
TL;DR
又是一年一度的GTC, 恰逢今年刚好是CUDA 20周年. Jensen整个Keynote对CUDA生态进行了一个回顾, 然后接着谈到了推理时代到来并预测了推理市场的持续性增长. 然后就是最激动人心的硬件发布环节, 发布了Groq 3 LPU 以及整个Rubin系列家族, 有一些新的变化. 接着就是OpenClaw以及Nvidia自己的NemoClaw的发布. 最后谈论了一下Physical AI 和Robotics. 接下来我们将详细分章节回顾整个Keynote. 视频回放可以访问《GTC 2026 Keynote》[1]
1. CUDA 20年
正好今年是CUDA发布20周年.

老黄又从2001年开始回忆可编程的Pixel Shader开始的经历, 这段历史不太熟悉的读者可以参考我以前整理的《GPU架构演化史》 这个专题.
然后开始介绍一些CDUA相关的生态, 第一个例子是RTX相关的DLSS5的demo, DLSS 5 引入了实时神经渲染模型, 能够为像素注入逼真的光照和材质效果. DLSS 5 弥合了渲染与现实之间的鸿沟, 使游戏开发者能够打造出前所未有的逼真计算机图形, 达到了好莱坞级别的视觉特效.

然后继续介绍CuDF 用于处理结构化数据.
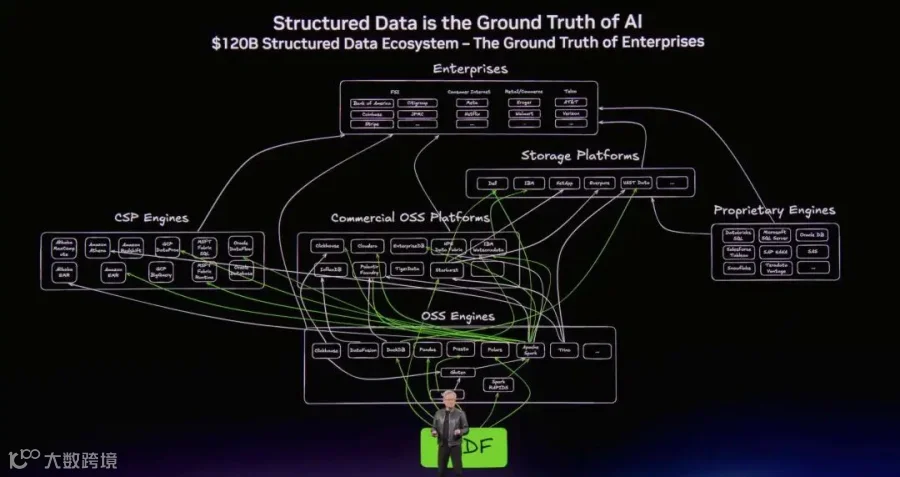
以及cuVS(Vector Search) 处理非结构化数据
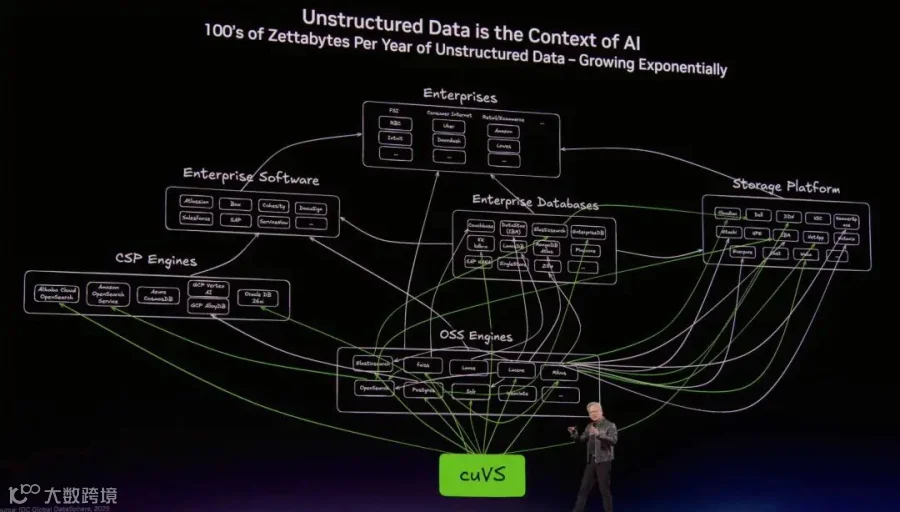
并通过GCP/AWS/Azure/Oracle/CoreWeave以及他们客户的例子来展示整个软件栈, 好基友们必须要雨露均沾的... 下面是每一家Cloud和他们的典型客户.




