
作者 | 肖恩
编辑 | 德新
人类对人形机器人的想象由来已久,它常常作为伙伴或公敌出现在科幻作品中,大约直到马斯克公布了Optimus的计划,人形机器人在人类社会中的场景,被真正具象化了。
过去两年,人形机器人不再只是电影和实验室里的明星,它们开始频繁地出现在各类开发者大会的主舞台,以及产线、仓储乃至商场的展台上。
镜头里,机器人能走能跑,能抓取能分类,能听懂“把水杯放到托盘里”的命令并完成动作。看得见的,是更像人的外形以及动作;看不见的,是机身内部从“看懂世界”到“让电机发力”的计算链路,它决定了机器人能不能稳住重心,能不能捏住纸杯而不至于掐扁它,能不能听懂一句模糊的口令并在嘈杂环境里正确完成任务。
链路的每一段都依赖芯片,但并不是靠一颗“万能芯片”就能完成所有的计算。相反,人形机器人之所以难,是因为它必须在同一个机体里,同时满足三个互相“较劲”的需求:
上层的大模型和多模态感知数据要吞吐;
中层的节拍和网络要准点;
底层的电机与传感要在毫秒以下闭环、随时自我保护。
当大众把目光停留在“TOPS 有多少”“能不能跑 LLM”时,工程师们却更在意另一套朴素的指标:延迟、抖动、对时、带宽、冗余,以及在真实场景里,能不能撑住连跑一整天。

异构计算:大脑与小脑协同
为什么要异构?
人形机器人需要同时完成两类任务:一类是语义理解、环境感知、任务规划等高层认知计算,另一类是电机控制、姿态稳定和协调动作等低层运动控制。
国际机器人联盟发布的报告,形象地将这两部分比喻为“大脑”(Brain)和“小脑”(Cerebellum):大脑负责处理感知、规划与决策,需要强大的人工智能算力;小脑负责运动控制、反馈和稳定,需要确定性、高实时性的执行。
为了同时满足这两种截然不同的需求,机器人采用了异构处理架构——在同一系统中配置多种类型的处理器,每种处理器擅长特定的工作。
各类处理器的特点
理解异构架构,首先要了解不同处理器的特点及适用场景。
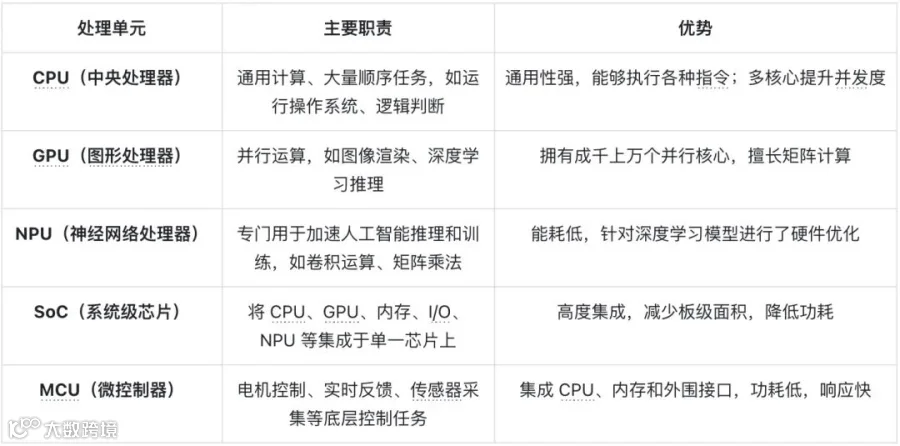
可以看出,CPU适合顺序性任务,GPU和NPU适合大规模并行的深度学习运算,MCU擅长低功耗实时控制,SoC则集成多种单元。
人形机器人在“大脑–小脑”架构中通常会同时使用这些处理器:
大脑部分采用CPU、GPU或NPU组合,运行操作系统、感知算法和认知模型。GPU/NPU提供并行加速,是视觉识别、语义理解和大语言模型推理的核心。由于大模型参数庞大,越来越多的机器人采用高算力SoC或AI模块(如 NVIDIA Jetson 系列)。
小脑部分通常由MCU或DSP承担,它们负责传感器采集、伺服控制、姿态稳定等,需要毫秒级的确定性和高可靠性。在一些平台中,MCU会与 CPU组成安全冗余系统,保证在主处理器异常时仍能维持基本控制。
因此,对于需要同时处理高阶认知和实时控制的人形机器人,“大小脑”协同异构架构是唯一可行的选择。

