非整倍体(aneuploidy)是癌症的普遍特征,但其导致的数百个基因剂量改变如何被细胞“缓冲”以维持蛋白质稳态,机制尚不明确。本研究创新性地提出了“缓冲比”(Buffering Ratio)指标,基于DepMap CCLE、ProCan、CPTAC等公共数据库中的拷贝数、转录组和蛋白质组数据,对癌细胞系和肿瘤样本中每个基因的剂量补偿程度进行了单样本精度的量化。结果显示,38-53%的蛋白质在拷贝数变异时表现出显著缓冲。通过整合35种生化与遗传特征,构建多因素机器学习模型(XGBoost、随机森林、SVM等),预测缓冲与线性扩增的AUC最高达0.85。SHAP特征重要性分析表明,高基因依赖性(essentiality)、参与多个蛋白复合物是缓冲的最强预测因子,而随机等位基因表达和转录因子数量则预测线性扩增。进一步,高缓冲细胞下调CCT/TRiC分子伴侣复合物、上调整合素和ECM通路,缓解蛋白毒性应激,但同时也导致对HSP和CHK抑制剂等药物的耐药性增强。该研究为理解非整倍体癌细胞适应性及靶向治疗提供了新思路。
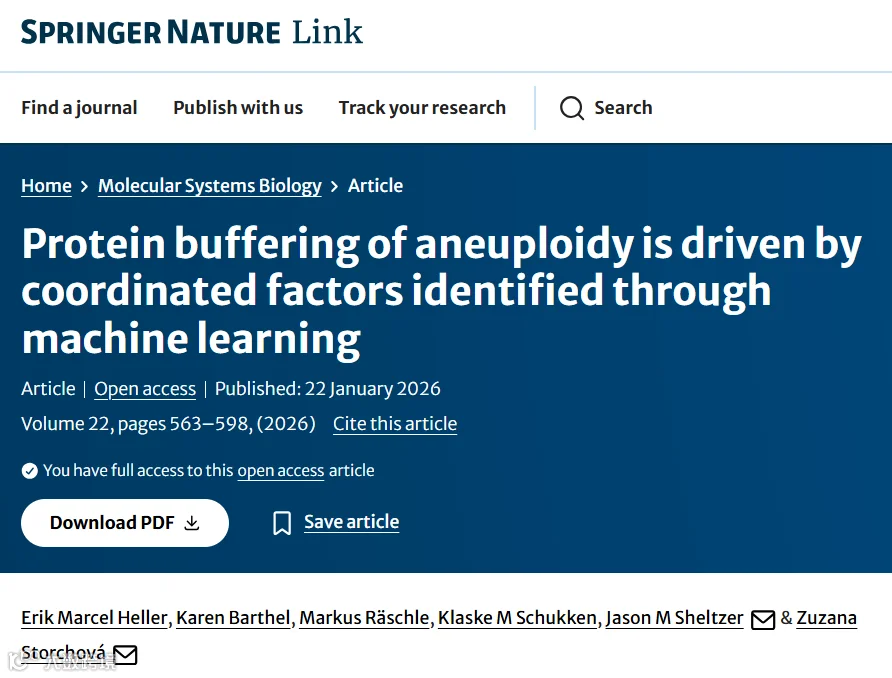
今天给大家解读一篇4月发表在《Molecular Systems Biology》上的题目为“Protein buffering of aneuploidy is driven by coordinated factors identified through machine learning.”的文章。该文章系统阐述了在非整倍体癌细胞中,蛋白质丰度如何被缓冲以回到接近二倍体的水平。研究通过开发新的定量指标“缓冲比”,发现缓冲现象普遍存在但程度各异。利用多因素机器学习模型,研究识别了驱动缓冲的关键因素(如基因必需性、参与蛋白复合物)。进一步分析表明,高缓冲能力与降低的蛋白毒性应激和增强的耐药性相关,而低缓冲细胞则存在特定的脆弱性,可用于治疗干预。(请持续关注我们,每天为您解读最新见刊的文献!)想薅生信资料羊毛?直接在对话框回复 “资料”,免费领取干货大礼包!包括数据集、绘图代码、图表复现、思路总结、参考文献……0代码!鼠标点点点即可轻松完成5-10分生信SCI全文复现!
不想做实验,没数据,还想要快速发表文章,没问题的!公共数据库就是我们的数据宝藏!没思路不用担心,作为专业的生信团队,我们很乐意为你们效劳,提供研究路线设计和数据挖掘分析,扫码联系我们吧!



团队成员合影(位于上海陆家嘴中心,可随时预约参观)
题目:《非整倍体的蛋白质缓冲作用是由通过机器学习识别的协同因素驱动的》Protein buffering of aneuploidy is driven by coordinated factors identified through machine learning
发表期刊:Molecular Systems Biology
影响因子:7.7
研究背景:
非整倍体是癌症的标志,会改变数百个基因的拷贝数及其编码蛋白的丰度。然而,大量证据表明,受影响染色体上的蛋白质水平常被“缓冲”,使其丰度回归二倍体水平。尽管这一现象普遍存在,但其背后的分子机制、决定因素、在不同肿瘤类型中的差异以及其潜在的适应性优势和治疗相关性在很大程度上是未知的。以往的研究未能高精度地预测缓冲现象。
CNSknowall 平台 Pubmed+AI 快速提炼全文要点
研究思路:
- 建立定量方法
利用DepMap、ProCan、CPTAC等大型公共数据库及实验室构建的非整倍体细胞系,基于绝对基因拷贝数和染色体臂拷贝数变化,开发“缓冲比(BR)”指标,量化单个基因在单个样本中的蛋白质丰度衰减程度。
- 识别影响因素
收集35种与基因和蛋白质相关的生物化学与遗传学特征,通过单因素和多因素(随机森林、XGBoost、神经网络)机器学习模型,分析各因素对缓冲(Buffered vs. Scaling)的预测能力,并通过SHAP值阐明各因素的作用方向。
- 解析生物学后果
比较高低缓冲样本的差异表达基因,进行富集分析和通路分析;利用CRISPR筛选数据比较高低缓冲细胞系的基因依赖性差异;利用药物筛选数据分析缓冲能力与药物敏感性的关系。
研究亮点:
- 建立了新的定量框架
