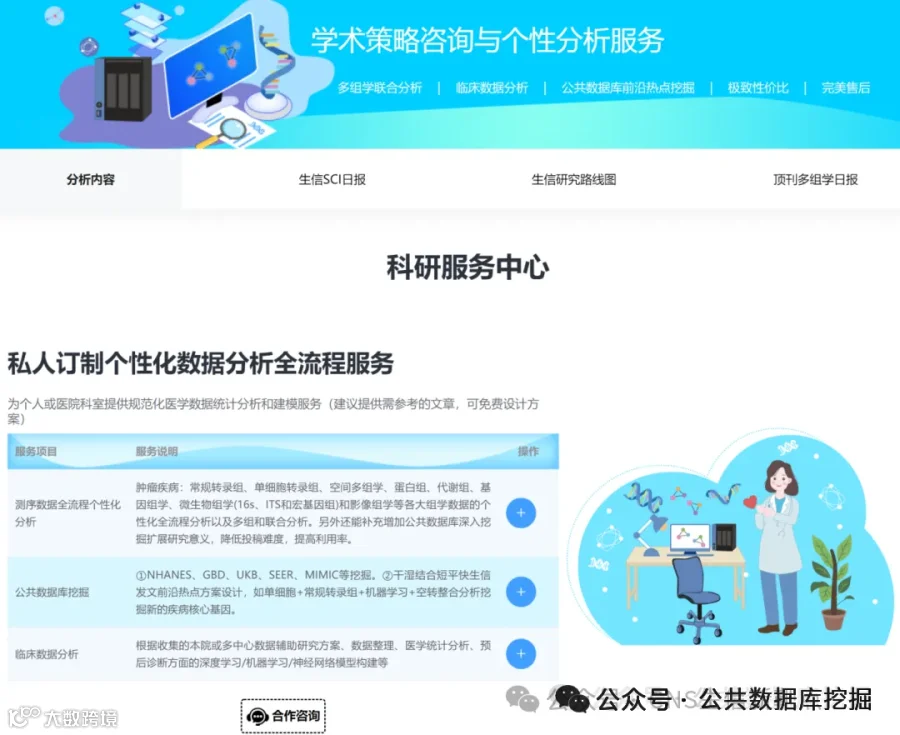
单细胞RNA测序(scRNA-seq)的聚类和注释是解析细胞异质性的关键步骤,但单一聚类分辨率难以同时捕获大群体和稀有亚群,且细胞周期等生物学变异常干扰结果。本研究提出CANTAO(Clustering and Annotation using Transcriptomic Average Overlap),一种基于平均重叠(AO) 的排名加权度量,通过比较各簇差异表达基因的排序相似性来量化簇间关系,并构建层次聚类树以指导合并。在Zhengmix8eq(8种血细胞)和CBMC(CITE-seq)等真实标签数据中,AO在调整兰德指数(ARI)、纯度和簇与真实群体距离上全面优于Pearson、Spearman、Kendall-tau相关系数和欧氏距离(基于表达量或主成分)。应用于小鼠胸腺细胞数据,CANTAO成功区分了双阴性(DN)T细胞的DN1、DN2a、DN2b、DN3a、DN3b等连续发育阶段,并识别出凋亡的DN4/ISP亚群,而细胞周期回归分析会丢失这些关键区分。CANTAO已集成于Scanpy框架,为单细胞聚类参数选择和自动化注释提供了新工具。
今天给大家解读一篇3月发表在《Molecular Systems Biology》上的题目为“CANTAO: guiding clustering and annotation in single-cell RNA sequencing using average overlap.”的文章。本研究针对单细胞RNA测序数据分析中,无监督聚类结果难以与生物学身份准确对应的问题,开发了CANTAO方法。该方法利用平均重叠度量计算聚类间差异表达基因排名的相似性,并据此进行层次聚类,以指导聚类的合并与最终注释。研究首先在已知真实标签的造血细胞数据集上验证了该方法的优越性,随后将其应用于小鼠胸腺细胞数据,成功鉴定并注释了从骨髓多能祖细胞到成熟T细胞的完整发育阶段,证明了其在解析高度同质细胞群体中的实用价值。(请持续关注我们,每天为您解读最新见刊的文献!)想薅生信资料羊毛?直接在对话框回复 “资料”,免费领取干货大礼包!包括数据集、绘图代码、图表复现、思路总结、参考文献……0代码!鼠标点点点即可轻松完成5-10分生信SCI全文复现!
不想做实验,没数据,还想要快速发表文章,没问题的!公共数据库就是我们的数据宝藏!没思路不用担心,作为专业的生信团队,我们很乐意为你们效劳,提供研究路线设计和数据挖掘分析,扫码联系我们吧!



