
摘要
混合专家模型(Mixture-of-Experts,MoE)是一种条件计算(conditional computation)架构,通过将大型Transformer模型的Feed-Forward Network(FFN)层拆分为多个独立的“专家”子网络,并引入可学习的路由(gating)机制,仅对每个输入token激活少量专家(通常Top-1或Top-2,这个概念跟前文提到的Top-K就类似了,Top-1表示只选择分数最高的1个专家,也就是每个token只激活这1个专家,其余专家完全不参与计算),从而实现总参数量的大幅扩展。MoE已成为当前大规模语言模型(LLM)计算高效扩展(compute-efficient scaling)的核心技术之一,在相同计算预算下显著优于稠密(dense)模型。本文从历史背景、动机、Transformer中的集成方式、工作原理、训练挑战与优化、缩放规律、典型变体、工程实践及实际案例等多个维度进行系统性、深入解析,并提供量化对比,全面理解MoE的理论基础。
一、背景与动机
1.1 从稠密模型到稀疏激活的演进
Transformer语言模型的缩放定律(scaling laws)已被Kaplan et al.(2020)和Hoffmann et al.(Chinchilla, 2022)等工作广泛验证:模型性能随参数量、数据集规模和计算量(FLOPs)的共同增长而提升。但稠密Transformer存在一个根本性矛盾——每个输入token必须经过模型全部参数的计算。参数量从亿级增长到万亿级时,推理阶段每一步的FLOPs、显存占用和延迟均线性增长,导致部署成本指数级上升。 MoE通过稀疏激活(sparse activation)打破这一瓶颈:总参数量可轻松扩展至数百亿甚至万亿,而每个 token 仅激活极少数专家(通常 Top-1 或 Top-2),实际参与计算的参数比例通常远低于 10%。这本质上是条件计算范式(conditional computation)的现代实现,早在1991年Jacobs et al.就提出MoE概念,2017年Shazeer et al.将其首次应用于语言建模,2021年Google的Switch Transformer将其推向大规模预训练。
1.2 核心思想:参数规模与激活规模的解耦
MoE的核心在于总参数量(total parameters)与活跃参数量(active parameters)的分离:
总参数量极大 → 模型容量(capacity)和表达能力大幅提升
每个token仅激活少量专家 → 计算量与稠密模型相当,甚至更低
这使得在相同FLOPs预算下,MoE模型可实现更低的困惑度(perplexity)和更好的下游任务性能,同时支持更高的吞吐量。
二、MoE在Transformer中的位置
现代大模型普遍采用Pre-LN(Pre-Layer Normalization)结构以提升训练稳定性(与原始Attention Is All You Need论文的Post-LN不同)。典型Transformer Block结构如下:
TransformerBlock(input): normed = LayerNorm(input) x = input + SelfAttention(normed) # 残差连接:输入 + 自注意力输出 normed_x = LayerNorm(x) x = x + FeedForwardNetwork(normed_x) # 第二层残差 return x
MoE的核心替换仅发生在FFN层:
MoETransformerBlock(input): normed = LayerNorm(input) x = input + SelfAttention(normed) # 和原来一模一样,残差结构不变 normed_x = LayerNorm(x) x = x + MixtureOfExperts(normed_x) # 只换这里,残差结构也和原来一样 return x
关键特性:
Self-Attention模块完全不变(保持全局依赖建模能力)
仅FFN被替换为MoE层(侵入性极低,便于现有稠密模型迁移)
MoE通常应用于每一层(或每隔几层),专家数量N可达8~160不等
这种设计使得MoE可无缝集成到Llama、Mistral等主流架构中。
三、MoE工作原理详解
3.1 整体架构
一个MoE层由两部分组成:
Gating Network(路由网络):通常是一个轻量级线性层(有时带噪声),负责为每个token分配专家。
N个Expert:每个Expert本质上是一个独立的FFN子网络(含两层线性变换 + 非线性激活,如SiLU/GELU)。
输出计算公式为:
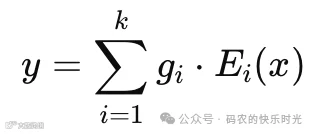
![]()
其中
x为输入向量
E_i为第i个专家
g_i为归一化后的路由权重
k为选中的专家数量(典型k=1或2)
3.2 路由(Gating)机制
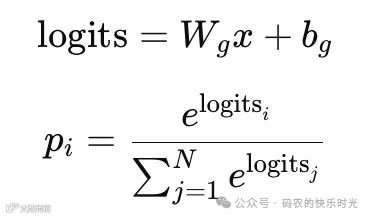
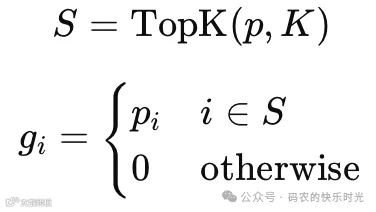
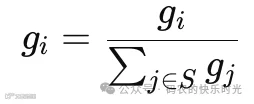
x为输入向量
W_g表示权重矩阵,为可训练参数
b_g表示偏置,为可训练参数
logits表示,执行线性投影,表示输入与各专家的线性相似度(affinity score)
p_i表示,执行softmax,把分数变成概率分布
g_i表示,Top_K稀疏化,然后重新归一化得到路由权重
完整流程:
路由网络首先计算logits,然后通过softmax得到概率分布,实际选择Top-K专家(Top-K Gating),其余g_i=0,并对选中的K个专家的概率重新归一化(以保证权重和为1)。
为什么Top-K优于Top-1?
Top-2(Mixtral、Grok-1常用)能让专家间协作,提升表达能力
Top-1(Switch Transformer)更高效,通信量减半
Noisy Top-K Gating(Shazeer 2017):为防止早期专家“死亡”,在logits上注入高斯噪声:
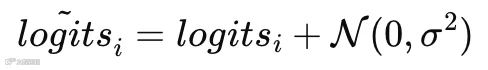
噪声标准差σ通常由模型学习(input-dependent noise scale)。
其中
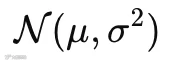
表示均值 = μ,方差 = σ2 的高斯分布(正态分布)
3.3 Token级计算流程与工程优化
输入序列长度L,形状[L, d]。路由输出形状[L, N]。
L为当前输入序列的长度
d为模型的隐藏层维度
N为该 MoE 层中专家的总数
路由决策:每个token独立选择Top-K专家。
Dispatch(分发):按专家ID对token进行分组(grouping),同一专家的tokens被打包成连续batch。
Expert Computation:并行计算各专家的FFN(高度并行化)。
Combine(合并):加权求和输出。
关键工程优化:
Token Regrouping + All-to-All通信:在分布式训练/推理中(TP/EP并行),使用All-to-All collective操作实现token在专家间的动态路由,该过程通常成为 MoE 的主要性能瓶颈之一。
专家容量(Capacity Factor):专家容量限制是 MoE 中的核心机制之一,即使在负载均衡优化下仍然需要显式控制。
GPU利用率:通过动态batching和专家并行(Expert Parallelism)维持高TFLOPS。
四、MoE训练难点与解决方案
4.1 专家负载不平衡(Load Imbalance)
核心问题是正反馈效应:早期被多路由的专家获得更多梯度,变得更“擅长”,进一步吸引更多token,形成“赢家通吃”。结果:少数专家过载,大量专家闲置(router collapse)。
4.2 解决方案
Noisy Top-K Gating:引入随机性,促进探索。
负载均衡辅助损失(Load Balancing Loss)(Switch Transformer):
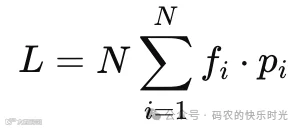
其中f_i为实际路由到专家i的token比例,
p_i为路由概率的batch均值。系数通常为0.01~0.1,与主损失加权求和。该损失强制不同专家的负载趋于均衡。
Switch Transformer改进:Top-1路由 + 更激进的负载均衡,显著降低通信开销。
其他高级技巧:
容量因子(Capacity Factor)与token dropping
随机路由或辅助专家(auxiliary experts)
动态专家剪枝/合并(现代优化)
