Token概念解析:深入理解AI世界的基本单位

为何Token概念常令人困惑?
在讨论大模型时,Token是一个无法回避的概念。我们常听到“模型支持100K Token上下文”、“API按Token计费”等说法,但Token究竟是什么?为何有时一个字符对应一个Token,有时多个字符才对应一个?
若您对此感到困惑,本文将用生活化的类比,帮助您透彻理解AI领域的这一“基本单位”。

从认知机制理解Token存在的必要性
在阐释Token之前,我们先做一个简单的实验:请快速读出以下单字:薛、赜、罅、龘,您是否需要停顿辨认,甚至有些字完全不认识?但如果这些字出现在词语中,如“薛定谔谔”、“赜赜探”,您可能立刻就能读出来。
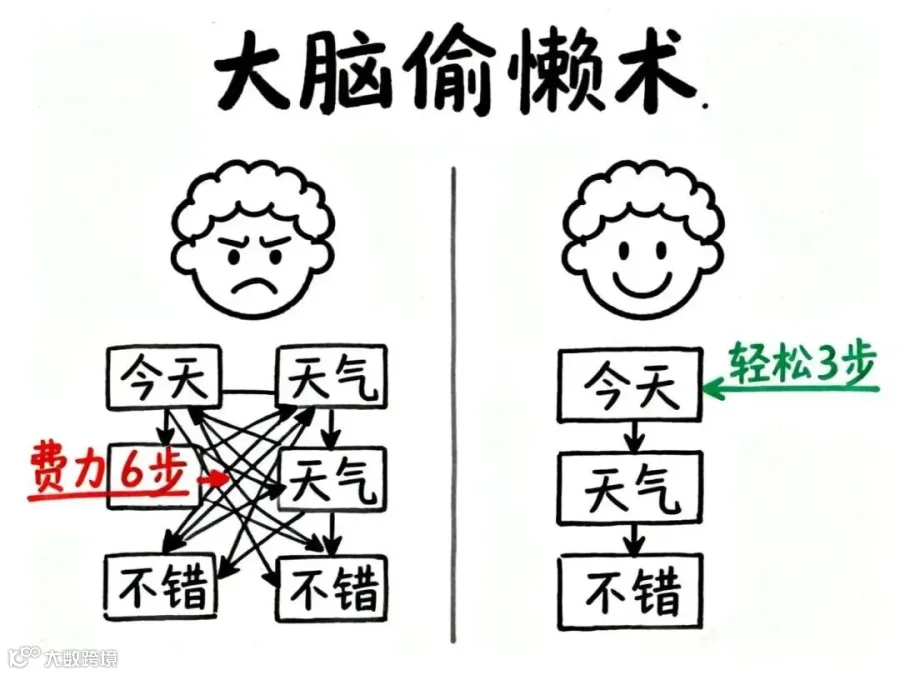
这体现了人脑的“效率优化机制”:我们更倾向于将有意义词语或短语作为整体处理,而非逐个识别单字,从而显著提升理解效率。
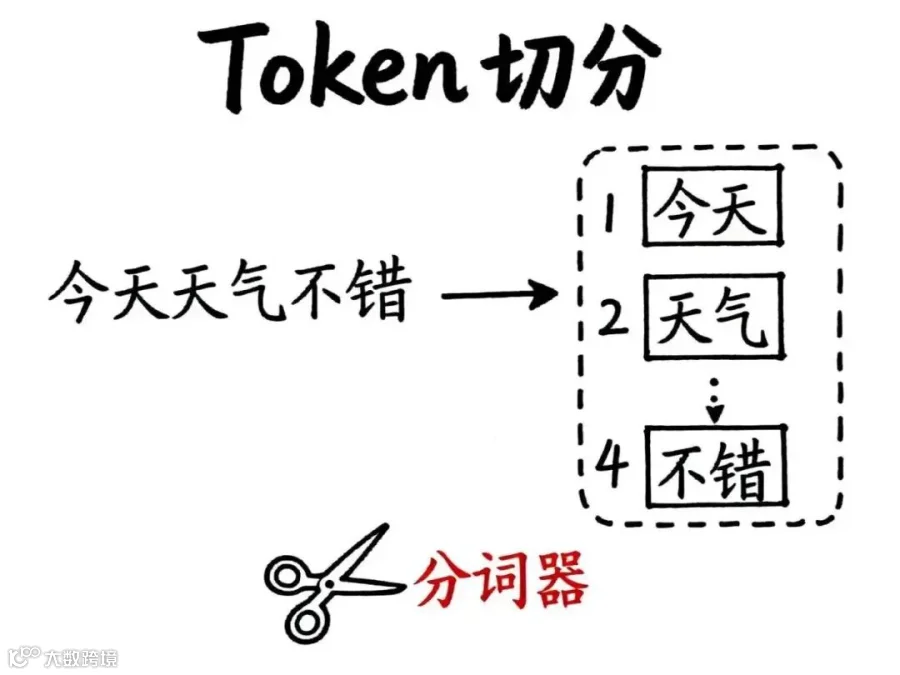
以“今天天气不错”为例:
• 按字处理:需处理6个单元并理解其组合关系
• 按词处理:只需处理“今天”、“天气”、“不错”3个有意义单元
既然人脑采用这种高效模式,AI自然也可以借鉴。
这就是Token存在的根本意义——它作为AI世界的“信息构建单元”,使大模型能够以更高效率处理文本。