然后介绍了一些和Dell合作的on-prem的部署:

接下来, 老黄介绍了多个行业的应用, 并且很有趣的对Quant从传统的特征工程到AI模型自动发现特征因子做了很详细的介绍. 不过好像介绍Telco的时候有点卡壳, 难道和AI RAN本身不太顺利有关系?

然后老黄继续介绍他的朋友们, 一系列AI native 公司, 很有趣的是国内模型公司上了3家, Deepseek / Kimi / Qwen, 为啥没有智谱和minimax这两家已经上市的公司呢?

2. 推理时代
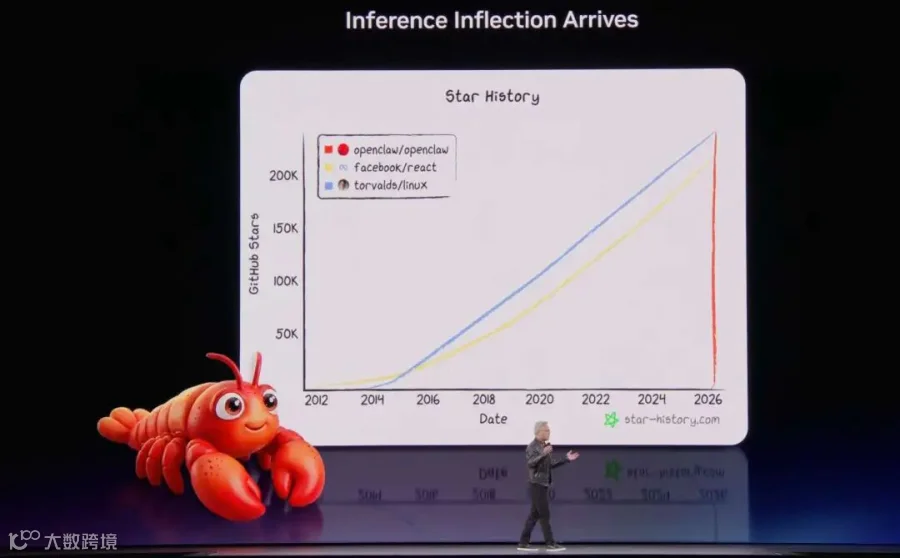
老黄回忆了过去两三年的几个代表时刻, ChatGPT带来的LLM时代, 然后o1带来的LRM时代, 以及Claude Code带来的Agentic时代. 然后Inference Inflection也挺有意思的. 是不是未来还有100X的增长?

