
给 Agent 同时接入 GUI 操作和工具调用能力,准确率反而可能下降。
模型往往无法在图形界面(GUI)与工具调用(Tool)之间做出正确抉择:该点击按钮时去调 API,该调 API 时却死磕菜单,导致执行路径混乱,任务成功率降低。
针对这一难题,复旦大学与通义实验室 MobileAgent 团队联合提出ToolCUA,一种面向 GUI-Tool 混合动作空间的计算机使用代理(Computer Use Agent)。其核心目标是让模型学会动态决策:何时使用 GUI、何时切换至 Tool、以及何时不应调用工具。
实验结果显示,ToolCUA-8B 在 OSWorld-MCP 基准测试中取得46.85%的准确率,不仅超越了 Claude-4-Sonnet,更逼近 Claude-4.5-Sonnet。目前,该项目代码与模型权重已全面开源。
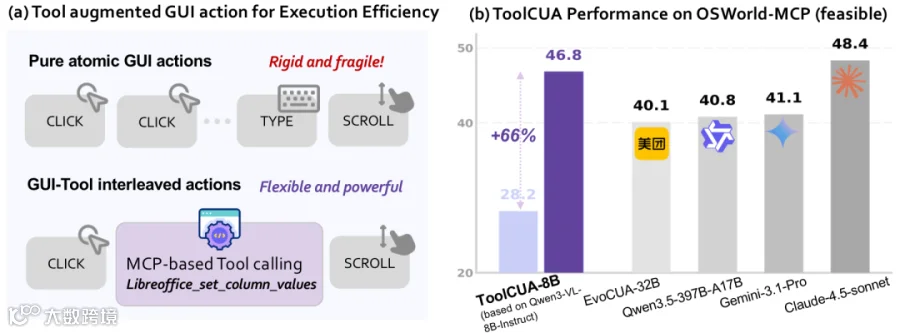
混合动作空间下的路径选择困境
传统计算机使用代理(CUA)主要依赖原子化 GUI 操作(如点击、输入、拖拽)。此类操作泛化性强,但步骤冗长且误差易累积,在复杂任务中常引发连锁错误。相比之下,工具调用(API)往往更高效精准,例如在 LibreOffice 中批量处理表格,一个 API 调用即可替代繁琐的菜单操作。
然而实验发现一个反直觉现象:直接将工具接入强模型,并不能自动提升性能。在混合动作空间中,若模型缺乏路径选择能力,会出现两类典型失败:
- 工具利用不足(Tool underuse):明明存在高效工具,模型仍坚持使用低效的 GUI 路径。
- 工具滥用(Tool overuse):模型频繁调用工具,但时机或粒度不当,反而降低成功率。
