一句话读完:斯坦福大学 Arc Institute 团队联合 UC Berkeley和NVIDIA英伟达团队发布了迄今生物学领域最大规模的生物大模型 Evo 2。它用 9.3 万亿个核苷酸、跨越细菌到人类的 10 万+物种基因组训练而成,不仅能预测基因突变是好是坏,还能从头设计全新的基因组序列——并且,它完全开源。
先感受一下这个数字:9,300,000,000,000
如果把人类基因组比作一本 30 亿字母的"生命之书",Evo 2 在训练时读了多少本这样的书?
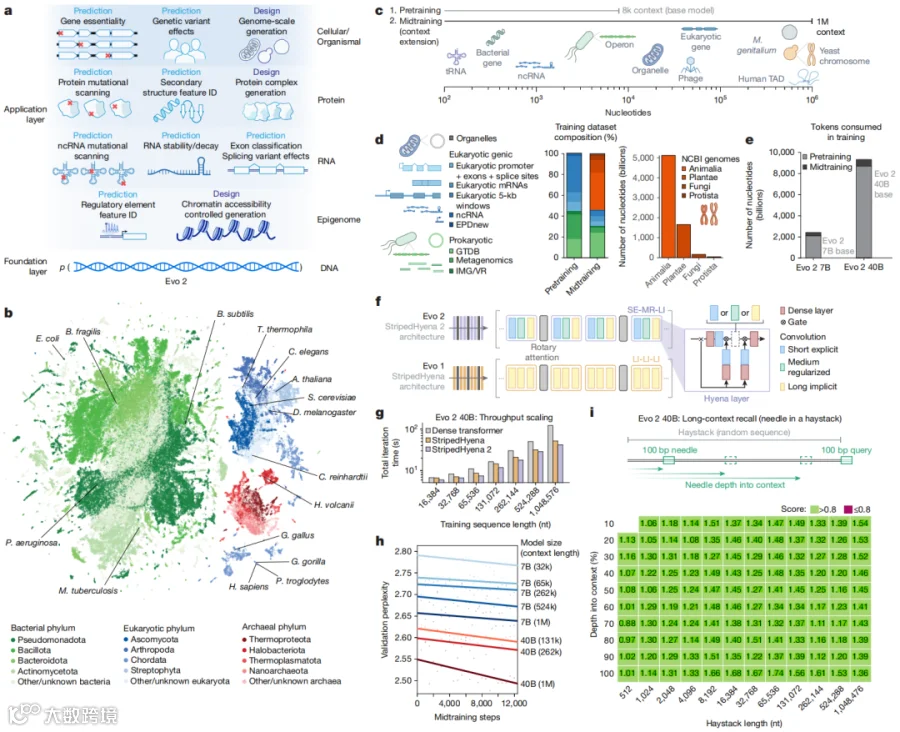
具体来说,Evo 2 的训练数据名为OpenGenome2,包含了来自细菌、古菌、真核生物(从酵母到人类)以及噬菌体的128,000 个完整基因组,总计9.3 万亿个核苷酸——也就是 9.3 trillion 个 A、T、C、G。
如果把每个碱基写成一个字符,这些 DNA 序列连起来可以绕地球赤道 37,000 圈。
Evo 2 是什么?不是算命先生,而是"基因组语言模型"
ChatGPT 读完了互联网上的海量文本,学会了理解和生成人类语言。Evo 2 则读完了地球生命之树上的海量基因组,学会了理解和生成生命的语言——DNA。
最惊人的是它的"长上下文"能力。传统 DNA 模型通常只能看几千个碱基,而 Evo 2 能一次性"通读"100 万个碱基。这让它不仅能看清单个基因,还能理解基因之间相隔几十万碱基的"远程对话"——而这正是调控基因表达的关键。
它真的"懂"生物学吗?让它考个试
研究团队设计了一系列"生物学期末考"来检验 Evo 2。
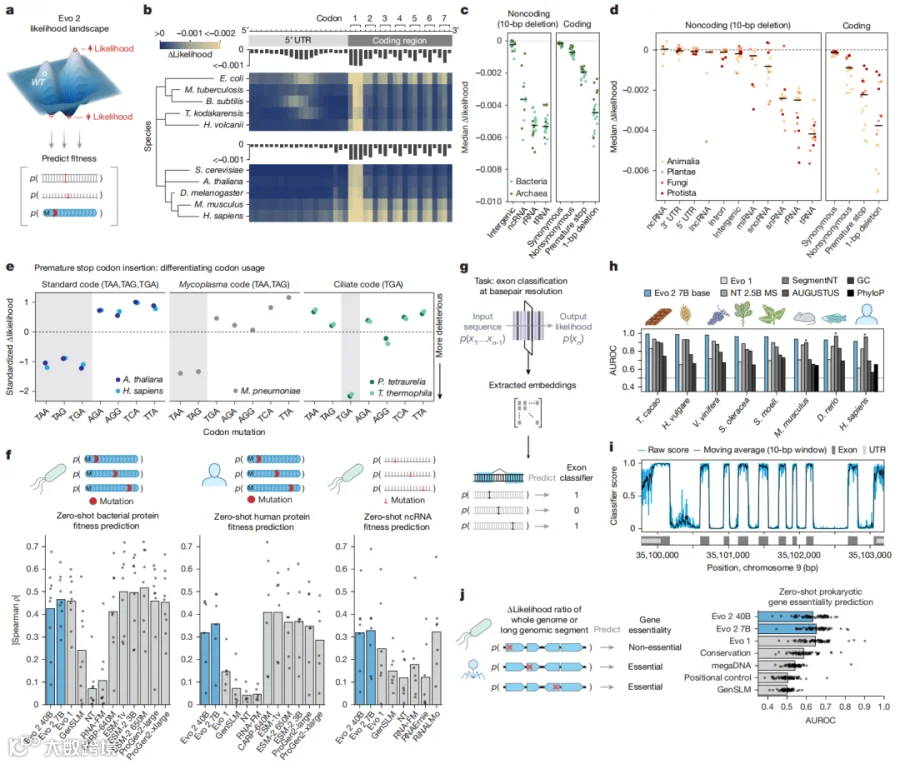