也就是在宣告整个推理的时代已经完全到来. 然后老黄讲了一下2026的一些订单的情况, 突然股价就直线拉升了. 但是很快就回落了, 看样子高频程序化交易的影响还是很剧烈的.
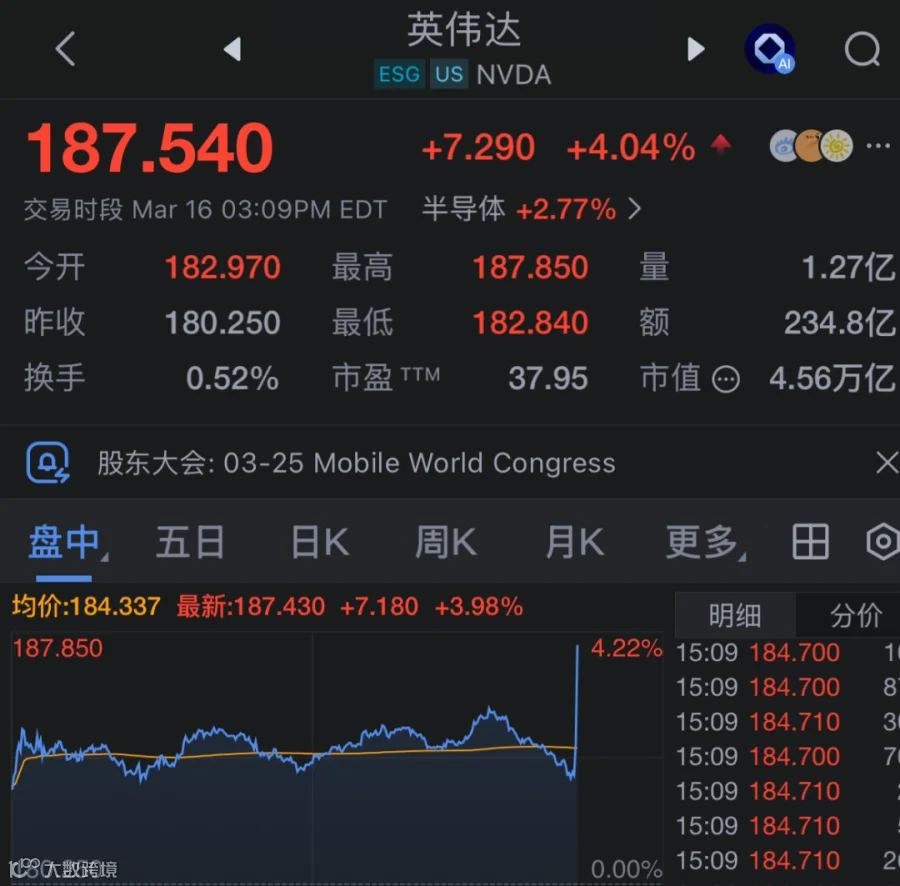
并且预测了整个市场持续性的增长
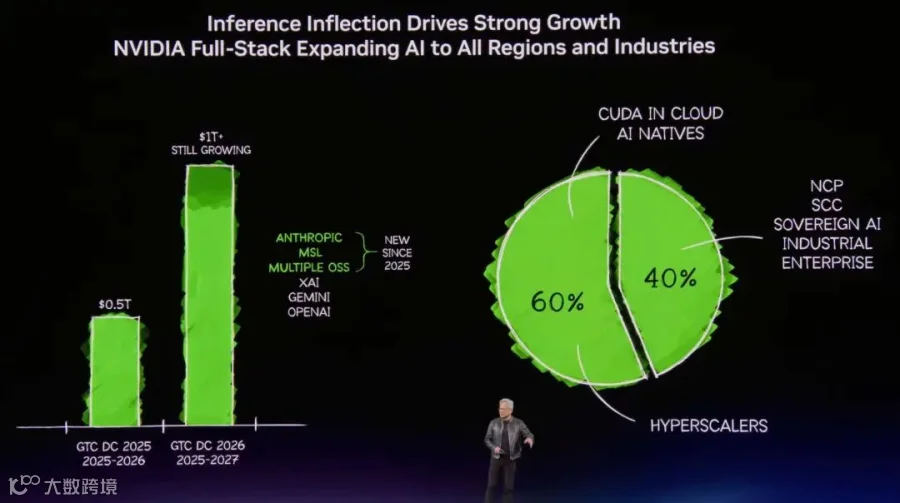
然后开始强调 NVL72 和 nvfp4 这些从Blackwell带来的变化以及对推理的优化. 功耗的降低, 性能的增长和推理成本的快速下降.
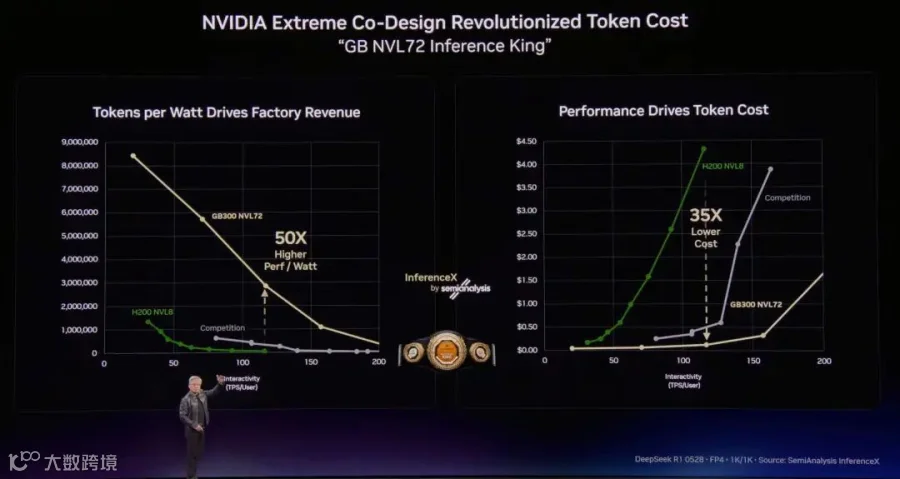
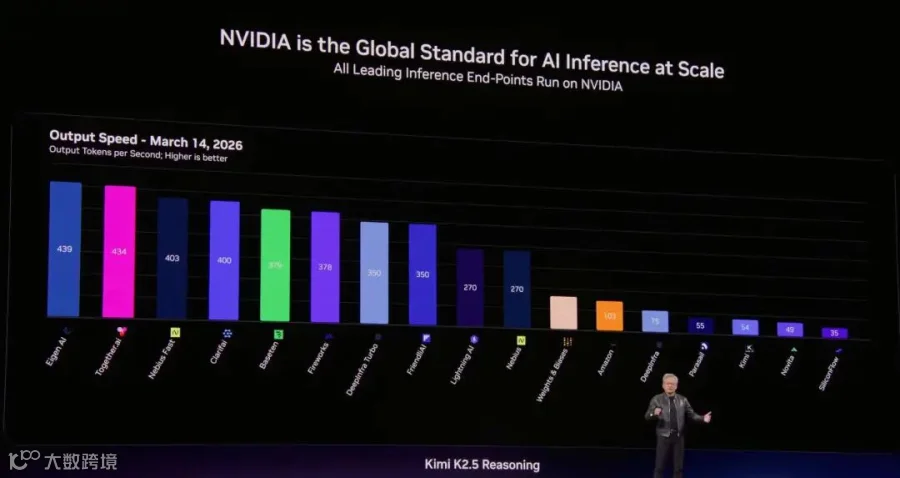
在推理速度上, 下面这图有点不对么? 模型用了Kimi K2.5但是... 最后几名... 额....这有何意味? 证明先进的卡真的没有出口到中国?
然后又再一次强调了AI Factory的概念

