

当下视频虚拟试穿技术已较为成熟,但大多只能实现静态衣物替换,无法模拟人手拉扯衣摆、拉动拉链等真实互动动作,体验与真实穿搭差距明显。为此,研究团队正式定义交互式视频虚拟试穿(Interactive VVT) 全新任务,同时梳理出行业三大核心难题:2D姿态信息难以判别手部交互行为、短时稀疏的交互动作让模型难以学习衣物形变、配套数据集与评估指标严重缺失。针对以上痛点,团队基于视频扩散Transformer架构打造iTryOn框架,一方面推出多层级交互注入机制,从空间、语义两大维度精准引导手衣互动;另一方面设计动作感知约束损失函数,强化稀疏交互帧的训练效果。这套方案成功实现了高逼真度的动态穿衣交互效果,补齐了传统虚拟试穿的短板,也为虚拟穿搭、数字时尚、电商展示等应用场景带来全新技术方向。
相关链接
-
论文:https://arxiv.org/pdf/2605.21431
论文介绍
 论文介绍并形式化了一项具有挑战性的新任务:交互式视频虚拟试穿(Interactive VVT)。与侧重于被动展示服装的传统视频虚拟试穿(VVT)方法不同,交互式VVT旨在生成一段视频,视频中用户能够主动与一件新的虚拟服装进行互动(例如,拉扯下摆、拉开外套拉链),这就要求服装能够根据这些动作产生逼真的形变。 作者们指出了这项任务面临的三大核心挑战:
论文介绍并形式化了一项具有挑战性的新任务:交互式视频虚拟试穿(Interactive VVT)。与侧重于被动展示服装的传统视频虚拟试穿(VVT)方法不同,交互式VVT旨在生成一段视频,视频中用户能够主动与一件新的虚拟服装进行互动(例如,拉扯下摆、拉开外套拉链),这就要求服装能够根据这些动作产生逼真的形变。 作者们指出了这项任务面临的三大核心挑战:
-
交互的语义歧义:标准的 2D 姿态信息不足以解决手部与服装交互的具体性质和 3D 上下文。 -
从稀疏事件中学习物理合理性:在视频中,互动过程中复杂的、由物理驱动的服装变形通常是短暂且不频繁的,导致模型训练的监督信号稀疏且不稳定。 -
数据和评估匮乏:缺乏用于交互式 VVT 的大规模数据集和量化交互保真度的指标。
为了应对这些挑战,论文提出了iTryOn,这是一个基于大规模视频扩散Transformer(Wan2.1-VACE骨干网)构建的新型框架。iTryOn引入了多级交互注入机制和动作感知约束损失。
方法概述
