

LinkAI平台及开源CowAgent均已全面接入DeepSeek V4系列模型,无论是本地部署的CowAgent,还是LinkAI平台上运行的云端「超级AI助理」,都能第一时间享受到更强的模型能力。
DeepSeek V4 系列发布之后,关于它能不能用、好不好用的讨论很多,但大部分评测仅停留在普通对话或编码上。CowAgent 作为开源中立的 Agent 框架,则更关心模型在 Agent 链路中的真实表现,包括 工具和技能规划、复杂编码、长期记忆、浏览器自动化、知识库构建、超长上下文处理,本次测评针对这 6 个真实场景,在 CowAgent 中对 DeepSeek V4 模型做了全面测试。

DeepSeek V4 模型系列分为 Flash 和 Pro 两档,本次评测主要关注 deepseek-v4-flash,因为它的价格大约是 Pro 的 1/10、Claude 4.6 Sonnet 的几十分之一、MiniMax M2.7 的三分之一,响应速度也更快。如果 Flash 已经能够覆盖大部分 Agent 任务,那 Pro 自然会有更好的效果。
本次测试也是为了决定是否要把 超级AI助理 及 开源CowAgent 的默认推荐模型切换到 V4 Flash 模型。
一、测试环境
测试在 CowAgent 的 Web 端进行,CowAgent 是开源的 AI Agent 框架,内置任务规划、工具、技能、长期记忆、知识库等模块,并支持多种接入渠道,也是LinkAI超级助理的底层内核。每个测试场景在独立会话中运行,互不干扰。关键参数:

