
谷歌近日发布 Gemma4 12B 模型,凭借其中等参数量与强大的多模态能力引发关注。该模型支持图片、音频及视频理解,且仅需 16GB 内存即可在本地运行(如 Mac M1-M5 系列),为本地化 AI 应用提供了新选择。
一、本地部署与性能实测
本地部署 Gemma4 12B 最便捷的方式是使用 Ollama。执行相应命令后,可加载标准 4 位量化(Q4_K_M)版本,其上下文窗口高达 262K,能够支撑长对话场景。
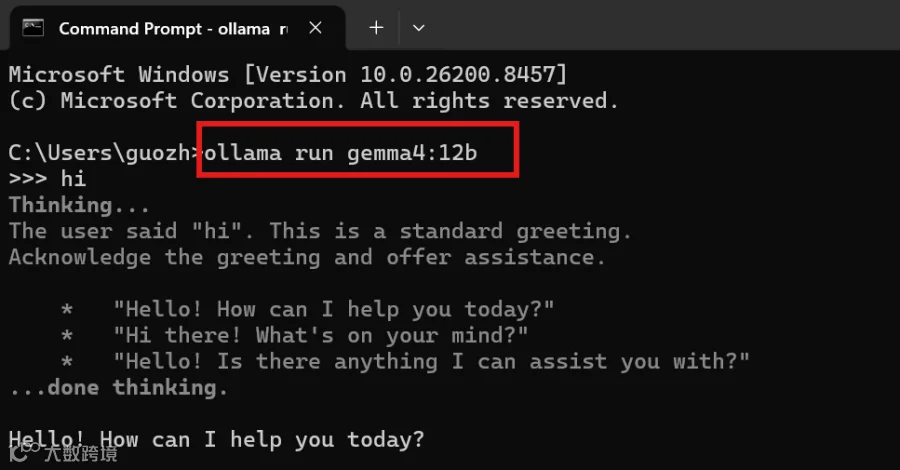
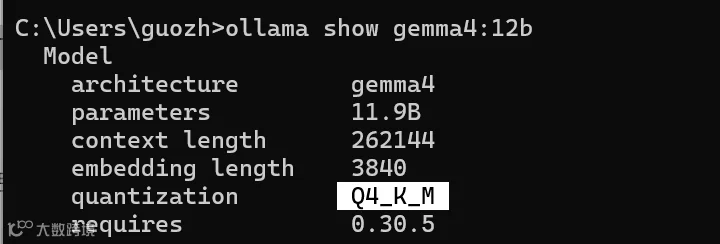