3. 硬件
老黄用一段Video从最早的DGX开始介绍, 然后Volta / Ampere / Hopper / Blackwell 回顾过去十年的发展作为这一节的开场. 然后整个Rubin这一代也露出了全貌, Groq 3 LPU成为这次发布的重点.

然后老黄展示了 Groq 3LPU compute Tray / NVL6 Switch Tray / Rubin Compute Tray

关于Groq 3 LPU将在后面详细介绍. 然后是 CX9+Vera构成的BF4 存储服务器 , Vera CPU Tray , CPO交换机

先来谈谈服务器, 原本宣传的是CX9和Grace合封构成的一颗DPU, 但实物展示的却是CX9和独立的Grace芯片. 最近因为存储密度上的需求, 以及Grace PCIe Lane不够的原因, 换成了使用CX9和 Vera CPU搭配构建. 其实这个场景和使用一个普通X86 CPU + CX9 有什么不同呢? 并且Nvidia在存储上的积累还是太少了, 对于DPU如何支撑好存储应用还是有很多东西没搞明白的.
然后是Vera的ComputeTray用于Agentic workload, 单个Vera Compute Tray集成了8颗Vera处理器, 每个处理器88核, 同时支持8通道的LPDDR5x内存, 单个socket支持1.2TB/s的内存带宽. ComputeTray上集成了2块BF4-DPU.
而关于CPO Switch的话题我们将稍后分析.
另一个比较有意思的话题是, 老黄认为基于CableTray和液冷的这套Orben机柜的结构对于快速部署也很有帮助, 因此又提供了一个Ethernet 256的版本, 猜测就是Switch Tray换成以太网交换机, 整个机柜支持32个 Vera ComputeTray, 然后支持256颗CPU连接到整个Rack上. 技术上估计还是使用BF4 DPU, 然后通过CableTray连接, 估计使用了CX8/CX9引入的多平面技术,即一个CX9 800Gbps端口拆分为8个112G端口, 然后连接到8个Switch Tray上. 通过相对成熟的Orben机柜结构(这里前后的图还是不一致的, 这个时候老黄展示的机柜只有2个Switch Tray但是后面的Roadmap那一页展示的是8个), 避免复杂的光纤连线. 也可以降低光模块带来的功耗.
注意, 这个ETH256只是标准的以太网通过CableTray连接的FrontEnd网络
下图左侧是Orben ETH256机柜的结构支持Vera CPU,上下各16个Vera ComputeTray. 右侧是BF4存储的Orben机柜, 应该没有背板的CableTray至少在存储服务器上没看到背板有连接器, 只有供电的接口.
接着继续发布了Rubin Ultra 和 Kyber Rack的Midplane

但是看到Rubin Ultra的DieSize似乎和宣传的不一致, 两块板都属于一个展示版本, 可以看到ComputeTray上有4颗Rubin Ultra 和2颗Vera CPU, 以及4颗CX9和一块BF4的DPU. 并配置了4块NVMe盘的插槽.
然后ComputeTray是竖着放置的, 并连接到Kyber的中背板, 仔细看了一下, 可以放置18个ComputeTray