团队成员合影(位于上海陆家嘴中心,可随时预约参观)
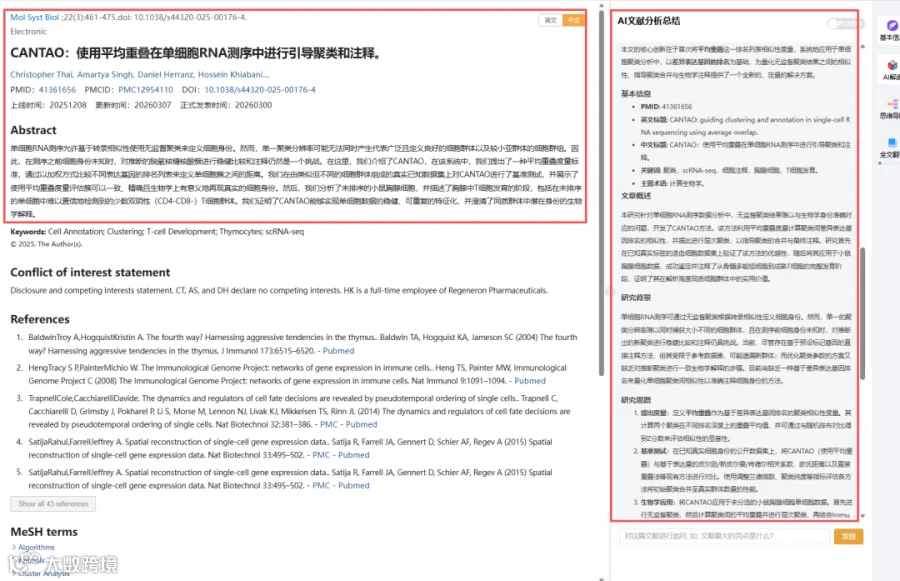
题目:《CANTAO:使用平均重叠在单细胞RNA测序中进行引导聚类和注释》CANTAO: guiding clustering and annotation in single-cell RNA sequencing using average overlap
发表期刊:Molecular Systems Biology
影响因子:7.7
研究背景:
单细胞RNA测序可通过无监督聚类根据转录相似性定义细胞身份。然而,单一的聚类分辨率难以同时捕获大小不同的细胞群体,且在测序前细胞身份未知时,对推断出的新聚类进行稳健比较和注释仍具挑战。当前,尽管存在基于预设标记基因的直接注释方法,但其受限于参考数据集,可能遗漏新群体;而优化聚类参数的方案又缺乏对推断聚类进行一致生物学解释的步骤。目前尚缺乏一种基于差异表达基因排名来量化单细胞聚类间相似性以准确注释细胞身份的方法。
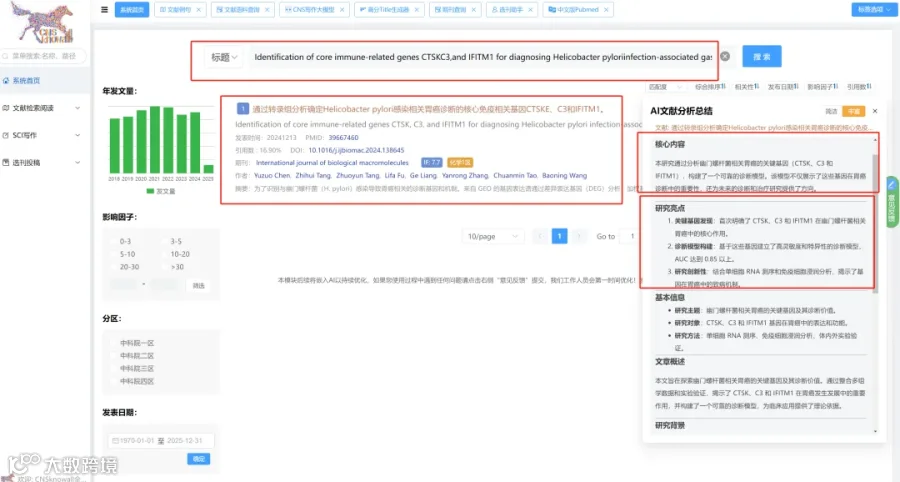
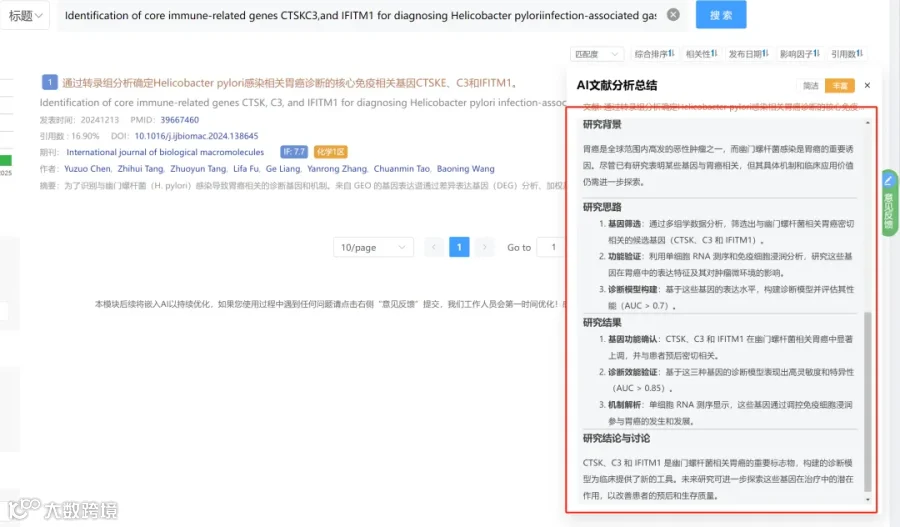
CNSknowall 平台 Pubmed+AI 快速提炼全文要点
研究思路:
- 提出度量
定义平均重叠作为基于差异表达基因排名的聚类相似性度量。其计算两个聚类在不同排名深度上的重叠平均值,并可通过与随机排布对比得到Z分数来评估相似性的显著性。
- 基准测试
在已知真实细胞身份的公开数据集上,将CANTAO(使用平均重叠)与基于表达量的皮尔逊/斯皮尔曼/肯德尔相关系数、欧氏距离以及直接重叠法等现有方法进行对比。使用调整兰德指数、聚类纯度等指标评估各方法将初始聚类合并至真实群体数量的性能。
- 生物学应用
将CANTAO应用于未分选的小鼠胸腺细胞单细胞数据。首先进行无监督聚类,然后计算聚类间的平均重叠并进行层次聚类,再结合Immunological Genome项目的批量测序参考数据,对聚类进行生物学注释,特别是解析T细胞发育早期阶段。
研究亮点:
- 度量特性
平均重叠是一种顶部加权的排名相似性度量,对排名靠前(即最差异表达)基因的差异更为敏感。
- 验证充分
在多个已知真实细胞身份的数据集上进行基准测试,证明其能更准确、一致地识别与真实身份对应的细胞群体。
- 应用突破
成功应用于未分选的小鼠胸腺细胞数据,解析了完整的T细胞发育轨迹,包括传统上难以区分的双阴性细胞亚群。
研究结果:
- 基准测试结果
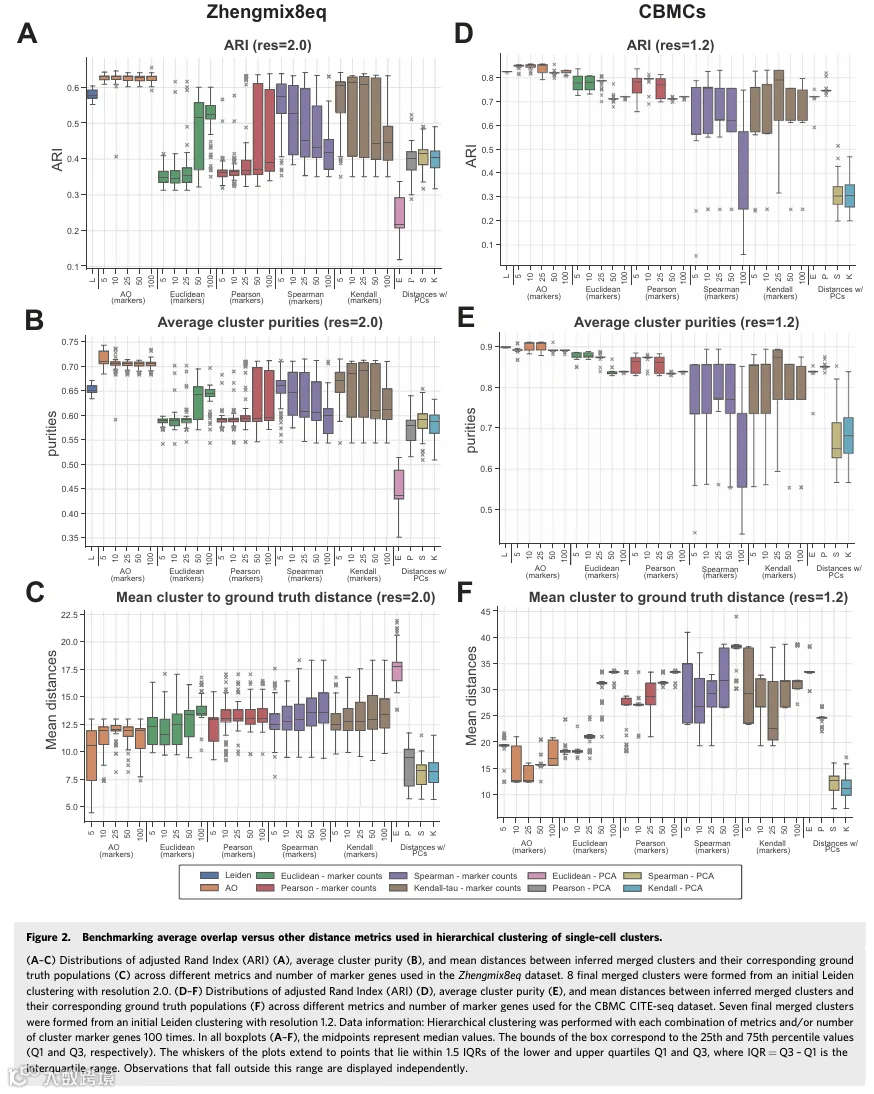
