼楼」。
翼楼里设有「房间」,按主题分类:认证系统一间、数据库选型一间、部署流程一间,数量不限。
房间之间由「走廊」串联,走廊按记忆类型划分:决策、里程碑、偏好、建议、发现,共五条固定通道。
跨翼楼的同名房间间,系统会自动生成「隧道」。
比如,「凯」这个人的翼楼里有间「认证迁移」,「漂流木」这个项目的翼楼里也有间「认证迁移」——隧道自动打通,同一件事在不同视角下的记忆被瞬间关联。
每个房间配有一个「衣柜」,存储摘要索引;衣柜里的「抽屉」则存放原始对话全文,一字不删。
搜索时,AI无需翻遍全部数据。
它先定位翼楼,再进房间,再开抽屉——范围从全库缩小到精确命中。
官方在2.2万多条真实对话记忆上测试,全库搜索召回率为60.9%,加上翼楼+房间过滤后直接升至94.8%,提升34个百分点。
换句话说,结构本身就是检索能力。
而且,所有数据全存在本地ChromaDB里,不调API、不上云、不花钱。
每年仅需0.7美元,记住所有事
再看一组对比数据——
按Milla的算法,把所有对话粘进去,一位重度AI用户半年大约会累积1950万token的对话历史。
如果只让大模型做摘要,一年要花约507美元,关键是摘要会丢失关键的推理过程。
而用MemPalace,每次AI启动仅加载170个token的关键事实——你的团队、项目、偏好……只在需要时才检索。
AAAK:专为AI设计的「速记法」
MemPalace中还有一个亮眼设计,叫AAAK。
这是一种专门写给AI读、而非给人看的压缩方言。
举个例子,下面这段英文约1000个token:
Priya 是 Driftwood 团队的负责人:Kai(后端,3 年)、Soren(前端)、Maya(基础设施)和 Leo(初级,上个月刚入职)。他们正在做一个 SaaS 数据分析平台。当前 sprint 是把鉴权迁移到 Clerk。Kai 基于价格和开发体验推荐了 Clerk 而非 Auth0。
压缩成AAAK后,仅约120个token:
TEAM: PRI(lead) | KAI(backend,3yr) SOR(frontend) MAY(infra) LEO(junior,new)PROJ: DRIFTWOOD(saas.analytics) | SPRINT: auth.migration→clerkDECISION: KAI.rec:clerk>auth0(pricing+dx) | ★★★★
信息无损,token减少8倍。
最妙的是,AAAK本质是结构化文本,任何能读文本的大模型——Claude、GPT、Gemini——都能直接理解,无需解码器、无需微调。
48小时,社区彻底检验
但故事还没完。
MemPalace上线不到48小时,开源社区就把项目里的水分挤了个干净。
第一刀砍在AAAK上。
AAAK是MemPalace自研的一套「缩写方言」,官方最初声称能实现「30倍无损压缩」。
社区拿真实tokenizer一跑,发现项目里的示例根本不省token——英文原文66个token,AAAK编码后反而变成73个。
而且AAAK是有损的,并非无损。在LongMemEval上,AAAK模式只拿到84.2%,比raw模式的96.6%低了12.4个百分点。
第二刀砍在「+34%宫殿增益」上。
这个数字对比的是「不过滤直接搜」与「用翼楼+房间做元数据过滤后搜」。元数据过滤是ChromaDB的标准功能,并非MemPalace独创。有用,但不是护城河。
第三刀砍在矛盾检测上。
项目描述得像是知识图谱会自动做事实校验,实际上fact_checker.py是一个独立脚本,根本没有接入知识图谱的操作流程。
然后Milla和Ben做了一件在开源圈相当少见的事。他们没有删评论、没有辩解,而是直接在项目顶部贴了一封公开信,逐条认错。
AAAK的token示例:承认用了粗糙的启发式算法,没跑真tokenizer。
「30倍无损压缩」:承认夸大,改口为「有损缩写系统」。「+34%宫殿增益」:承认措辞误导,补充说明是标准元数据过滤。
矛盾检测:承认未接入,列出了待修复的Issue编号。
公开信最后一句:「我们宁愿正确,也不愿看起来厉害」。
开源社区的反应也很有趣。批评过后,反而有更多人开始认真审视这个项目——96.6%的raw模式成绩是实打实的,本地免费也是实打实的。
扒皮没有杀死MemPalace,反而给它做了一次免费的信任审计。
三步上手,开发时代真的变了
pip install mempalace# Set up your world — who you work with, what your projects aremempalace init ~/projects/myapp# Mine your datamempalace mine ~/projects/myapp # projects — code, docs, notesmempalace mine ~/chats/ --mode convos # convos — Claude, ChatGPT, Slack exportsmempalace mine ~/chats/ --mode convos --extract general # general — classifies into decisions, milestones, problems# Search anything you've ever discussedmempalace search "why did we switch to GraphQL"# Your AI remembersmempalace status
若要接入Claude/ChatGPT/Cursor等支持MCP的工具,只需一行命令:
# Connect MemPalace onceclaude mcp add mempalace -- python -m mempalace.mcp_server
之后19个工具便接好了,AI会自己调用。你再也不用手动敲mempalace search。
这个项目最令人感慨之处,不一定是那个100%的分数,也不一定是30倍的压缩比。
而是它再次提醒我们:AI时代「开发者」的边界正在消失。
一位以《第五元素》《生化危机》闻名的巨星,与一位工程师朋友,借助Claude,就拿下了一个被大厂刷了一年多的行业SOTA。
关键是,它还是开源、免费、本地运行的版本。
Ben最新一条帖子中,还做了一个双关:Mempalace -> Multipass。
——熟悉《第五元素》的人都知道,那是Leeloo全片最经典的一句台词「通行无阻」。
看来这次,是真的「通行无阻」了。
———— END ————
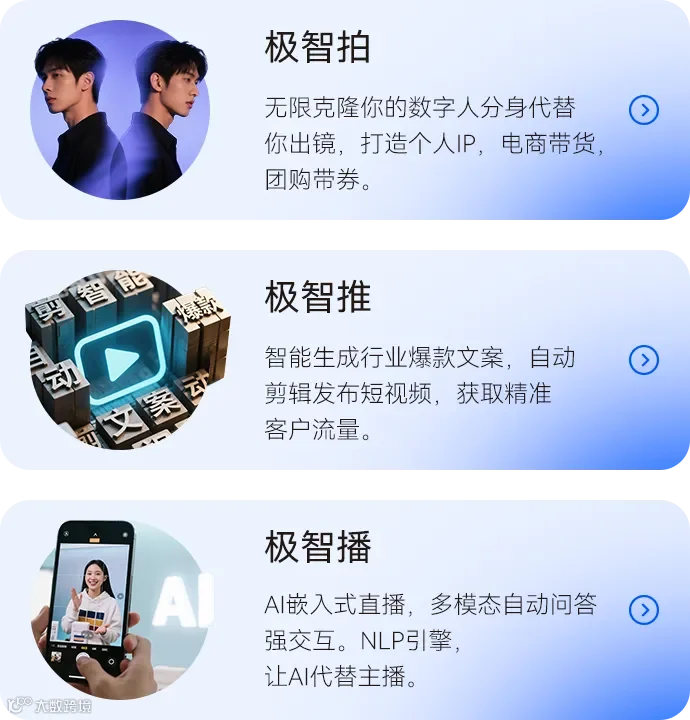
灵思极智旗下“极智系列”三款AI智能应用