



原来做L4的科技公司:从Robotaxi上迁移感知,调整传感器;
传统Tier1或者OEM:把感知做好,处理好复杂场景。

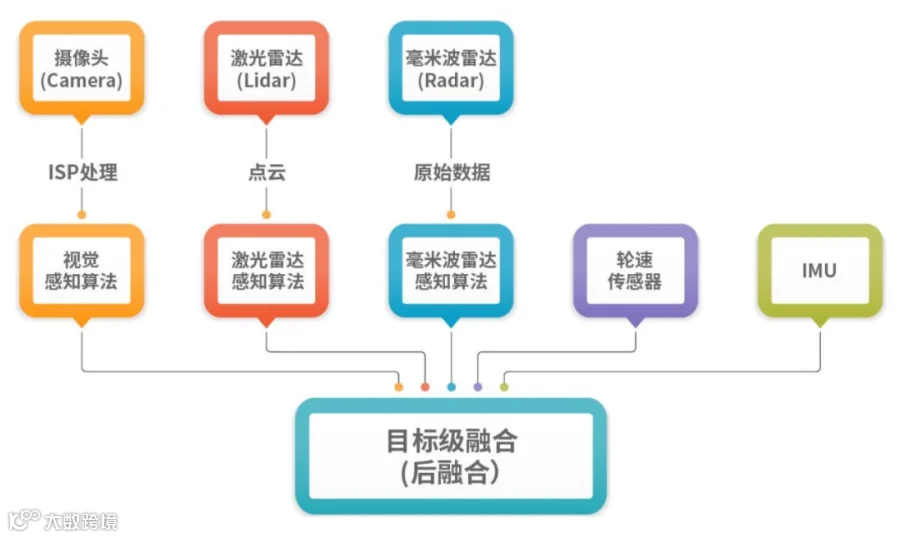
不同传感器各自算各的,把感知和分类的结果做投票,这个投票是根据场景的不同计算权重的;
算法由不同供应商提供,不需要域上的大算力,但每个传感器都可能丢失重要信息,比如高速公路上的破碎轮胎;
在行泊一体之前,大多数的行车、泊车是两套完全不同的传感器。
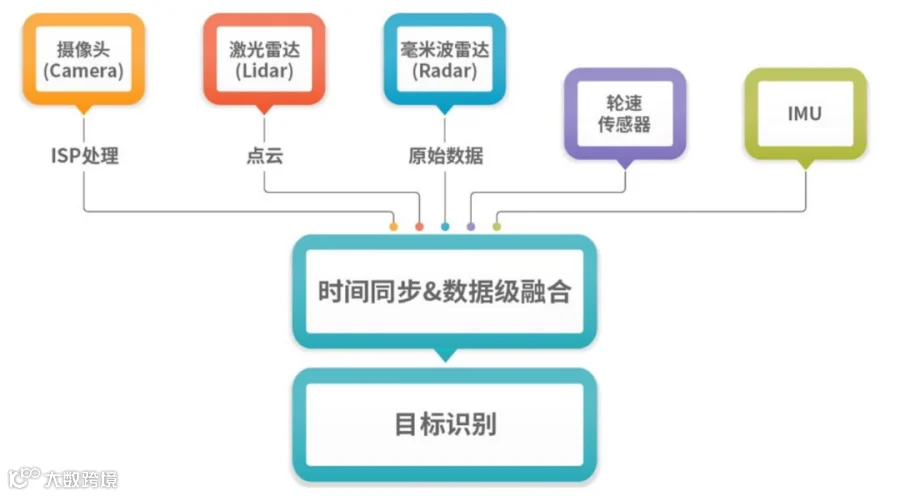
这么多点云与像素去做匹配的时候,时空同步难度很大;
算力消耗非常大;
不同的传感器硬件系统时间是不一样的,很难知道激光雷达的某一帧到底实际严格意义上对应了摄像头或者毫米波雷达的哪一帧,而且存在运动补偿的误差。