最后是交换背板, 它也是垂直放置的, 并没有出现正交的无中背板架构

主要原因是在这一代上考虑到原来的CableTray布线距离太长, 而采用中背板结构构建Shuffle线路, 将前面板的18个ComputeTray的Serdes分组连接到后面板的不同插槽内.
然后是Rubin NVL72带来的性能增长以及从电力约束下带来的Revenue的增长, 继续给Rubin带货.
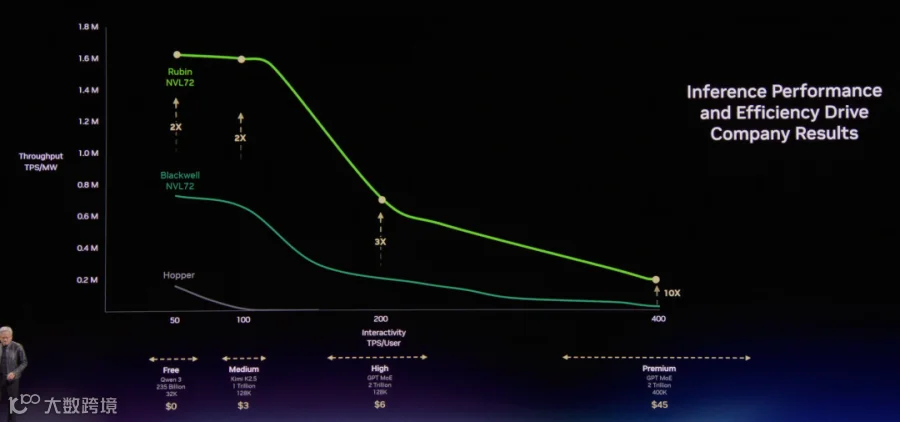
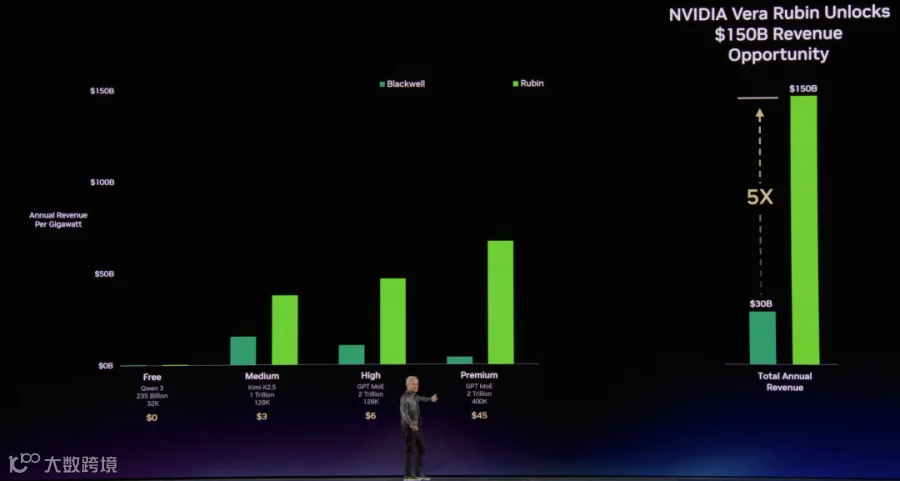
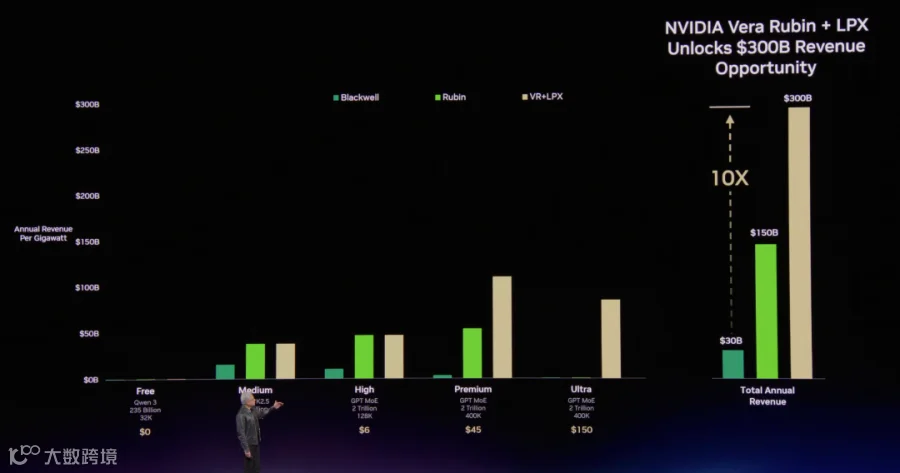
接着从功耗降低以及推理速度的需求, 推导出Groq的收购, 以及基于Groq 3 LPX带来的Revenue的增长, 可以看到同样的功耗下Vera-Rubin + Groq 3 LPX还可以相对Rubin提升1倍的能效.
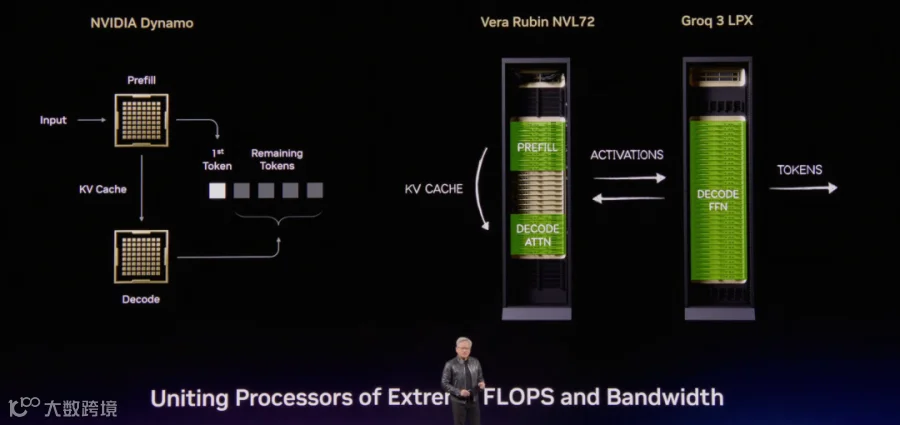
然后是关于Rubin Prefill, Groq 3 Decode的方案. 单颗Groq 3 LPU的SRAM增加到了500MB, 同时带宽增加到了150TB/s