提出了“缓冲比(BR)”这一指标,实现了在单基因和单样本水平上对蛋白质剂量补偿进行精细化、拷贝数敏感的定量分析,克服了以往平均化分析的局限。
- 多因素机器学习模型
通过整合35种生物化学和遗传学特征,构建了可解释的机器学习模型,不仅显著提高了对蛋白质缓冲的预测精度(AUC最高达0.85),还识别出基因依赖性、蛋白复合物参与等关键预测因子及其作用方向。
- 揭示临床与生物学意义
研究发现不同癌症类型和细胞系具有不同的平均缓冲能力,且高缓冲与降低的蛋白毒性应激(UPR)、增强的耐药性相关,并发现低缓冲细胞对HSP和CHK抑制剂等特定药物更敏感,为靶向治疗提供了新思路。
研究结果:
- 缓冲现象的普遍性与可变性
在多种癌症细胞系和肿瘤样本中,38%-53%的基因在拷贝数变化后表现出蛋白质缓冲。肿瘤样本的缓冲比显著高于细胞系。基因缺失事件比增益事件引发更强的缓冲。实验室构建的单倍体细胞几乎将所有基因都归为“Buffered”类。
- 关键预测因子
多因素机器学习模型(尤其是XGBoost)的预测性能(AUC最高0.85)显著优于单因素分析。核心预测因子包括:高基因依赖性(必需性)、高蛋白复合物参与度,这两个因素与更高的缓冲概率相关。相反,高转录因子结合数、高随机等位基因表达频率与更低的缓冲概率(即Scaling)相关。
- 生物学关联与临床意义
高缓冲的细胞系下调了CCT/TRiC等蛋白折叠复合体及DNA修复相关通路,上调了整合素信号、上皮间充质转化(EMT) 等通路。在肿瘤样本中,高缓冲与降低的未折叠蛋白反应(UPR) 显著相关。高缓冲细胞系对基因的依赖性发生改变,并在总体上表现出更高的耐药性,尤其是对HSP和CHK抑制剂更不敏感,而低缓冲细胞则对这些药物敏感。
研究总结:
- 主要结论
蛋白质剂量补偿(缓冲)是非整倍体癌症中一个普遍且重要的调控机制,用于维持蛋白稳态。通过机器学习整合的多因素模型能够有效预测这一过程。缓冲能力影响癌细胞的适应性、致癌潜能和药物敏感性,将缓冲作为治疗脆弱性具有潜在价值。
- 讨论与延伸
- 机制
缓冲主要通过降解多余蛋白(尤其是蛋白复合物亚基)来维持亚基的化学计量平衡。基因必需性是驱动缓冲的最重要因素,提示必需基因的剂量必须被精确调控。
- 适应性优势
虽然高缓冲并未直接提升细胞增殖率,但它通过缓解非整倍体带来的蛋白毒性应激,可能增强了细胞对非整倍体的耐受性,从而在肿瘤进化中提供了适应性优势。
- 治疗启示
低缓冲能力的细胞对HSP和CHK抑制剂敏感,这为靶向那些无法有效缓解蛋白毒性应激的癌症提供了新策略。高缓冲能力与耐药性相关,提示需要开发克服此耐药性的新疗法。
- 局限性
缓冲比受蛋白质组学和拷贝数数据噪声的影响,研究未完全解析缓冲与细胞粘附通路之间关系的机制,且缺乏直接证据证明增加缓冲是适应性特征。
结果译文:
1.利用人类细胞系和肿瘤样本中的绝对基因拷贝数计算蛋白质水平的衰减
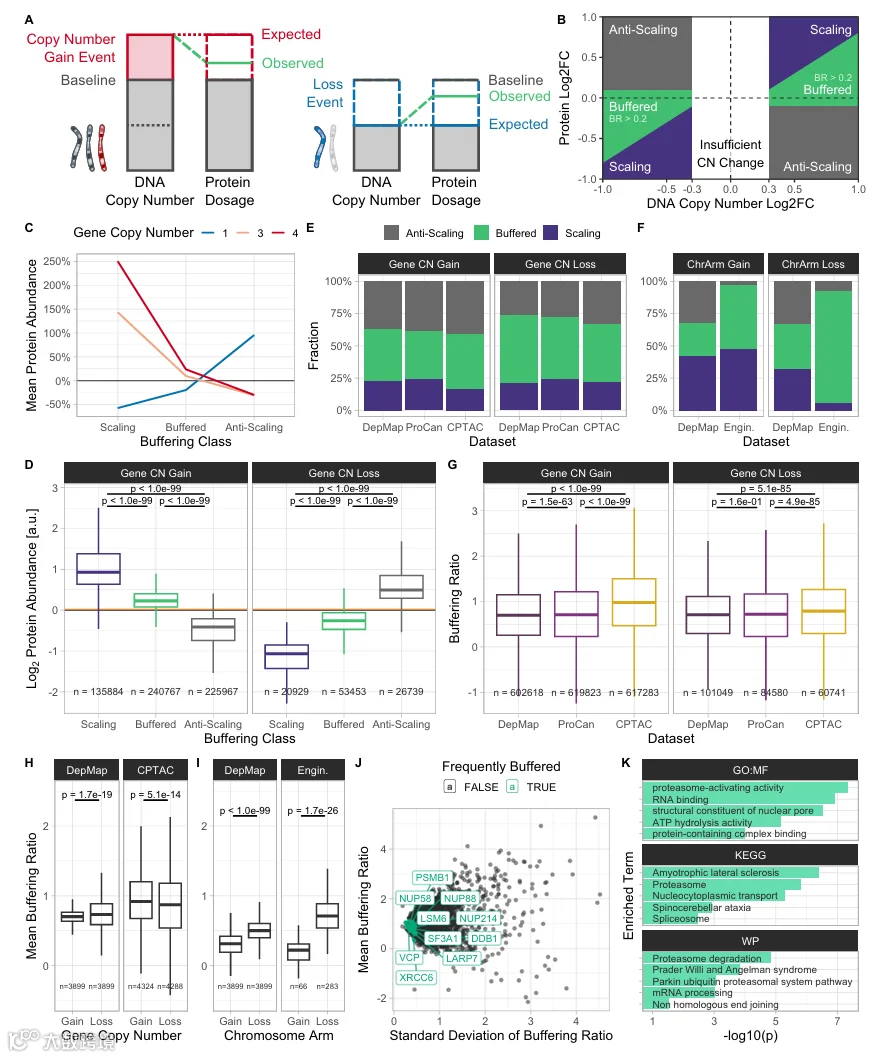
精确量化剂量补偿依赖于分析全基因组拷贝数变化及其与蛋白质组变化的匹配。在以往的研究中,拷贝数变化通常被评估为整条染色体或染色体臂的获得或丢失。然而,我们在肿瘤组织和癌细胞中经常观察到亚臂水平的拷贝数变化(图EV1A)。为提高此类分析的粒度,我们推导了一个新指标,称为缓冲比(Buffering Ratio,BR),它同时将局部基因和全染色体范围的拷贝数变化与蛋白质丰度变化进行比较。BR定义为蛋白质丰度log2倍数变化与(基因或染色体)拷贝数log2倍数变化之间的差值(见“方法”)。这一定义允许使用数值化的基因和染色体臂拷贝数差异进行缓冲量化,与以往将染色体臂拷贝数改变预先分类为获得、中性和丢失的方法相比,提高了缓冲估计的精度。BR允许对每个样本(细胞系或肿瘤样本)内的每个基因进行蛋白质缓冲量化,从而比跨样本平均蛋白质缓冲的方法提高了分析粒度。由于BR对蛋白质组学和拷贝数数据的噪声都很敏感,我们为BR计算了置信度评分,并从后续分析中移除了低置信度的BR测量值。
