
Context engineering 指的是在给 AI 分配任务之前,为它创建合适的运行设置。这个设置包括:
关于 AI 应该如何行动的 Instructions,例如充当一位乐于助人的低预算旅行指南。
从数据库、文档或实时来源获取 useful info 的能力。
记住 past conversations,避免重复或遗忘。
AI 可以使用的 Tools,例如计算器或搜索功能。
关于你的重要信息,例如你的 preferences 或所在位置。
AI engineers are now shifting from prompt engineering to context engineering,因为……
Context Engineering 关注的是为 AI 提供正确的背景信息和工具,使它的回答更智能、更有用。
在这篇博客中,我们将探讨如何使用 LangChain 和 LangGraph 这两个用于构建 AI agents、RAG apps 和 LLM apps 的强大工具,有效实现 contextual engineering,从而改进我们的 AI Agents。
所有代码都可以在这个 GitHub Repo 中找到:
https://github.com/FareedKhan-dev/contextual-engineering-guide
Table of Contents
- Table of Contents
- 什么是 Context Engineering?
- 使用 LangGraph 实现 Scratchpad
- 创建 StateGraph
- LangGraph 中的 Memory Writing
- Scratchpad Selection Approach
- Memory Selection Ability
- LangGraph BigTool Calling 的优势
- 基于 Contextual Engineering 的 RAG
- 使用 knowledgeable Agents 的 Compression Strategy
- 使用 Sub-Agents Architecture 隔离 Context
- 使用 Sandboxed Environments 实现 Isolation
- LangGraph 中的 State Isolation
- 总结
什么是 Context Engineering?
LLMs 就像一种新型操作系统。LLM 类似 CPU,而它的 context window 类似 RAM,作为短期记忆使用。但就像 RAM 一样,context window 用来存放各种信息的空间是有限的。
就像操作系统决定哪些内容进入 RAM 一样,“context engineering” 关注的是选择 LLM 应该在 context 中保留哪些内容。
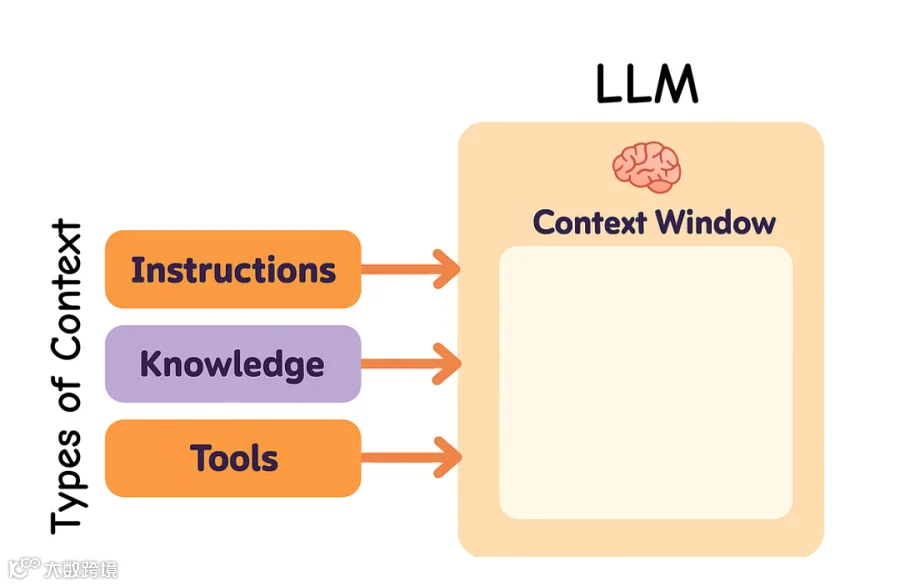
在构建 LLM 应用时,我们需要管理不同类型的 context。Context engineering 主要涵盖以下几类:
Instructions:prompts、examples、memories 和 tool descriptions
Knowledge:facts、stored information 和 memories
Tools:来自 tool calls 的 feedback 和 results
今年,越来越多人开始关注 agents,因为 LLMs 在推理和使用工具方面变得更强。Agents 会结合 LLMs 和 tools 来执行长期任务,并根据 tool 的反馈选择下一步。
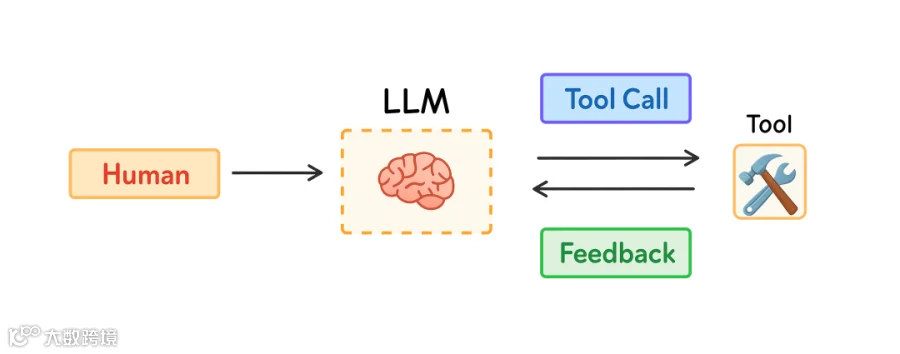
但长期任务以及从 tools 中收集过多反馈会消耗大量 tokens。这可能带来一些问题:context window 溢出、成本和延迟上升,agent 的表现也可能变差。
Drew Breunig 解释了过多 context 如何损害性能,包括:
Context Poisoning:当错误或 hallucination 被加入 context 时
Context Distraction:当过多 context 让模型困惑时