在所有测试数据集和初始聚类分辨率下,基于差异表达基因排名的平均重叠度量在性能上均优于其他基于表达量或主成分的度量。其获得的调整兰德指数最高,聚类纯度最高,且推断群体与真实群体间的转录差异最小。平均重叠的性能波动最小,且使用较少标记基因时即可达到最佳性能。
- 胸腺细胞分析结果
- 细胞周期的影响
基于平均重叠的层次聚类将19个初始聚类按细胞周期阶段(G1、S、G2/M)清晰分组,这表明细胞周期基因是聚类相似性的重要组成部分。
- 发育轨迹解析
通过与参考数据比对,成功将初始聚类注释为T细胞发育的连续阶段,包括:MPP4/DN1、DN2a、DN2b、DN3a、DN3b、DN4/ISP(含一个推断为凋亡的亚群)、ISP、DP、成熟CD4 T细胞、成熟CD8 T细胞,以及自然杀伤细胞和γδ T细胞等小群体。
- 方法对比
正交分析表明,基于表达量的相关度量无法一致地按细胞周期或发育阶段对聚类进行分组。而回归掉细胞周期效应会导致DN2a/b、DN4和ISP等具有增殖特征的群体相互混合,失去分辨力,这反证了细胞周期信号在区分这些发育阶段中的重要性。
研究总结:
- 方法优势
平均重叠通过关注差异表达基因的排名而非表达量,能够更稳健地度量单细胞聚类间的相似性,尤其擅长捕捉高转录相关性细胞群体间的细微差异。其顶部加权的特性使其对高维数据的“维度诅咒”不敏感,性能稳定。
- 生物学洞见
在胸腺细胞发育中,细胞周期信号与谱系标记基因的组合是区分特定阶段(如DN2b、DN4、ISP)的关键特征。默认回归掉细胞周期可能会丢失重要的生物学信息。
- 应用价值
CANTAO提供了一种独立于聚类算法和参数的、定量评估聚类相似性的方法。它能帮助识别由真实生物学变异产生的聚类,并与噪声聚类相区分,对于研究分化轨迹或克隆群体等具有挑战性的生物学场景具有广泛适用性。
- 工具提供
研究团队已将CANTAO实现为Python软件包,可与Scanpy分析框架无缝集成。
结果译文:
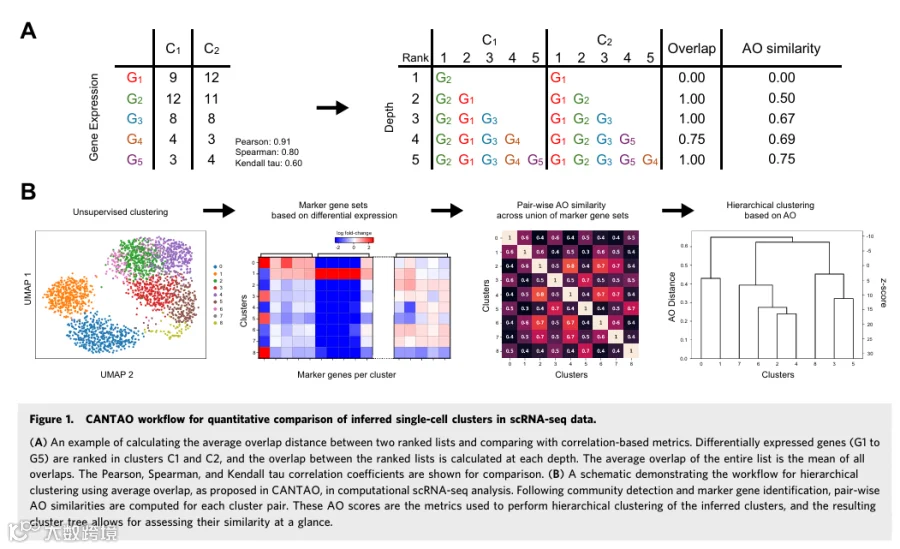
为了比较从无监督社区检测算法获得的单细胞簇,我们首先将每个簇的标志基因集定义为相对于其他细胞最差异表达的基因。然后,我们根据差异表达的显著性对每个集中的基因进行排序,获得簇标志基因,并假设共享具有相似排名的标志基因的簇更可能具有相似的细胞身份和/或状态。
为了验证这一假设,我们提出使用基于名为平均重叠(AO)的排名度量(Webber et al, 2010)设计的CANTAO,这是一种排名列表相似性的顶部加权度量。在标志基因集的背景下,AO将差异表达最显著的基因排名中的差异比列表中排名较低的基因权重更高。AO定义为两个排名列表在列表的不同深度处计算的重叠的平均值(图1A)。AO距离范围从0到1,从完全不相似到完全相同。当在随机打乱的列表上计算时,AO紧密遵循以中点AO距离0.5为中心的正态分布(附录图S1)。该分布通过定义AO z-分数和计算两个标志基因集排名相似性的似然,为分配AO距离的显著性提供了一种统计方法。使用这些z-统计量,包含相同基因的随机打乱的标志集将平均具有0的AO z-分数,而相似排名的集将具有越来越正的AO z-分数。相反,随着标志基因集变得越不相似,AO z-分数变小,并最终变得越负。