基于BR以及蛋白质丰度变化与基因拷贝数的同向性,我们将基因分为以下缓冲类别:若蛋白质丰度变化与基因拷贝数变化成比例,则称为“线性扩增”(Scaling);若蛋白质丰度变化小于比例,则称为“缓冲”(Buffered);若这些值呈反比,则称为“反线性扩增”(Anti-Scaling)(图1B)。我们使用染色体臂CNA和绝对基因拷贝数,为泛癌细胞系数据集DepMap CCLE(含375个细胞系的蛋白质组数据)、Sanger ProCan(949个细胞系)以及泛癌肿瘤样本数据集CPTAC(1026个肿瘤样本和523个正常组织样本)中的每个基因和样本计算了BR和缓冲类别。我们移除了纯度低于40%的肿瘤样本以控制肿瘤纯度。此外,我们还分析了携带单染色体单体或三体的近二倍体p53缺陷人视网膜色素上皮细胞系。我们为所有数据集提供了基因和染色体拷贝数获得与丢失情况下的个体缓冲比和类别数据(数据集EV1)。
正如预期,使用BR归类为线性扩增的蛋白质,其蛋白质丰度变化与拷贝数变化成比例,而缓冲蛋白则维持在接近二倍体的水平(图1C、D)。在泛癌细胞系(DepMap、ProCan)和肿瘤样本数据集(CPTAC)中,大多数蛋白质在基因拷贝数获得和丢失时要么是缓冲的(38-53%),要么是反线性扩增的(26-41%)(图1E)。CPTAC在基因拷贝数获得时缓冲蛋白的比例最高(42%),而DepMap在基因拷贝数丢失时缓冲蛋白的比例最高(53%)。此外,基因拷贝数丢失时缓冲观察的比例高于获得时(获得:38-42%;丢失:45-53%),而反线性扩增在拷贝数丢失时减少(获得:37-41%;丢失:26-33%)。这种模式在使用染色体臂CNA数据的泛癌细胞系数据集DepMap CCLE中得以保持(图1F),并且在控制全基因组倍增后也得以保持(图EV1C)。有趣的是,实验室工程细胞系与泛癌数据集相比,反线性扩增蛋白较少,且几乎所有受染色体臂丢失影响的蛋白质都被归类为缓冲(图1F;数据集EV1)。因此,基因剂量缓冲是工程非整倍体细胞中广泛存在的现象。
比较不同数据集之间的BR分布发现,与细胞系相比,肿瘤样本在获得和丢失时BR显著增加,这与观察到的缓冲和反线性扩增蛋白比例增加一致(图1G)。我们没有观察到肿瘤纯度与BR之间存在可能混淆这些结果的显著相关性(图EV1D)。相反,我们在平均BR高的肿瘤样本中观察到略有增加的免疫和基质细胞浸润评分(图EV1D)。为了解不同条件下缓冲的变化,我们比较了(基因拷贝数和染色体臂)获得与丢失之间的BR分布。我们观察到,在实验室工程细胞系和泛癌细胞系中,丢失事件的BR显著高于获得事件,而在肿瘤样本中,基因拷贝数获得时的BR更高(图1H、I)。这可能是由于肿瘤样本中具有强拷贝数扩增的基因比例增加(图EV1A)。因此,肿瘤样本可能也显示出增强的缓冲,以将这些基因的蛋白质丰度恢复到接近二倍体的水平。有趣的是,在经历过WGD的细胞系中,基因拷贝数丢失的BR低于获得,而在非WGD细胞系中,丢失的BR更高(图EV1B)。这表明,当仅有一个基因拷贝可用时,缓冲可能尤其重要。我们得出结论,在非整倍体细胞系中,与获得事件相比,拷贝数丢失时发生更多的蛋白质缓冲,无论这些是染色体畸变还是局部基因拷贝数变异。
计算出每个基因和每个样本的缓冲比后,我们询问哪些基因在不同细胞状态下频繁且一致地被缓冲。为此,我们筛选了在所有泛癌数据集(DepMap、ProCan、CPTAC)中超过33%的样本中被归类为缓冲且BR标准差小于2的基因。然后我们跨数据集汇总了它们的BR标准差排名。在BR变异低的前10个频繁缓冲基因中,有核孔复合体的三个亚基NUP88、NUP214和NUP58;核糖核蛋白LARP7、SF3A1和LSM6;DNA修复蛋白XRCC6和DDB1;蛋白酶体亚基PSMB1;以及VCP,一种将蛋白质从大蛋白组装中分离出来以促进其在蛋白酶体中降解的蛋白质(图1J;数据集EV2)。所有这些蛋白质都是大分子复合物的亚基,此前被认为受到广泛的剂量补偿。唯一的例外是分离酶VCP/p97,它与许多蛋白质相互作用,但不是大分子复合物的稳定成员。重要的是,VCP在蛋白质质量控制中起关键作用,而非整倍体细胞常面临蛋白质质量控制挑战。过度代表性分析进一步证实,RNA结合与加工、剪接体和蛋白酶体基因在前50个频繁缓冲基因中显著富集(图1K)。这证实了大分子复合物亚基需要维持化学计量水平的先前观点。
这些结果是可重复的,因为我们观察到细胞系数据集DepMap和ProCan之间基因拷贝数衍生的BR平均相关性为50%,而前50个频繁缓冲基因的平均相关性为55%(Spearman;图EV1E、F)。