Context Confusion:当额外且不必要的细节影响答案时
Context Clash:当 context 中的不同部分给出冲突信息时
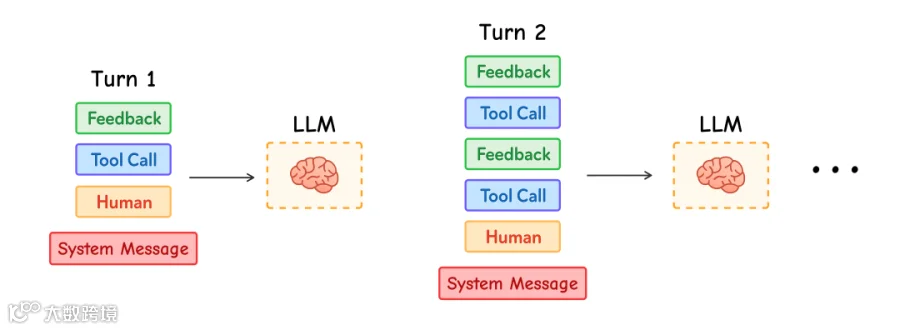
Anthropic 在其研究中 强调了这一点的重要性:
Agents 经常会进行数百轮对话,因此谨慎管理 context 至关重要。
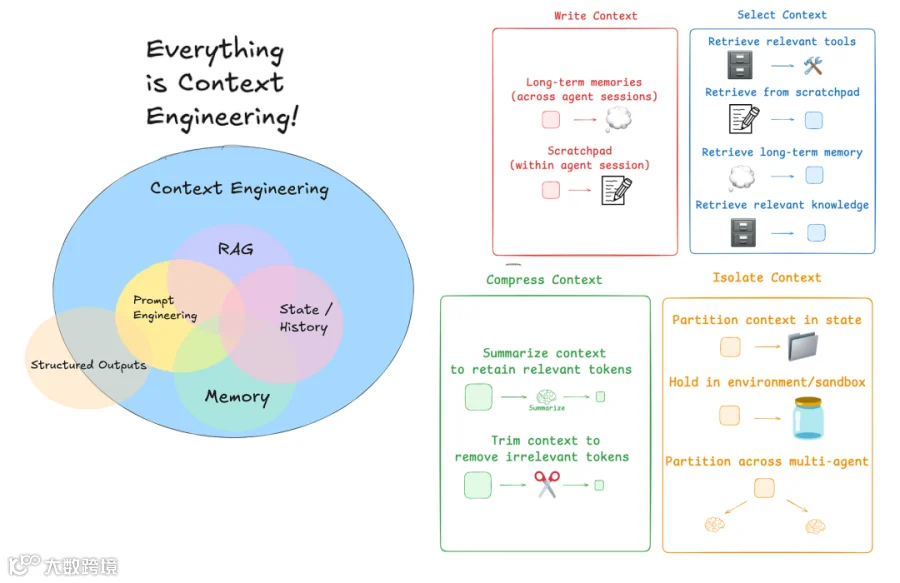
那么,如今人们是如何解决这个问题的?常见的 agent context engineering 策略可以分为四大类:
Write:创建清晰且有用的 context
Select:只选择最相关的信息
Compress:压缩 context 以节省空间
Isolate:将不同类型的 context 分离开来
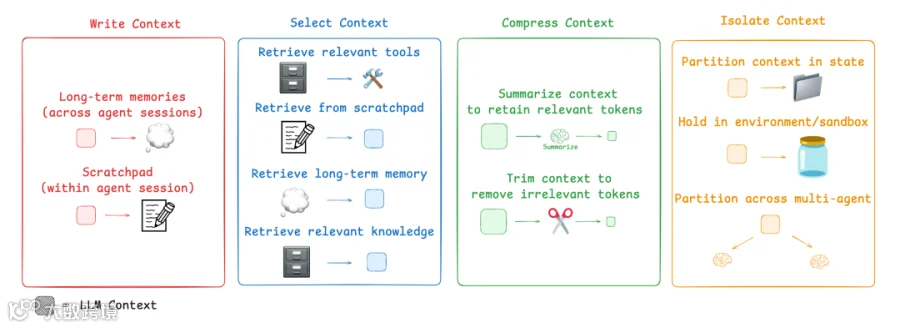
[LangGraph](https://www.langchain.com/langgraph) 被设计为支持所有这些策略。我们将逐一了解 LangGraph 中的这些组件,并看看它们如何帮助我们的 AI agents 更好地工作。
使用 LangGraph 实现 Scratchpad
就像人类会做笔记来记住之后任务需要的信息一样,agents 也可以使用 scratchpad 做类似的事。它将信息存储在 context window 之外,以便 agent 在需要时访问。
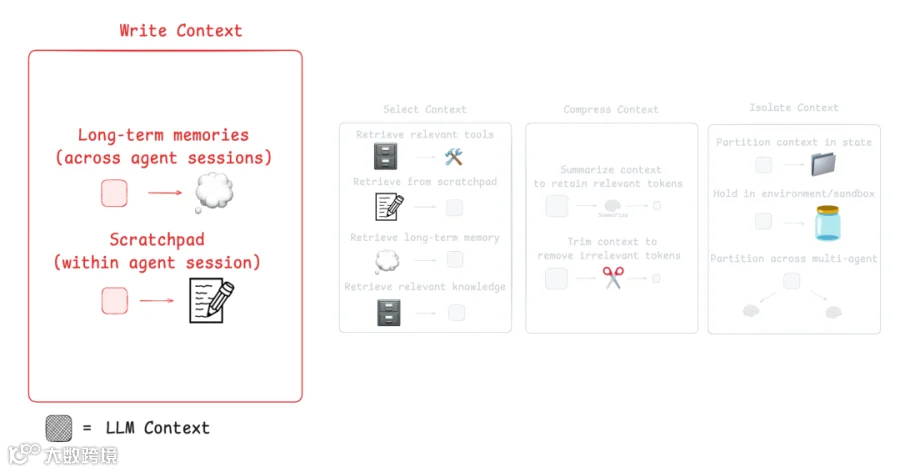
一个很好的例子是 Anthropic multi-agent researcher:
LeadResearcher 会规划自己的方法并将其保存到 memory 中,因为如果 context window 超过 200,000 tokens,就会被截断;保存计划可以确保它不会丢失。
Scratchpads 可以通过不同方式实现:
作为一个 tool call,用于写入文件。
作为 runtime state object 中的一个字段,在 session 期间持续存在。
简而言之,scratchpads 帮助 agents 在 session 中保留重要笔记,从而更有效地完成任务。
在 LangGraph 中,它同时支持 short-term(thread-scoped)和 long-term memory。
-
Short-term memory 使用 checkpointing 在 session 中保存 agent state。它的作用类似 scratchpad,让你可以在 agent 运行时存储信息,并在之后检索。
state object 是图节点之间传递的主要结构。你可以定义它的格式,通常是 Python dictionary。它相当于一个共享 scratchpad,每个 node 都可以读取和更新指定字段。
我们只会在需要时导入模块,这样可以一步一步清晰地学习。
为了获得更好、更干净的输出,我们将使用 Python 的 pprint module 进行美化打印,并使用 rich library 中的 Console module。首先导入并初始化它们:
# Import necessary libraries
from typing import TypedDict # For defining the state schema with type hints
from rich.console import Console # For pretty-printing output
from rich.pretty import pprint # For pretty-printing Python objects
# Initialize a console for rich, formatted output in the notebook.
console = Console()
接下来,我们将为 state object 创建一个 TypedDict。
class State(TypedDict):
"""
Defines the structure of the state for our joke generator workflow.