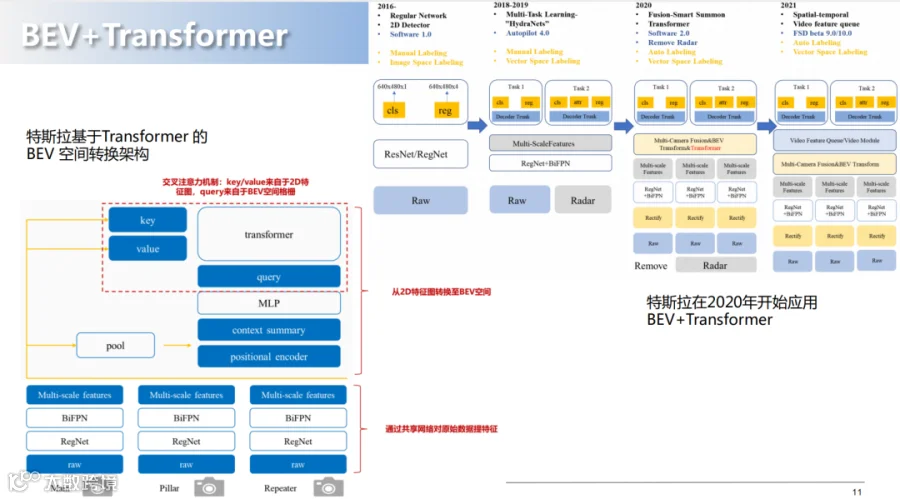
增加了系统的跟踪和推断的能力;
加了异构传感器的融合和算法泛化能力;
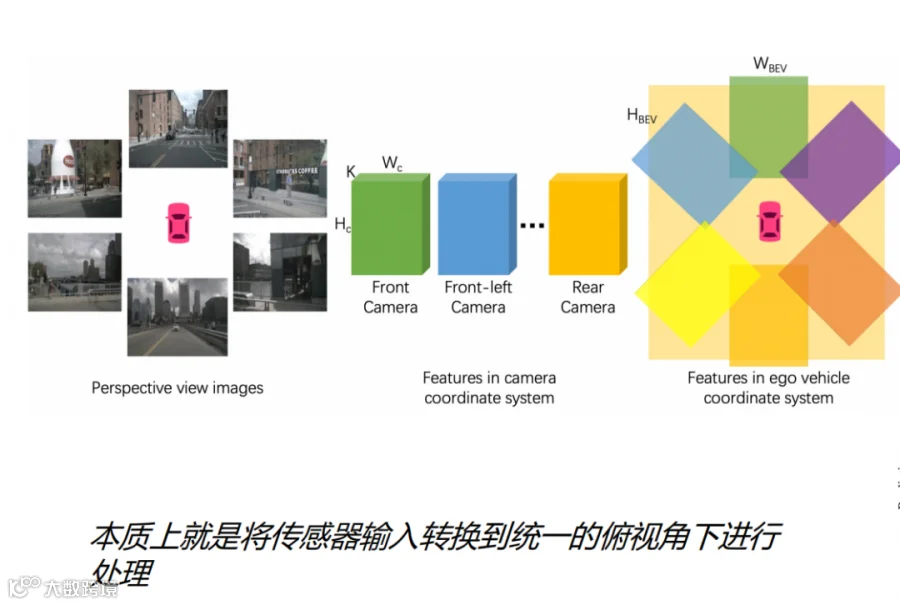
实现了不同视角下在BEV中进行统一的表达;
对于端到端的优化,模块更简洁了,任务的可扩展性也更强了。
拥有构建语义地图的能力,即是方案可以摆脱高精地图。
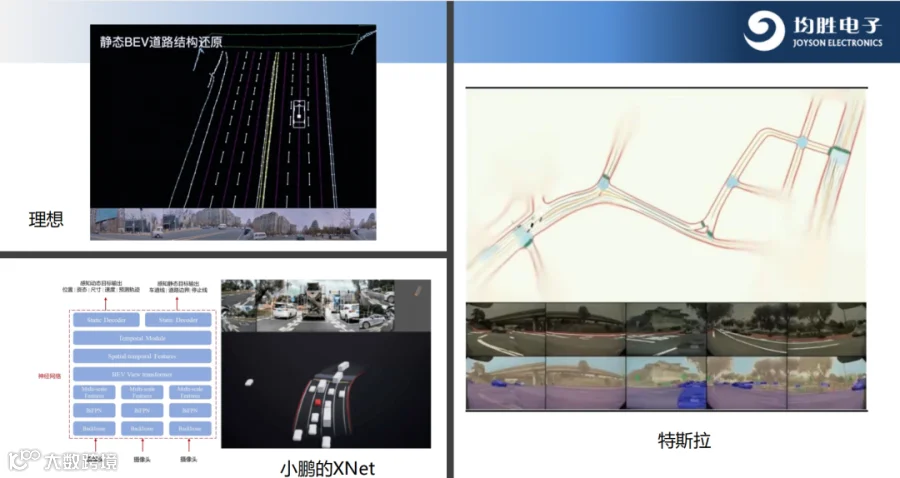
在影子模式的过程中得到了非常多的数据,数据能够自动地进行相对准确的标注;
然后用人工进行抽检的方式,能够现在越来越好地为深度学习/transformer的模型等提供更多输入数据。