Token的本质是什么?
简而言之,Token是大模型理解与生成文本的最小单位。
当您向ChatGPT或DeepSeek输入一段文字时,模型并非直接“读懂”内容,而是先通过一个称为分词器(Tokenizer)的组件将文本切割成多个Token。
切割后的Token可能对应以下不同语言单位:
• 一个汉字:「鸡」
• 两个汉字:「苹果」
• 三个汉字:「孙悟空」
• 一个标点:「。」
• 一个英文单词:「apple」
• 一个单词片段:「ing」
为何如此不统一?
因为分词器通过分析海量文本发现,某些字符组合频繁共现,将其打包处理更为高效。这类似于点餐时选择“套餐”比单点更便捷。

分词器的工作原理
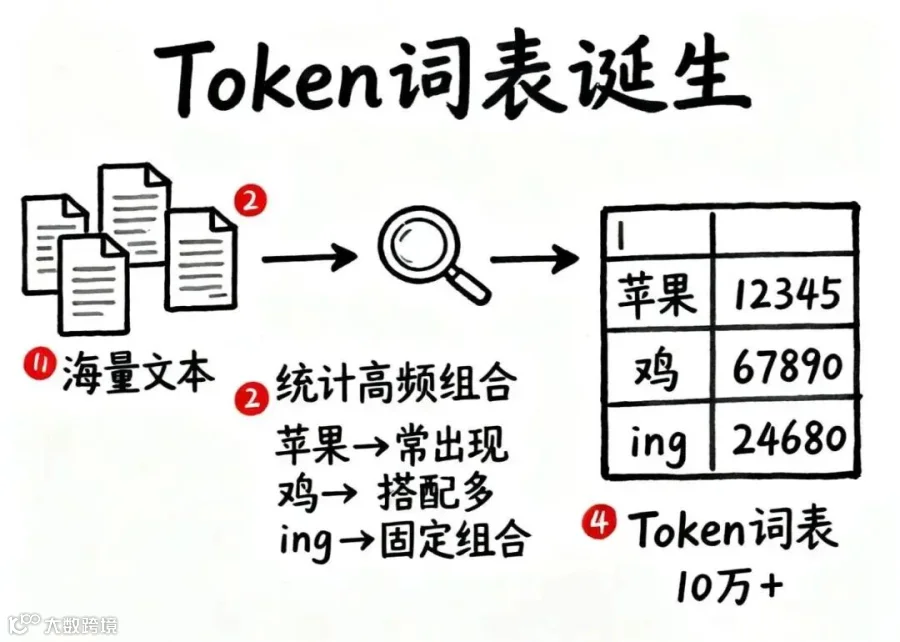
分词器的训练本质是“发现规律、构建词表”的过程:
1. 统计高频组合:分析大量文本,识别常一起出现的字或字母序列
2. 构建Token词表:形成包含数万甚至更多Token的映射表,涵盖常见字、词、符号
3. 转换与编码:
• 输入阶段:将文本切割为Token并转换为数字编号
• 计算阶段:模型仅处理这些数字编号
• 输出阶段:将数字编号转换回人类可读文本
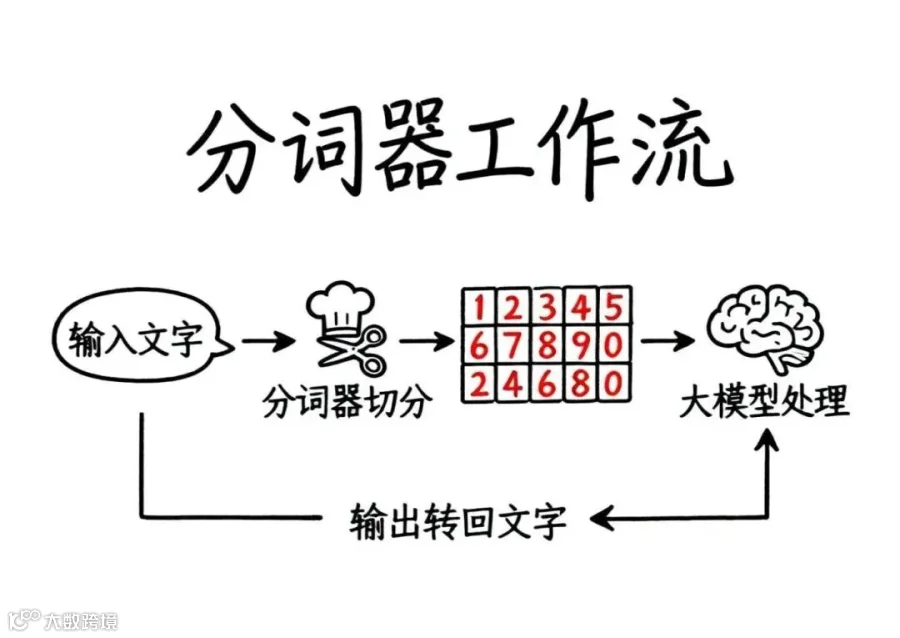
这一过程类似于餐厅分工:分词器是“切配工”,负责将食材(文本)切成合适大小;大模型是“主厨”,负责将处理好的食材烹制成菜肴(生成内容)。切配工的刀工越精准,主厨就越高效。

