
想象一下,你正在训练一个拥有数千亿参数的大语言模型。
第一轮训练,模型输出的内容杂乱无章,几乎是在随机猜测。
第十轮训练,模型开始能说一些通顺的句子了。
第一百轮训练,模型已经能写出逻辑清晰的文章,甚至能写代码、做推理。
问题来了:在这个过程中,模型是怎么知道自己"进步了"?它又是如何知道该往哪个方向调整参数才能变得更好?
答案就藏在两个核心概念里——损失函数和梯度下降。
这篇文章,我们就来深入理解这两个概念,揭开大模型"学习"的神秘面纱。
一、先弄清楚:模型到底在干嘛?
很多人以为大模型在“理解语言”,其实不是。它只在做一件事:
👉 根据前面的内容,预测下一个最可能的词
例如:
输入:我喜欢机器
模型输出的不是一个词,而是一个概率分布:
学习:0.6工作:0.2睡觉:0.05...
✅ 什么是“正确答案的概率”?
训练数据会告诉模型:正确答案:学习
所以:
👉 正确答案的概率 = 模型给“学习”的概率(比如 0.6)
二、损失函数:模型是怎么被“批评”的?
模型每预测一次,都会被打一个分:
👉 错得越离谱,罚得越狠
这个评分规则就是:
👉 损失函数(Loss Function)
定义:损失函数是衡量模型预测值与真实值之间差距的函数,它将模型的"错误程度"量化为一个标量值。
对于语言模型,损失函数的输入是:
模型预测的概率分布
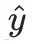
真实的 token
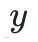
输出是一个标量损失值:
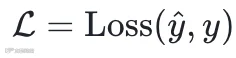
它具备三重角色:
评估指标(Evaluation Metric):量化模型当前表现,模型有多好?
优化目标(Optimization Objective):定义训练方向,我们要优化什么?
梯度来源(Gradient Source):提供反向传播信号,参数改怎么改?
三、LLM为什么选用“交叉熵”损失函数?
LLM 的预训练任务是Next token prediction,每个预测位置都是一个多分类问题,标准配置为:交叉熵损失函数。
直接给你最核心公式:
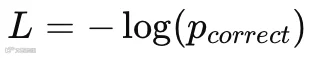
3.1 这公式到底在干嘛?
只看一件事:
👉 模型给“正确答案”的概率有多大
3.2 为什么一定要加 log?
如果不用 log:
0.9 和 0.99 差别很小
模型学不动
加了 log 之后:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
✅ 一句话结论
👉 log 的作用:放大错误,让模型“更痛”
3.3 交叉熵到底是什么?
完整形式是:
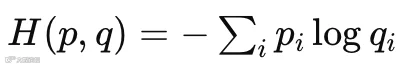
但在 LLM 中:
真实答案是 one-hot,如 p = [0, 0, 1, 0, 0, ...]
所以只剩一项
👉 就变成:
只看正确答案的概率
四、模型怎么知道“该怎么改”?(梯度)
现在模型已经知道:
❌ 自己错了(loss)
但问题是:
👉 怎么改参数?
答案是两个字:
👉 求导(梯度)
4.1 梯度是什么?
公式是:
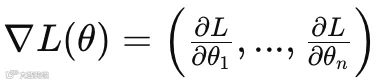
θ表示模型的所有参数,为n的向量
L就是损失函数
∇L(θ)表示损失函数L对所有参数的变化率
公式右侧表示每一个参数 θᵢ 改一点点,会让 Loss 变多少
4.2 人话解释
👉 某个参数动一下,会让 loss 变多少
4.3 交叉熵最重要的结论

zi表示logits,softmax 之前的原始输出
yi^表示第i个词的预测概率
yi表示第i个词的真实标签
✅ 一句话理解
👉 梯度 = 预测 - 真实
4.4 这意味着什么?
|
|
|
|---|---|
|
|
|
|
|
|
👉 这就是模型“自我纠错”的机制
五、真正的学习:梯度下降
有了梯度之后,模型开始更新参数:
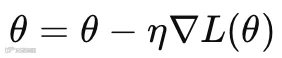
θ表示模型的所有参数
∇L(θ)表示损失函数L对所有参数的变化率
η表示学习率
5.1 一句话解释
👉 往“让错误变小”的方向走一步
5.2 一个非常形象的比喻
你在山上找最低点:
梯度:哪边最陡
梯度下降:往下走
最终:
👉 找到最低点(loss 最小)
六、现实世界:为什么用 AdamW?
普通梯度下降不够好:
容易震荡
收敛慢
不稳定
所以用:
👉 AdamW(大模型标配优化器)
6.1 它在做什么?
核心是两个“记忆”:
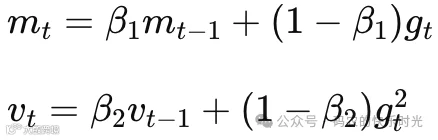
t 为时间步,第几次更新参数
mt 为一阶矩估计(动量)
gt 为当前计算的梯度
vt 为二阶矩估计(方差)
β₁ 为一阶矩衰减率(默认 0.9)
β₂ 为二阶矩衰减率(默认 0.999)
6.2 最终更新公式
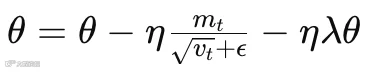
👉 AdamW = 更稳定 + 自动调节步长 + 防过拟合
七、把整个过程串起来
模型每一步都在做:
① 预测下一个词(概率分布)② 用交叉熵计算错误③ 对损失函数求导(得到梯度)④ 用 AdamW 更新参数
循环:
👉 上亿 / 上百亿次
八、为什么它最后会“变聪明”?
因为它一直在做一件事:
猜错 → 被惩罚
梯度告诉它哪里错
参数被调整
下次更接近正确答案
最终:
👉 逼近人类语言的概率分布
你可以这样理解大模型:
它从来没有“理解语言”
它只是被训练成:👉 在任何上下文下,都能给出“最像人类会说的话”的概率分布
九、一句话总结
LLM 的本质 = 用交叉熵衡量错误 → 用求导得到梯度 → 用 AdamW 做梯度下降 → 不断逼近真实语言分布
来源:码农的快乐时光