"""
topic: str
joke: str
这个 state object 将存储 topic,以及我们要求 agent 根据给定 topic 生成的 joke。
创建 StateGraph
定义 state object 后,我们可以使用 StateGraph 将 context 写入其中。
StateGraph 是 LangGraph 用于构建有状态 agents or workflows 的核心工具。可以把它理解为一个 directed graph:
Nodes 是 workflow 中的步骤。每个 node 接收当前 state 作为输入,更新它,并返回更改。
Edges 连接 nodes,定义执行流程。流程可以是线性的、条件式的,甚至是循环的。
接下来,我们将:
通过从 Anthropic models 中选择模型,创建一个 chat model。
在 LangGraph workflow 中使用它。
import getpass
import os
from IPython.display import Image, display
from langchain.chat_models import init_chat_model
from langgraph.graph import END, START, StateGraph
from dotenv import load_dotenv
api_key = os.getenv("ANTHROPIC_API_KEY")
if not api_key:
raise ValueError("Missing ANTHROPIC_API_KEY in environment")
llm = init_chat_model("anthropic:claude-sonnet-4-20250514", temperature=0)
我们已经初始化了 Sonnet model。LangChain 通过 API 支持许多开源和闭源模型,因此你可以使用其中任意一种。
现在,我们需要创建一个函数,使用这个 Sonnet model 生成响应。
def generate_joke(state: State) -> dict[str, str]:
topic = state["topic"]
print(f"Generating a joke about: {topic}")
msg = llm.invoke(f"Write a short joke about {topic}")
return {"joke": msg.content}
这个函数只是返回一个包含生成响应(joke)的 dictionary。
现在,使用 StateGraph,我们可以轻松构建并编译 graph。接下来就这么做。
workflow = StateGraph(State)
workflow.add_node("generate_joke", generate_joke)
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", END)
chain = workflow.compile()
display(Image(chain.get_graph().draw_mermaid_png()))
现在我们可以执行这个 workflow。
joke_generator_state = chain.invoke({"topic": "cats"})
console.print("\n[bold blue]Joke Generator State:[/bold blue]")
pprint(joke_generator_state)
输出:
{
'topic': 'cats',
'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'
}
它返回的是一个 dictionary,本质上就是我们 agent 的 joke generation state。这个简单示例展示了如何将 context 写入 state。
你可以进一步了解 Checkpointing 如何保存和恢复 graph states,以及 Human-in-the-loop 如何在 workflow 中暂停并获取人工输入后再继续。
LangGraph 中的 Memory Writing
Scratchpads 帮助 agents 在单个 session 内工作,但有时 agents 需要跨多个 sessions 记住信息。
Reflexion 提出了 agents 在每一轮后进行反思,并复用自生成提示的想法。
Generative Agents 通过总结过去的 agent feedback 来创建 long-term memories。

这些思路如今已应用在 ChatGPT、Cursor 和 Windsurf 等产品中,它们会从用户交互中自动创建 long-term memories。
Checkpointing 会在一个 thread 的每一步保存 graph state。一个 thread 有唯一 ID,通常代表一次交互,例如 ChatGPT 中的一次聊天。
Long-term memory 允许你跨 threads 保留特定 context。你可以保存 individual files(例如用户画像)或 memories 的 collections。
它使用 BaseStore interface,也就是 key-value store。你可以在内存中使用它,也可以与 LangGraph Platform deployments 搭配使用。
现在,让我们创建一个 InMemoryStore,用于在这个 notebook 的多个 sessions 中共享。
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("rlm", "joke_generator")
store.put(
namespace,
"last_joke",
{"joke": joke_generator_state["joke"]},
)
我们将在下一节讨论如何从 namespace 中选择 context。目前,我们可以使用 search method 查看 namespace 中的 items,并确认已经成功写入。
stored_items = list(store.search(namespace))
console.print("\n[bold green]Stored Items in Memory:[/bold green]")
pprint(stored_items)
输出中可以看到,我们成功保存了上一次生成的 joke。
现在,让我们把刚才做的内容嵌入到一个 LangGraph workflow 中。
我们将使用两个参数编译 workflow:
checkpointer:在 thread 中保存每一步 graph state。store:跨不同 threads 保存 context。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
checkpointer = InMemorySaver()
memory_store = InMemoryStore()
defgenerate_joke(state: State, store: BaseStore) -> dict[str, str]:
existing_jokes = list(store.search(namespace))
if existing_jokes:
existing_joke = existing_jokes[0].value
print(f"Existing joke: {existing_joke}")
else:
print("Existing joke: No existing joke")
msg = llm.invoke(f"Write a short joke about {state['topic']}")
store.put(namespace, "last_joke", {"joke": msg.content})
return {"joke": msg.content}
workflow = StateGraph(State)
workflow.add_node("generate_joke", generate_joke)
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", END)