异构架构下的典型组合
随着芯片行业的发展,机器人在芯片的选择上可以从多个维度进行组合,从早期的桌面级PC方案到现在的多SoC异构组合,这背后不仅仅是机器人行业的快速发展,还能窥见整个AI行业的变革。
x86 CPU + GPU:机器人芯片的经典组合
早期机器人和研究平台普遍采用桌面级处理器配合独立显卡。

优必选Walker X,图片来源:企业官方
典型例子是优必选的 Walker X,官方规格表显示其使用双通道Intel i7 8665U处理器和NVIDIA GT1030 显卡。
除了独立显卡也可以使用CPU自带的集成显卡,例如傅里叶的N1,采用的是Intel Core i7‑13700H处理器,搭配Intel Iris Xe集成显卡。

傅里叶N1,图片来源:企业官方
x86 CPU + GPU组合的优点是基于成熟的PC生态,支持Ubuntu及ROS等通用软件,显卡能够提供一定的并行算力,可以处理基础视觉和导航算法,这是一种灵活且可以快速部署的解决方案。
缺点是功耗和体积都很大,续航和散热难以优化,因此随着SoC性能提升逐渐被更集成的方案所替代。
一些实验室自制机器人也使用i7 + RTX显卡进行仿真和实时渲染,但更多是研究原型而非量产产品。
低功耗SoC + 高算力AI模组:丰俭由人的灵活方案
面向消费级和教育市场的机器人通常采用高集成SoC,这类SoC在一颗芯片上集成了CPU、GPU和NPU,典型的产品如瑞芯微的RK3588,它是瑞芯微面向广域 AIoT/多媒体/边缘计算的通用高性能ARM SoC,采用四个Cortex‑A76内核(最高 2.4 GHz)和四个Cortex‑A55内核组成的8核CPU,内置Mali‑G610 MP4 GPU及6 TOPS NPU,还支持8K@60fps H.265/VP9解码和8K@30fps H.265/H.264编码,并提供Wi‑Fi、蓝牙、双千兆以太网、USB 3.0/3.1、CAN/RS‑485等丰富接口。
由于功耗低、体积小且成本相对较低,这类单板SoC常用于低成本人形机器人(如灵犀X2青春版)的基础计算板,但其算力上限有限,难以支撑大模型推理,因此通常与高算力模组搭配使用。
提到高算力AI模组就绕不开Nvidia Jetson系列,它是英伟达专为无人机、机器人等嵌入式应用打造的计算平台,在一张小型PCB上集成Arm CPU、GPU 以及专用NVDLA加速器,功耗低且支持完整CUDA生态,被定位为自主机器的“大脑”。
Jetson Orin家族按算力分为AGX Orin、Orin NX和Orin Nano系列。
AGX Orin模块可提供高达275 TOPS的AI算力,功耗在15W至60W之间,Orin NX最高157TOPS,更小的Orin Nano可提供67TOPS算力。这些模组均采用Ampere架构GPU和Arm Cortex‑A78AE CPU,软硬件兼容,可根据机器人的目标算力选择不同型号。
与汽车领域的Orin‑X相比,Jetson Orin虽然使用同代Orin架构但属于不同SKU,无法互刷系统;Orin‑X 是NVIDIA Drive平台上面向L2+自动驾驶的 SoC,单芯片INT8算力为254 TOPS,需要配合Drive OS使用,而Jetson模组预装JetPack系统,专注机器人和边缘AI应用。
随着机器学习模型规模不断扩大,Jetson AGX Orin的算力也开始捉襟见肘,因此Jetson AGX Thor应运而生。
它采用Blackwell架构GPU和14核Arm Neoverse‑V3AE CPU,支持MIG多实例GPU和4×25 GbE高速接口,可在75W至120W的功耗范围内提供2070 FP4 TFLOPS (相当于 INT8 2070TOPS)并配备128GB LPDDR5X内存,带宽273GB/s。