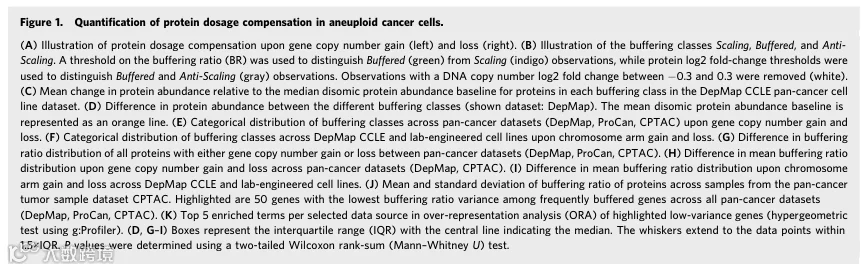
接下来,我们询问蛋白质剂量补偿在不同细胞系和肿瘤类型之间是否存在差异。使用与之前相同的数据集,我们通过计算每个样本(细胞系或肿瘤样本)所有基因的平均BR来获得样本缓冲比。计算样本BR的z分数显示,细胞系之间的平均缓冲存在显著差异(图2A)。这些结果在不同细胞系数据集之间一致,因为DepMap和ProCan之间计算的样本BR高度相关。BR的高相关性使我们能够跨数据集使用平均归一化排名(MNR)聚合细胞系的样本BR排名,为每个细胞系提供独立于数据集的平均缓冲估计资源(图2B;数据集EV3)。使用OncoTree分类按癌症类型绘制每个数据集的平均样本BR,显示不同癌症类型之间的平均缓冲存在差异(图2C)。在平均缓冲低的癌症类型中,我们观察到纤维肉瘤、肝母细胞瘤、尤文肉瘤、神经母细胞瘤和髓系/淋巴系肿瘤,而胰腺神经内分泌肿瘤、胸膜间皮瘤、肝细胞癌、甲状腺未分化癌和浸润性乳腺癌属于高缓冲癌症类型。值得注意的是,儿童癌症的平均样本BR通常低于成人癌症,高缓冲肿瘤样本的患者生存概率略低(图EV2C、D)。有趣的是,TP53突变的影响不一致,但我们观察到样本BR与细胞系的非整倍体评分和平均倍性呈正相关(图2C、D和EV2A、B、E)。此外,将细胞系分为有或无全基因组倍增的队列显示,这些队列之间的样本BR存在显著差异,表明WGD阳性细胞平均表现出更多的蛋白质缓冲(Wilcoxon秩和检验,ProCan:P = 8.0×10⁻⁴⁴)。我们得出结论,WGD阳性细胞、高度非整倍体细胞和成人癌症细胞平均表现出更多的蛋白质缓冲,并且非整倍体程度和WGD状态是分析平均细胞样本缓冲时需要控制的潜在混杂因素。
我们注意到,非实体癌如髓系和淋巴系肿瘤以及其他在悬浮培养中生长的细胞系,其平均蛋白质缓冲显著低于贴壁生长的细胞系(图2E)。由于非整倍体是样本BR的混杂因素,并且悬浮生长的细胞系通常非整倍体评分较低,我们通过从贴壁队列中移除非整倍体评分高于悬浮队列最大值的细胞系来控制这两个生长模式队列之间非整倍体程度的差异。我们还对贴壁生长队列应用了分层抽样方案,以确保两个生长模式队列之间非整倍体评分的分布相等。即使在这种设置下,与贴壁生长模式的细胞系相比,悬浮培养的细胞系平均缓冲仍然较低(图2E和EV2F、G)。因此,蛋白质平均缓冲程度在不同细胞和癌症类型之间存在差异,可能是受细胞生理学和组织类型影响的内在特征。
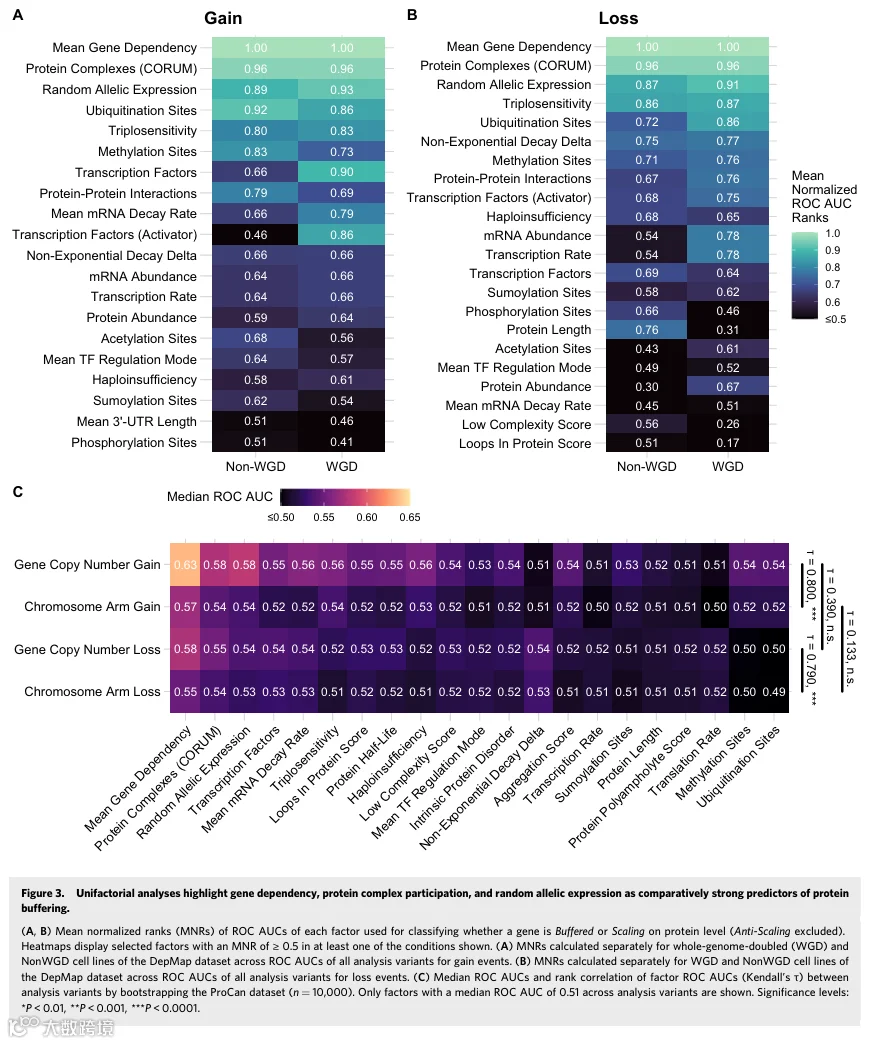
3.单因素分析突出基因依赖性、蛋白复合物参与和随机等位基因表达是蛋白质缓冲的相对强预测因子
为了研究影响蛋白质缓冲的因素,我们整理并整合了描述每个蛋白质生物化学和遗传特性的35个因素的多数据集。然后我们评估了每个因素的单独预测能力,通过计算受试者工作特征曲线下面积来确定其预测蛋白质是否被缓冲的有效性。我们在所有泛癌数据集(DepMap、ProCan、CPTAC)中,基于绝对基因拷贝数和染色体臂拷贝数衍生的BR缓冲类别,计算了ROC AUC。此外,我们通过先前描述的方法确定了每个基因在所有样本中的缓冲类别,该方法应用平均log2倍数变化阈值,将染色体臂CNA分类为获得、中性和丢失,将蛋白分组为线性扩增、缓冲和反线性扩增。这产生了三个独立的分析变体(Gene CN、ChrArm、ChrArm(avg.)),在分析影响蛋白质缓冲的因素时提供了不同粒度的多个视角。然后我们聚合了所有分析变体和所有泛癌数据集的ROC AUC排名,使用平均归一化排名来总结哪些因素在预测获得和丢失事件时的蛋白质缓冲中最相关,并额外按WGD状态分开(数据集EV4)。