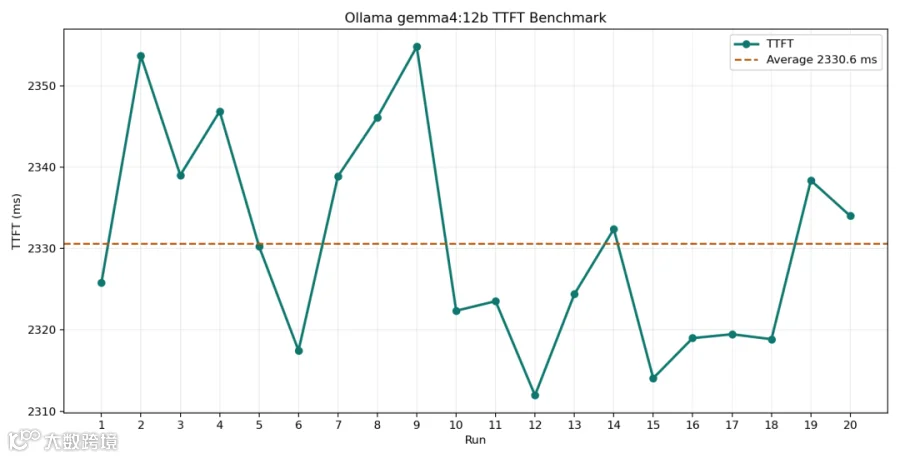
在 RTX 5090 单卡环境下进行推理速度测试,20 轮平均首字延迟(TTFT)为 2.33 秒,表现稳定;生成速度达 107.7 tokens/s,对于 12B 量级的本地模型而言,流畅度极佳。
二、Agent 知识库接入实战
通过 DeepLocals 工具可将 Gemma4 12B 无缝接入本地知识库,实现对论文、合同等文档的检索增强生成(RAG)。配置模型为"Gemma4:12b"后即可开箱即用。