chain = workflow.compile(checkpointer=checkpointer, store=memory_store)
很好!现在我们可以直接执行更新后的 workflow,并测试启用 memory 功能后的效果。
config = {"configurable": {"thread_id": "1"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
console.print("\n[bold cyan]Workflow Result (Thread 1):[/bold cyan]")
pprint(joke_generator_state)
由于这是 thread 1,我们的 AI agent memory 中还没有已保存的 joke,这正符合新 thread 的预期。
因为我们使用 checkpointer 编译了 workflow,所以现在可以查看 graph 的 latest state。
latest_state = chain.get_state(config)
console.print("\n[bold magenta]Latest Graph State (Thread 1):[/bold magenta]")
pprint(latest_state)
你可以看到,state 现在展示了我们与 agent 最近一次对话的结果,也就是我们让它讲一个关于 cats 的笑话。
接下来用不同 ID 重新运行 workflow。
config = {"configurable": {"thread_id": "2"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
console.print("\n[bold yellow]Workflow Result (Thread 2):[/bold yellow]")
pprint(joke_generator_state)
我们可以看到,来自第一个 thread 的 joke 已成功保存到 memory 中。
你可以进一步了解 LangMem 的 memory abstractions,以及 Ambient Agents Course 中关于 LangGraph agents memory 的概览。
Scratchpad Selection Approach
如何从 scratchpad 中选择 context 取决于它的实现方式:
如果它是一个 tool,agent 可以通过 tool call 直接读取它。
如果它是 agent runtime state 的一部分,那么你作为 developer 可以决定在每一步向 agent 共享 state 的哪些部分。这可以让你精细控制暴露哪些 context。
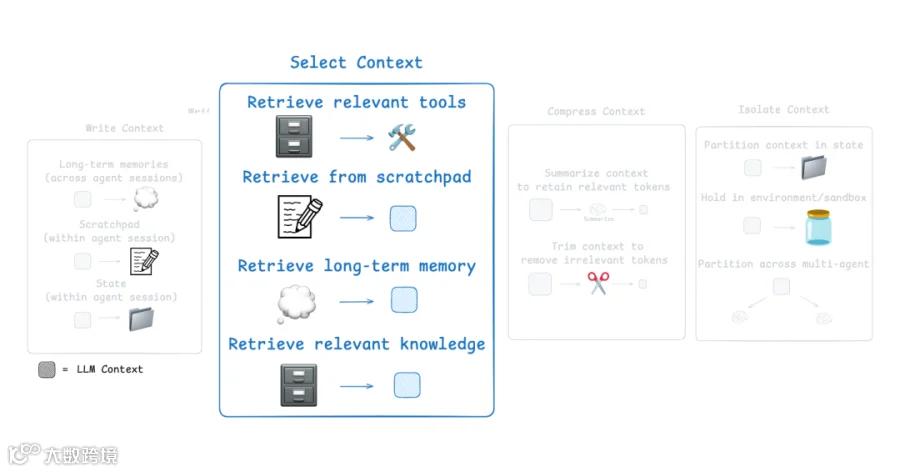
在上一步中,我们学习了如何写入 LangGraph state object。现在,我们将学习如何从 state 中选择 context,并将其传递给下游 node 中的 LLM call。
这种选择性方法允许你精确控制 LLM 在执行过程中能看到哪些 context。
def generate_joke(state: State) -> dict[str, str]:
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def improve_joke(state: State) -> dict[str, str]:
print(f"Initial joke: {state['joke']}")
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}
为了稍微增加复杂度,我们现在给 agent 添加两个 workflows:
Generate Joke:和之前一样。
Improve Joke:接收生成的 joke,并对其进行改进。
这个设置将帮助我们理解 LangGraph 中的 scratchpad selection 是如何工作的。现在,让我们像之前一样编译 workflow,并看看 graph 的结构。
workflow = StateGraph(State)
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", "improve_joke")
workflow.add_edge("improve_joke", END)
chain = workflow.compile()
display(Image(chain.get_graph().draw_mermaid_png()))
执行这个 workflow 后,我们会得到结果。
joke_generator_state = chain.invoke({"topic": "cats"})
console.print("\n[bold blue]Final Workflow State:[/bold blue]")
pprint(joke_generator_state)
现在我们已经执行了 workflow,接下来可以进入 memory selection 步骤。
Memory Selection Ability
如果 agents 可以保存 memories,它们也需要为当前任务选择相关 memories。这对以下内容很有用:
Episodic memories:作为 few-shot examples,展示期望行为。
Procedural memories:用于指导行为的 instructions。
Semantic memories:提供任务相关 context 的 facts 或 relationships。
有些 agents 使用范围较窄、预定义的文件来存储 memories:
Claude Code 使用
[CLAUDE.md](http://claude.md/)。Cursor 和 Windsurf 使用 “rules” 文件来保存 instructions 或 examples。
但当存储大量 facts(semantic memories)的 collection 时,selection 会变得更困难。
ChatGPT 有时会检索到不相关的 memories。正如 Simon Willison 所展示的,ChatGPT 错误地获取了他的位置信息,并将其注入到图像中,让 context 感觉“已经不再属于他”。
为了改进 selection,通常会使用 embeddings 或 knowledge graphs 来进行 indexing。
在上一节中,我们在 graph nodes 中写入了 InMemoryStore。现在,我们可以使用 get method 从中选择 context,并将相关 state 拉入 workflow。
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("rlm", "joke_generator")
store.put(
namespace,
"last_joke",
{"joke": joke_generator_state["joke"]}
)
retrieved_joke = store.get(namespace, "last_joke").value
console.print("\n[bold green]Retrieved Context from Memory:[/bold green]")
pprint(retrieved_joke)
它成功从 memory 中检索到了正确的 joke。
现在,我们需要编写一个合适的 generate_joke function,它能够:
接收当前 state,作为 scratchpad context。
使用 memory,在执行 joke improvement 任务时获取过去的 jokes。
接下来编写代码。
checkpointer = InMemorySaver()
memory_store = InMemoryStore()
defgenerate_joke(state: State, store: BaseStore) -> dict[str, str]:
prior_joke = store.get(namespace, "last_joke")
if prior_joke:
prior_joke_text = prior_joke.value["joke"]
print(f"Prior joke: {prior_joke_text}")
else:
print("Prior joke: None!")