论文将此定义为最优 GUI-Tool 路径选择(optimal GUI-Tool path selection)问题,即在长程任务中动态规划最高效的执行路径。
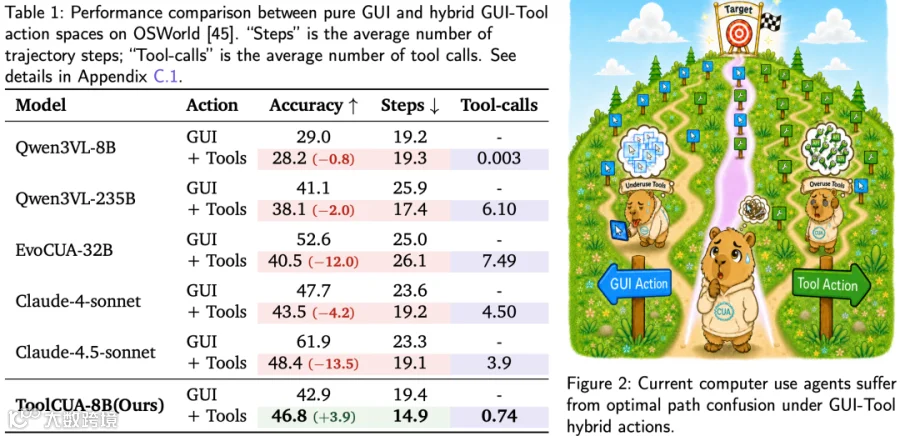
数据显示,Qwen3VL-8B 接入工具后几乎不使用(平均调用仅 0.003 次),准确率不升反降;Qwen3VL-235B 虽大幅增加工具调用,步骤数减少,但准确率同样下滑。Claude 系列模型也呈现类似趋势。这证明混合动作空间的核心难点在于模型是否具备正确的路径决策能力。
第一阶段:数据合成与工具引导微调
为解决数据稀缺问题,团队提出交错式 GUI-Tool 轨迹扩展流水线(Interleaved GUI-Tool Trajectory Scaling Pipeline),将现有的纯 GUI 数据转化为高质量的混合轨迹数据。
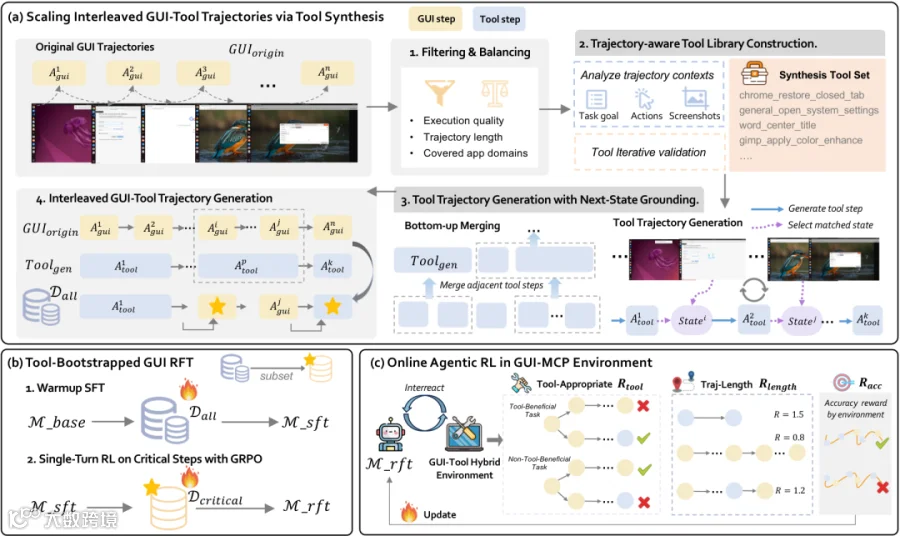
该流程包含三个关键步骤:
1. 轨迹感知的合成工具库构建
基于真实 GUI 轨迹,从具体操作流程中抽象出可调用的工具(如从 Chrome 设置中提取语言配置工具),确保工具能力 grounded in concrete trajectory behavior。
2. 带下一状态锚定的工具轨迹生成
利用多模态大模型生成功能等价的纯工具轨迹,并通过“下一状态锚定”验证工具执行效果与原始 GUI 截图的状态变化是否一致。
3. 交错式 GUI-Tool 轨迹生成
随机采样部分工具调用替换回对应的 GUI 子序列,形成多种 GUI 与 Tool 交错的轨迹。此举旨在让模型学习不同工具可用性下的决策边界及关键切换步骤。