我们在CANTAO中提出的工作流程涉及使用AO作为基础距离,用于计算由Louvain、Leiden或其他用于scRNA-seq分析的常见聚类算法推断出的簇的层次聚类。一旦获得簇标志基因集,将它们合并成一个单一集,并跨这个全局标志基因集使用排名来计算成对AO距离,这反过来生成一个可视化簇相似性的树。这个最终树用于量化高度相似的簇,其中AO z-分数指示簇对可能共享相同细胞身份的可能性(图1B)。
为了评估AO在量化scRNA-seq分析中推断簇之间差异的性能,我们在细胞身份通过独立于RNA测量的实验方法已知的数据集中对其性能进行了基准测试。我们使用了一个预分选的血细胞群体数据集,称为Zhengmix8eq(Duo et al, 2018; Zheng et al, 2017)。我们在具有高度异质性、良好分离群体(如B细胞和单核细胞)的完整数据集上,以及在仅由T细胞组成的更同质性群体的子集上进行了基准测试。此外,我们使用了一个脐带血单核细胞的CITE-seq数据集(CBMCs)(Stoeckius et al, 2017),其中真实细胞身份通过表面蛋白谱获得(图EV1A-C)。
我们在每个数据集中通过首先以不同分辨率(Zhengmix8eq为1.0-2.0,T细胞子集为1.5-2.0,CBMCs为0.6-1.2)使用Leiden算法对细胞进行聚类,来对AO进行基准测试。我们使用在不同数量的顶部标志基因(每个簇5、10、25、100、200和500个)上获得的差异表达基因的并集来计算成对AO距离,并对得到的Leiden簇进行层次聚类。使用这些树,我们迭代地合并具有最高AO z-分数的簇(图1B),直到剩余簇的数量与真实标签的数量匹配。
为了将AO与其他用于评估单细胞簇之间相似性的度量进行基准比较,我们使用标志基因的归一化表达计数,利用成对Pearson、Spearman和Kendall-Tau相关性以及欧氏距离执行了相同的层次聚类。我们还对应用于前50个主成分(总结了所有基因的表达)的这些相同度量进行了基准测试。此外,为了提供一个比较基线,我们计算了使用簇顶部标志基因集的直接重叠以及没有任何细化的Leiden聚类本身的性能,其中分辨率参数被高度调整以达到精确的真实群体数量(图EV1A-C)。我们每次使用一个新的随机种子启动Leiden算法,将这些分析各重复100次。