prompt = (
f"Write a short joke about {state['topic']}, "
f"but make it different from any prior joke you've written: {prior_joke_text if prior_joke else 'None'}"
)
msg = llm.invoke(prompt)
store.put(namespace, "last_joke", {"joke": msg.content})
return {"joke": msg.content}
现在,我们可以像之前一样执行这个 memory-aware workflow。
workflow = StateGraph(State)
workflow.add_node("generate_joke", generate_joke)
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", END)
chain = workflow.compile(checkpointer=checkpointer, store=memory_store)
config = {"configurable": {"thread_id": "1"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
没有检测到 prior joke。现在可以打印最新的 state structure。
latest_state = chain.get_state(config)
console.print("\n[bold magenta]Latest Graph State:[/bold magenta]")
pprint(latest_state)
我们从 memory 中获取前一个 joke,并将它传给 LLM 来改进它。
config = {"configurable": {"thread_id": "2"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
它成功地 从 memory 中获取了正确的 joke,并按预期进行了 改进。
LangGraph BigTool Calling 的优势
Agents 会使用 tools,但给它们太多 tools 可能导致混乱,尤其是在 tool descriptions 互相重叠时。这会让模型更难选择正确的 tool。
一种解决方案是在 tool descriptions 上使用 RAG(Retrieval-Augmented Generation),根据 semantic similarity 只获取最相关的 tools。Drew Breunig 将这种方法称为 tool loadout。
根据 recent research,这种方法可以将 tool selection accuracy 提升最高 3 倍。
对于 tool selection,LangGraph Bigtool library 非常适合。它会基于 tool descriptions 执行 semantic similarity search,选择与任务最相关的 tools。它使用 LangGraph 的 long-term memory store,使 agents 能够为给定问题搜索并检索正确 tools。
让我们通过一个包含 Python 内置 math library 所有函数的 agent 来理解 langgraph-bigtool。
import math
all_tools = []
for function_name indir(math):
function = getattr(math, function_name)
ifnotisinstance(
function, types.BuiltinFunctionType
):
continue
if tool := convert_positional_only_function_to_tool(
function
):
all_tools.append(tool)
我们首先将 Python math module 中的所有函数加入一个 list。接下来,需要将这些 tool descriptions 转换为 vector embeddings,以便 agent 可以执行 semantic similarity searches。
为此,我们将使用 embedding model,这里使用 OpenAI text-embedding model。
tool_registry = {
str(uuid.uuid4()): tool
for tool in all_tools
}
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(
index={
"embed": embeddings,
"dims": 1536,
"fields": ["description"],
}
)
for tool_id, tool in tool_registry.items():
store.put(
("tools",),
tool_id,
{
"description": f"{tool.name}: {tool.description}",
},
)
每个函数都会被分配一个唯一 ID,并被组织为标准化格式。这个结构化格式确保函数可以轻松转换为 embeddings,用于 semantic search。
现在,让我们可视化 agent,看看所有 math functions 都已 embedded 并准备好进行 semantic search 后的样子。
builder = create_agent(llm, tool_registry)
agent = builder.compile(store=store)
agent
现在,我们可以用一个简单 query 调用 agent,并观察这个 tool-calling agent 如何选择并使用最相关的 math functions 来回答问题。
from utils import format_messages
query = "Use available tools to calculate arc cosine of 0.5."
result = agent.invoke({"messages": query})
format_messages(result['messages'])
你可以看到,我们的 AI agent 非常高效地调用了正确的 tool。你可以进一步了解:
Toolshed:提出 Toolshed Knowledge Bases 和 Advanced RAG-Tool Fusion,以改善 AI agents 的 tool selection。
Graph RAG-Tool Fusion:结合 vector retrieval 和 graph traversal 来捕获 tool dependencies。
LLM-Tool-Survey:关于 LLMs tool learning 的综合调研。
ToolRet:用于评估和改进 LLMs tool retrieval 的 benchmark。
基于 Contextual Engineering 的 RAG
RAG(Retrieval-Augmented Generation) 是一个非常大的主题,而 code agents 是生产环境中 agentic RAG 的最佳示例之一。
在实践中,RAG 往往是 context engineering 的核心挑战。正如 Varun from Windsurf 所指出的:
Indexing ≠ context retrieval。结合 AST-based chunking 的 embedding search 是有效的,但随着 codebases 增长会失效。我们需要 hybrid retrieval:grep/file search、knowledge-graph linking,以及基于 relevance 的 re-ranking。
LangGraph 提供了 tutorials and videos 来帮助将 RAG 集成到 agents 中。通常,你会构建一个 retrieval tool,它可以组合使用上述任意 RAG 技术。
为了演示,我们将使用 Lilian Weng 优秀博客中最近的几篇文章,为 RAG system 获取 documents。
首先使用 WebBaseLoader utility 拉取页面内容。
from langchain_community.document_loaders import WebBaseLoader
urls = [
"https://lilianweng.github.io/posts/2025-05-01-thinking/",
"https://lilianweng.github.io/posts/2024-11-28-reward-hacking/",
"https://lilianweng.github.io/posts/2024-07-07-hallucination/",
"https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",
]
docs = [WebBaseLoader(url).load() for url in urls]
RAG 有不同的数据 chunking 方式,而合适的 chunking 对有效 retrieval 至关重要。
这里,我们将在将 documents indexing 到 vectorstore 之前,把它们分成更小的 chunks。我们将使用一种简单直接的方法,例如带 overlap segments 的 recursive chunking,以在 chunks 间保留 context,同时保持每个 chunk 适合 embedding 和 retrieval。
from langchain_text_splitters import RecursiveCharacterTextSplitter
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=2000, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
现在我们已经有了 split documents,可以将它们 indexing 到 vector store 中,用于 semantic search。
from langchain_core.vectorstores import InMemoryVectorStore
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits, embedding=embeddings
)
retriever = vectorstore.as_retriever()
我们需要创建一个 retriever tool,供 agent 使用。
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"Search and return information about Lilian Weng blog posts.",
)
现在,我们可以实现一个能够从 tool 中选择 context 的 agent。
tools = [retriever_tool]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
对于基于 RAG 的解决方案,我们需要创建清晰的 system prompt 来指导 agent 的行为。这个 prompt 是它的核心 instruction set。
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, ToolMessage
from typing_extensions import Literal
rag_prompt = """You are a helpful assistant tasked with retrieving information from a series of technical blog posts by Lilian Weng.
Clarify the scope of research with the user before using your retrieval tool to gather context. Reflect on any context you fetch, and
proceed until you have sufficient context to answer the user's research request."""