Evo 2 被要求在基因起始密码子附近引入随机突变,然后打分。结果它展现出了惊人的生物学直觉:
-
起始密码子本身突变 → 分数暴跌(知道这里不能乱动)
-
同义突变(不改变氨基酸)→ 分数波动小(知道这是"软柿子")
-
无义突变/移码突变 → 分数暴跌(知道这会搞砸蛋白质)
-
密码子第三位摇摆碱基 → 分数波动最小(懂沃布尔假说!)
更绝的是,它还能区分不同生物的"遗传密码方言"——比如支原体只用 TAA 和 TAG 作终止密码子,而纤毛虫用 TGA。当你把纤毛虫基因组人工改成标准密码时,Evo 2 会立刻"抗议":这些突变是有害的!
研究人员让 Evo 2 预测一个基因对细菌/古菌生存是否"必需"。结果它零样本(zero-shot)就能准确判断,而且比专门训练的其他模型表现更好。
Evo 2 的嵌入向量被用来训练一个简单的外显子分类器。在 8 个不同物种的测试集上,AUROC 达到 0.91–0.99,超过了经典基因注释工具 AUGUSTUS,也打败了其他 DNA 语言模型。
结论:Evo 2 不是死记硬背,它真的学会了生物学的底层逻辑。
最实用的能力:预判你的基因突变是好是坏
对普通人来说,Evo 2 最激动人心的应用可能是疾病突变预测。
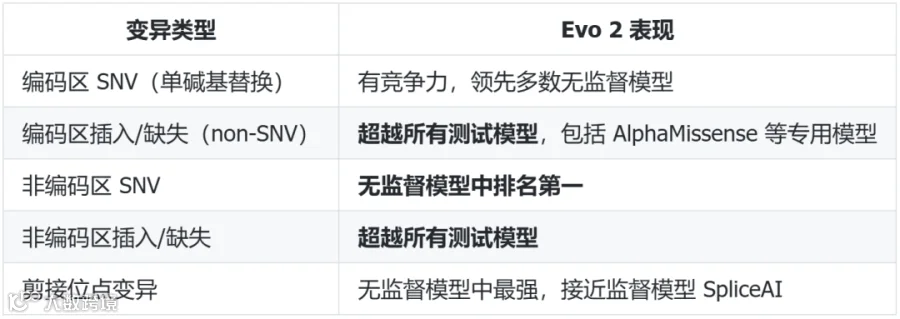
研究人员用 ClinVar(人类疾病变异数据库)测试 Evo 2 区分"致病突变"和"良性突变"的能力:
BRCA1 是与乳腺癌高度相关的基因。研究人员用 Evo 2 预测 BRCA1 上每一个可能的突变是否有害。结果:
零样本预测就能很好地区分"功能丧失"和"功能正常"的变异;