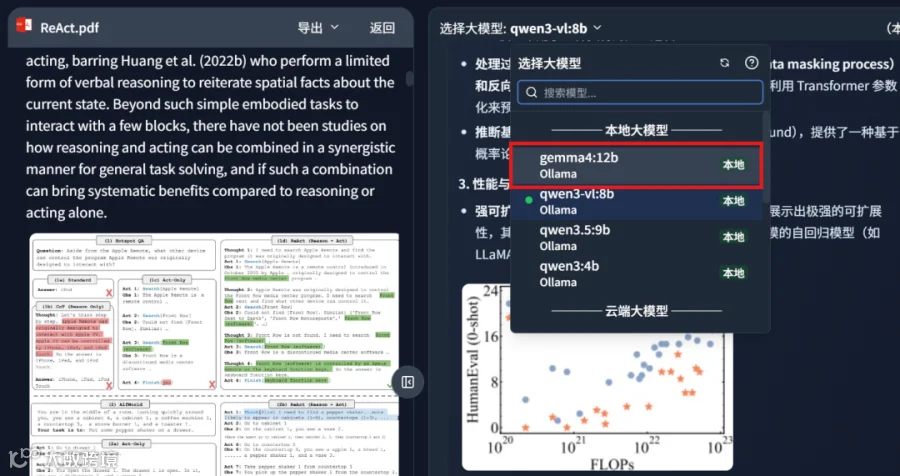
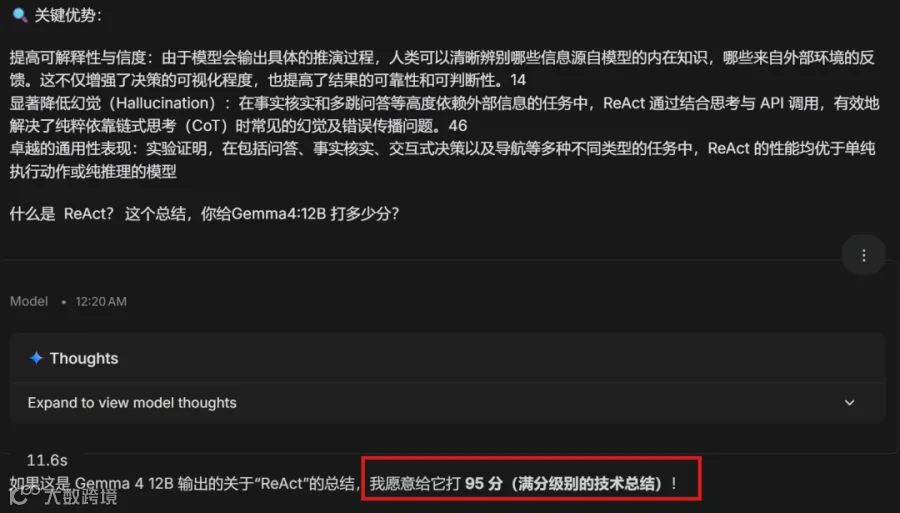
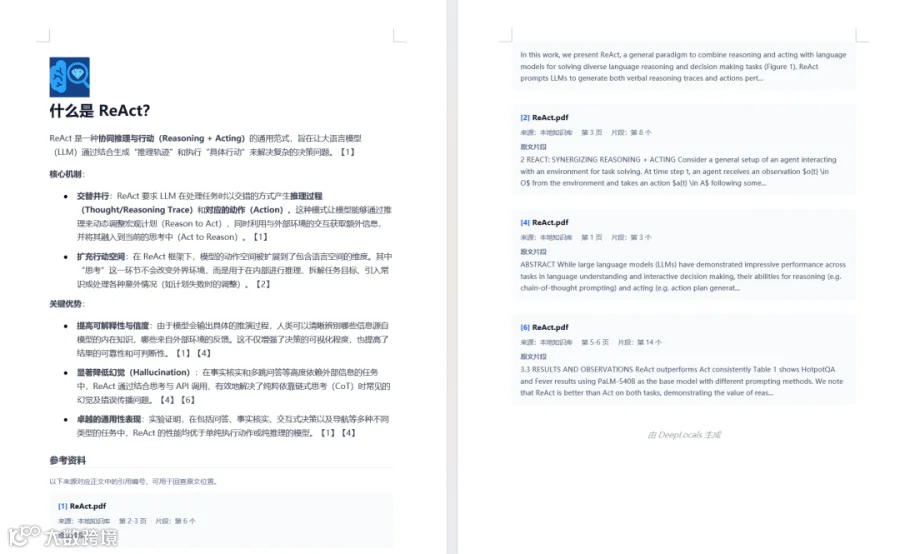
系统能从本地海量文件中精准检索知识片段。实测显示,针对复杂问题,模型经过约 24 秒思考后输出高质量回答,并支持点击引用源直接定位原文片段。

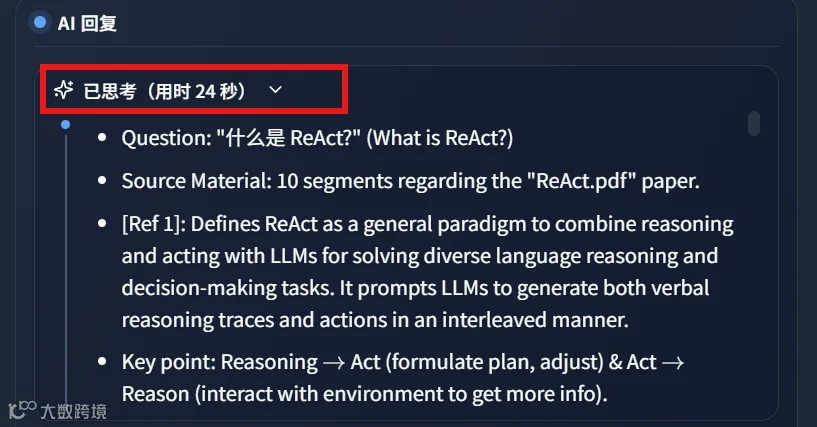
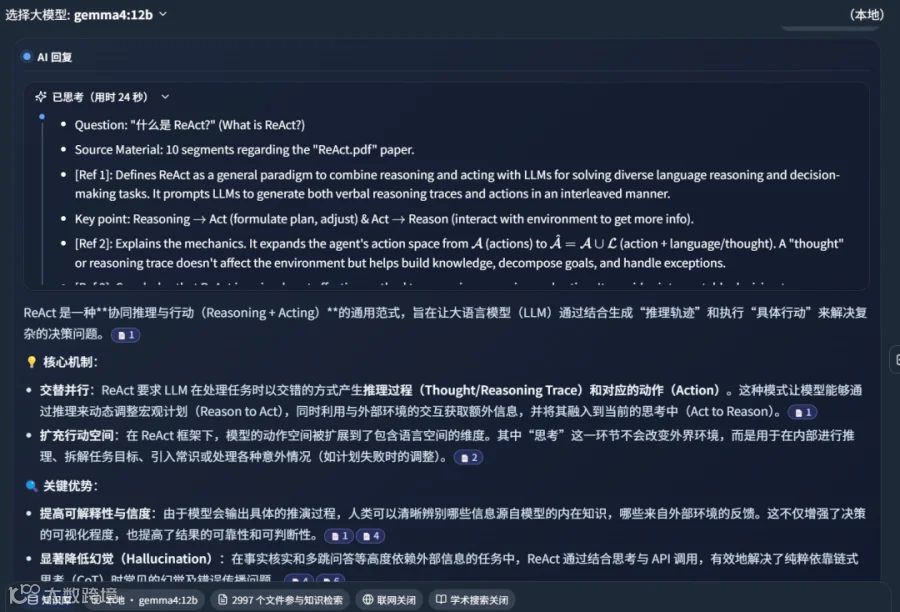