接下来,我们定义 graph 的 nodes。我们需要两个主要 nodes:
llm_call:这是 agent 的大脑。它接收当前 conversation history(user query + previous tool outputs),然后决定下一步是 call a tool 还是生成 final answer。tool_node:这是 agent 的执行部分。它执行llm_call请求的 tool call,并将 tool result 返回给 agent。
def llm_call(state: MessagesState):
messages_with_prompt = [SystemMessage(content=rag_prompt)] + state["messages"]
response = llm_with_tools.invoke(messages_with_prompt)
return {"messages": [response]}
deftool_node(state: dict):
last_message = state["messages"][-1]
result = []
for tool_call in last_message.tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=str(observation), tool_call_id=tool_call["id"]))
return {"messages": result}
我们需要一种方式来控制 agent 的流程,即决定它应该 call a tool 还是已经完成。
为此,我们创建一个 conditional edge function,称为 should_continue。
这个函数检查 LLM 的最后一条 message 是否包含 tool call。
如果包含,graph 会路由到
tool_node。如果不包含,则 execution 结束。
def should_continue(state: MessagesState) -> Literal["Action", END]:
last_message = state["messages"][-1]
if last_message.tool_calls:
return "Action"
return END
现在,我们可以构建 workflow 并编译 graph。
agent_builder = StateGraph(MessagesState)
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("environment", tool_node)
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
"Action": "environment",
END: END,
},
)
agent_builder.add_edge("environment", "llm_call")
agent = agent_builder.compile()
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
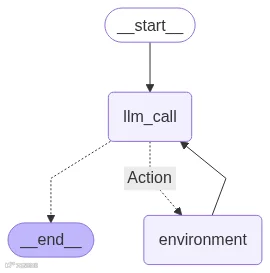
这个 graph 展示了一个清晰的循环:
agent 启动并调用 LLM。
根据 LLM 的决策,它要么执行 action(调用 retriever tool)并循环回来,要么结束并提供答案。
让我们测试 RAG agent。我们将询问一个关于 “reward hacking” 的具体问题,这个问题只能通过检索我们 indexed 的 blog posts 来回答。
query = "What are the types of reward hacking discussed in the blogs?"
result = agent.invoke({"messages": [("user", query)]})
format_messages(result['messages'])
正如你所见,agent 正确识别出自己需要使用 retrieval tool。随后,它成功从 blog posts 中检索相关 context,并用这些信息给出了详细且准确的答案。
这是一个非常好的例子,展示了如何通过 RAG 实现 contextual engineering,从而创建强大且知识丰富的 agents。
使用 knowledgeable Agents 的 Compression Strategy
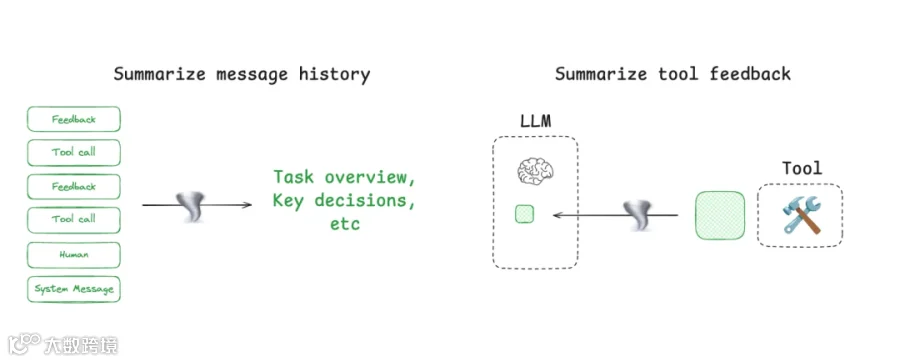
Agent interactions 可能跨越 hundreds of turns,并包含 token-heavy tool calls。Summarization 是管理这一问题的常用方式。
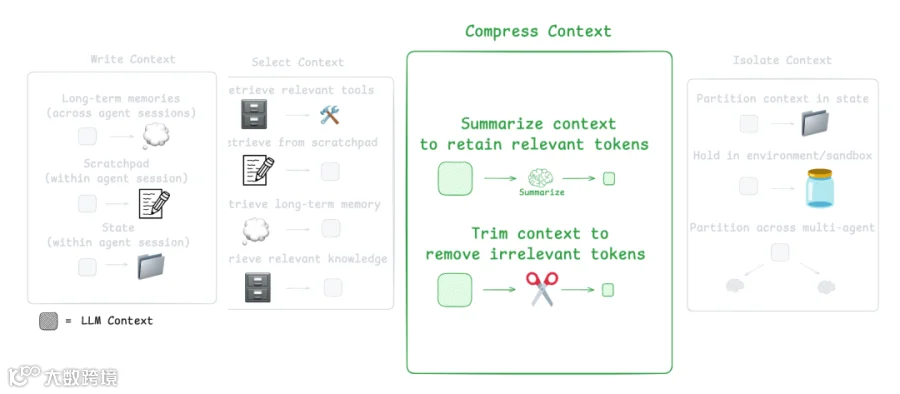
例如:
Claude Code 在 context window 超过 95% 时会使用 “auto-compact”,对整个 user-agent interaction history 进行 summarizing。
Summarization 可以使用 recursive 或 hierarchical summarization 等策略压缩 agent trajectory。
你也可以在特定位置添加 summarization:
在 token-heavy tool calls 之后,例如 search tools,这里有示例。
在 agent-agent boundaries 处进行 knowledge transfer。Cognition 在 Devin 中使用 fine-tuned model 做到了这一点。
LangGraph 是一个 low-level orchestration framework,让你可以完全控制:
将 agent 设计为一组 nodes。
在每个 node 中显式定义逻辑。
在 nodes 之间传递共享 state object。
这使得以不同方式压缩 context 变得很容易。例如,你可以:
使用 message list 作为 agent state。
使用 built-in utilities 对其进行 summarization。
我们将使用之前编码的同一个基于 RAG 的 tool-calling agent,并为其 conversation history 添加 summarization。
首先,需要扩展 graph state,加入一个用于最终 summary 的字段。
class State(MessagesState):
"""Extended state that includes a summary field for context compression."""
summary: str
接下来,定义一个专门用于 summarization 的 prompt,同时保留之前的 RAG prompt。
summarization_prompt = """Summarize the full chat history and all tool feedback to
give an overview of what the user asked about and what the agent did."""
