
98% 的 LLM API 消耗已是输入 Token,Prompt 缓存让「标价」彻底失真。DeepSeek V4 Flash 通过 2% 缓存读取成本,把实际价格压到$0.018/百万 Token——这才是 2026 年 AI 创业的定价基准线。
事件回顾
OpenRouter 的 AI 模型排名榜出现了一个「陌生人」——腾讯的 Hy3(预览版)。它上周的 Token 消耗量超过了 Claude 全系模型,高出 50% 以上,仅次于 DeepSeek V4 Flash。
很多人第一反应:腾讯什么时候搞出来了一个杀手模型?
答案没那么简单。数据科学家 Max Woolf(BuzzFeed 高级数据科学家)深入挖掘了 OpenRouter 的公开数据后,发现了一个更值得 AI 创业者关注的故事——不是谁排第一,而是 LLM API 的定价逻辑已经被 Prompt 缓存彻底改写了。
Hy3 凭什么登顶?
先看 Hy3 到底是什么。它是腾讯混元团队的开源模型,参数规模 295B(从最初 400B+ 压缩而来),基准测试成绩诚实得令人尊敬——在腾讯自己发布的 HuggingFace 页面上,Hy3 的编码基准成绩明显落后于其他中国开源模型。
但它在 OpenRouter 上火了。原因是三个要素叠加:
- 价格足够低:$0.066/百万输入 Token,比 DeepSeek V4 Flash 的$0.10/百万便宜不少
- 先免费后付费的经典策略:5 月 8 日前免费提供,积累了大量用户,切换到付费后用户没有流失
- 唯一提供商 SiliconFlow:新加坡的推理服务商,在 Hy3 之前几乎没有存在感,Hy3 上线后使用量爆炸增长
但这不是故事的全部。Hy3 的缓存读取成本高达 44%,这意味着实际使用成本是$0.034/百万——几乎是某些 DeepSeek V4 Flash 提供商的两倍。
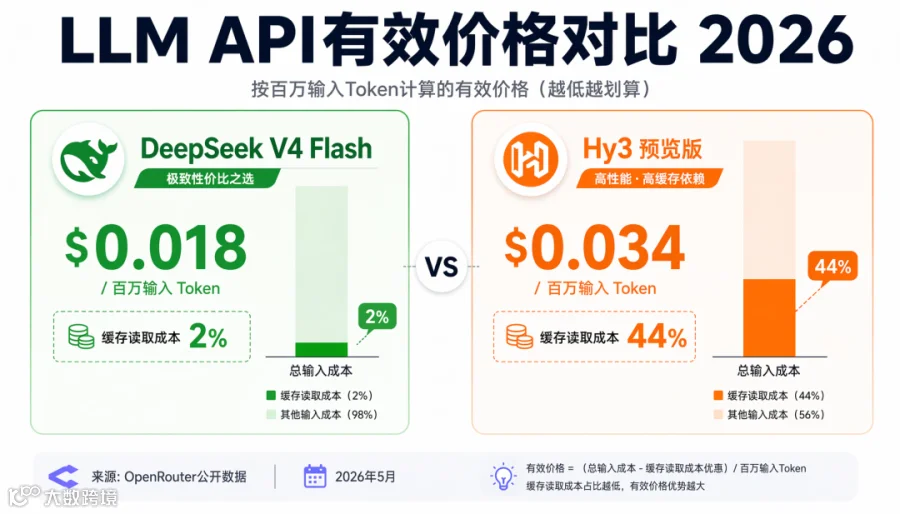
▲ DeepSeek V4 Flash vs Hy3 有效价格对比 (来源:OpenRouter 公开数据,2026 年 5 月)
真正的价格屠夫:DeepSeek V4 的 KV 缓存革命
如果你只看标价,DeepSeek V4 Flash 是$0.10/百万 Token。但 OpenRouter 现在展示了有效价格(effective price)——计入缓存命中率后的实际成本。
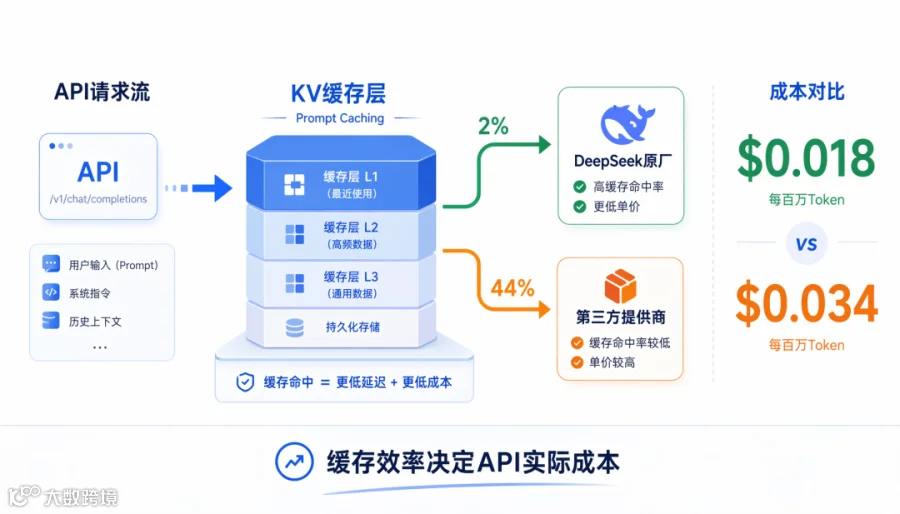
▲ Prompt 缓存效率决定 API 实际成本:2% vs 44% 的缓存读取成本差异 (来源:OpenRouter 有效价格数据)
DeepSeek 自己作为提供商时,缓存读取成本只有2%(行业标准是 10-50%),有效价格降到$0.018/百万输入 Token。DeepSeek V4 Pro 版本更夸张——缓存读取成本降到0.83%。
怎么做到的?DeepSeek 从 V4 开始实现了一种新的 KV 缓存方案。KV 缓存(Key-Value Cache)是 Transformer 推理时保存已处理 Token 的中间状态,避免重复计算。DeepSeek 的优化让它自己的提供商在缓存效率上远超第三方。
这对 AI 创业者意味着什么:同样的 API 调用,选择不同提供商,实际成本可以差 5 倍以上。
为什么缓存这么重要?