DeepSeek-V2中的精细化专家设计(更小粒度专家 + 共享专家)
4.3 训练不稳定与优化
原因包括梯度路径碎片化、专家间竞争。解决方案:
更小的学习率 + 梯度裁剪
合理的专家初始化(不同专家轻微扰动)
LayerNorm + RMSNorm稳定激活分布
混合精度训练(BF16)+ 梯度检查点
4.4 推理部署挑战
显存:需加载全部参数(虽活跃参数少,但KV cache仍受上下文影响)
动态路由:小batch下GPU利用率低 → 采用连续批处理(continuous batching)+ 专家缓存
分布式:Expert Parallelism + Pipeline Parallelism + All-to-All优化(vLLM、DeepSpeed-MoE等框架已成熟)
五、MoE缩放规律
Switch Transformer实证结论:在相同FLOPs下,MoE模型困惑度更低、收敛更快、参数效率更高。 量化示例(基于公开论文):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在相同 FLOPs 预算下,MoE 模型通常表现出比稠密模型更优的参数效率,但这并不直接违背或替代 Chinchilla scaling law,而是提供了一种不同的扩展路径(conditional computation)。
六、常见变体
6.1 专家粒度
标准:整个FFN作为一个专家
细粒度:将FFN拆分成多个小专家(DeepSeekMoE采用此策略,进一步提升路由灵活性)
6.2 共享 vs 私有专家
纯私有:所有专家独立(早期设计)
共享 + 路由(现代主流,如DeepSeek-V2):引入少量全局共享专家(处理通用特征)+ 大量路由专家(处理特定模式),兼顾通用性与专业性。
6.3 路由策略
Top-2:效果最佳(Mixtral、Grok-1)
Top-1:最高效率(Switch)
哈希路由(Hash Routing):无学习开销,但性能较差
层次化/树状MoE、软路由(soft MoE)等前沿探索
七、MoE优缺点总结
优点:
参数效率极高:在相同计算预算下获得更强性能
专家专业化(specialization):专家通常会表现出一定程度的 specialization(如语法、代码等),但并非严格可控或完全可解释
易集成:对现有Transformer改动极小
推理性价比高:每个 token 仅激活其中部分专家(如 2/8),有效计算规模远小于总参数量
缺点:
训练复杂度更高(需辅助损失、噪声、正则化)
部署挑战大(All-to-All通信、负载均衡)
小batch场景下延迟优势不明显
显存占用仍较高(全参数加载)
八、MoE为何会越来越流行?
2023-2026年间,MoE架构迅速主导开源前沿:Mixtral 8x7B以6倍推理速度超越Llama 2 70B;DeepSeek-V2以236B总参数、21B活跃参数实现顶级性能与极致效率;Grok-1(314B)则展示了MoE在大规模xAI训练栈下的可扩展性。根本原因在于:
稠密模型参数扩展已接近算力/能耗极限
MoE提供参数-计算解耦,在相同训练/推理成本下效果更优
工程生态成熟(DeepSpeed、vLLM、Megatron-MoE等)
实证缩放优势显著,越来越多新一代模型开始探索或采用 MoE 架构
参考文献
[1] Shazeer et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.
[2] Fedus et al. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.
[3] Lepikhin et al. (2020). GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
[4] Jiang et al. (2024). Mixtral of Experts (Mistral AI).
[5] Liu et al. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.
[6] xAI (2024). Grok-1 Open Release.
[7] https://huggingface.co/blog/zh/moe
本文仅作学术信息分享,如有侵犯请联系删除