英伟达Jetson Thor,图片来源:企业官方
Jetson Thor相较AGX Orin实现7.5倍AI算力、3.5倍能效和2.6倍CPU性能提升,并通过MIG机制和更大的内存为大语言模型和多传感器感知提供硬件支持,适合运行多摄像头3D感知、融合视觉与语言的大模型等复杂任务。
采用“低功耗SoC + Jetson模组”的组合,可以让机器人在不牺牲电源预算的情况下获得强劲的AI加速。
例如灵犀X2探索版/旗舰版在双RK3588控制板上加装Jetson Orin NX模块,总算力提升至约157TOPS;宇树A2也提供可插拔的Jetson模组供用户根据任务难度选择。

宇树A2,图片来源:企业官方
未来,随着Jetson Thor量产,类似的组合有望将算力提升到千TOPS级,但这也意味着更高的功耗和散热需求。因此,在设计机器人时需平衡性能、重量和续航,以选择合适的AI模组。
算控一体SoC平台:大小脑协同
这两年机器人控制板开始集成“大脑”和“小脑”,将通用处理器、AI加速单元和实时控制器封装在一颗车规级SoC中。这类平台通常源于自动驾驶芯
片,兼具高算力和功能安全,可以称为“算控一体”的计算平台。

地瓜机器人RDK S100,图片来源:企业官方
例如地瓜机器人推出的RDK S100:“大脑”采用6核心Arm Cortex-A78AE CPU,可提供100K DMIPS高效算力,支持实时内核,具备高效调度和低延迟特性,BPU基于Nash架构,算力达到了80TOPS,支持160+ONNX准算子,专为CNN和Transformer优化,推理更快、功耗更低,能够满足各类复杂决策和规划任务的计算需求。
“小脑”由4核心Arm Cortex-R52+MCU组成,具备6K+DMIPS算力,为机器人提供了高帧率、低延迟的关节实时控制能力,满足各种实时运控场景的计算需求。通过这种“类人”的大小脑协同异构架构设计,RDK S100能够支持大小模型的动态融合、无缝切换,打通从感知到执行的完整闭环,助力机器人应对各类复杂多变的真实场景任务。
地瓜机器人的前身是地平线AIoT事业部,独立出来之后专注于机器人领域,而RDK S100 BPU所采用的Nash架构其实与地平线的自动驾驶芯片征程6同源。这也从侧面说明了车规级芯片的设计经验正在迁移到机器人领域。
RDK S100通过将征程6系列的AI内核裁剪并优化,加上机器人专用接口,成为地瓜机器人定制的“机器人大脑”平台。
另一家汽车行业的芯片公司芯驰科技同样以“车规标准”切入机器人市场,推出了多核异构的SoC:D9-Max,集成了12核 Cortex‑A55 CPU、双锁步 Cortex‑R5F MCU、8TOPS NPU、115 GFLOPS GPU和DSP单元。D9‑Max符合ISO 26262 ASIL‑D功能安全标准并支持Linux/Android/RTOS同时运行。芯片内置H.264/H.265 4K视频编解码器,支持9路摄像头输入及4屏1080p同步显示,满足机器人多模态感知需求;同时集成PCIe 3.0、USB 3.0、Ethernet TSN、12路CAN-FD等20+种通信接口,兼容工业总线与消费级协议,是一款面向工业和服务机器人市场的车规级SoC。
D9-Max通过 “AI 处理器 + 应用处理器 + 高性能 MCU” 三合一设计 ,可替代传统方案中5颗独立芯片,显著降低系统成本与开发复杂度。旨在为机器人、工业控制等场景提供高可靠性、高集成度的计算解决方案。
在智驾芯片取得量产后,黑芝麻智能今年也宣布正式进军机器人领域。
年初,黑芝麻智能与武汉大学达成战略合作,聚焦人形机器人技术突破与创新应用。以武汉大学自主研发的首个人形机器人“天问”为核心载体,基于黑芝麻智能芯片及算法方案,为“天问”分别打 造更强大的智能“ 大脑 ”与“ 小脑 ”。其中,“ 大脑 ”平台由黑芝麻智能华山A2000芯片提供算力支持,“ 小脑 ”平台基于黑芝麻智能武当C1236芯片打造。