若用 Evo 2 的嵌入向量训练一个简单的监督分类器,AUROC 达到 0.95,AUPRC 达到 0.88——远超现有方法。
这意味着什么?未来,当一个普通人做完基因检测,Evo 2 可能在几分钟内告诉你:"这个突变此前没见过,但根据我对 9.3 万亿碱基的学习,它大概率是无害的。"——或者相反。
打开黑箱:我们第一次看清了 AI 脑子里的"生物学概念"
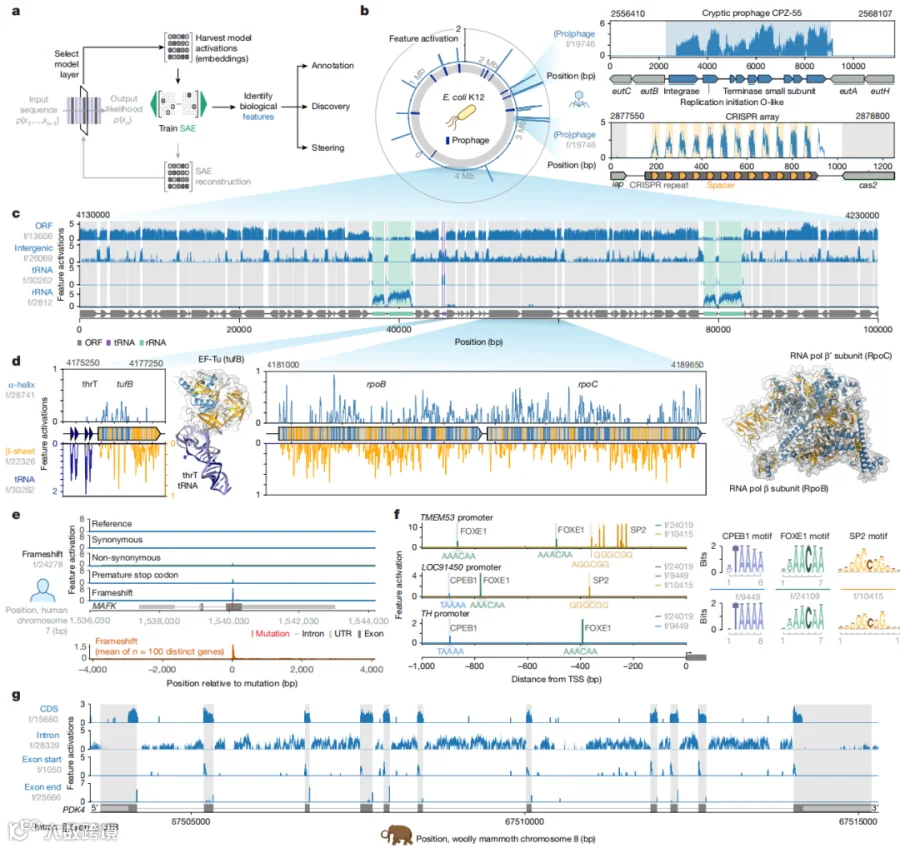
大语言模型常被诟病为"黑箱"。但研究团队用稀疏自编码器(SAE)打开了 Evo 2 的大脑,发现了令人震惊的事实:
Evo 2 自己学会了大量人类可理解的生物学概念,而且完全没有看过任何人工注释!
-
特征 f/19746:专门识别噬菌体/前噬菌体区域,还能识别 CRISPR 阵列中的间隔序列(因为它知道这些片段来自外源入侵者);
-
特征 f/28741 / f/22326:分别对应蛋白质的 α-螺旋 和 β-折叠;
-
特征 f/24278:对移码突变和提前终止密码子极度敏感——相当于 Evo 2 内部的"质量警报器";
-
特征 f/10415, f/24019:识别人类转录因子结合位点,匹配已知基序(如 FOXE1、SP2、MAFK)。
更有趣的是,这些特征具有跨物种泛化能力。研究人员用大肠杆菌和人类基因组训练 SAE,结果发现同样的特征在已灭绝的猛犸象基因组上也能准确识别外显子和内含子边界。
这暗示了一个深刻的事实:生命共享着某种普适的语法,而 Evo 2 捕捉到了它。
从"读"到"写":Evo 2 开始设计基因组了
如果说预测突变是"阅读理解",那生成新序列就是"命题作文"。Evo 2 的作文能力如何?
