
精准有效的告警
在某大型商业银行的ECC监控中心,时常会有这样的场景:突然某个重要的业务发生了故障中断,一线值班的监控人员没有及时发现,直到业务流程处理出现了异常,才后知后觉。二线运维人员接到故障处理任务,手忙脚乱,无法在最短的时间内确定故障发生的位置。这无疑对迅速恢复业务系统大大地增加了难度。想象一下,客户在银行办理某个重要业务却长时间无法完成,显然是很难接受的;回到银行的角度,长时间数据无法处理,业务无法恢复,损失自然也相当惨重。银监会对银行的故障恢复时间提出了要求:15分钟内必须恢复!长此以往,运维部门的压力越来越大,工程师们需要付出更多的时间在故障处理的工作上。除了精力和时间上的大量消耗外,在心理上也会产生巨大的负担。以上场景我们定义为“运维之殇”,这不是一个简单独立的案例,在许多大型的银行、券商、运营商中都反复出现过。
那么到底是监控中的哪个环节出了问题,导致了如此严重的后果呢?仔细斟酌,问题还是出现在源头。运维人员缺乏一种有效的告警机制。各家银行集中监控中心的网管平台会对:网络设备,应用交付设备,主机等基础设备的资源类指标实现监控。因为不具备业务级别的性能监控,无法完成基础设备故障和交易性能的关联。而告警的准确性也是对运维人员的一个考验,在运维的过程中经常出现以下问题:
上海天旦一直致力于业务性能管理的技术研究和产品开发。其中CrossFlow BPC业务解决方案,真正实现了从业务视角出发,以服务为导向的业务性能管理。实现了业务层面的性能监控, 从根本上解决了告警和业务状况没有直接关联的现状。在2015年7月,上海天旦发布了全新的业务性能管理产品BPC 3.0。在BPC 3.0中对于告警功能进行了升级和性能优化,为运维部门进行故障诊断和处理带来了极大的帮助。
BPC 3.0对于不同岗位的人员提供了多种视图方式,通过层层的Drill-Down(钻取)的方式实现了从宏观总量到每笔交易细节的全立体监控。满足了从领导到一/二/三线运维人员的不同视角。
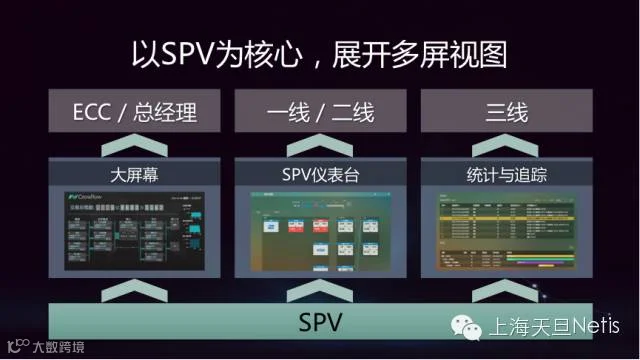
ECC大屏和服务仪表台都属于集中监控的手段,但又提供了不同的监控视角,对应不同的需求场景。
ECC监控中心里,投放BPC 3.0特有的大屏幕模式,从业务的视角实现监控 ,填补了ECC内业务监控视角的缺失。通过统一告警平台实现了基础设备告警和业务性能的结合。 在大屏设置里可以显示重要的交易信息,如交易总笔数或者交易总金额等。同时可以设置重要业务的连接关系、实时运行状况。大屏幕视图模式为监控人员或部门领导对公司重要业务的运行情况提供了直观的了解。
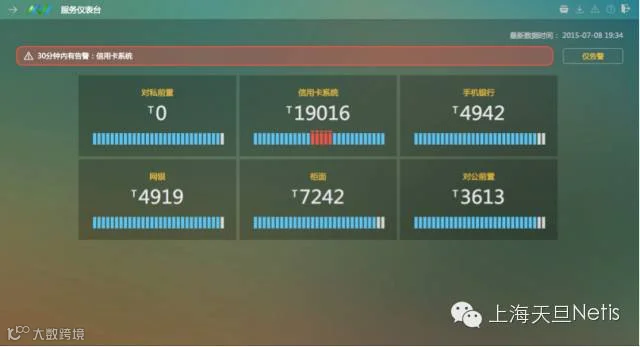