现在,创建一个 summary_node。
这个 node 会在 agent 工作结束时触发,用于生成整个 interaction 的简洁 summary。
llm_call和tool_node保持不变。
def summary_node(state: MessagesState) -> dict:
messages = [SystemMessage(content=summarization_prompt)] + state["messages"]
result = llm.invoke(messages)
return {"summary": result.content}
现在,conditional edge should_continue 需要决定是 call a tool,还是进入新的 summary_node。
def should_continue(state: MessagesState) -> Literal["Action", "summary_node"]:
last_message = state["messages"][-1]
if last_message.tool_calls:
return "Action"
return "summary_node"
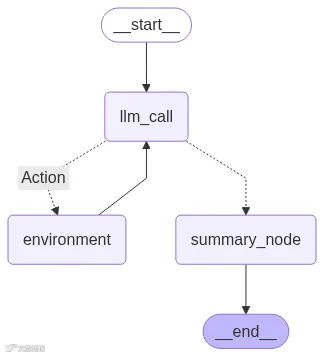
让我们构建一个在最后加入 summarization 步骤的 graph。
agent_builder = StateGraph(State)
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("Action", tool_node)
agent_builder.add_node("summary_node", summary_node)
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
"Action": "Action",
"summary_node": "summary_node",
},
)
agent_builder.add_edge("Action", "llm_call")
agent_builder.add_edge("summary_node", END)
agent = agent_builder.compile()
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
现在,让我们用一个需要获取大量 context 的 query 来运行它。
from rich.markdown import Markdown
query = "Why does RL improve LLM reasoning according to the blogs?"
result = agent.invoke({"messages": [("user", query)]})
format_message(result['messages'][-1])
Markdown(result["summary"])
效果不错,但它使用了 115k tokens!你可以在这里查看完整 trace。这是具有 token-heavy tool calls 的 agents 常见挑战。
更高效的方法是在 context 进入 agent 主 scratchpad 之前先进行压缩。让我们更新 RAG agent,使其能够即时总结 tool call output。
首先,为这个特定任务创建一个新的 prompt:
tool_summarization_prompt = """You will be provided a doc from a RAG system.
Summarize the docs, ensuring to retain all relevant / essential information.
Your goal is simply to reduce the size of the doc (tokens) to a more manageable size."""
接下来,修改 tool_node,加入 summarization step。
def tool_node_with_summarization(state: dict):
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
summary_msg = llm.invoke([
SystemMessage(content=tool_summarization_prompt),
("user", str(observation))
])
result.append(ToolMessage(content=summary_msg.content, tool_call_id=tool_call["id"]))
return {"messages": result}
现在,should_continue edge 可以简化,因为不再需要最终的 summary_node。
def should_continue(state: MessagesState) -> Literal["Action", END]:
if state["messages"][-1].tool_calls:
return "Action"
return END
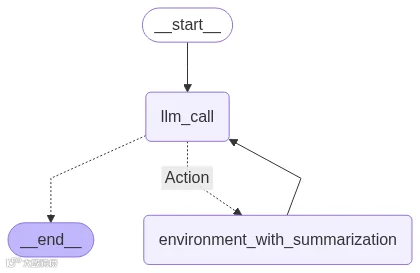
让我们构建并编译这个更高效的 agent。
agent_builder = StateGraph(MessagesState)
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("Action", tool_node_with_summarization)
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
"Action": "Action",
END: END,
},
)
agent_builder.add_edge("Action", "llm_call")
agent = agent_builder.compile()
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
让我们运行同样的 query,看看差异。
query = "Why does RL improve LLM reasoning according to the blogs?"
result = agent.invoke({"messages": [("user", query)]})
format_messages(result['messages'])
这一次,agent 只使用了 60k tokens。可以在这里查看 trace。
这个简单修改几乎将 token 使用量减半,使 agent 更高效、更具成本效益。
你可以进一步了解:
Heuristic Compression and Message Trimming:通过 trimming messages 管理 token limits,防止 context overflow。
SummarizationNode as Pre-Model Hook:在 ReAct agents 中总结 conversation history,以控制 token usage。
LangMem Summarization:通过 message summarization 和 running summaries 管理 long context 的策略。
使用 Sub-Agents Architecture 隔离 Context
隔离 context 的一种常见方式是将其拆分到 sub-agents 中。OpenAI 的 Swarm library 就是为这种 “separation of concerns” 设计的,其中每个 agent 负责一个特定 sub-task,并拥有自己的 tools、instructions 和 context window。
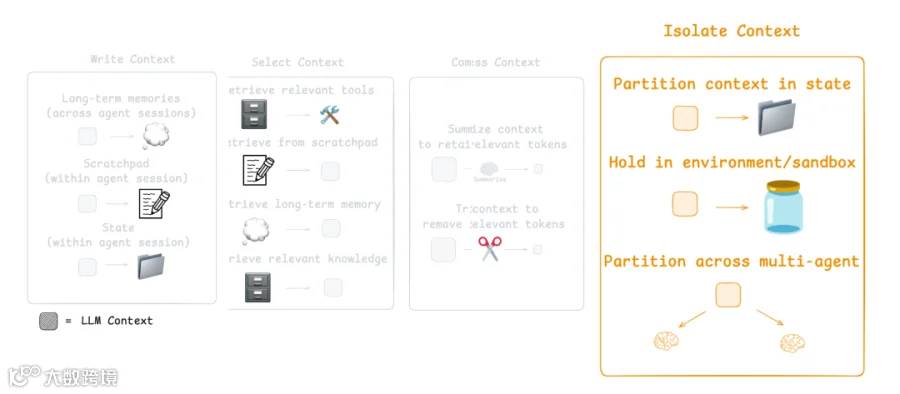
Anthropic 的 multi-agent researcher 表明,具有 isolated contexts 的多个 agents 比单个 agent 表现高出 90.2%,因为每个 sub-agent 都专注于范围更窄的 sub-task。
Subagents 会并行运行,并拥有自己的 context windows,同时探索问题的不同方面。
不过,multi-agent systems 也存在挑战:
token 使用量大幅增加,有时比 single-agent chat 多 15 倍。
需要仔细的 prompt engineering 来规划 sub-agent work。
协调 sub-agents 可能很复杂。
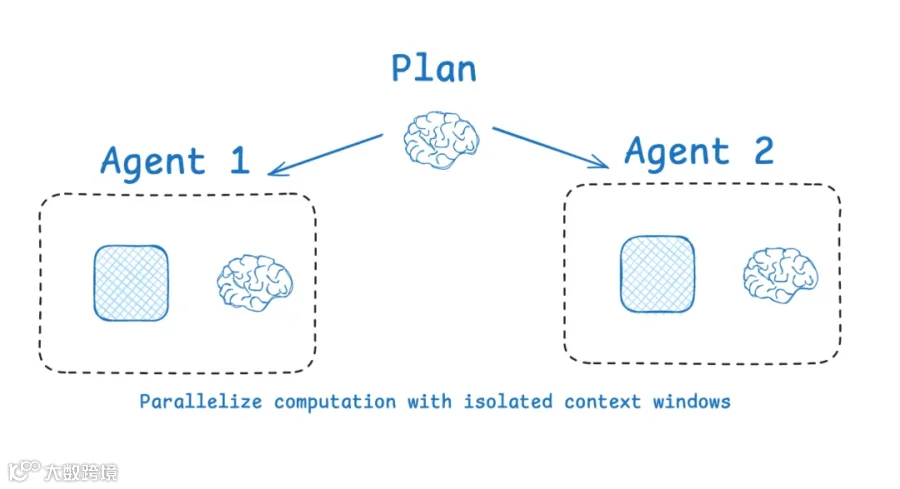
LangGraph 支持 multi-agent setups。常见方法是 supervisor architecture,Anthropic multi-agent researcher 也使用了这种架构。supervisor 会将任务委派给 sub-agents,而每个 sub-agent 都在自己的 context window 中运行。
让我们构建一个简单的 supervisor,管理两个 agents:
math_expert处理 mathematical calculations。research_expert搜索并提供 researched information。
supervisor 会根据 query 决定调用哪个 expert,并在 LangGraph workflow 中协调它们的 responses。
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisor
defadd(a: float, b: float) -> float:
"""Add two numbers."""