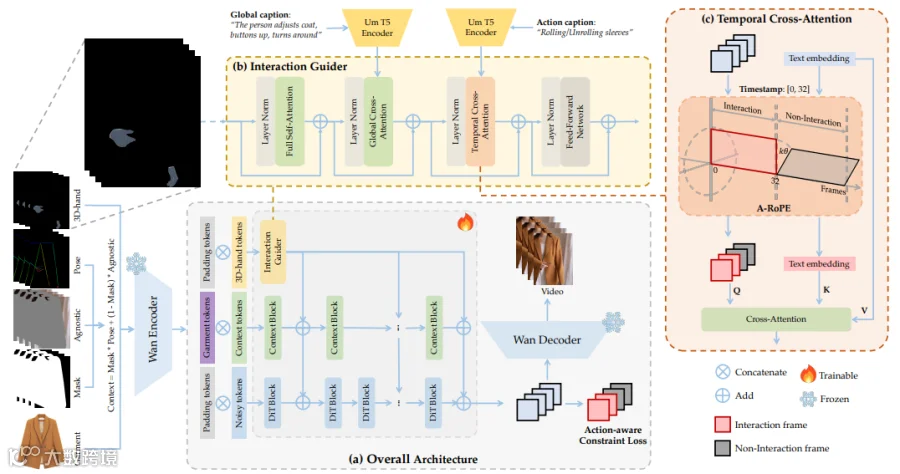 iTryOn架构。(a) DiT骨干网络,并行注入通用上下文和来自我们交互引导器的3D手部引导信息。动作感知约束损失函数将训练重点放在交互帧上。(b) 交互引导器模块融合空间特征以及全局和动作特定的文本提示。(c) A-RoPE机制通过时间交叉注意力机制中独特的旋转位置编码,将动作字幕与其对应的视频片段对齐。
iTryOn架构。(a) DiT骨干网络,并行注入通用上下文和来自我们交互引导器的3D手部引导信息。动作感知约束损失函数将训练重点放在交互帧上。(b) 交互引导器模块融合空间特征以及全局和动作特定的文本提示。(c) A-RoPE机制通过时间交叉注意力机制中独特的旋转位置编码,将动作字幕与其对应的视频片段对齐。
实验结果

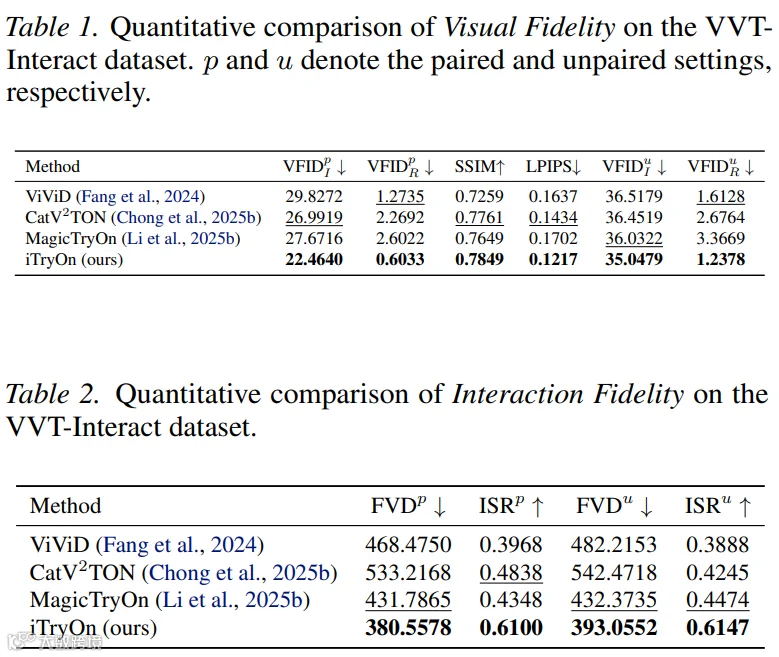
 广泛的实验表明,iTryOn 不仅在传统 VVT 基准 ViViD 数据集上取得了 SOTA 性能(归因于强大的 Wan2.1-VACE 骨干和先进的通用训练策略),而且在新的交互式 VVT 设置中确立了绝对领先地位,ISR 成功率超过 61%,远高于现有方法的低于 49%。这证实了 iTryOn 能够生成物理上可信且语义准确的复杂动态交互。
广泛的实验表明,iTryOn 不仅在传统 VVT 基准 ViViD 数据集上取得了 SOTA 性能(归因于强大的 Wan2.1-VACE 骨干和先进的通用训练策略),而且在新的交互式 VVT 设置中确立了绝对领先地位,ISR 成功率超过 61%,远高于现有方法的低于 49%。这证实了 iTryOn 能够生成物理上可信且语义准确的复杂动态交互。
结论
论文引入并形式化了交互式视频虚拟试穿(Interactive VVT)这一新任务。为了促进该领域的研究,论文构建了首个大规模数据集 VVT-Interact,并提出了交互成功率(ISR)指标用于标准化评估。 为了应对模糊性和稀疏性的核心挑战,论文提出了 iTryOn,一个融合了多级交互注入机制和动作感知约束损失的框架。大量实验表明,iTryOn 在新的基准测试中取得了显著优势,验证了其生成物理上合理的交互的能力。此外,在传统的 ViViD 数据集上的额外评估也证实了该模型的通用性和一流的视觉质量。
感谢你看到这里,添加小助手 AIGC_Tech 加入官方 AIGC读者交流群,下方扫码加入 AIGC Studio 星球,获取前沿AI应用、AIGC实践教程、大厂面试经验、AI学习路线以及IT类入门到精通学习资料等,欢迎一起交流学习💗~