服务仪表台集中展示各个业务系统的实时运行状况。蓝色表示一切正常,红色表示有告警产生。在同一界面上集中展示所有重点监控系统的状况。哪个系统有问题,只有一个系统有问题,还是同时多个?这个问题发生在几分钟前?每个系统实时的交易量是多少?使得一线监控人员一目了然。
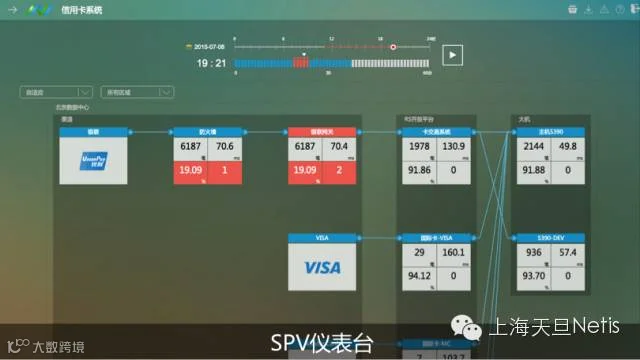
对于一线/二线的运维人员来说,光有大屏幕视角显示是不够的。BPC 3.0提供了SPV(服务路径)视图模式。在该视图下,运维人员可以查看到需要监控的业务的整个链路状态、组件与组件的连接情况等。视图最上方的时间轴组件,可提供最近24小时的历史数据给运维工程师进行回朔;下面的钢琴键则实时展现了30分钟内业务的运行情况。其中,蓝色琴键代表实时且运行正常的一分钟数据;红色琴键则代表有告警产生的一分钟数据。对于每个组件都由四方格组成,分别实时显示了该组件在一分钟内的交易笔数、响应时间、交易成功率、告警数。当有业务告警产生时,BPC会根据应用组件的前后关系,逻辑判断出根源组件,发生故障的组件颜色会由蓝色变成红色,一目了然。
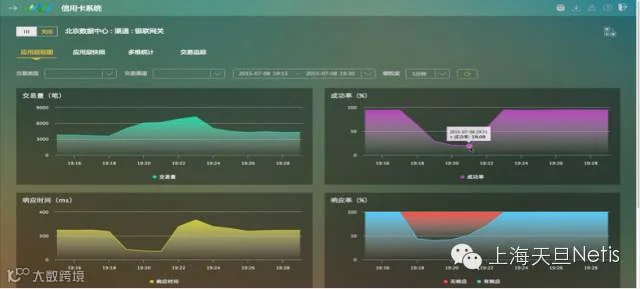
应用层视图则提供给三线的业务管理部门使用。当在SPV中点击任一组件,就可以查看该组件的具体参数包括交易量、成功率、响应时间、响应率、交易类型排名及返回码分布,以趋势图展现 。此外还可以继续向下钻取,通过多个维度的统计结果,查看一笔特定交易的具体情况。这样给业务部门的优化提供了客观依据。
如何设定准确的告警阈值一直是困扰运维人员的问题。有了多种视图工具后,各相关部门如何利用BPC 3.0快速设定符合预期的告警呢?BPC 3.0能够通过各业务已运行的历史数据的“复盘”实现精准的告警阈值设定。
“复盘”来源于华尔街的高频交易系统。在每天交易结束后,利用一整天的交易数据回测你的交易模型,是否实现了利润最大化。上海天旦把这交易“大数据”的最佳实践用到了告警的阈值设定。对过去一天,一周或者更久的交易历史数据进行分析,用当前环境的真实数据去检验这个阈值的设定是否合理。模拟结果和真实历史情况的比对,便可轻松的判断告警的阈值设置的是否合理。
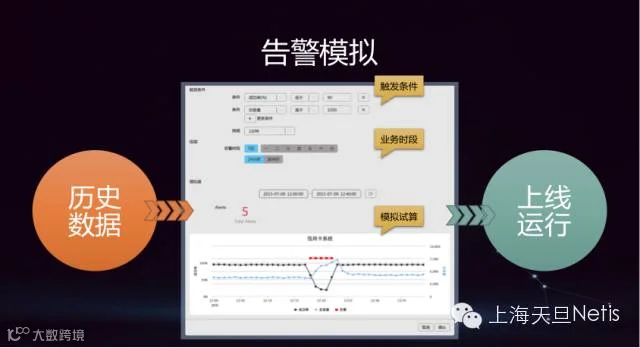
历史数据的回放配合高颗粒度的设置精度,让BPC 3.0能够产生精准的告警。这个过程分成四个步骤来完成:设置触发条件-告警模拟运行-验证模拟结果-上线运行。