对于性能评估,我们首先使用调整兰德指数(ARI)(图2A、D)、调整互信息(AMI)和Fowlkes-Mallows评分(FMS)(附录图S2-S4)量化了推导出的细胞群体与真实身份之间的一致性。在所有测试的数据集和初始Leiden分辨率中,应用于簇标志基因的AO度量相比其他度量(无论是基于表达计数还是主成分计算的)都具有最佳性能(图2A、D和图EV2A-C;附录图S2-S6)。特别地,使用较少数量标志基因时达到了最佳性能(图EV3A-C)。相比之下,除了应用于Zhengmix8eq T细胞子集的Pearson相关性(图EV2B、C)外,所有其他使用主成分的应用表现最差。在所有数据集中,AO度量在不同起始Leiden分辨率的基准测试迭代中也显示出最小的性能方差。事实上,AO度量的表现与从固定的、高度优化的Leiden聚类(产生与真实群体相同数量的簇)获得的基线非常相似。
其次,我们验证了每个推断簇理想情况下应包含单一真实细胞身份,且其基因表达谱与其相应的多数真实群体高度相似的假设。为此,我们计算了簇纯度(定义为每个簇包含单一真实标签的程度),并计算了簇与其相应的真实群体之间平均基因表达的差异。同样,在所有测试的数据集和分辨率中,使用基于AO的树时,平均簇纯度最高,转录差异最小(图2B、C、E、F和图EV2A-C;附录图S5和S6)。正如预期,当每个簇包含少于25个标志基因时,直接重叠簇标志基因集在所有数据集中的表现极差(附录图S7)。在这些情况下,不相似的细胞群体不太可能共享标志基因。相反,当每个簇包含超过100个标志基因时,直接重叠和AO在所有数据集中显示出相似的捕获真实细胞身份的性能。
为了说明使用AO z-分数解释AO相似性显著性的用途,我们展示了使用每个群体的前25个标志基因,在先前基准测试的分辨率1.0下对Zhengmix8eq数据集进行Leiden聚类后,为真实群体和聚类计算的成对AO z-分数(图EV4A、B)。在最不相似的细胞类型(如B细胞、单核细胞和自然杀伤细胞)之间的成对AO z-分数对应于小值或负值。相比之下,高度相似的T细胞群体的成对AO z-分数为正,范围从5.4到14.7个标准差(图EV4C、D)。正如预期,在高分辨率聚类中,高度相似的细胞群体可能分裂成多个组,相应的成对AO z-分数变得非常大,表明更大的AO z-分数始终指向更相似的细胞身份。
总之,AO基于标志基因的排名稳健且可重复地测量单细胞簇之间的相似性,并在识别和表征多样化造血细胞群体中存在群体方面显著优于基于相关性和欧氏距离的度量。
胸腺中T细胞发育的特定阶段已通过单细胞转录组研究得到表征,从双阴性(DN)群体DN1-DN4开始,进展到未成熟单阳性(ISP)和双阳性(DP),最终成为成熟的CD4和CD8 T细胞。虽然胸腺中的T细胞发育轨迹已在正常和疾病状态下部分解析,但使用单细胞方法表征双阴性细胞亚群一直特别具有挑战性,特别是在没有预先细胞分选的情况下测量总胸腺细胞时,导致将所有DN亚群归为一组,而无法具体区分DN1-DN4状态(Belver et al, 2019; Oh et al, 2023a; Park et al, 2020; Totton et al, 2021)。