最终数据集涵盖约 4000 个独特工具及 18 万步训练数据。基于此,团队执行工具引导的 GUI 强化微调(Tool-Bootstrapped GUI RFT):先进行 warmup SFT 学习工具基础知识,再通过 single-turn RL 校准模型在关键切换点的局部决策。
在线代理强化学习与路径效率奖励
第二阶段采用在线代理强化学习(Online Agentic RL),在真实环境中进行长程 rollout,优化轨迹级的路径选择策略。核心机制是设计的工具高效路径奖励(Tool-Efficient Path Reward)。
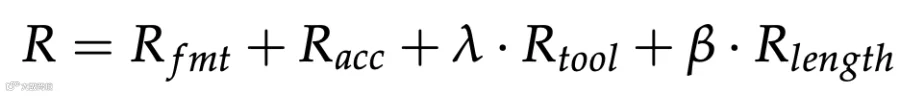
除常规格式与成功奖励外,ToolCUA 引入两项专用奖励:
工具适用性奖励 (R_tool)
该奖励仅在成功轨迹上激活,鼓励模型在适合用工具的任务中调用工具,在不适合的任务中避免滥用,从而解决混合混淆问题。
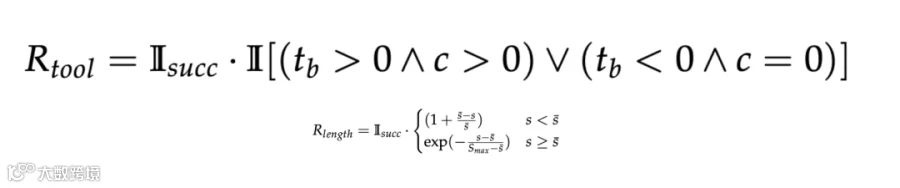
路径效率奖励 (R_length)
采用组内相对比较机制:若成功轨迹短于组内平均步长则给予奖励,反之衰减。这促使模型主动探索更短的高效执行路径,通常意味着用高层工具替代冗余 GUI 操作。
OSWorld-MCP 评测表现:准确率提升 66%
在引入混合动作空间的 OSWorld-MCP 基准测试中,ToolCUA-8B 取得46.85%的准确率,较基线模型(28.23%)相对提升约66%。
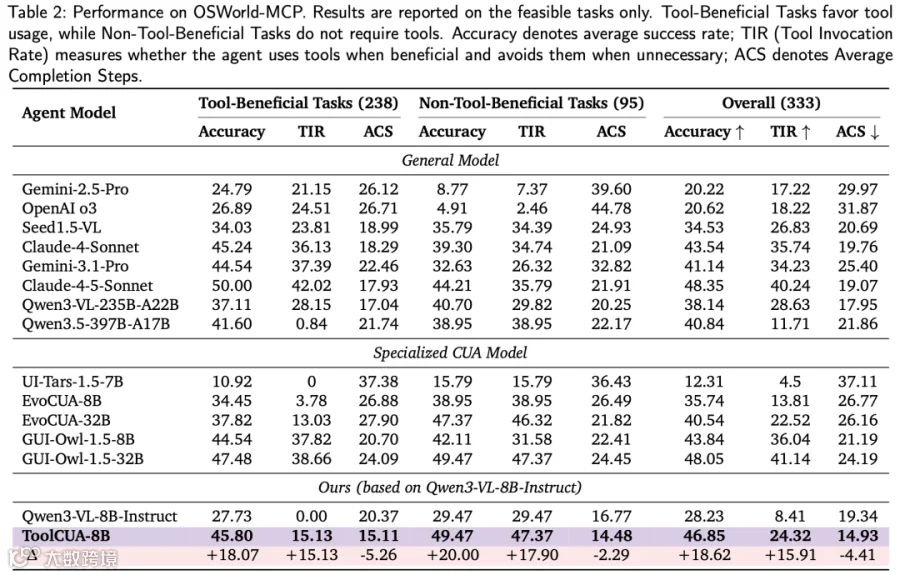