二、场景设计
6 个场景的设计原则是:每个场景对应 Agent 的一个核心能力维度,且尽量贴近真实使用
三、场景实测
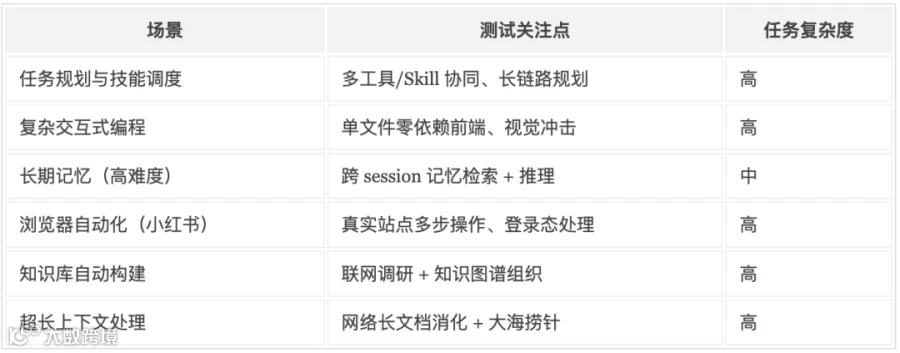
场景 1:任务规划与工具/技能调度
🎯关注点:在 13 个工具和 30+ 个 Skill 的工作空间里,能不能精准选择并组合执行,这是最考验规划能力的场景。
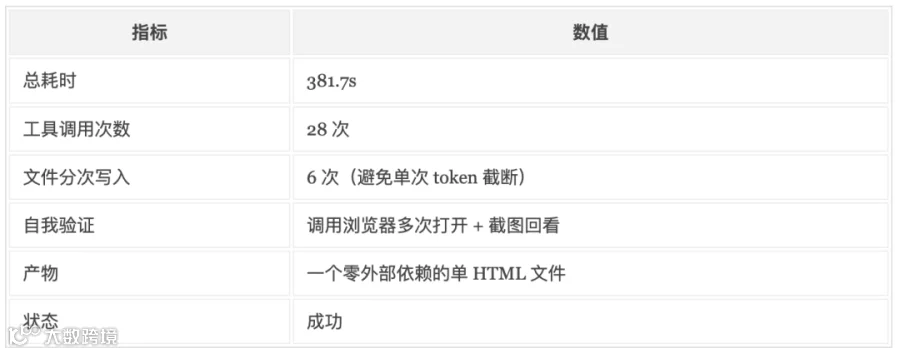
📊 实测数据:
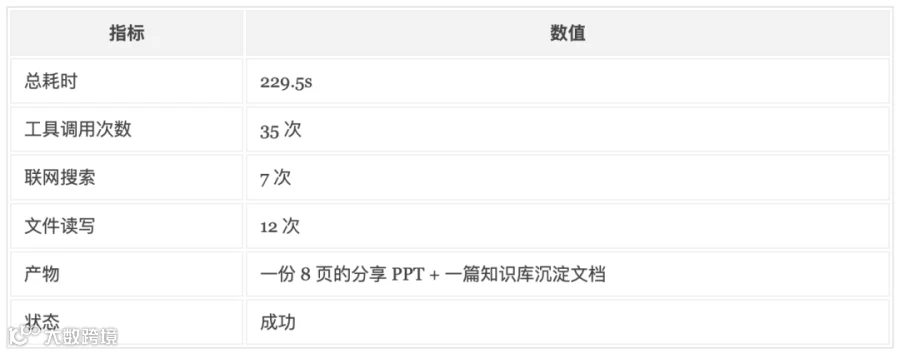
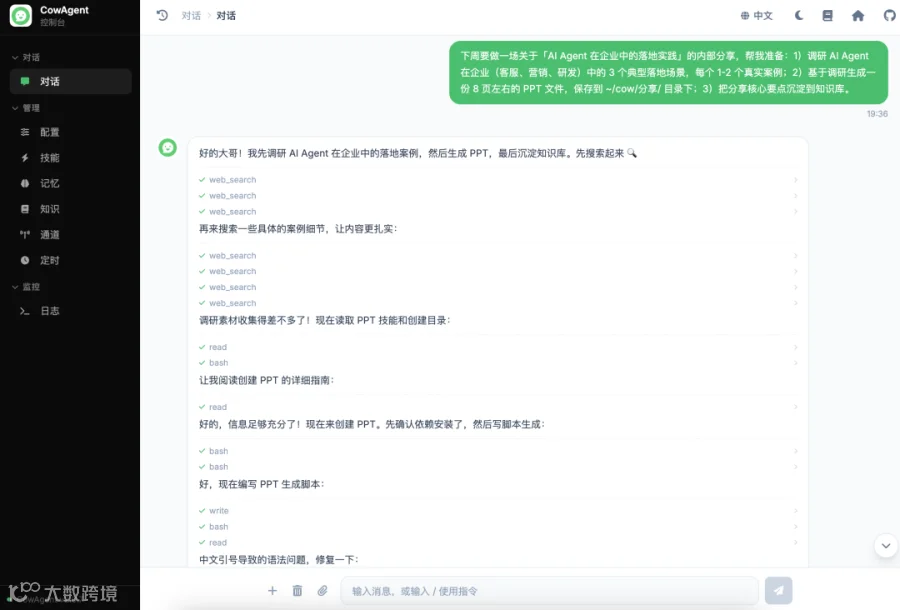
🔍 观察:Flash 的执行路径基本是 拆解 → 逐场景调研 → 沉淀文档 → 生成 PPT → 更新知识库,整个链路一次跑通,没有出现重复执行或漏步骤。35 次工具调用都用得很克制,没有冗余动作,说明它的多工具规划在 Agent 框架的提示词约束下是稳定的。
Web端对话:
生成结果:
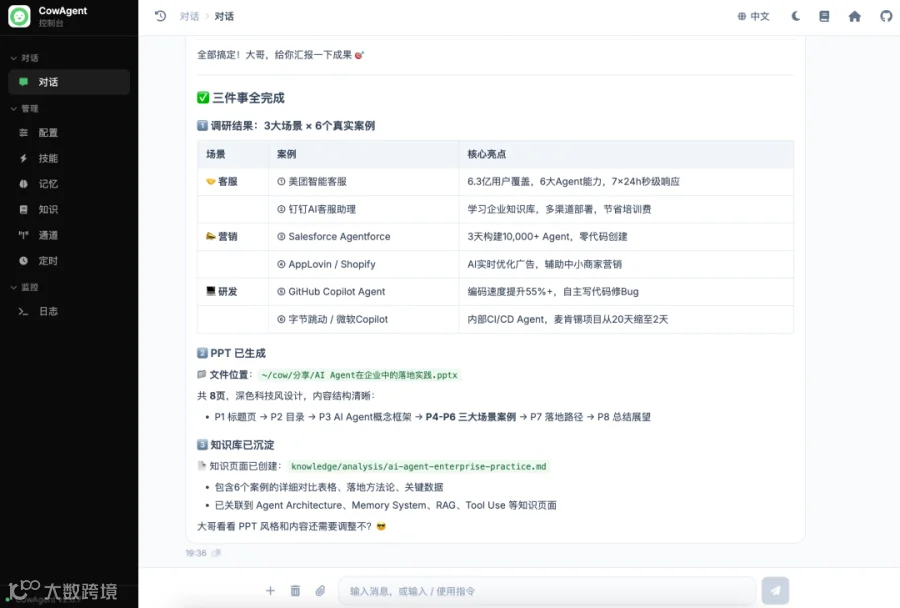
最终生成的 PPT(样式和美观性还要取决于安装的 Skill,这里用了一个比较基础的 PPT 生成技能,整体文字、排版基本没有问题):
场景 2:复杂交互式编程
🎯关注点:复杂前端代码生成 + 视觉品味 + 单文件零依赖约束。