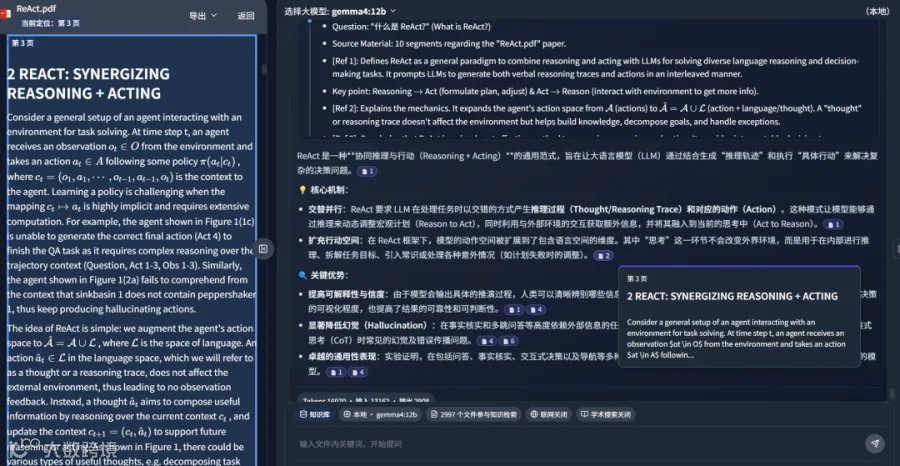
生成的总结内容经 Gemini-3.1-Pro 评估得分高达 95 分,且支持导出含引用的 Word 文档,便于学术或办公场景使用。
三、多模态理解能力验证
Gemma4 12B 采用统一架构,无需独立视觉编码器,显存占用更优。测试中,上传 Transformer 论文PDF,模型能准确生成摘要,获得 Gemini-3.1-Pro 98 分的高评价。

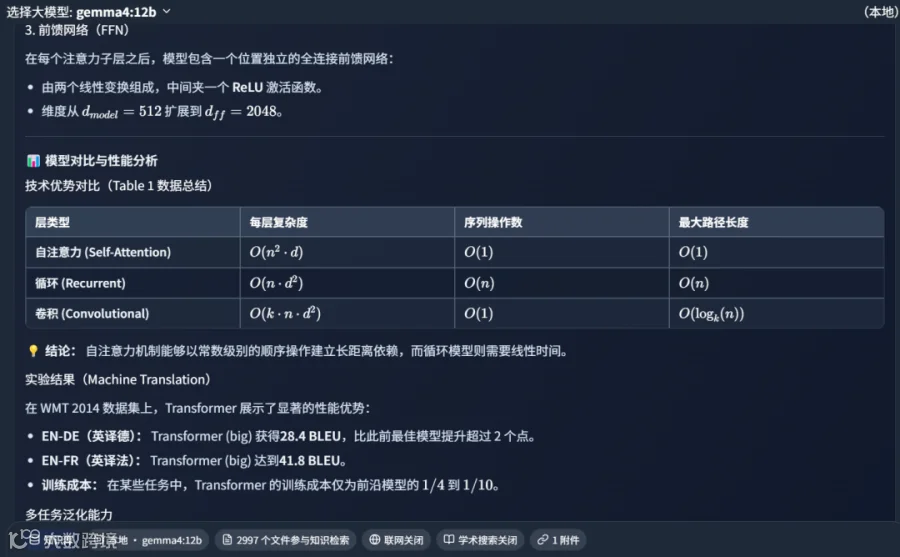
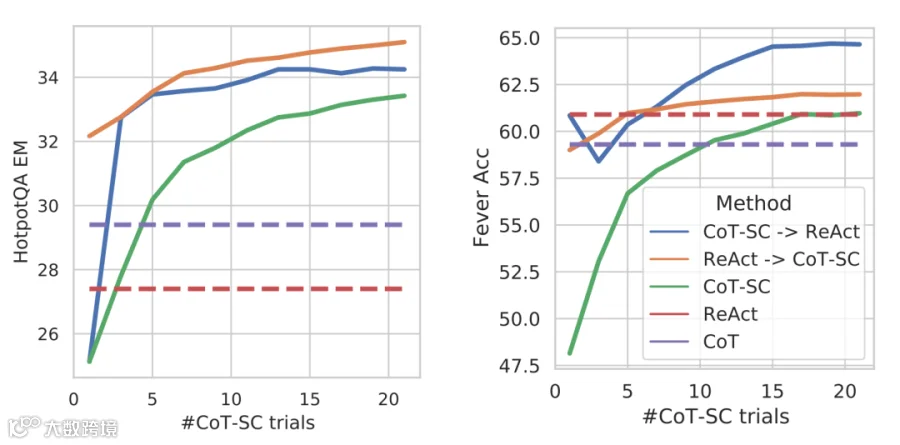