Groq的详细架构分析可以参考《谈谈那个被NV看上值20B的Groq》. 详细分析Prefill和Decode的workload, Prefill是Compute Bound和Memory Capacity Bound, 而Decode是Memory Bandwidth Bound的应用. 因此某种程度上需要对Decode的内存带宽上进一步加大, 单个Groq 3 LPU SRAM容量增加到了500MB, 而第一代为220MB, 带宽也从第一代的80TB/s增加到了150TB/s, . 但是这一代仅支持FP8. 接下来NV会出一款Groq L35来支持nvfp4.
然后老黄对比了Rubin GPU 和8颗Groq 3 LPU构成的ComputeTray, 可以明显看到这种趋势. 在Prefill节点支持更高的算力和更多的内存容量. 而在Decode节点更多的是提升内存带宽.
另外我们注意到原来的Rubin CPX的方案似乎被取消了, 大概猜测是DDR的价格涨的太恐怖了, 而且Rubin CPX的方案1:1配比本来就有不少的问题. 具体分析可以参考《详细分析一下Nvidia Rubin CPX》. 其实我们可以详细分析一下Agentic LLM的workload, 由于Context通常超过200K未来进一步还会到1M, 对于KVCache的搬运需要更大的带宽, 基于PCIe的Rubin CPX可能有一些力不从心.
比较有意思的是, 针对PD分离的同时, 如何使用Groq, 老黄这里画出的是AFD. 继续用Rubin做Attn, 而Groq 3 LPU只做FFN. 其实这里有几个问题经不起推敲的. 首先它把EP的流量跨机柜传输, 用的是什么网络? 如果是ScaleOut, 但是在LPX的ComputeTray上只有一颗BF4. 另一个问题是Groq确定性执行如何支持MoE? 如果Rubin Attn节点算好MoE Gate Index后, 将index写入数据包只发送一份到整个LPX机柜, 然后在机柜内部做dispatch和combine, 跨机柜互连的带宽小了. 然后在Groq内部做一些mask处理不参与计算的Expert? 另一方面从Rubin上dispatch, 然后逐个token直接送入到对应的LPU做FFN, 通过LPU的对外I/O的buffer缓存一部分未计算的token. 算完后再Combine. 这样对于两个机柜的互连带宽要求更高, 似乎又没有互连的ScaleUP, 毕竟两者是不同的协议(LPU C2C和NVLink).
还有一个问题是对于一些超过1T的模型, 单个LPX机柜256颗LPU累计的SRAM容量仅128GB, 似乎也放不下这些专家的参数(当前Groq 3仅支持FP8), 所以整个AFD的方案实际上是经不起推敲的. 不知道NV是如何解决这些问题的.
Groq 3 LPX的ComputeTray结构如下, 可以看到它还是延续了原来的LPU C2C接口并没有采用NVLink, 也没有相应的交换芯片, 可能未来会有向NVLink转换的一个过程.