区分蛋白质缓冲与线性扩增的最具预测性因素(获得事件)是:基因的平均依赖性评分(即必需性)、蛋白质参与的蛋白复合物数量、基因的随机等位基因表达频率与双等位基因表达的比较、蛋白质上的泛素化和甲基化位点数量、基因的三体敏感性概率,以及靶向该基因的转录因子数量(图3A)。在丢失事件中,最具预测性的因素是平均基因依赖性评分、蛋白复合物参与、蛋白质的非指数衰减程度、随机等位基因表达和三体敏感性(图3B)。这表明获得和丢失事件之间的预测因素效力仅有部分重叠。非指数衰减A评分和单倍不足概率在丢失时比获得时更具预测性,而平均mRNA衰减率在获得时比丢失时更重要。接下来我们询问能否识别出区分缓冲与线性扩增的重要性受基因组倍增影响的因素。泛素化和甲基化位点数量以及蛋白质-蛋白质相互作用数量在非WGD样本的获得事件中更重要,而平均mRNA衰减率、单倍不足概率和具有激活作用模式的转录因子数量在WGD阳性样本中更重要(图3A)。比较WGD与非WGD样本的丢失事件发现,转录因子数量、蛋白质长度和磷酸化位点数量在非WGD样本中更重要。相比之下,泛素化和乙酰化位点数量、mRNA丰度和转录速率以及蛋白质-蛋白质相互作用数量在WGD样本中更重要(图3B)。
接下来,我们通过自助法重采样缓冲类别并计算因素的ROC AUC排名相关性,来确定因素预测性在获得与丢失事件之间是否存在显著差异(见“方法”;数据集EV5)。为控制分析变体选择引起的差异,我们还评估了使用基因拷贝数数据与染色体臂CNA数据确定的缓冲类别之间的因素排名差异。当比较基因拷贝数与染色体臂的获得(或丢失)分析时,因素排名相关性很高,而当使用相同的拷贝数来源比较获得与丢失分析时,两者之间没有显著相关性(图3C)。因此,我们得出结论,蛋白质缓冲在获得时与丢失时至少部分受不同因素的影响,这与拷贝数变异发生在基因水平还是染色体臂水平无关。
我们观察到使用单因素预测的最大ROC AUC为0.672,表明对缓冲与线性扩增蛋白的区分能力中等(数据集EV4)。此外,蛋白质丰度、转录速率和mRNA丰度等因素的原始值和自助法ROC AUC经常强烈地成对相关,表明这些因素在预测蛋白质缓冲时携带等效信息(图EV3B-D)。计算因素值与(基因水平)缓冲比的相关性证实,平均基因依赖性评分、蛋白复合物参与、三体敏感性、mRNA衰减率和泛素化位点是重要因素,较高的值可预测蛋白质缓冲(图EV3E)。较高的随机等位基因表达频率和转录因子数量更预测线性扩增蛋白。然而,仅达到弱相关性(最大|ρ|=0.27)。我们得出结论,单因素分析能够识别出相对预测能力较高的因素,但无法强有力地整体预测蛋白质缓冲。
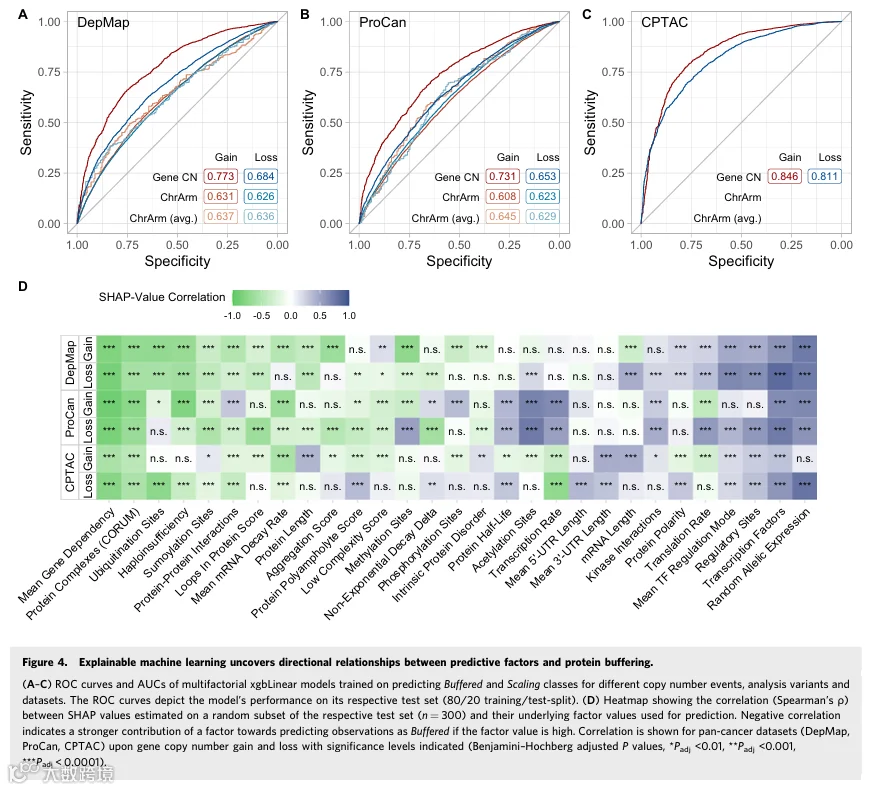
4.可解释机器学习揭示预测因素与蛋白质缓冲之间的方向性关系
我们考虑同时使用所有因素构建组合模型将提高预测能力。为此,我们训练了一系列机器学习模型,这些模型同时使用所有收集因素的一个子集来预测基因是缓冲还是线性扩增,基于为单因素预测建立的分类方案(图EV4A)。移除了高度相关且包含冗余信息的因素,以防止模型过拟合。我们从不同的分析变体、拷贝数事件和泛癌数据集中衍生出训练和测试数据集,并在每个训练集上训练模型(见“方法”)。
评估每个模型在其关联测试集上的性能显示,多因素模型比使用单个因素预测蛋白质缓冲的效果更好,达到了很强的区分能力(图4A-C和EV4B;数据集EV6)。此外,基于基因拷贝数衍生的缓冲类别训练的模型始终优于使用染色体臂CNA衍生缓冲类别的模型。尤其是在基因拷贝数获得时,模型在数据集上的表现优于拷贝数丢失。这可能是因为基因拷贝数提供了更精细的拷贝数信息,而在使用染色体臂拷贝数时会丢失这些信息。这些信息可以与BR结合使用,生成更准确的缓冲类别,从而可以被更自信地预测。此外,肿瘤样本衍生模型(CPTAC,Gene CN获得:ROC AUC = 0.846;丢失:ROC AUC = 0.811)的预测性能超过了在细胞系数据上训练的模型(DepMap,Gene CN获得:ROC AUC = 0.773;丢失:ROC AUC = 0.684)。接下来,我们评估了模型在未见数据集(样本外预测)上的预测性能。我们观察到,在细胞系数据集上训练的模型在基因拷贝数获得时对其他细胞系数据集表现良好,但对肿瘤样本数据表现较弱,反之亦然(图EV4C;数据集EV6)。基于这些观察,我们假设因素对蛋白质缓冲的影响在肿瘤样本和细胞系中略有不同。