📊 实测数据:
🔍 观察:
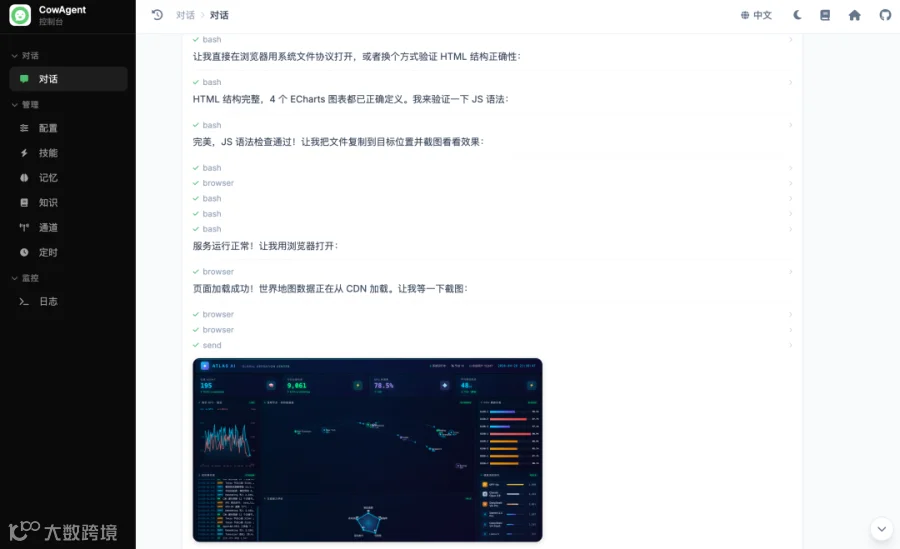
(1)V4 Flash 主动用 分块写入 的方式构建大文件,先写骨架再补图表
(2)写完后 主动调用浏览器工具打开页面截图回看,这一步不是 prompt 要求的,是模型自己加的稳定性兜底
(3)一个小遗憾:prompt 里要求"零外部依赖",模型还是引用了 echarts CDN。这是 Flash 在约束细节上的执行还不够严格的体现,复杂约束下 Pro 大概率会更稳
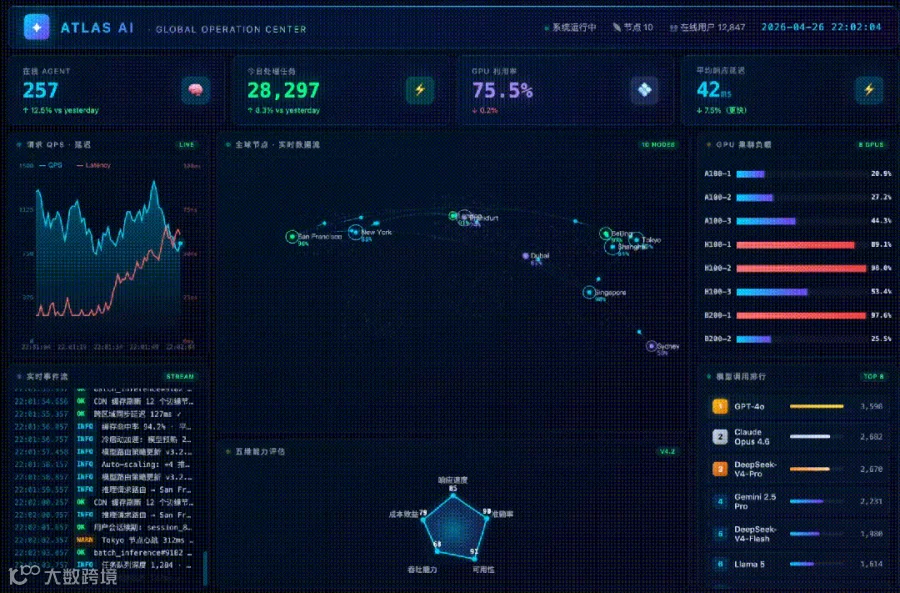
网页展示效果:
模型自己调用浏览器打开页面、截图回看的过程:
场景 3:长期记忆
🎯关注点:跨 session 记忆能否被精准检索 + 多条记忆能否综合推理。
📊 实测数据:
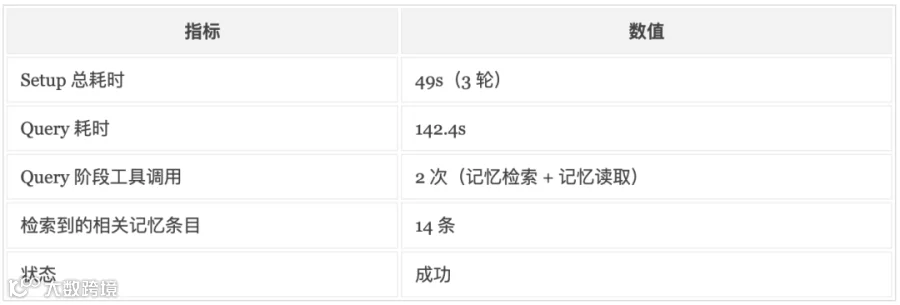
🔍 观察:在全新 session 里,Flash 只用 2 次工具调用就把品牌的全部细节拿出来了,视觉色(雾霾蓝 #6B8FA8)、供应商(普洱孟连老黑寨合作社)、租金、店长候选人薪资全部一字不差,并且基于这些信息给出了结构化建议:
「精品咖啡调性优先 → 推小林 → 但可以谈到 1.6~1.7 万作折中 → 用股权/分红预期补一点薪资差距」
第一个会话中进行了多轮问题咨询:

新会话中的回复,可以看到模型主动触发了记忆检索:
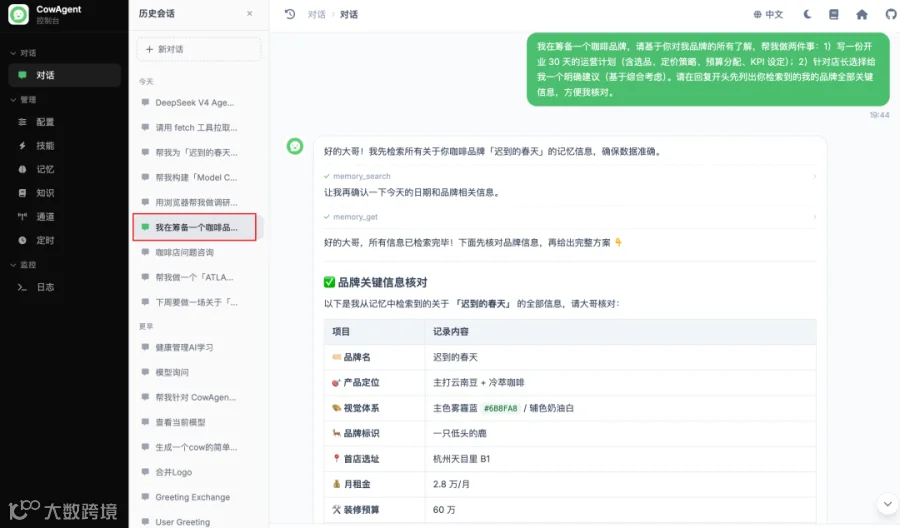
长期记忆中沉淀下来的品牌信息:

场景 4:浏览器自动化
🎯关注点:真实有反爬的网站、登录态处理、知道什么时候应该停下来求助用户。
📊 实测数据:

🔍 观察:
(1)Flash 在扫码节点的处理是这次的亮点:没有盲目填写用户名密码,而是先截图当前页面发送给用户,等用户回复已登录后再继续
(2)在最终发布按钮前停下来等确认,没有擅自把内容发出去。这是 Agent 安全感的一个细节体现
(3)标题模仿小红书爆款结构(emoji + 钩子 + 数字)写得很到位
搜索结果页和模型总结的爆款套路:

模型在登录页主动请求用户协助:
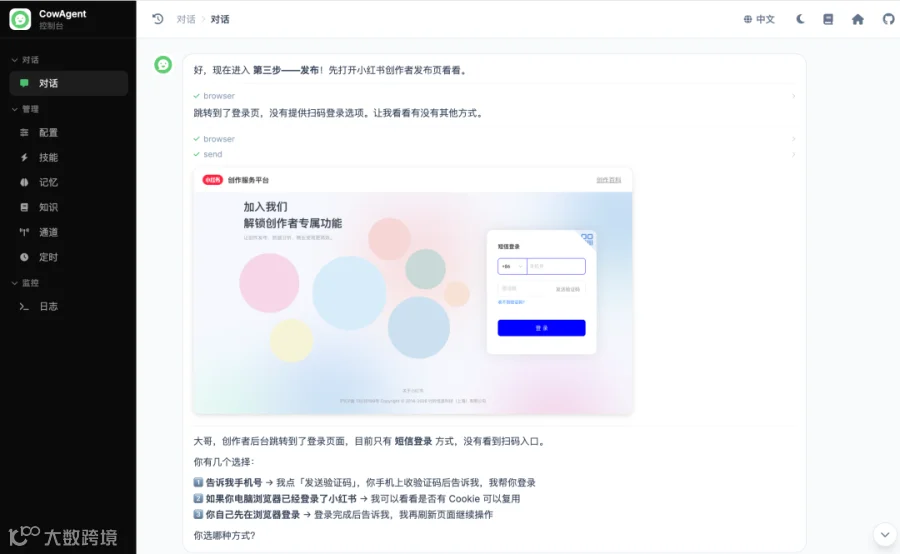
登录后自动填写表单内容,模型停在发布按钮前等待用户确认:

场景 5:知识库自动构建
🎯关注点:联网 + 文件操作 + 知识组织能力的综合,最终能正确构建出知识图谱
📊 实测数据:

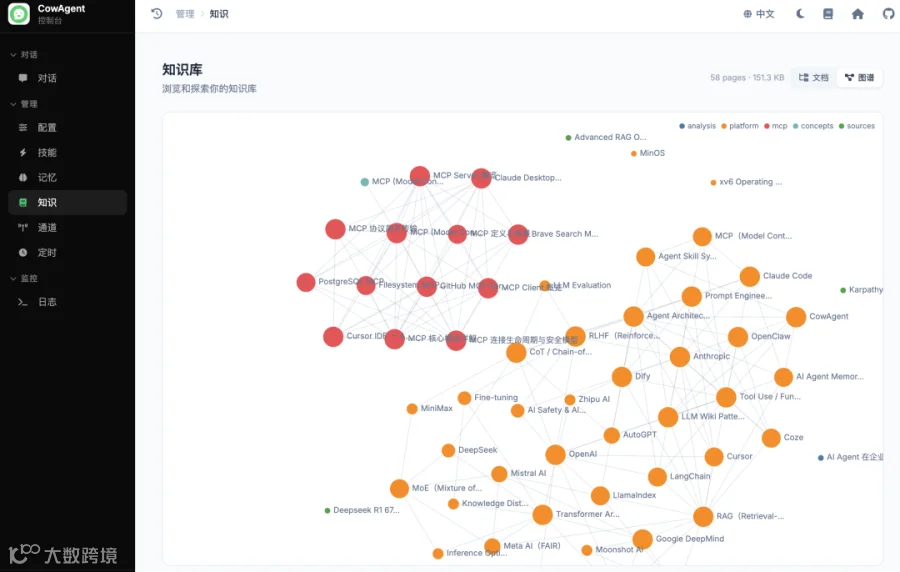
🔍 观察:Flash 真正做出了图谱的样子,不是把所有内容写成一篇大文档,而是遵循知识库 wiki 技能的设定,切成「概念页 / Server 实现页 / 客户端集成页」并且互相 link,每篇结尾都有"相关阅读"区域指向兄弟节点。这个分层组织能力对知识库类任务非常重要。
知识库构建过程:
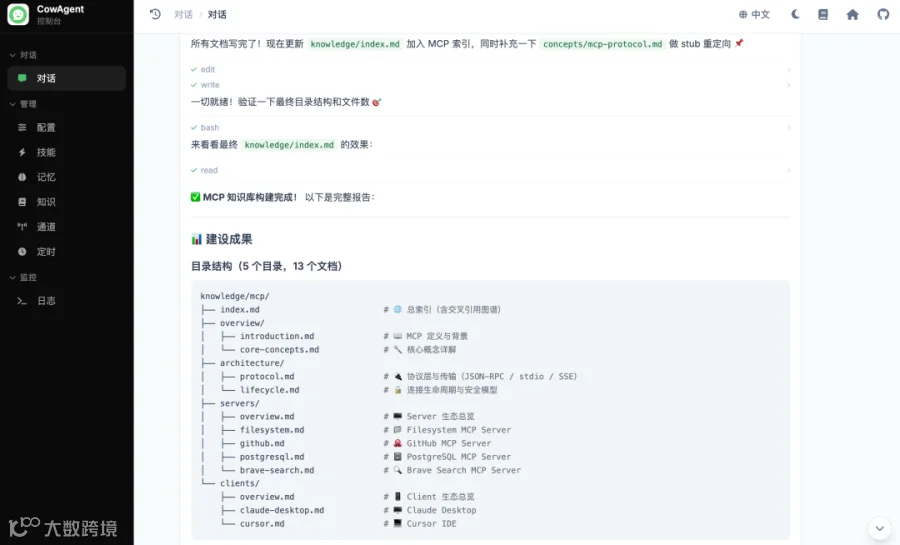
生成的知识库目录结构:

索引页渲染后的效果:
场景 6:超长上下文处理
🎯关注点:超长文档的全局理解 + 大海捞针式的精确定位 + 原文引用准确度。
📊 实测数据:
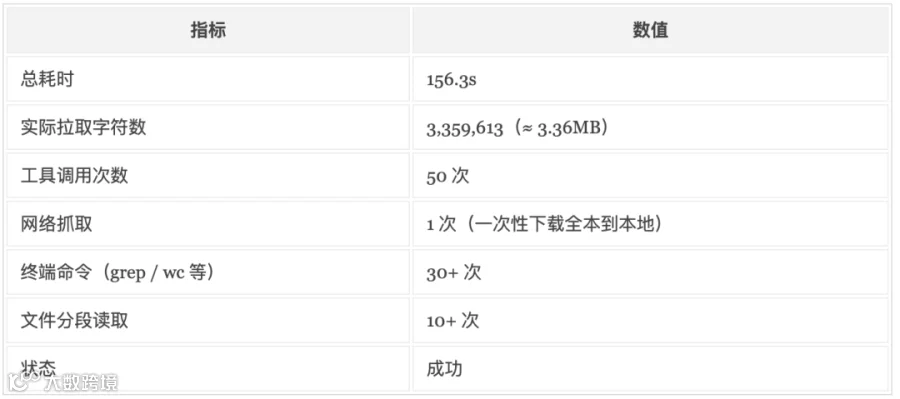
实测下来模型并没有试图把 3.36MB 全部塞进 context,而是:先一次性把全文落到本地,只在 context 里保留前 5 万字符;后续通过终端命令在本地文件里搜索关键词("Austerlitz"、"lofty sky"、"Natasha"、"waltz" 等)拿到行号;再按行号区间分段读取,把关键段落带回 context。
最后给的答案:
Andrei 的天空场景 精准定位到第 15869 行,原文引用一字不差:"the lofty sky, not clear yet still immeasurably lofty, with gray clouds gliding slowly across it..."
Pierre 第一次出场 锁定到 Book One Chapter II
Natasha 第一次舞会 锁定到 Book Six Chapter XVI,舞伴 Andrei,给出原文引用
最后一章哲学主题:自由意志 vs 历史必然性,并附了托尔斯泰的原文段落
整个过程 50 次工具调用都没出错,也没有陷入死循环。先把全文落盘,再用搜索一步步定位、分段读,这种处理路径才是 Agent 在长文档场景下真正实用的能力。
在 Agent 场景里,发生一次性把 1M token 塞进 prompt 的概率其实很低,真到了几十万 token 的文档,更好的做法就是先落盘再搜索,而不是一次性加载全部内容。所以这个场景测的不是模型能装多大,而是模型够不够聪明知道什么时候该装入上下文、什么时候该走工具,这才是 Agent 真正需要的长上下文能力。
模型的工具调用过程(先获取全文落盘,再用 grep 定位、按行号区间分段读取):

最终回答中带章节引用的原文段落:

四、数据汇总
6 个场景全部跑完的汇总数据:

几个数据观察:
零失败、零死循环。6 个场景全部一次跑通,没有一次进入工具调用死循环或解析失败,在后续的批量任务测试中同样有很好的表现。这是从 V3 到 V4 最显著的一个升级,V3 时代复杂场景偶尔会陷入重复同一个工具或工具参数解析错误的循环
响应速度足够快。所有场景都在 2~6 分钟内完成,且执行过程中会把详细步骤流式发送出来,用户能实时看到 Agent 的思考和动作,体感上响应延迟很低
五、结论
整体看下来,DeepSeek V4 Flash 在 6 个场景里的稳定性已经足以做默认模型来用,最复杂的场景1(35 次工具调用)和场景6(50 次工具调用)也能稳定跑完,比 V3 时代有非常明显的改善。
规划、编码、记忆、浏览器、知识库、长上下文这几项基础能力都没有明显短板,长期记忆和长上下文这两块的表现甚至有些超出预期。
再加上价格优势,Agent 一次任务往往要几十次 LLM 调用,模型成本是选型里很关键的一项。Flash 在这个价位上能做到这种水准,作为日常使用的默认选择性价比很高。
当然 Flash 也不是没短板,复杂约束的执行偶尔会打折扣,比如场景2里要求"零外部依赖",模型还是引用了 echarts CDN。遇到真正复杂的任务,直接切到 Pro 配合 reasoning_effort=max 能拿到更深的思考深度。后面我们也会继续补充批量任务测试和不同模型的横向对比,并形成一套可复用的 Agent 能力评测框架。
基于这次评测的结果,目前平台超级AI助理和CowAgent开源项目在最新版本中均已将 deepseek-v4-flash 设置为默认模型,欢迎体验和咨询。

立即体验