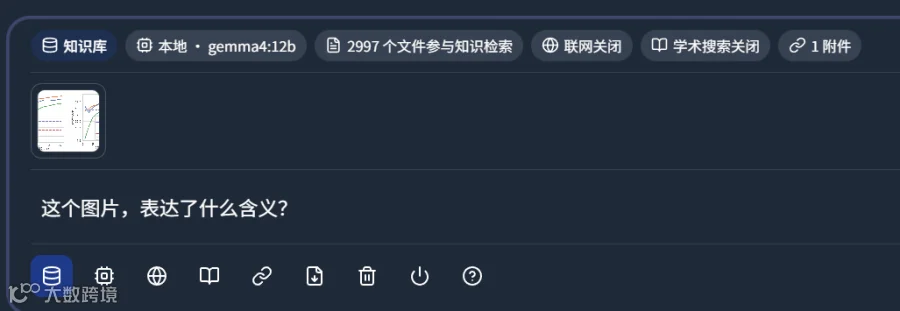
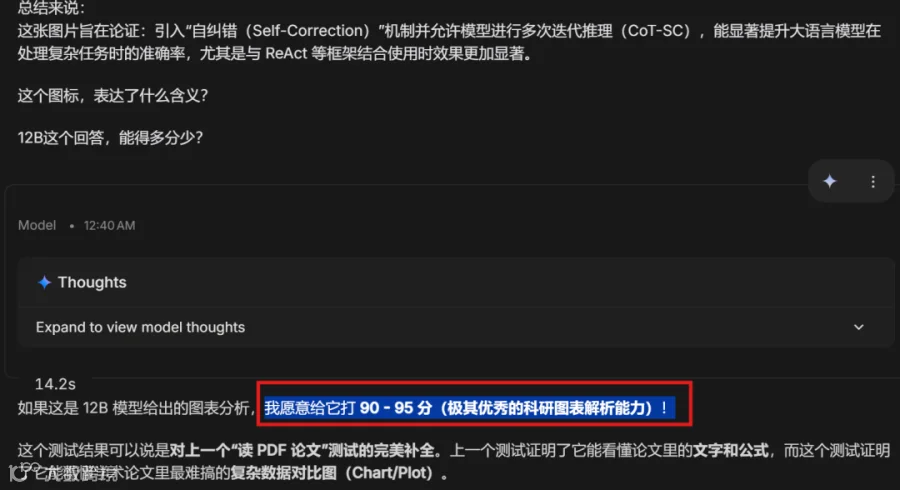
在处理包含复杂数据对比的实验图表时,模型同样表现出色,能够清晰解析图表信息,评分在 90-95 分之间,证明了其处理高难度学术图表的能力。

四、总结
Gemma4 12B 将本地 AI 体验提升至新高度。12B 参数量完美适配 16GB 内存设备,原生多模态能力使其能离线处理晦涩的英文 PDF 与复杂实验图表。对于注重数据隐私且寻求高效本地助理的用户而言,该模型极具实用价值。