return a + b
defmultiply(a: float, b: float) -> float:
"""Multiply two numbers."""
return a * b
defweb_search(query: str) -> str:
"""Mock web search function that returns FAANG company headcounts."""
return (
"Here are the headcounts for each of the FAANG companies in 2024:\n"
"1. **Facebook (Meta)**: 67,317 employees.\n"
"2. **Apple**: 164,000 employees.\n"
"3. **Amazon**: 1,551,000 employees.\n"
"4. **Netflix**: 14,000 employees.\n"
"5. **Google (Alphabet)**: 181,269 employees."
)
现在,我们可以创建 specialized agents 和管理它们的 supervisor。
math_agent = create_react_agent(
model=llm,
tools=[add, multiply],
name="math_expert",
prompt="You are a math expert. Always use one tool at a time."
)
research_agent = create_react_agent(
model=llm,
tools=[web_search],
name="research_expert",
prompt="You are a world class researcher with access to web search. Do not do any math."
)
workflow = create_supervisor(
[research_agent, math_agent],
model=llm,
prompt=(
"You are a team supervisor managing a research expert and a math expert. "
"Delegate tasks to the appropriate agent to answer the user's query. "
"For current events or facts, use research_agent. "
"For math problems, use math_agent."
)
)
app = workflow.compile()
让我们执行 workflow,看看 supervisor 如何委派任务。
result = app.invoke({
"messages": [
{
"role": "user",
"content": "what's the combined headcount of the FAANG companies in 2024?"
}
]
})
format_messages(result['messages'])
这里,supervisor 正确地为每个任务隔离 context:将 research query 发送给 researcher,将 math problem 发送给 mathematician,展示了有效的 context isolation。
你可以进一步了解:
LangGraph Swarm:一个用于构建 multi-agent systems 的 Python library,支持 dynamic handoffs、memory 和 human-in-the-loop。
Videos on multi-agent systems:关于构建协作型 AI agents 的更多见解(video 2、video 3)。
使用 Sandboxed Environments 实现 Isolation
HuggingFace 的 deep researcher 展示了一种很酷的 context isolation 方法。大多数 agents 使用 tool calling APIs,返回 JSON arguments 来运行 search APIs 等 tools 并获取 results。
HuggingFace 使用 CodeAgent,由它编写代码来调用 tools。这些代码会在安全的 sandbox 中运行,代码执行结果再返回给 LLM。
这使得大量数据,如 images 或 audio,可以保留在 LLM token limit 之外。HuggingFace 解释说:
[Code Agents allow for] better handling of state ... Need to store this image/audio/other for later? Just save it as a variable in your state and use it later.
在 LangGraph 中使用 sandboxes 很简单。LangChain Sandbox 使用 Pyodide(编译到 WebAssembly 的 Python)安全运行不可信 Python 代码。你可以将它作为 tool 加入任何 LangGraph agent。
注意: 需要安装 Deno。安装地址:https://docs.deno.com/runtime/getting_started/installation/
from langchain_sandbox import PyodideSandboxTool
from langgraph.prebuilt import create_react_agent
tool = PyodideSandboxTool(allow_net=True)
agent = create_react_agent(llm, tools=[tool])
result = await agent.ainvoke(
{"messages": [{"role": "user", "content": "what's 5 + 7?"}]},
)
format_messages(result['messages'])
LangGraph 中的 State Isolation
Agent 的 runtime state object 是另一种很好的 context isolation 方式,类似于 sandboxing。你可以使用 schema,例如 Pydantic model,来设计这个 state,并为存储 context 设置不同字段。
例如,一个字段(如 messages)会在每一轮展示给 LLM,而其他字段会将信息隔离保存,直到需要时才使用。
LangGraph 是围绕 state object 构建的,允许你创建自定义 state schema,并在整个 agent workflow 中访问其字段。
例如,你可以将 tool call results 存储在特定字段中,在必要之前不暴露给 LLM。你已经在这些 notebooks 中看到过许多这样的例子。
总结
让我们总结一下目前完成的内容:
我们使用 LangGraph
StateGraph创建了一个用于 short-term memory 的 “scratchpad”,并使用InMemoryStore实现 long-term memory,使 agent 能够存储并回忆信息。我们演示了如何从 agent state 和 long-term memory 中选择性地提取相关信息。这包括使用 Retrieval-Augmented Generation(
RAG)查找特定知识,以及使用langgraph-bigtool从大量 tools 中选择正确 tool。为了管理长对话和 token-heavy tool outputs,我们实现了 summarization。
我们展示了如何即时压缩
RAGresults,使 agent 更高效并减少 token usage。我们探索了如何保持 contexts 分离以避免混淆:通过构建带 supervisor 的 multi-agent system,将任务委派给 specialized sub-agents;以及使用 sandboxed environments 来运行代码。
所有这些技术都属于 “Contextual Engineering”:这是一种通过谨慎管理 AI agents 的 working memory(context)来提升其效率、准确性,并增强其处理复杂、长期运行任务能力的策略。