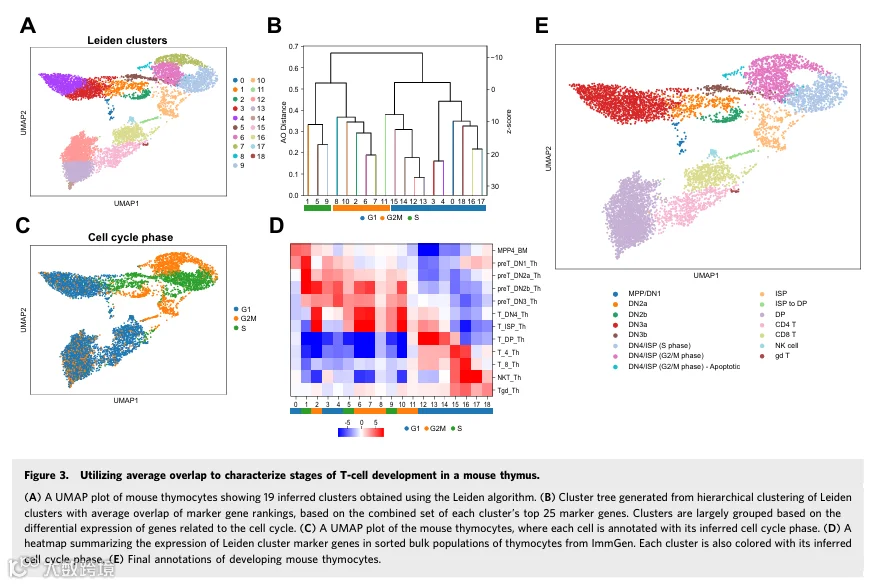
为了应对这一挑战并展示AO度量在阐明胸腺细胞群体之间关系中的实用性,我们使用CANTAO分析了先前发表的小鼠胸腺细胞单细胞转录组数据(Totton et al, 2021)。我们在默认Leiden分辨率1.0下获得了19个单细胞簇(图3A),并验证了高AO相似性的T细胞簇对应于具有相似身份和状态的细胞群体的假设(图3B、C;附录图S8)。然后,我们使用每对簇之间标志基因排名的成对AO距离进行层次聚类。我们利用作为免疫基因组计划一部分的MyGeneSet工具来指导对无监督簇的T细胞身份注释,并使用复合z-分数将每个簇的前50个标志基因的表达映射到12个分选的小鼠胸腺细胞群体上(图3D)。该分析将19个de novo单细胞簇的表达谱与ImmGen细胞群体中的MPP4、DN1、DN2a、DN2b、DN3、DN4、ISP、DP、成熟CD4和CD8、自然杀伤以及γδ T细胞联系起来。
多个单细胞簇中的标志基因包括与细胞周期阶段相关的基因。基于标志基因集AO的层次聚类识别出不同的单细胞簇组;因此,我们假设由AO量化的差异表达基因排名的相似性将根据细胞周期阶段对簇进行分组。我们通过基于已知细胞周期基因的表达对每个细胞进行评分并预测其细胞周期阶段来验证这一假设(图3B)。我们发现簇1、5和9富集了S期的细胞,而簇2、6、7、8、10和11富集了G2/M期的细胞(图3C)。这些簇组在其标志基因集中也显示出非常高的AO相似性,S期中的簇1、5和9对应的AO z-分数在11.5至19.5之间。同时,处于G2/M期的簇2、6、7、8、10和11的AO z-分数范围从10.0到23.1(附录图S8)。其余簇富集了G1期的细胞,分为两组:簇0、3、4、16、17、18以及簇12、13、14、15(图3C)。这些与细胞周期相关的标志基因也在多个ImmGen bulk群体中高表达,包括DN2b、DN4和ISP群体(图3D)。这些结果表明,从AO聚类中出现的簇分组反映了细胞周期特征,指向涉及快速扩增和增殖的T细胞发育阶段,例如T谱系定型和β-选择后发生的阶段。
使用MyGeneSet和ImmGen分选群体的注释,我们发现最早的胸腺祖细胞(MPP4和DN1细胞)最强映射到簇0,其标志基因在任何其他ImmGen胸腺群体中均未显示显著表达。同时,根据AO,簇0未显示出与任何其他簇的高度相似性;因此,我们将簇0注释为多能祖细胞和DN1细胞的混合物。