可选择单个指标作为触发条件,也可设置2个以上的复合条件。同时可以定义故障发生的持续时间,也可以根据真实的业务时段定义(例:证券交易业务时段是周一至周五早上(9:15-11:30, 13:00-15:00)来设置。 简单说,BPC 可以查看某一个服务组件(或服务器)的某交易类型(例如:消费)在某个时间段内(9:15-11:30, 13:00-15:00)的交易量、响应时间和交易成功率三个指标的复合告警。
触发条件设置后,可以根据业务需求选择合适的历史数据时间范围,然后进行模拟试算,得出告警模拟的结果。
运维工程师根据各个业务的特点对模拟结果进行判断,确定其是否符合当前业务的真实情况。在回放的过程中是否触发了告警事件,模拟触发的告警事件和真实的业务故障能否对应等等。如果判断合理,就可以将该告警进行设置,上线运行;如果判断有误差,可以调整触发条件,重新模拟,直到产生满意的结果为止。
BPC 3.0的告警数据来源十分丰富,既可以根据服务路径或其中的某一个组件来提供,也可以由服务器提供。同时也可以根据维度数据(交易类型、交易渠道等)来判断告警。在BPC 3.0中,可以设置4种类型的告警,分别是:阈值告警、基线告警、返回码告警和故障定位。运维部门或业务部门可以根据不同的需求来设置。

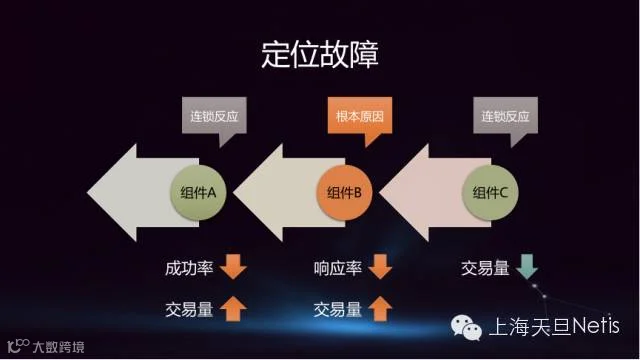
在监控业务系统时,仅仅设置常规告警是远远不够的。在目前的系统环境里,许多组件是协同工作的。故障产生了,很有可能会有2个或者更多的组件同时告警,哪个才是真正的故障源呢?如何准确地定位发生故障的位置和组件,同样十分重要。
BPC 3.0内置了一套故障定位的模型。有故障发生时,自动定位故障源。下图是一个典型的定位故障组件判断方法:通过三个组件交易量、影响率、成功率等指标发生的变化,找出发生故障的根本原因并成功定位故障源。
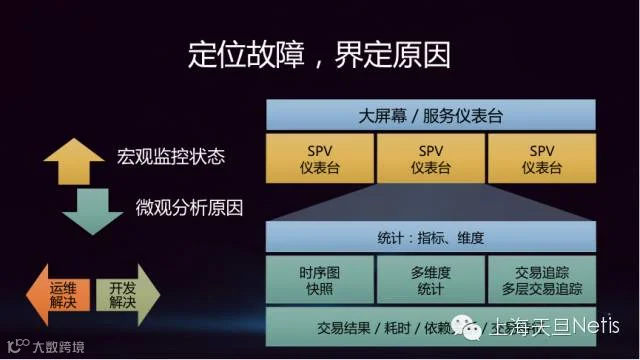
故障定位后,产生告警信息。一线/二线人员可以根据大屏幕或服务路径仪表台,快速发现发生告警的组件,给排障及业务恢复提供宝贵的时间。三线人员可根据应用层视图里的统计数据,包括时序图快照、多维度统计、交易追踪等,深层次的分析组件产生故障的原因,挖掘业务性能瓶颈,给业务系统进一步开发提升性能提供可靠的依据。
在BPC 3.0告警功能的帮助下,一线二线的工程师们在工作时可以实时地查看业务的运行情况,迅速地定位告警故障;在休息时再也不用担心系统发生问题而定位不出故障。对于三线的业务优化人员则多了一把分析业务瓶颈的利器。有了BPC 3.0 ,“运维之殇”的场景会越来越少,痛苦、负担这些之于运维人员的专有名次也可以彻底去除了。希望在BPC 3.0的引领下,运维会慢慢变得简单、高效而有乐趣。
我的中文名字叫旦旦