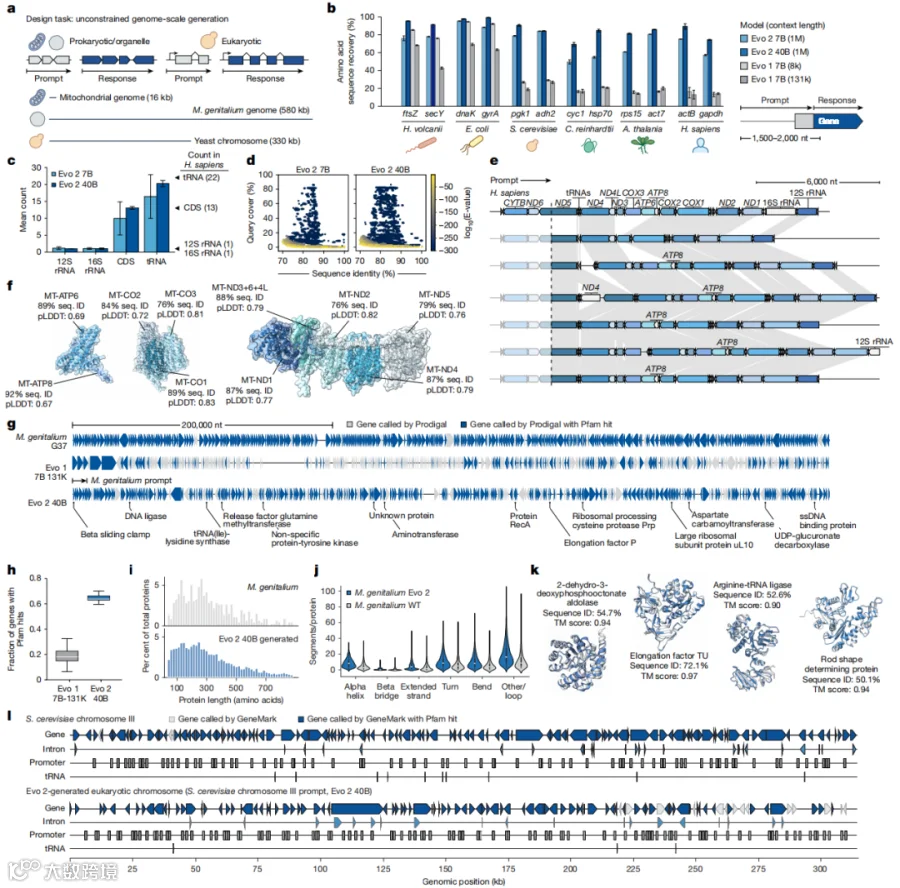
给定一小段人类线粒体 DNA 作为开头,Evo 2 生成了完整的 16 kb 线粒体序列。结果:
-
正确生成了全部 13 个蛋白编码基因、22 个 tRNA、2 个 rRNA;
-
-
-
生成的蛋白质能用 AlphaFold 3 折叠出有意义的结构。
支原体 M. genitalium 是已知能独立生存的最小生命体之一,基因组约 580 kb。Evo 2 生成了 10 条完整序列,其中近 70% 的基因能找到与天然蛋白显著相似的 Pfam 结构域——比 Evo 1 的 18% 大幅提升。
Evo 2 还生成了真核生物尺度的序列——以酿酒酵母 III 号染色体为 prompt,生成了包含基因、内含子、启动子和 tRNA 的 330 kb 序列。
当然,论文坦诚地指出:这些序列在"看起来像真的"方面已很出色,但还不能保证放入细胞后一定能活。从"像真的"到"就是真的",还有实验验证的长路要走。
最酷的实验:用 DNA 写"摩斯电码"
研究团队做了一件浪漫又硬核的事:他们让 Evo 2 设计具有特定染色质开放模式的 DNA 序列。
染色质可及性(chromatin accessibility)决定了基因能否被读取。研究人员想要 DNA 上的某些区域"开放"(accessible),某些区域"关闭"(inaccessible),而且这些开放区域的位置和宽度可控。
他们用 Evo 2 生成序列,再用 Enformer/Borzoi(预测染色质状态的模型)作为"裁判"打分,通过 beam search 不断优化。最终设计的序列被合成出来,通过位点特异性整合插入小鼠胚胎干细胞和人类细胞系,然后用 ATAC-seq 实测。
实验测得的染色质开放图谱与设计目标高度吻合,AUROC 达到 0.92–1.00。
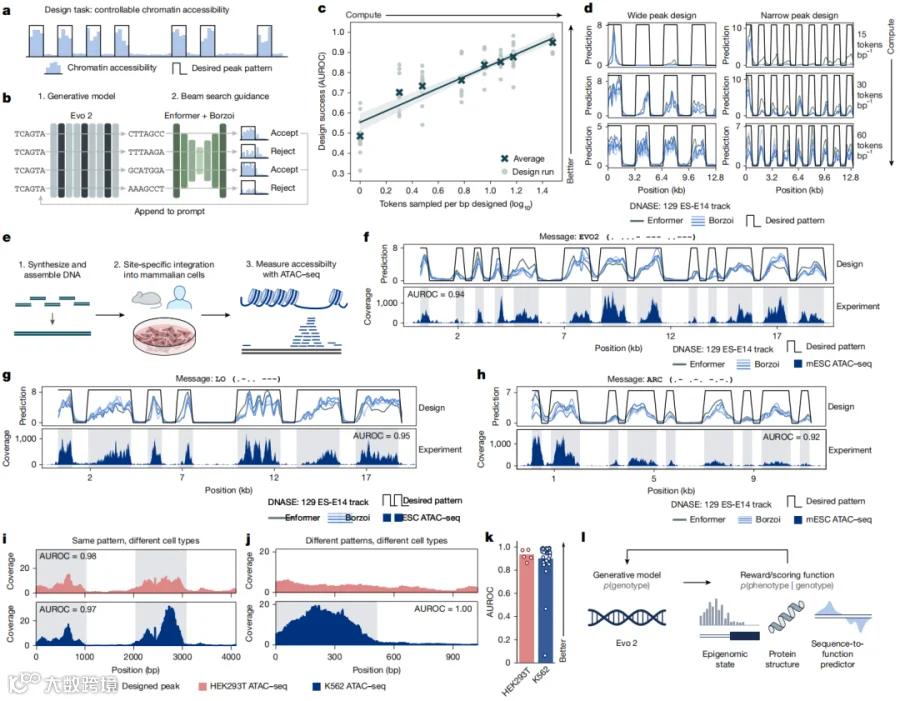 为了展示这种精确的控制力,研究人员把开放峰设计成了摩斯电码:
为了展示这种精确的控制力,研究人员把开放峰设计成了摩斯电码:
-
-
"LO" ——互联网历史上发送的第一个单词(也是 Edmund Spenser《仙后》的开篇词)
-
"ARC" ——进行这项研究的 Arc Institute
是的,他们真的在活细胞的 DNA 里用表观遗传标记写下了 "Evo 2"。
安全吗?一个负责任的开源故事
Evo 2 完全开源,这既是福音,也带来生物安全担忧。团队做了几件重要的事:
-
