
你好,我是郭震。你的电脑中是否积累了大量 PDF、Word、Excel 等各类文档?包括会议纪要、项目资料、论文及合同等。存储时认为未来必有用途,但在实际检索时却往往难以定位。
当文件数量达到成千上万时,仅依靠 Windows 自带搜索或记忆已无法满足需求。若需查找特定合同条款或论文实验数据,传统方式效率极低。本文将分享针对此类痛点的高效解决方案。
1. 攻克复杂扫描 PDF 解析难题
日常存储的 PDF 多为扫描件或排版复杂的学术论文,常包含多栏布局、数学公式及嵌套表格:
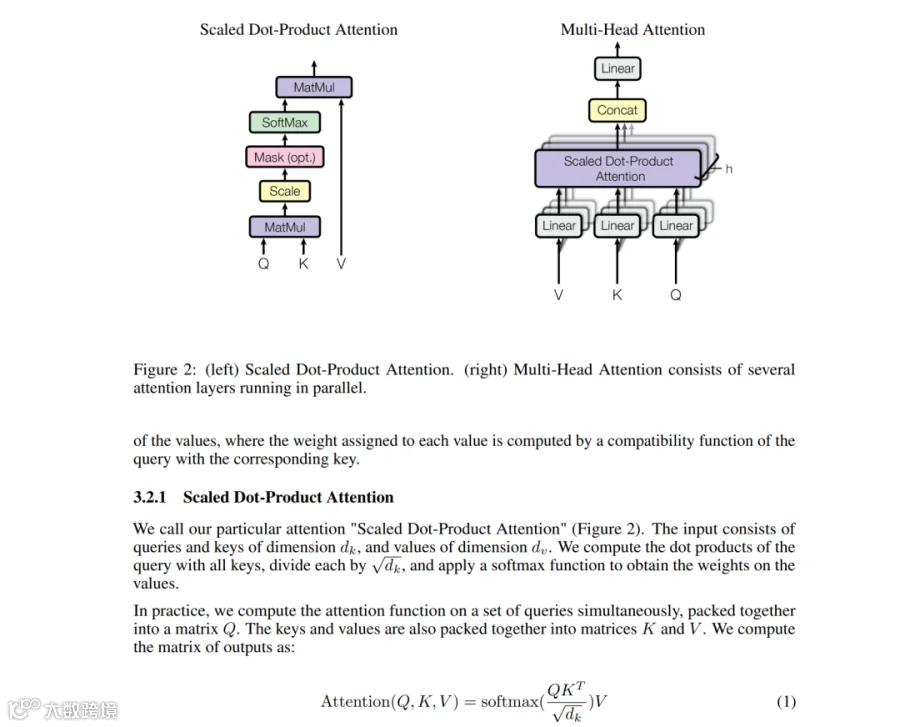
