




|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
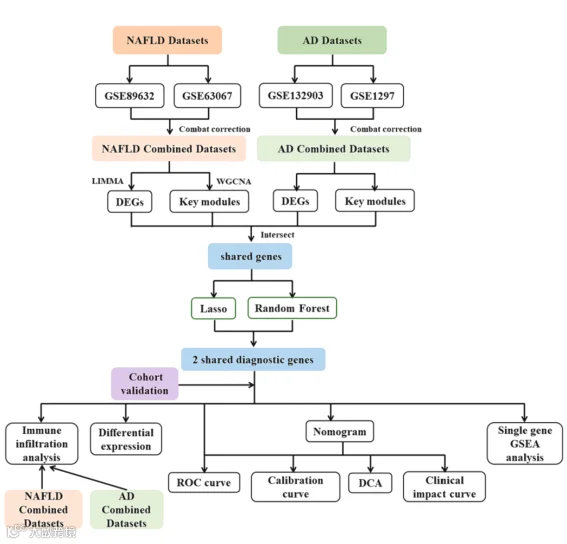
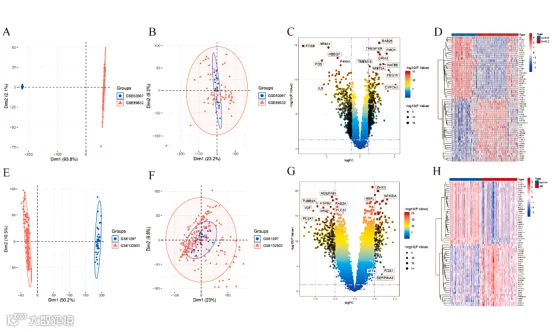
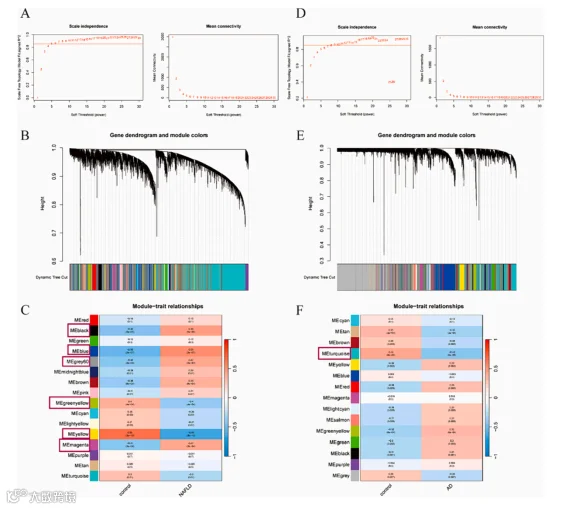
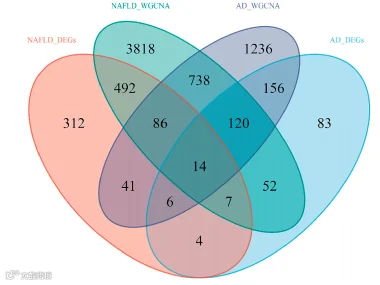


小记者话生信
如果您的时间和精力有限或者缺乏相关经验,并且对生信分析和期刊推荐有所需要的话,“生信日报”非常乐意为您提供如下服务:免费思路评估、付费生信分析和方案设计以及付费选刊等,有意向的小伙伴欢迎咨询小记者哦!

生信分析
思路设计
服务器租赁
扫码咨询小记者

1、超高分sci!将近50分你还有不看的理由?德国学者真是把机器学习玩出花了,直接构建一个新生信分析方法,还不快看!
2、国自然出品就是牛!复旦大学施思&虞先濬团队:借公共数据库+RNA-seq+湿实验研究癌症成纤维,IF近9分属实佩服!
3、MDPI期刊再爆丑闻!23本期刊存在“审稿人工厂”问题!
END