训练数据排除了感染真核生物的病毒(包括人类病毒)。如果试图让 Evo 2 生成人类病毒蛋白,输出基本是随机的;
-
红队测试:邀请多学科专家尝试"攻击"模型,检验其生成有害序列的能力;
-
人群偏倚评估:证明模型设计减轻了对不同祖先人群的预测偏倚;
-
与 Responsible AI × Biodesign 承诺对齐,在开放前完成风险评估。
论文也坦承:没有任何安全措施是完美的,后续研究和治理框架仍需不断完善。
结语:可编程生物学的黎明
Evo 2 的意义,绝不仅仅是"又一个更大的生物 AI 模型"。
第一,统一尺度的生物学理解。 Evo 2 用同一种表征同时理解 DNA、RNA 和蛋白质,从单个核苷酸到百万碱基的染色体,从细菌到人类。生物学不同尺度之间的壁垒,第一次被同一个神经网络打通了。
第二,从"读基因组"到"写基因组"。 测序技术让我们读取生命密码,CRISPR 让我们编辑个别字符,而 Evo 2 让我们开始从头起草全新的章节。虽然距离"设计一个活细胞"还很远,但方向已经明确。
第三,开放科学的标杆。 在 AI 大模型 increasingly closed 的当下,Evo 2 选择完全开源——模型、代码、数据、可视化工具全部公开。这让全世界的科学家都能站在 9.3 万亿碱基的肩膀上,探索自己感兴趣的问题。
"Evo系列模型为生物建模与设计奠定了基础,它用统一的表征将生物学不同尺度上的多样性联系起来。这些能力,结合大规模 DNA 操作技术,可能使更复杂生物功能的可编程设计成为现实。"
也许再过十年回望,2026 年 Evo 2 发表的那一天,会被视为可编程生物学元年的起点。
Brixi, G., Durrant, M.G., Ku, J. et al. Genome modelling and design across all domains of life with Evo 2. Nature (2026). https://doi.org/10.1038/s41586-026-10176-5
-
模型与代码:https://github.com/ArcInstitute/evo2
-
在线设计工具:https://arcinstitute.org/tools/evo/evo-designer
-
可解释性可视化:https://arcinstitute.org/tools/evo/evo-mech-interp
本文基于 Nature 2026 年发表的 Evo 2 研究论文撰写,力求准确通俗。如需进一步探讨,欢迎留言。