此类文件直接输入传统 AI 工具,往往导致格式错乱。例如在 NotebookLM 知识库中解析后,公式排版出现明显错误:
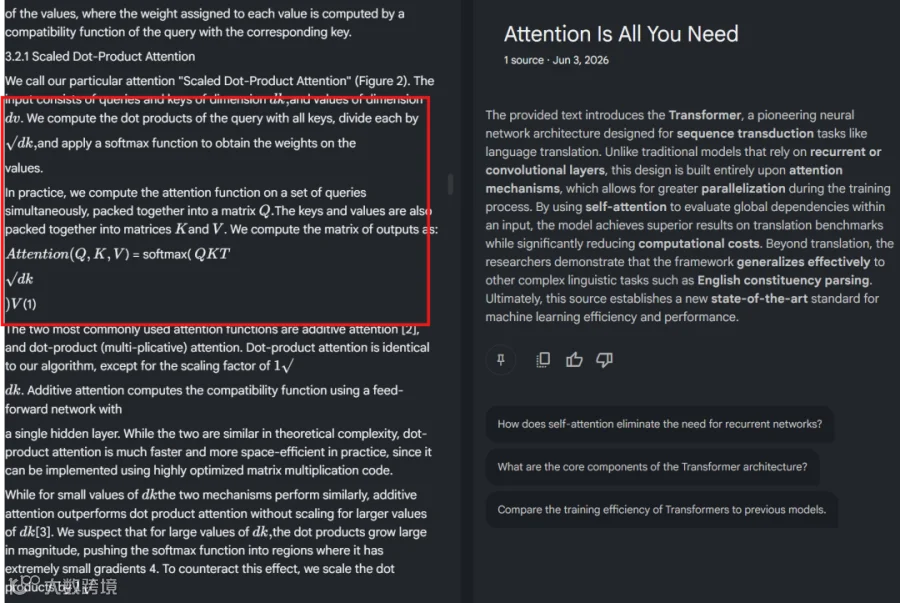
推荐采用 MinerU 工具解决此类“难啃”文档。该工具能精准还原复杂公式、嵌套表格及扫描件内容,最大限度保持原文语义结构。
接入 DeepLocals 知识库并通过 MinerU 解析后,公式还原质量显著优于 NotebookLM:
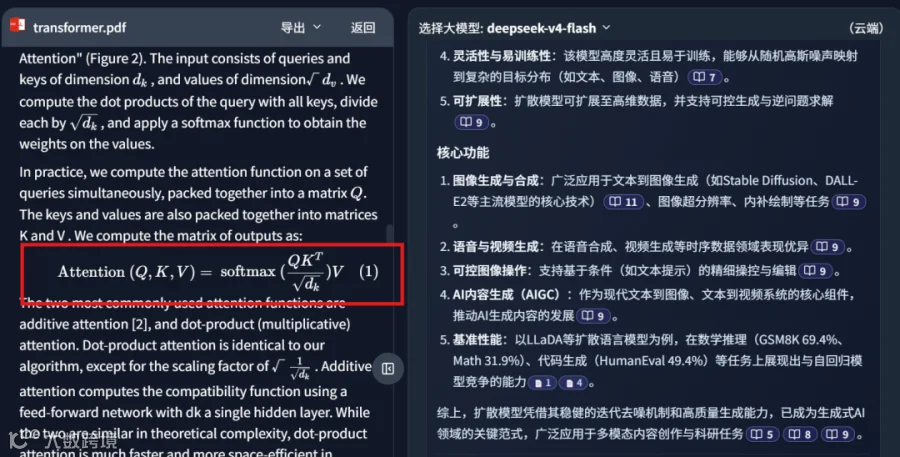