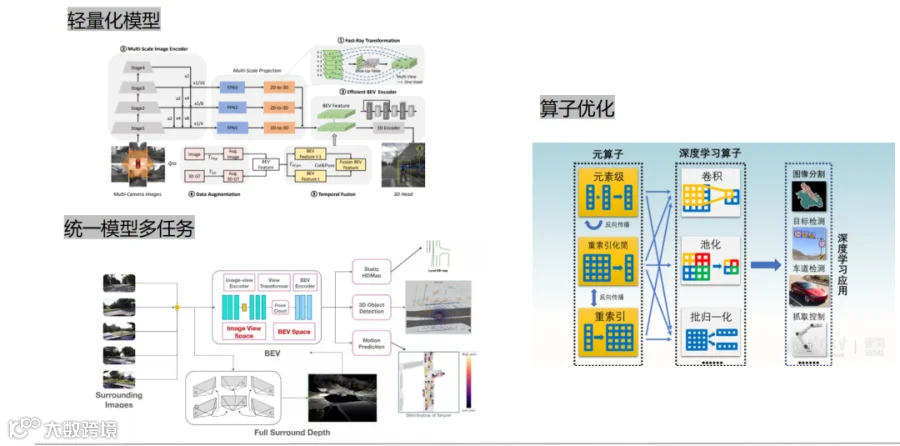
用相对轻量化的模型;
用多任务模型就统一一个模型,但输出多个任务可能是静态可能动态的,反正就是用一个模型输出多个;
对算子做一些优化。

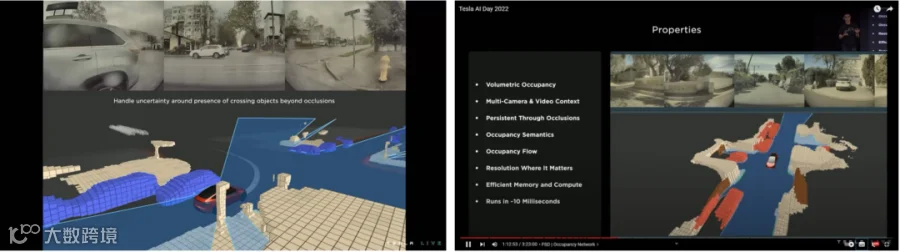

用传统的只知道摄像头的内参几何变换的方式得到的,但因为外部道路环境、车本身俯仰角的变化,使得模型很容易失效;
开始去尝试引入到车的位置信息,道路信息,然后开始去用深度学习去做BEV;
2021年开始,特斯拉把transformer和BEV做了结合之后,增加了多传感器,国内车厂开始跟随此方案,第三个阶段确实和大模型有非常大的关系。