最后再次展示了一下全家福, 并且透露了Rubin已经点亮了交付给微软在测试了.

然后老黄再一次强调了存储的重要性, 从传统人使用CuDF/CuVS转换到AI使用存储, 并包括新的KVCache的需求, AI对于这些处理的速度要求会更高, 因此对于存储的需求也会更强烈.
接下来谈论了一些Roadmap
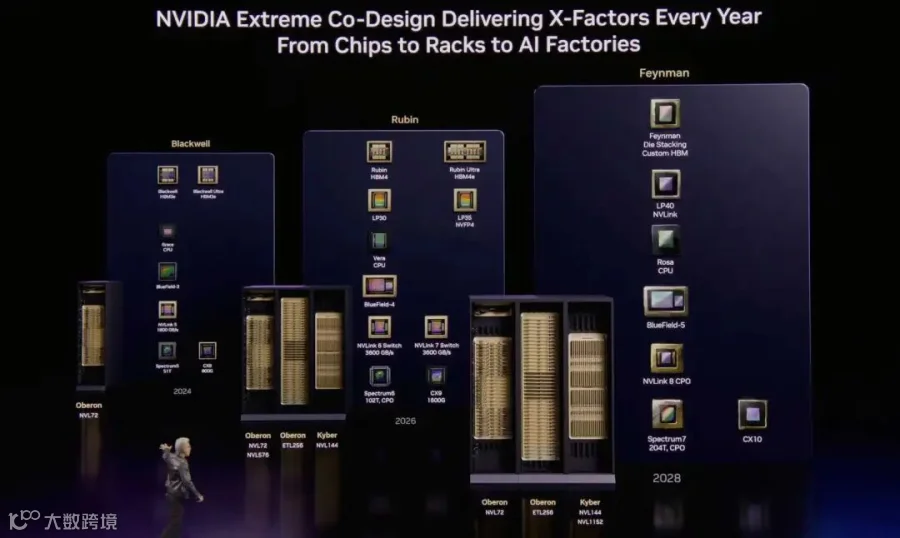
在Rubin这一代, 会很快配合Rubin Ultra推出支持NVFP4的Groq 3.5(LP35), 然后CX9上还是继续在误导, 明明是一颗800Gbps的ASIC非要写成1.6Tbps. 比较大的一个变化是, 老黄还是念念不忘他的NVL576, 在Oberon机框上会将8个机柜并联支持. 不过这样就需要NVLink支持光互连了, 可靠性的问题是如何解决的, 整个故障域加大后整机的MTBF下降是如何处理的, 实际上在工程上还有很多挑战. 然后关于支持ETH256的互连, 再次强调一下, 它只是利用CableTray来连接Vera CPU的, 此时是一个标准的800Gbps Ethernet, 并不是国内常见的ETH-ScaleUP
同样在Kyber这一代ScaleUP上, 也会支持8并柜的互连, 也挺值得期待他们是如何解决光的可靠性问题的, 难道是华为UB几千卡的ScaleUP的压力也传导给老黄了?
然后是关于Feynman这一代, 明确了Feynman采用3D堆叠, 但是并不是堆叠Groq LPU, 而更大程度是在堆叠定制的HBM. 然后这一代的LPU会从LPU C2C切换到NVLink, 同时值得一提的是这一代会全面支持CPO光互连的ScaleUP和ScaleOut. 然后CX10和BF5也被排到了2028年.
关于CPO的判断和我前面的详细分析是基本一致的, 具体可以参考《谈谈光互连的一些问题》
最后针对地球电不够, 也在说正在研究太空中的抗辐射的Vera Rubin架构