簇1强烈对应DN2a群体,而簇2根据其标志基因在DN2a/b和早期祖细胞群体中的特异性表达被推断为DN2b细胞。簇2的标志基因也在增殖的DN4和ISP群体中高表达,源于与已知细胞周期基因的36%重叠,包括Hmmr和Nusap1。
簇3和4的标志基因在DN3群体中高表达,并显示出显著的AO相似性(z-分数=25.3)。此外,簇5的标志基因在DN3细胞中显示相对较高的表达。为了将这些细胞进一步表征为DN3a和DN3b群体,我们针对纯化野生型DN3a和3b细胞中上调的基因对簇3、4和5中的细胞进行评分(Vogel et al, 2016)。虽然簇4与DN3a高度相关,簇3与两个阶段均适度相关,但处于细胞周期S期的簇5显示出与DN3b细胞的相似性,共同表明细胞从DN3a向DN3b状态的转变(附录图S9)。因此,我们将簇3和4合并形成DN3a群体,并将簇5注释为DN3b群体。
簇6、7、8和9强烈映射到ImmGen DN4和ISP群体。虽然簇9被区分为处于细胞周期S期的DN4/ISP细胞,但簇6、7和8根据它们的成对AO以及与细胞周期G2/M期的关联而聚集在一起。值得注意的是簇8,其包含的细胞对一组特定基因的表达较低,这些基因在任何其他簇中均未表达(附录图S10)。与簇6和7中的细胞相比,簇8中的细胞显示出mt-Co1、mt-Co2、mt-Co3和其他线粒体基因的上调。事实上,线粒体基因平均占该簇表达转录本的7.8%,表明簇8的一部分刚好低于我们在分析开始时用于过滤低质量细胞的12%线粒体表达阈值。综上所述,我们将簇8解释为代表凋亡的DN4/ISP细胞(附录图S11)。
簇10显示出与ImmGen ISP的最高对应性,而簇11根据其标志基因在晚期发育T细胞中的表达被推断为ISP和DP阶段之间的中间群体(附录图S10)。簇12、13和14被鉴定为更大DP群体的一部分,因为每个簇都强烈映射到ImmGen DP细胞,并显示出所有簇中最高的AO相似性(z-分数范围:24.1-31.1)。T细胞发育的成熟阶段由簇15中的单阳性CD4和簇16中的单阳性CD8 T细胞代表。最后,簇17和18分别被分配给较小组的自然杀伤细胞和γδ T细胞。因此,通过使用CANTAO和ImmGen分选群体中的标志基因表达,我们能够特异性地注释胸腺中T细胞发育的阶段,尤其是双阴性发育的中间阶段(图3E)。
最后,我们探索使用正交方法表征我们数据中T细胞发育的阶段。这些分析是在原始Leiden聚类之后进行的。首先,我们询问伪时间推断是否能恢复这些发育中T细胞的细胞身份,并使用以簇0为起点的扩散伪时间(Haghverdi et al, 2016)。推断的轨迹与我们注释的发育阶段相匹配,并支持簇6和7中的细胞相对于簇2中的细胞具有更晚的发育轨迹;因此,尽管处于相同的细胞周期阶段,仍部分区分了DN2b与DN4/ISP细胞(附录图S12A)。然而,当选择簇2作为分析的起点时,这种模式不成立(附录图S12B)。簇6和7中的细胞被赋予了与所选簇2相同的起始伪时间值0,表明伪时间计算可能被强烈的细胞周期特征所混淆。