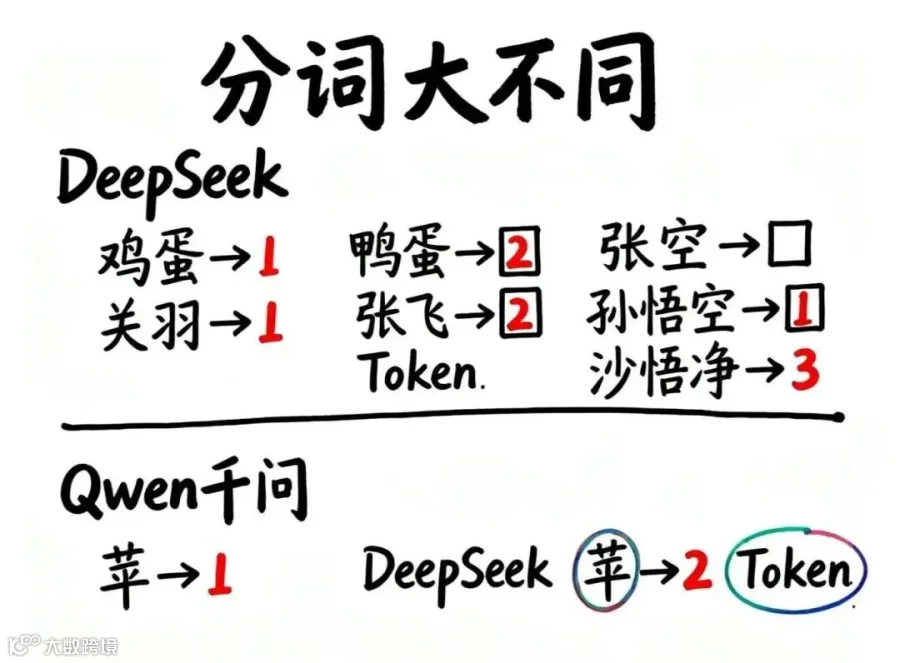
Token的差异性:为何不同模型切割方式不同?
有趣的是,不同大模型的分词策略可能存在显著差异。通过OpenAI的Tokenizer工具可观察到以下现象:
• 案例1:笑声处理
「哈哈」→ 1个Token
「哈哈哈」→ 1个Token
「哈哈哈哈」→ 1个Token
「哈哈哈哈哈」→ 2个Token
说明训练数据中连续4个“哈”为常见模式,第5个“哈”超出高频范围。
• 案例2:词语处理
在DeepSeek中:
「鸡蛋」→ 1个Token(高频词打包)
「鸭蛋」→ 2个Token(鸭+蛋)
「关羽」→ 1个Token
「张飞」→ 2个Token
这反映训练数据中“鸡蛋”出现频率远高于“鸭蛋”。
• 案例3:跨模型对比
同一词组「苹苹」:
• DeepSeek中 → 2个Token
• Qwen(千问)中 → 1个Token
这种差异源于各模型训练数据不同,对“高频组合”的判断标准各异。

Token的实用价值:计费机制解析
目前主流大模型均按Token数量计费,其合理性基于以下原因:
1. Token数量直接对应计算量:模型生成内容本质是预测“下一个最可能Token”,处理越多Token,消耗算力越大。
2. 中英文Token消耗差异:由于分词设计,中文通常更“费Token”。例如:
• 中文「人工智能」可能切为3-4个Token
• 英文「Artificial Intelligence」仅需2-3个Token
这意味着中文提问可能比英文多消耗20%-30%的Token费用。
优化Token消耗的实用建议 :
• 精简提示词:避免冗余描述,用简洁语言表达需求
• 善用上下文:多轮对话中避免重复已提及内容
• 设置长度限制:明确要求模型用特定字数回答
• 英文场景优先英文:若内容本身为英文,直接使用英文提问更经济
分词技术的未来演进,当前Token机制仍有改进空间:
• 语言公平性:中文、日文等高密度字符语言Token消耗高于英文
• 语义理解局限:分词基于统计频率,而非真正理解语义
未来可能朝以下方向发展:
• 多语言均衡分词:优化不同语言的Token消耗公平性
• 语义感知分词:结合上下文理解进行切割
• 动态Token粒度:根据任务类型调整切割策略

总结:Token是AI的“乐高积木”
经过以上解析,Token不再神秘。它本质是AI处理信息的基本单元,模型通过计算Token间关系推测后续内容,生成连贯文本。理解Token后,您能更深入认识:
• 为何模型生成内容像“逐字输出”?——因它按Token顺序生成
• 为何API按使用量计费?——Token数量直接对应计算成本
• 为何不同语言成本不同?——分词方式导致消耗差异
下次与AI对话时,您可以想象:您的每句话被“切配工”分词器切成小块,送给“主厨”大模型烹饪,最终呈现一道道“文本佳肴”。Token,正是这场AI盛宴的基本素材。
———— END ————
灵思极智旗下“极智系列”三款AI智能应用