4. Agentic Computing
接着老黄也在开始谈论龙虾, 养龙虾开场

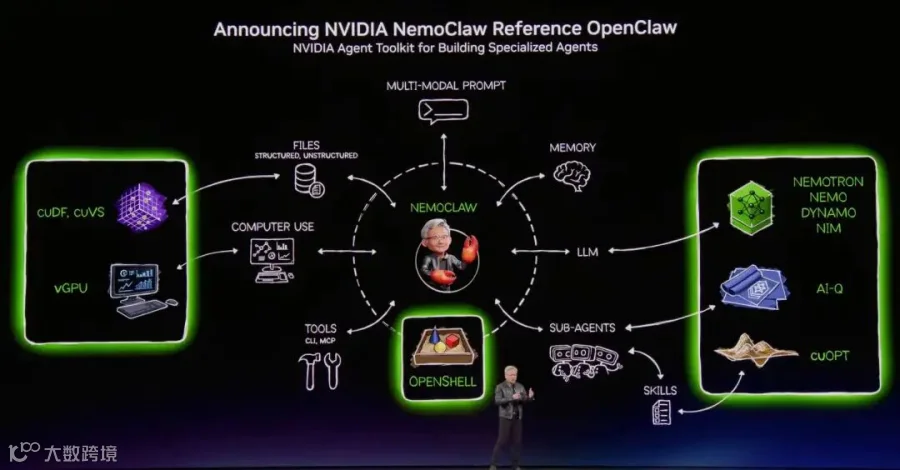
然后开始介绍Agentic Computing, 它和Linux / HTTP / HTML一样带来了大量的变革. 这一点也听献涛(JVS Claw负责人, 阿里云终端智能计算事业部总裁)讲述过, 他作为一个做了二十多年Linux内核的技术老兵, 对OpenClaw的判断非常准确. 并且从OpenClaw发布时他就关注龙虾的安全执行和做原生的交互体验. 并且最近发布了JVS Claw《想安全简洁的养虾吗? 选择JVS Claw吧》. 而我们注意到老黄的判断和NemoClaw的整个思路和JVS Claw基本是一致的. 同样强调安全和易部署的能力, 并且以Agent为中心构建整个生态.
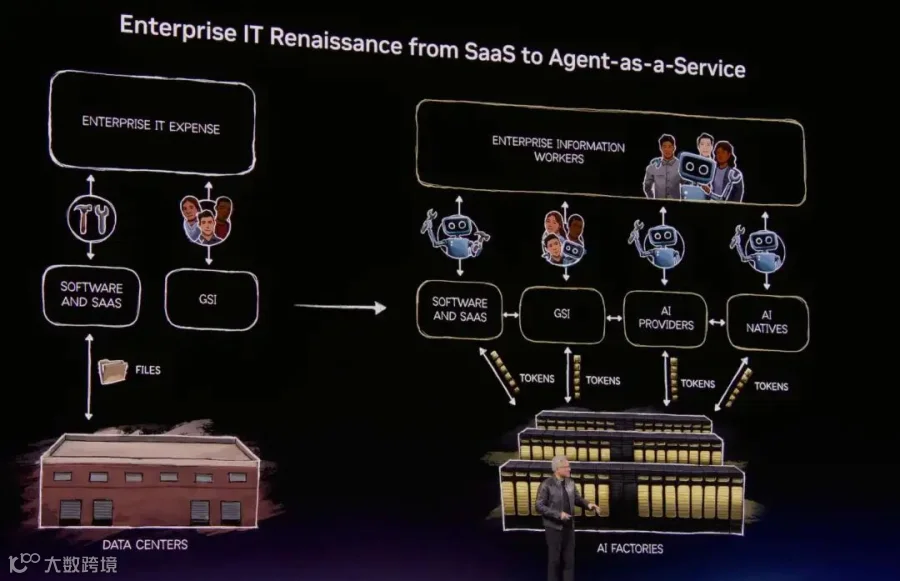
接着老黄宣告了整个企业IT从SaaS到Agent-as-a-Service的转变, 是不是要给SaaS判死刑了?
然后开始介绍了一些Nvidia的开源模型和相应的合作伙伴等.

5. Robotics & Physical AI

自动驾驶方面, BYD/吉利/现代/尼桑等厂家加入Robtaxi, 并且和Uber合作. 然后机器人方面KUKA/FANUC/ABB等厂商, 还有很多机器人/无人机平台等. 然后就是与之配套的整个软硬件平台, 包括仿真/模拟等. 再一次强调了GB300进行训练, RTX6000进行仿真, Thor在终端执行的硬件栈.
最后的彩蛋是结尾的那个总结MV, 歌写的很好听, 歌词也很有趣. 可以值得去听一下.
GTC 2026 Keynote: https://www.youtube.com/watch?v=jw_o0xr8MWU&t=4438s