为了确定每个因素对每个模型预测的贡献程度,我们计算了SHapley Additive exPlanation值,该值将实际预测与基线预测之间的差异归因于各个特征(图EV4D、E;数据集EV7)。由于可以为每个因素和预测获得SHAP值,我们在模型测试集的一个子集上计算了SHAP值,仅使用模型预测正确的观测值。负SHAP值表示,对于给定样本中的某个蛋白质,模型使用相应的因素值更确信地将该观测值分类为缓冲。为了量化因素在预测蛋白质缓冲中的影响方向并揭示生物学上有意义的趋势,我们计算了每个因素的SHAP值与其对应因素值之间的Spearman相关性。这种方法比单因素分析中直接关联BR与因素值获得了更强的相关性(最大|ρ|=0.95)。我们观察到,频繁参与大分子复合物和高平均基因依赖性与较低的SHAP值相关,因此在基因拷贝数获得和丢失时始终预测缓冲蛋白(图4D;数据集EV6)。这表明,当一个蛋白质在许多样本中是必需的且参与大量蛋白复合物时,模型更确信将其分类为缓冲。相反,结合到基因上的高数量转录因子、高比例具有激活调节模式的转录因子、高随机等位基因表达频率以及已知调节蛋白质功能的高数量位点,在基因拷贝数获得和丢失时始终预测线性扩增蛋白。有趣的是,泛素化位点数量增加在DepMap和ProCan中获得时比丢失时更预测缓冲蛋白,而在CPTAC中,泛素化位点数量增加在基因拷贝数丢失时更预测缓冲蛋白。我们在单因素相关分析中也观察到了这种模式(图EV3E)。
总之,多因素机器学习模型在预测蛋白质缓冲方面优于单因素分析。我们表明,增加的平均基因依赖性和蛋白复合物参与有助于更高的蛋白质缓冲概率,而更多的激活转录因子相互作用、蛋白质调节位点和更高的随机等位基因表达频率则有助于更低的蛋白质缓冲概率。这些发现与先前的单因素分析一致;然而,机器学习方法大大提高了模型置信度,并能够预测每个因素的方向性(缓冲 vs. 线性扩增)。此外,我们的多因素方法揭示了更微妙的关系,突显了癌症和癌细胞系之间的背景依赖性差异。
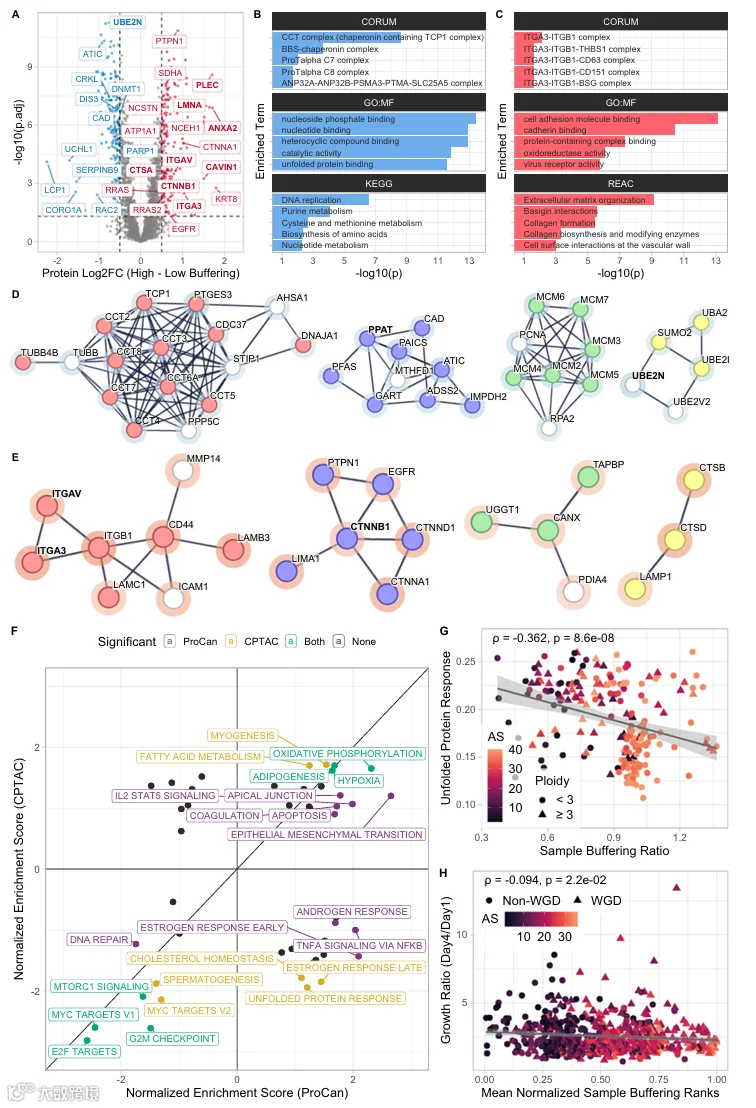
5.高平均缓冲的癌症样本显示出与蛋白质折叠相关的差异表达模式改变
接下来,我们研究了细胞系和肿瘤样本中的高平均蛋白质缓冲是否与特定的基因表达模式相关。使用先前计算的样本BR,我们将样本分为低缓冲和高缓冲组,并检测了与低缓冲样本相比,高缓冲样本中哪些蛋白质差异表达(图5A)。我们鉴定出癌驱动因子LMNA(核纤层蛋白A)、EGFR(表皮生长因子跨膜酪氨酸激酶受体)、RRAS(RAS小GTP酶家族成员)、CTNNB1(β-连环蛋白,Wnt信号通路的关键组分)等,在两个泛癌细胞系数据集(DepMap、ProCan)的高缓冲细胞系中显著上调。在高缓冲细胞系中下调的蛋白质中,我们观察到LCP1(一种与遗传性癌症综合征相关的肌动蛋白结合蛋白)和DNA甲基转移酶DNMT1。对高平均缓冲细胞系中下调基因的ORA显示,与蛋白质折叠相关的术语,如含伴侣蛋白CCT复合物、DNA复制和核苷酸结合得到富集(图5B)。CCT/TRiC复合物参与折叠10%的蛋白质组,包括肌动蛋白、微管蛋白和细胞周期调节因子。在上调蛋白中,整合素复合物伙伴、细胞粘附蛋白、钙粘蛋白结合蛋白和参与细胞外基质组织的蛋白得到富集(图5C)。
我们注意到血液癌症(通常在悬浮中生长)具有特别低的样本BR。为避免细胞生长方法的混杂影响,我们创建了一个贴壁对照,仅计算贴壁生长的高缓冲与低缓冲细胞系之间的差异表达。使用该贴壁对照,细胞粘附、细胞运动和细胞外基质组织蛋白在高缓冲细胞中仍然上调,而核苷酸代谢和生物合成蛋白仍然下调(图EV5A-C)。我们进一步发现在所有细胞系和贴壁对照数据集中共同失调的27个基因(数据集EV8)。
使用STRING可视化ProCan中差异表达基因参与已知和预测的蛋白质-蛋白质相互作用的方式(图5D、E)。除了CCT/TRiC复合物,我们还观察到参与核苷酸生物合成、蛋白质SUMO化相关基因以及与MCM复合物相关的DNA复制因子下调(图5D)。MCM复合物的失调与基因组不稳定性和非整倍体增加有关。此外,PCNA和UBE2N下调;这些基因在无错后复制修复中起作用。与ORA结果一致,包含整合素和与细胞外基质受体相互作用相关蛋白的簇上调(图5E)。特别是,整合素ITGA3、ITGA5和ITGB1在高缓冲细胞系中上调;它们的失调已被证明可改变细胞粘附并促进细胞侵袭。钙粘蛋白结合蛋白也上调,包括正调节细胞迁移的致癌基因EGFR,以及参与调节细胞粘附的Catenin beta-1(CTNNB1)。我们观察到EGFR(以及其他致癌基因)在染色体臂丢失时具有更高的BR,这意味着高缓冲细胞中EGFR的上调是由于EGFR本身在丢失时被缓冲(图EV5E-G)。