基于高质量的解析结果,AI 在回答问题时不再依赖推测,而是能准确识别图表与公式内容。在知识库检索问答场景中,系统可精准命中对应文档片段并输出准确答案:
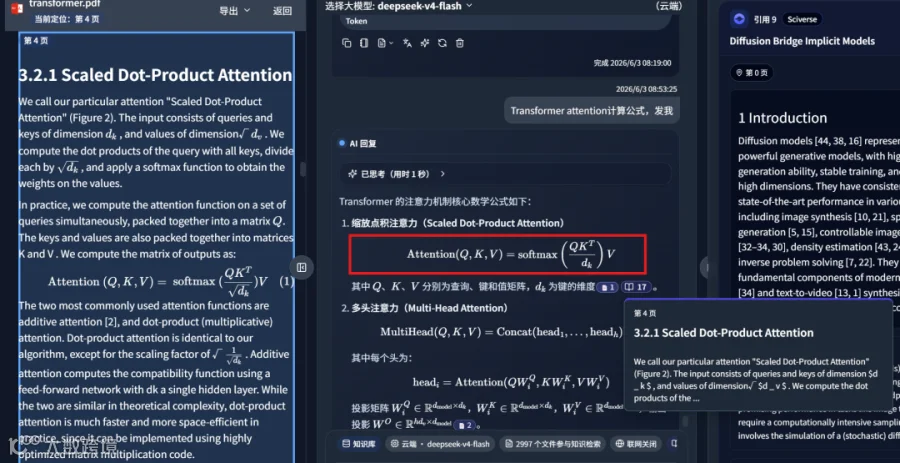
MinerU 之所以具备卓越的解析能力,得益于其强大的智能文档解析引擎:

2. 私有资料与外部学术库联动
仅依赖本地资料往往不足以满足深度调研或技术方案查证需求,通常需要结合外部专业文献。
MinerU 近期已接入 Sciverse 学术库,涵盖 2500 万篇公开文献:
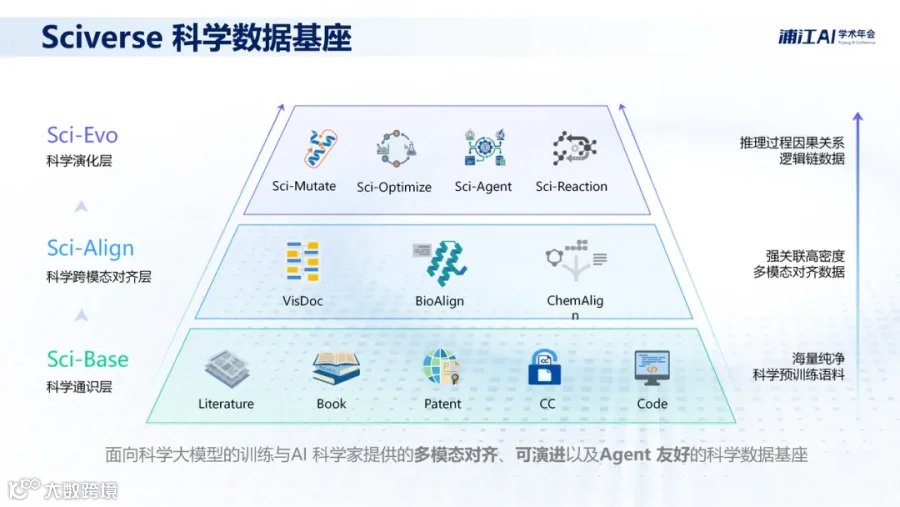
DeepLocals 也已集成此功能。用户在提问时勾选“学术文献搜索”,系统将同步检索本地文件与全球专业学术论文。
以"diffusion 总结”为例,使用 DeepSeek-V4 大模型进行查询:
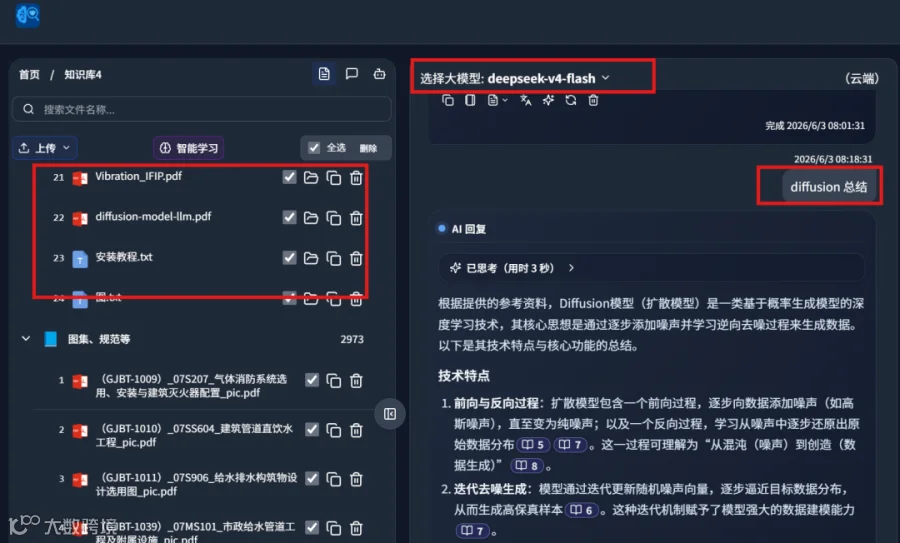
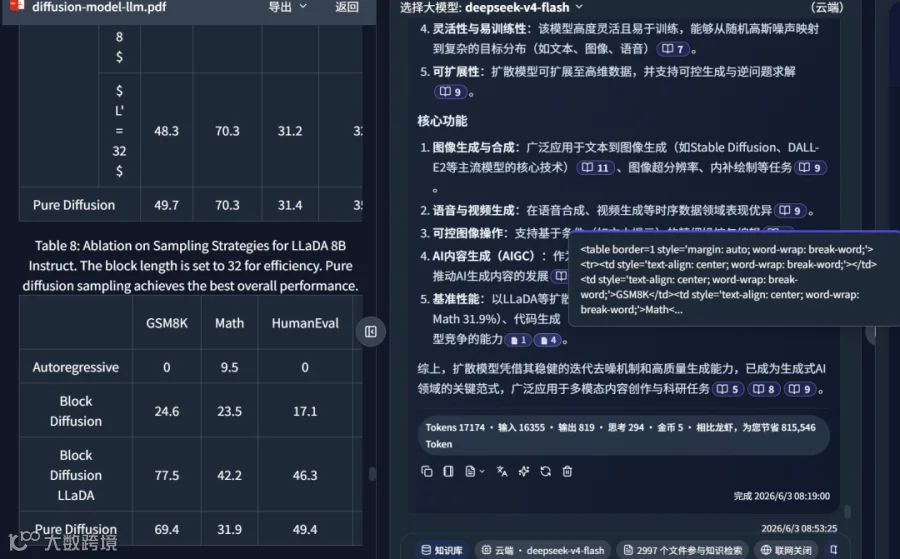
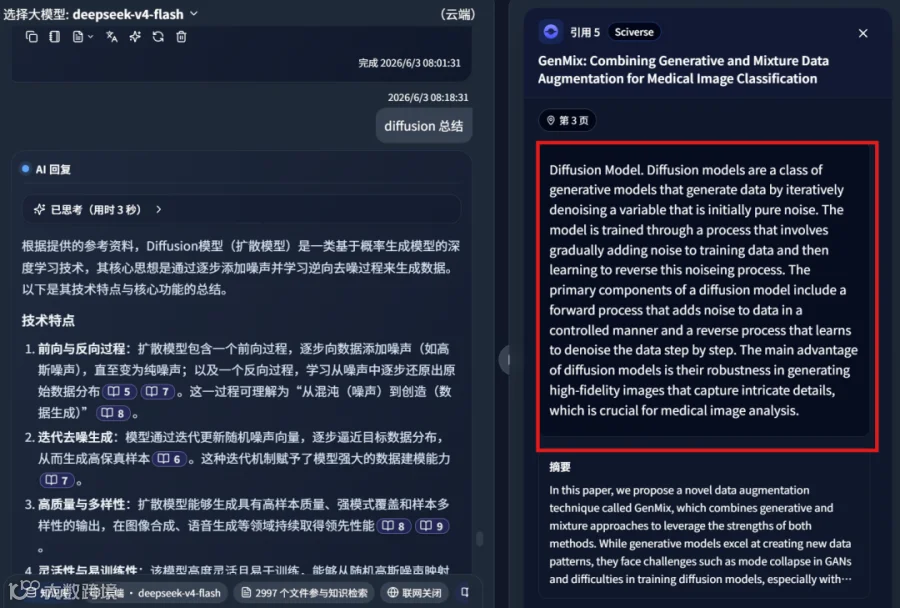