因为 2026 年的 LLM 使用模式已经彻底变了。
Max Woolf 挖出的一个关键数据:OpenRouter 上 API 调用的 Token 构成现在是 98% 输入、2% 输出。
这不是笔误。当 AI Agent 进行多轮对话时,每一轮都要把整个对话历史重新发送给模型。一个 30 轮的编码会话,第 30 轮发送的上下文可能包含之前 29 轮的全部内容。这就是为什么 Agent 编码的成本比单次问答题高出一个数量级。
再加上代码库上下文、工具输出、MCP 服务器返回的数据——输入 Token 的膨胀是指数级的。而 Prompt 缓存能把重复处理的成本降到原来的 10% 甚至更低。
对于日烧几百万 Token 的 AI 创业公司来说,选对提供商就是选对生死线。
三个值得关注的信号
信号 1:API 定价不再有「标价」这回事
OpenRouter 现在不得不在每个模型页面展示「有效价格」表格。同一模型、不同提供商的有效价格差异巨大:
| 提供商 | 缓存命中率 | 有效价格 ($/1M 输入) |
|---|---|---|
| DeepSeek 原厂 | ~90%+ | 0.018 |
| SiliconFlow(Hy3) | ~56% | 0.034 |
| 第三方 A | ~30% | 0.070 |
如果你在 OpenRouter 上选了「自动路由」而不指定提供商,可能会被分配到缓存命中率只有 30% 的节点——成本直接翻 3 倍。
信号 2:订阅制 vs API,新的计算方式
Max Woolf 指出了一个反直觉的结论:如果你能稳定耗尽 Claude Code 或 Codex 的订阅额度,订阅制仍然是最划算的。 但 DeepSeek V4 Flash 的 API 价格给了另一种选择:不锁定订阅,按需付费,且比超额购买订阅便宜得多。
信号 3:中国模型正在重新定义「便宜」的底线
DeepSeek V4 Flash 的$0.018/百万有效价格,Hy3 的$0.034/百万,对比 Claude Opus 4.7 的$15/百万输入——价格差是800 倍。虽然质量不在同一级别,但对于大量「不需要最强模型」的场景(数据清洗、格式转换、初稿生成),便宜模型的价值在快速提升。
行动建议
- 立刻检查你的 API 提供商配置:如果你在用 OpenRouter,确认你的 Agent 是否在调用 DeepSeek V4 Flash 时指定了 DeepSeek 原厂作为提供商。不指定的代价可能是 3-5 倍的成本。
- 建立「有效定价」意识:不要再按模型的标价做预算。询问你的 API 提供商三个问题:缓存读取成本是多少?历史缓存命中率是多少?是否支持指定提供商?
- 分层模型策略:重任务用 Claude/GPT(订阅制更划算),轻任务用 DeepSeek V4 Flash(API 按需付费),模板化任务甚至可以尝试 Hy3 级别的模型。一个合理的 Agent 架构应该支持按任务难度自动路由到不同模型。
- 关注 DeepSeek API 直连:OpenRouter 上的 DeepSeek 原厂提供商有效价格虽低,但部分 Agent 框架可能不支持指定提供商。直接使用 DeepSeek API Key 可以获得同样的缓存优势,且更可控。
一个值得追问的问题
Hy3 的故事最有趣的部分不是它登顶了——而是没人知道为什么。它的使用量高度去中心化(前 5 个 App 加起来不到 1%),不是某个大客户在推。也没有明显的 Agent 编码工具把它设为默认。
Max Woolf 的猜测是:某个大型非编码类 App 把 Hy3 作为数据处理骨干。如果是这样,它说明了一个趋势——便宜模型正在吃掉大量「后台」场景,而这些场景的 Token 消耗量远超前台对话。
对于 AI 创业者来说,这意味着:你的产品不需要在所有场景都用最强模型。把推理层做好分层,成本可以降低一个数量级。
#AI 风向 #LLM 定价 #DeepSeek #AI 创业 #API 经济 #一人公司
本文由 AI 辅助创作,经人工审核编辑发布