EGFR已被证明在染色体臂获得时常线性扩增,我们的分析证实了这一点(Fisher精确检验,OR=0.27,P=7.9×10⁻⁴)。这表明癌细胞系独立于染色体臂获得或丢失而维持升高的EGFR水平。此外,溶酶体蛋白LAMP1、组织蛋白酶D和组织蛋白酶B上调。组织蛋白酶D和B的过表达以及LAMP1细胞表面表达增加与转移潜能和肿瘤侵袭增加相关。与下调基因类似,我们还在上调基因中发现了参与未折叠蛋白结合的蛋白簇(UGGT1、CANX、TAPBP),它们在未折叠和错误折叠蛋白的滞留和质量控制中发挥作用。这与CCT/TRiC复合物的下调相结合,表明高平均蛋白质缓冲的细胞系中蛋白质折叠质量控制增加,而整体蛋白质折叠需求可能减少。
为了进一步研究哪些癌症标志物在高平均缓冲细胞中失调,我们使用MSigDB标志基因集进行了基因集富集分析,并比较了肿瘤样本和细胞系之间的富集分数。MYC靶点、G2M检查点、MTORC1信号和E2F靶点基因集在高缓冲肿瘤样本和细胞系中均显著下调,而DNA修复基因集仅在细胞系中显著下调(图5F)。此外,与上皮-间充质转化相关的基因集在细胞系中显著上调,这与钙粘蛋白结合蛋白的上调相匹配。由于我们确定非整倍体是基于BR的分析的潜在混杂变量,我们还对高非整倍体与低非整倍体样本之间的差异表达数据进行了GSEA。在这种比较中,E2F靶点和MTORC1信号通路在高非整倍体肿瘤样本中上调,而EMT通路下调。这种对比表明,E2F和MTORC1信号的下调以及EMT通路的上调是高平均缓冲样本独有的,且与非整倍体无关(图EV5H;数据集EV8)。此外,EMT通路在高缓冲样本中的上调比在高非整倍体样本中更强。
高度非整倍体的细胞系和原发肿瘤遭受增加的蛋白毒性应激,并具有增加的未折叠蛋白反应。我们观察到UPR基因集在高平均缓冲的肿瘤样本中显著下调,但在细胞系中没有,表明肿瘤样本可能使用蛋白质缓冲来缓解蛋白毒性应激,并且比细胞系更有效(图5F)。为了验证这一假设,我们对CPTAC应用了单样本GSEA,使用UPR标志基因集,并将单样本富集分数与样本BR相关联。确实,表现出高平均缓冲的肿瘤样本显示出降低的UPR,尤其是在高度非整倍体的WGD阴性样本中,表明蛋白质缓冲减轻了蛋白毒性应激(图5G;数据集EV8)。肿瘤异质性和低肿瘤纯度可能混淆这些结果,但UPR富集分数与肿瘤纯度无显著相关(Spearman’s ρ = −0.034,P = 0.63;图EV5D),且纯度高于70%的肿瘤比低纯度肿瘤更少出现UPR升高(OR = 0.41,P = 0.021)。此外,当移除纯度低于50%的肿瘤样本时,样本BR与UPR富集分数之间的相关性增加(Spearman’s ρ = −0.43,P = 6.4×10⁻³),表明结果不受低纯度肿瘤样本的混淆。
因此,我们询问表现出高水平蛋白质缓冲的细胞系是否可能具有增殖优势,因为它们可能能够更好地减轻非整倍体引入的蛋白毒性应激。使用GDSC药物筛选数据集中DMSO处理细胞系的生长速率表明,一些细胞系非整倍体程度越高(尤其是WGD阳性细胞系),增殖越差(Spearman’s ρ = −0.270,P = 8.2×10⁻⁶)。然而,我们没有观察到细胞系中生长速率与平均缓冲估计之间的强烈显著相关性(图5H)。我们得出结论,高缓冲改变了细胞系中的蛋白质稳态,影响DNA修复、蛋白质折叠和细胞粘附通路。有趣的是,增加的缓冲并没有提供普遍的增殖优势。
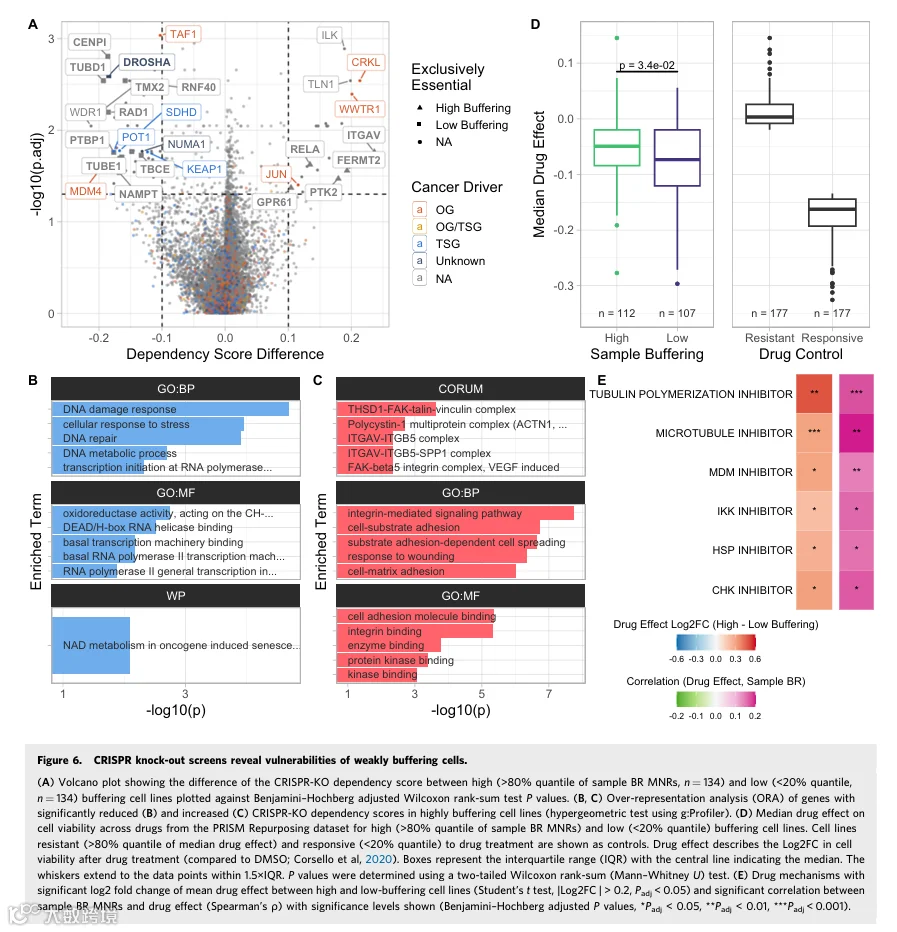
由于高平均蛋白质缓冲似乎并未在非整倍体细胞系中提供普遍的增殖优势,我们调查了这些细胞系是否对某些基因表现出差异依赖性,或者增加的缓冲是否减轻了非整倍体诱导的脆弱性。我们将细胞系分为高平均缓冲组和低平均缓冲组,并比较了这些组之间基因的依赖性评分。依赖性评分来源于CRISPR-KO筛选,量化了细胞系对特定基因的依赖程度。高平均缓冲细胞系更多地依赖致癌基因CRKL(一种可能激活RAS和JUN的蛋白激酶)和Hippo信号通路转录共激活因子WWTR1。另一方面,它们较少依赖致癌基因MDM4(p53调节因子)、TAF1(TATA结合因子);肿瘤抑制基因POT1(端粒保护蛋白)、SDHD(线粒体呼吸链亚基)和氧化应激传感器KEAP1(图6A;数据集EV9)。此外,ITGAV、FERMT2、PTK2、GPR61和RELA在高缓冲细胞中独有必需,而CENPI、DROSHA、RNF40、TUBD1、TMX2、RAD1、DPY30、PTBP1、TBCE、MED10、WDR48、TUBE1和NAMPT在低缓冲细胞系中独有必需。