其次,我们询问任何先前基准测试的度量(即Pearson、Spearman和Kendall-Tau相关性或欧氏距离)应用于标志基因的表达计数是否能推断T细胞相似性。该分析表明,得到的层次聚类树未能一致地基于细胞周期阶段或T细胞发育阶段对单细胞簇进行分组(附录图S13),突出了AO通过使用差异表达基因的排名而非其计数来推断生物学意义关系的优势,尤其是在高度相似细胞的背景下。最后,我们使用singleR工具(Aran et al, 2019)对每个单细胞进行了自动注释,以ImmGen中分选的小鼠胸腺细胞bulk RNA-seq群体作为注释参考(附录图S14)。这些算法分配的标签与CANTAO的无监督方法紧密对齐,并确认了基于AO的聚类及后续注释的准确性;然而,它们缺乏解析对胸腺细胞发育特定阶段至关重要的细胞周期特征的分辨率。
鉴于细胞周期在胸腺发育中的突出作用,我们测试了回归掉细胞周期效应是否会影响聚类注释和推断。正如预期,虽然de novo Leiden聚类能够识别处于细胞周期G1期的群体,但之前被鉴定处于细胞周期不同阶段的DN2、DN4和ISP细胞被混合在一起,无法被推断为单独的群体(图EV5A-C)。当我们将原始注释(包括细胞周期)或singleR参考注释叠加在由回归后的基因表达计数产生的UMAP上时,这种效应可以很容易地看到(图EV5D、E)。回归细胞周期导致DN2a/b群体之间的分离丢失,以及DN3b与DN4和ISP群体的分离不再清晰。
总体而言,我们对真实标签造血群体以及未分选小鼠胸腺细胞的扩展分析表明,AO可以准确地指导高度同质性细胞群体的聚类和注释,并帮助表征胸腺中T细胞发育的轨迹,包括检测难以捉摸的双阴性(CD4-CD8-)细胞。我们已在Python中实现CANTAO,并设计了一个包在Scanpy框架内工作,以便无缝集成到单细胞分析工作流中。
更多结果和补充图表:doi:10.1038/s44320-025-00176-4
长按二维码关注我们,用最短的时间和最高的效率学习更多数据分析方法!
扫描上方二维码或登录平台官网后添加CNSknowall客服微信咨询!官网地址:
https://cnsknowall.com
CNSknowall:24年最新问世的遥遥领先的科研数据(0代码生信+统计学)分析平台,同时含有机制图模块+汉化版Pubmed融合Deepseek高效筛选目标文献+SCI文献例句/语料检索模块+OPenAI官方GPT接口,>500款CNS级别图表皆可一秒内一键出图,登录即秒变数据分析大神,体验前所未有的便捷数据分析之旅,开启科研天骄之路!
可向下滑动批阅!