2025年8月,黑芝麻智能与国内具身智能初创企业云深处科技达成战略合作,双方将在具身智能控制平台开发、行业智能解决方案共建及国际市场拓展等方面展开深度合作。黑芝麻智能提供高性能车规级芯片及边缘计算能力,云深处科技负责机器人本体与场景算法,联合开发面向船舶巡检、智慧建造、科研教学等场景的具身智能解决方案;同时,双方计划于2025年内完成首批海外示范项目落地,加速智能机器人的全球化应用。
未来,黑芝麻智能还将发布全新的机器人产品线,融合高性能SoC芯片、模块化硬件及全栈软件生态,在边缘端实现“感知—认知—决策—执行”闭环。
算控一体SoC平台在体积、功耗和数据延迟上具有明显优势,而且由于源自车载自动驾驶芯片,它们具备完备的功能安全体系。缺点是生态较新、硬件升级不如模块化方案灵活,开发者需要深入理解芯片架构和工具链才能充分利用其性能。
FPGA:下一波硬件革新
当前机器人的动作相对简单,对控制环的时延要求不算严格:行走或者摆手的控制周期通常在几十毫秒乃至上百毫秒,一个通用CPU/GPU通过软件调度即可胜任。
反观人类的运动神经系统,从运动神经元发出动作电位到肌肉产生张力的潜伏期仅为1–2毫秒。一些生理学理论将骨骼肌一次收缩划分为潜伏期、收缩期和放松期,其中潜伏期约2毫秒、收缩期10–100毫秒、放松期100–400毫秒。
这意味着,当我们希望机器人像人类一样在瞬间调整步伐或做出避障动作时,控制系统必须在几个毫秒内发出精准指令。
然而,通用CPU 一次只能顺序执行一条指令,操作系统还会引入上下文切换和中断等开销,使得程序的实际响应时间存在不确定性。即便GPU具备强大的并行计算能力,它也主要面向批量矩阵运算,算法调用栈较深,启动开销大,不适合微秒级的硬实时控制。
随着机器人需要完成更复杂、更敏捷的动作,仅依靠CPU/GPU很难在数毫秒的时间窗口内完成感知、决策和执行的闭环控制。这时,FPGA的优势就凸显出来。
FPGA内部由大量可配置的逻辑单元和互连构成,开发者可以通过硬件描述语言将复杂算法映射成并行电路,实现专用的数据通路和控制逻辑。由于逻辑单元直接在硬件上运行,FPGA可以提供确定性的纳秒级时延,非常适合伺服电机控制、传感器数据融合和安全监测等实时任务。
随着机器人追求“像人类一样快速反应”的目标,单靠CPU/GPU已经难以满足毫秒级甚至微秒级的运动控制要求。通过在系统中加入FPGA这种可编程逻辑的芯片,开发人员可以在硬件层面构建低延迟、确定性的控制回路,为人形机器人提供类似人类运动神经的反应速度。
由于外挂FPGA的方案会增加硬件复杂度,数据需要跨芯片传输,仍然依赖操作系统安排任务,并不一定能彻底消除延迟。因此集成了FPGA的MPSoC(Multiprocessor System on Chip)才是更优的方案。