性能对比显示,ToolCUA 超越了 GUI-Owl-1.5-8B、Gemini-3.1-Pro 及 Claude-4-Sonnet,并接近 Claude-4.5-Sonnet 等更大规模模型。在效率方面,其平均完成步数(ACS)仅为14.93 步,为所有参评模型中最低。同时,工具调用率(TIR)从 8.41% 显著提升至 24.32%,表明模型不仅任务完成度更高,且工具决策更为精准。
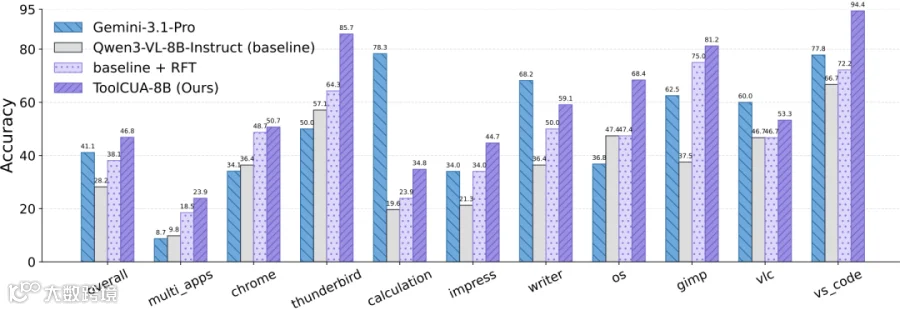
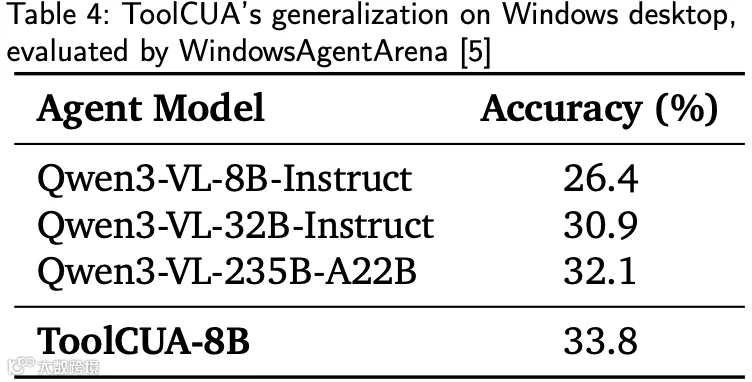
在未见过多应用任务(multi_apps)及特定应用领域(如 LibreOffice、VS Code)中,ToolCUA 均展现出显著的泛化提升。此外,在跨平台评测 WindowsAgentArena 中,尽管训练数据源自 Linux,ToolCUA 在 Windows 环境下仍达到 33.8% 的准确率,优于多个参比模型,证明了其学到的是一种可迁移的混合动作编排能力。
消融实验:为何 ToolCUA 真正学会了选路
消融实验揭示了 ToolCUA 成功的三大关键因素:
1. 交错数据是基础
若缺少离线交错轨迹数据的引导,仅靠在线强化学习,模型难以形成稳定的工具调用行为,工具调用率长期低迷。
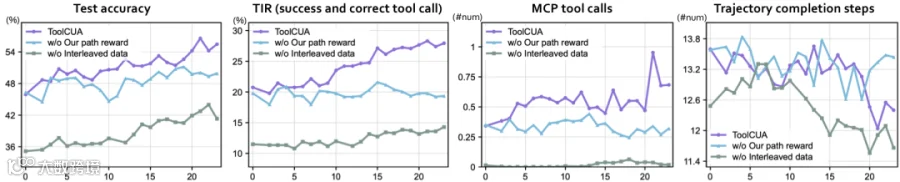
2. 专用奖励函数不可或缺
移除工具适用性与路径效率奖励后,模型准确率曲线波动剧烈,最终性能下降约 7 个百分点,且无法学会稳定高效的路径策略。
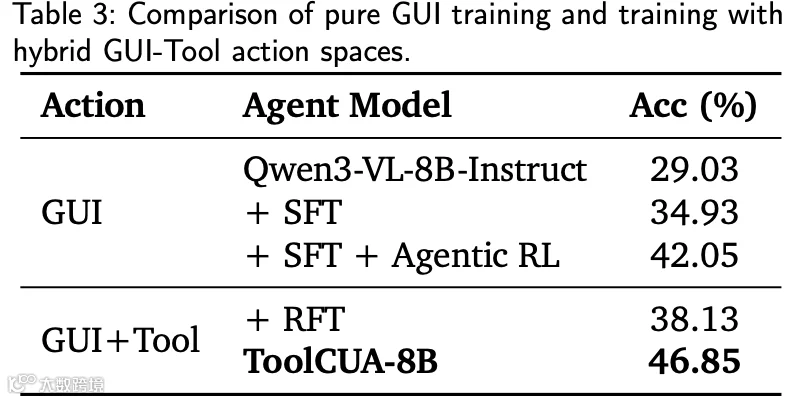
3. 混合训练优于纯 GUI 训练