参考来源包含多篇高质量文献,如文献 11:
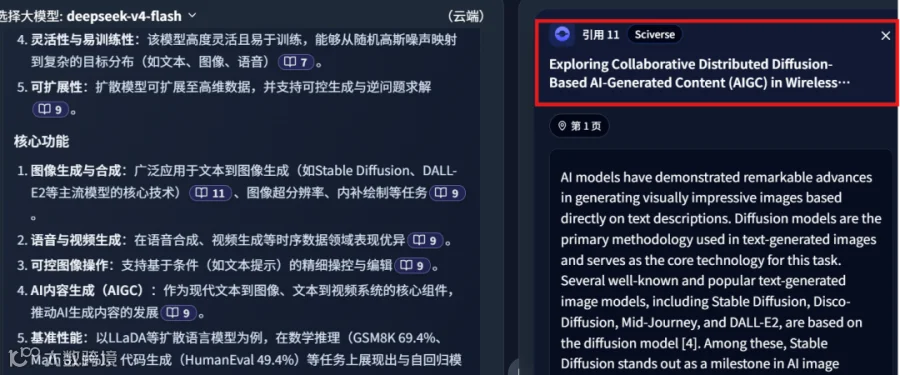
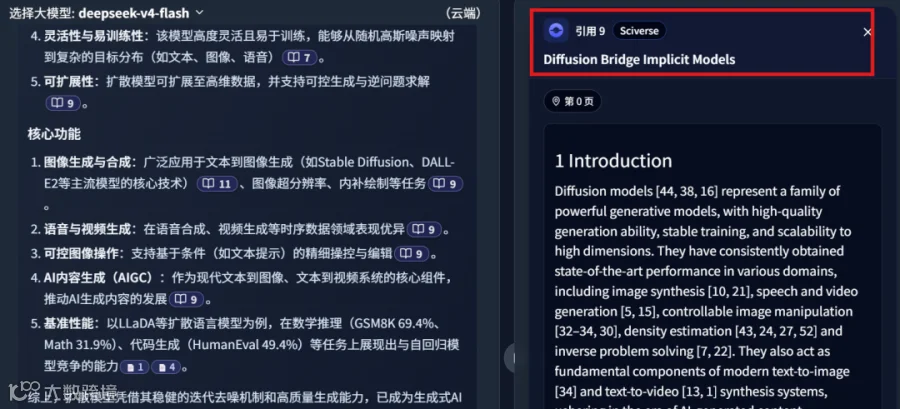
文献 8:

3. DeepSeek-V4 赋能多模态知识库
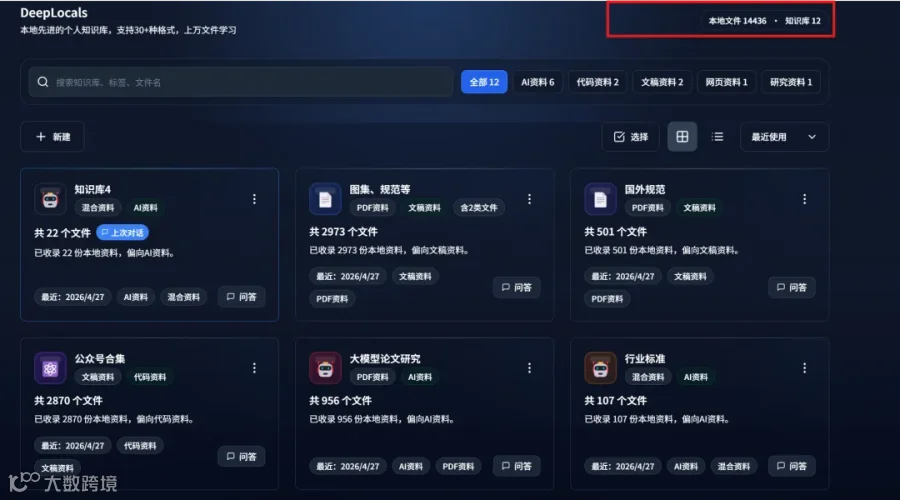
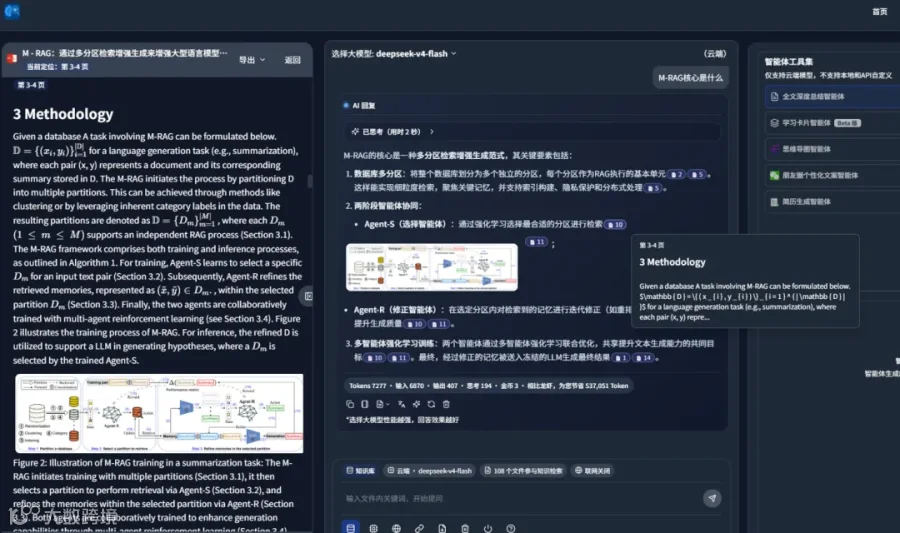
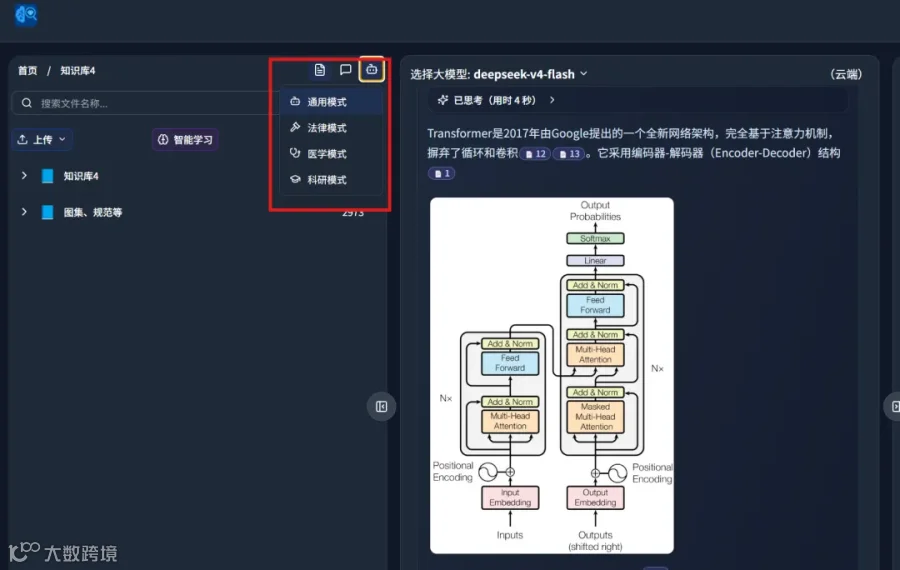
此外,系统支持跨多个知识库联合回答问题:
除上述方案外,腾讯 IMA 等也是常用的知识库工具,感兴趣的用户可自行体验。
总结
本文实测了 DeepSeek-V4 结合 MinerU 的解决方案,有效解决了扫描 PDF 处理难题,并实现了本地与外部知识的无缝联动。
具体而言,利用 MinerU 规范混乱文档,借助 Sciverse 引入全球学术证据,构建了“本地资料整理有序、外部文献检索精准”的高效 AI 工作台。
若您也受困于文档堆积,希望借助 AI 实现基于证据的高效工作,这套组合方案值得尝试。