AMD Zynq UltraScale + 是机器人领域应用最广的MPSoC平台之一。其EV系列在单芯片内集成Arm Cortex‑A53 CPU集群、Mali GPU、DSP和FPGA逻辑,并可搭配4GB DDR4内存。官方文档称,Kria KR260机器人入门套件基于K26 SOM(采用 Zynq UltraScale+ MPSoC)设计,提供即时硬件启动、硬件加速应用和ROS 2软件包,使开发者能在无需FPGA经验的情况下构建高性能机器人。
在需要强实时和高并行的场景里,FPGA的优势首先体现在“以硬件描述算法”。开发者可以把多通道传感器融合、并行滤波、编码解码等数据流任务,直接映射为按位、按拍运行的电路与流水线,从而获得远高于通用处理器的并行度。由于没有操作系统调度与缓存抖动的干扰,时序由时钟和状态机严格主导,单次路径延迟可压到微秒甚至更低,尤其适合用于伺服控制回路、联锁与安全监测等对确定性有刚性要求的环节。与此同时,FPGA在固定功能的数据流任务上,相比依赖大批量线程与缓存体系的GPU,FPGA往往能以更低的功耗完成同等吞吐,能效优势明显。
但这些好处并非没有代价。FPGA开发需要掌握Verilog/VHDL等硬件描述语言与时序约束,理解时钟域、资源利用率、布线与收敛等“硬件思维”,学习曲线相对陡峭;定位问题也更偏硬件范式,往往要借助仿真、在线逻辑分析与探针观测,调试复杂度高于纯软件系统。此外,中高端器件与集成可编程逻辑的SoC平台价格不菲,叠加更高的开发与验证成本,使得初期部署的总体成本显著高于仅用通用SoC的方案。
但是随着工具链和高层次综合技术的进步,使用FPGA开发已经不像过去那样困难。
因此,未来越来越多的机器人厂商可能会在算控一体的MPSoC路线中,按需引入可编程逻辑:上层由CPU/GPU/NPU负责感知与决策,下层用FPGA承担对时延最敏感的控制与安全功能,在性能、确定性与能效之间取得实践可行的平衡。

机器人大潮来临,未来的计算趋势
未来几年,机器人核心芯片的发展将集中在少数几个关键方向,而不是重复堆叠已经讨论过的概念。
算力不断攀升,大模型驱动“超大脑”
多模态大语言模型的普及使机器人需要在本地处理亿级甚至十亿级参数。为了在不依赖云端的情况下完成感知、规划与对话,边缘端的算力必须大幅提升。像Jetson Orin NX和AGX Thor这样的小型模块,在几十瓦功耗范围内便能提供100 TOPS乃至800TFLOPS的AI性能。随着芯片制程的进步,未来的主板上将集成更高带宽的内存、更先进的混合精度单元,以及针对大模型优化的NPU/GPU架构,使机器人真正拥有“超大脑”。
功能安全与系统安全双重加强
在人机共存的应用中,安全是任何技术跃迁的前提。以D9‑Max为代表的新一代SoC在单芯片内配置双核MCU 、安全岛和ECC内存,以硬件冗余保障功能安全并通过ISO 26262等认证。与此同时,安全启动、固件签名、可信执行环境和OTA更新等技术也将成为标配,提升网络安全和数据隐私保护能力。未来的机器人芯片将像汽车电子一样,围绕功能安全和信息安全构建全链路的标准体系。
能效与热管理优化
随着算力提升,功耗和散热成为移动机器人的主要制约。Jetson AGX Thor和Orin相比在提供7.5倍AI性能的同时能耗比提升了3.5倍。这一趋势意味着未来芯片不仅要提供更高的理论算力,还要通过动态电源管理、功耗按需分级、先进封装与散热技术,提升每瓦性能。良好的热设计将决定机器人是否能够长时间稳定工作。
国产生态与自主可控
除了国际巨头的产品,国内芯片厂商也在快速崛起。
全志MR系列、瑞芯微RK3588和地瓜RDK S100系列为人形机器人提供了从中低端到高端的算力选择。随着工具链、本土化生态和供应链的完善,国产芯片在成本、可获取性和适配性方面将形成竞争优势,未来的机器人平台可能会看到更多“混血”方案:国产SoC + 国际AI加速器或国产AI芯片配合国际 MCU 的组合。
人形机器人是多学科交叉的产物,其核心计算平台从单一CPU发展到复杂的异构组合,既要满足人工智能推理的高算力需求,又要满足运动控制的高实时性要求。
虽然未来的机器人芯片路线仍存在不确定性,但有一点可以确定:计算硬件的不断进步正在让机器人成为现实。从教育研究到工业生产,从家庭服务到危险作业,人形机器人将与我们一起进入一个由软硬件协同驱动的智能时代。