对比显示,混合动作空间训练范式在各项指标上均显著优于纯 GUI 训练,证明该环境能更好地教会模型何时以结构化工具替代冗余操作。
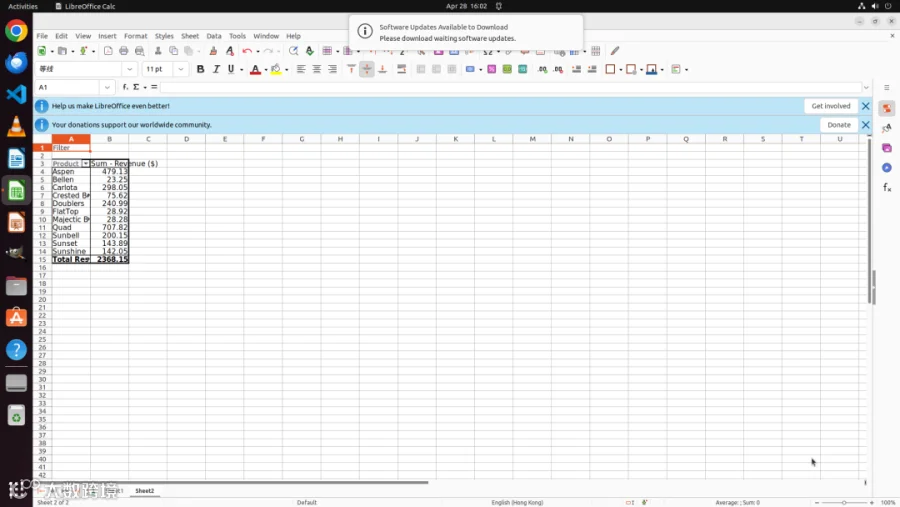
案例解析:真正的 GUI-Tool 协同
在实际案例中,ToolCUA 展现了灵活的协同能力。例如在 LibreOffice Calc 任务中,模型先调用工具读取数据结构,直接生成透视表,绕过了繁琐的菜单导航;而在 VS Code 添加文件夹任务中,模型先用工具完成目录加载,随后识别到弹出的信任确认对话框,立即切换回 GUI 操作点击确认。
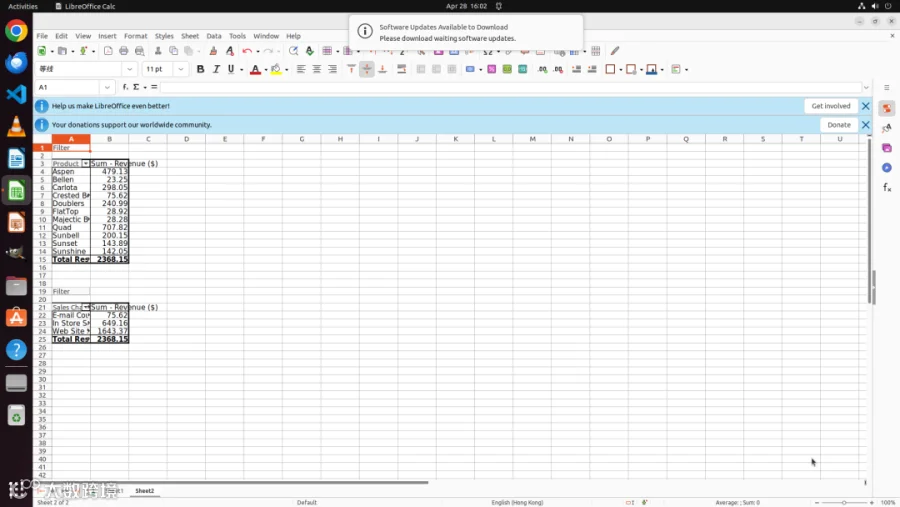

这些案例表明,ToolCUA 并非试图用工具完全替代 GUI,也不是退回纯手工操作,而是在真实环境中实现了两种动作空间的智能协同与无缝切换。
展望:混合动作训练成为下一代 CUA 范式
ToolCUA 的研究揭示了一个关键洞察:进入混合动作空间后,若无专门的路径选择训练,现有模型极易陷入困惑。通过分阶段训练范式,ToolCUA 验证了混合动作训练路线的有效性。
未来,构建更大规模的工具库与基座模型,使 CUA 原生具备混合动作处理能力,将是解决人类复杂问题的关键方向。
项目网站:https://x-plug.github.io/ToolCUA/
代码仓库:https://github.com/X-PLUG/ToolCUA
模型地址:https://huggingface.co/mPLUG/ToolCUA-8B
Mobile-Agent 系列:https://github.com/X-PLUG/MobileAgent