对依赖性评分有显著差异的基因进行ORA显示,高平均缓冲细胞系比低平均缓冲细胞系更少依赖DNA损伤反应、DNA修复和细胞应激反应基因(图6B)。有趣的是,高缓冲细胞更依赖细胞粘附调节、底物粘附依赖性细胞铺展、激酶结合和整合素结合基因(图6C)。和之前一样,我们创建了一个贴壁生长的细胞系对照子集,并比较了该子集中高缓冲与低缓冲细胞系之间的差异依赖性(图EV6A;数据集EV9)。ORA显示,高缓冲细胞系中通用转录起始因子结合基因的必需性较低(图EV6B)。此外,在控制生长方法后,仍仅在低缓冲细胞系中独有必需的基因是CENPI(着丝粒蛋白I)、RAD1(RAD1检查点DNA外切酶)、TUBD1(微管蛋白δ1)和TBCE(微管蛋白折叠蛋白)。该分析进一步突显了高缓冲和低缓冲细胞系之间的生理差异。
接下来,我们分析了具有不同平均蛋白质缓冲程度的样本是否对药物治疗表现出改变的敏感性。我们从PRISM Repurposing数据集中收集了药物效应评分,量化了药物处理与DMSO处理之间细胞活力的变化,较低的值表示药物处理后细胞生长相对于DMSO对照降低。如果细胞系的中位药物效应高于药物效应评分的80%分位数,则将其归类为耐药;如果中位药物效应评分低于20%分位数,则归类为药物应答。和之前一样,我们还根据样本BR MNR的80%和20%分位数将细胞系归类为高缓冲和低缓冲。值得注意的是,高缓冲细胞中药物对细胞活力的中位效应更接近耐药细胞群,且与低平均蛋白质缓冲的细胞系相比,药物对高缓冲细胞活力的中位效应显著较低,尽管差异很小(图6D)。为了测试高缓冲和耐药是否经常同时发生,我们按中位样本BR MNR和中位药物效应分离所有可用细胞系。结果表明,高缓冲细胞系比样本BR MNR低于中位数的细胞系更频繁地出现耐药(Fisher精确检验,OR = 1.525,P = 2.1×10⁻²)。增加的耐药在很大程度上由非整倍体增加解释,表明缓冲对药物敏感性仅存在边际的独立于非整倍体的总体效应(图EV6C、D)。然而,高缓冲样本在独立于非整倍体状态的情况下,仍然略微更频繁地出现耐药(图EV6E;高非整倍体:OR = 1.088,P = 0.021;低非整倍体:OR = 1.182,P = 0.57)。这意味着,依赖于非整倍体的程度,仍然有一个可归因于缓冲的对药物敏感性的小效应。为了理解这些差异,我们按作用机制分析了单个药物和药物组。虽然高缓冲细胞系对任何药物组均未表现出敏感性,但低缓冲细胞系对HSP、CHK、MDM、IKK、微管和微管蛋白聚合抑制剂显著更敏感(图6E)。因此,不能有效缓冲非整倍体引起的蛋白质失衡的细胞,对靶向蛋白质折叠、有丝分裂纺锤体功能、先天免疫应答和DNA损伤应答的药物特别敏感。作为对照,我们分析了高非整倍体与低非整倍体细胞之间的药物效应差异。在高非整倍体细胞中不显著且是低缓冲细胞所独有的药物机制是CHK和HSP抑制剂(数据集EV10)。总之,虽然总体上增加的耐药可以很大程度上由非整倍体解释,但存在一种独立于非整倍体的对热休克蛋白和检查点激酶抑制剂的耐药性,可归因于增强的缓冲。
更多结果和补充图表:doi:10.1038/s44320-026-00187-9
长按二维码关注我们,用最短的时间和最高的效率学习更多生信思路!
扫描上方二维码或登录平台官网后添加CNSknowall客服微信咨询!官网地址:https://cnsknowall.com
CNSknowall:24年最新问世的遥遥领先的颠覆性科研数据(0代码生信+统计学)分析平台,同时含有机制图模块(原创3000多素材和机制图模板)+AI一键生成高质量比国自然标书初稿+汉化版Pubmed融合Deepseek高效筛选目标文献同时一键提炼全文核心创新点+SCI文献例句/语料检索模块+全文翻译+文献求助+图片查重+期刊查询+OPenAI官方GPT接口,>500款CNS级别图表皆可一秒内一键出图,登录即秒变数据分析大神,体验前所未有的便捷数据分析之旅,开启科研天骄之路!
可向下滑动发掘更多科研秘籍!