

某月10日凌晨3点开始,BPC监控的第三方支付系统持续发生响应时间高于阈值的警告。BPC管理员联系对方后,其管理员却表示业务正常。
某日10:05分,核心业务系统触发响应时间告警,告警时段响应率略微波动。此时,业务仍然能够进行,业务人员并未反馈业务问题。
这些究竟是误告,还是另有隐情呢?
在近日举行的旦旦直播课《BPC如何在不同业务故障场景下为运维人员带来帮助》上,天旦老司机从六大场景化的告警视角出发,分享了不同业务场景的告警案例及经验总结。

文章开头的两个场景便是直播课的其中两个案例,现在就让我们回到案例,了解事情的来龙去脉:
案例回顾1
某月10日凌晨3点开始,BPC监控的第三方支付系统持续发生响应时间高于阈值的警告。BPC管理员联系对方后,第三方支付系统管理员表示业务正常,也没有收到前台业务异常的反馈。
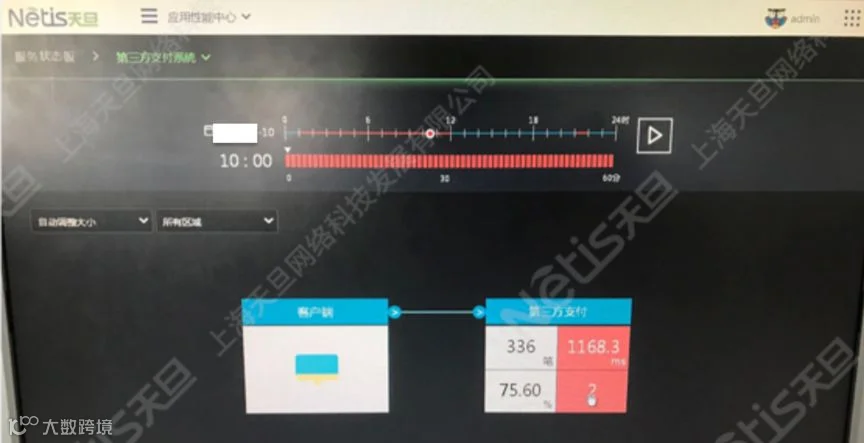
BPC管理员对此很疑惑,为何系统响应时间会异常并持续告警?于是通过应用层图视查看了响应时间的变化规律,发现8-10日第三方支付系统的平均响应时间不断上升。响应时间从最初的289ms上升到了1120ms。
BPC管理员再次联系对方管理员详细询问后才得知,8日第三方支付做过一次变更操作,同时核心数据库新增了一个第三方支付的表。于是BPC管理员通过BPC查看该表对应核心的应用类型「zfyw24h」,发现从8日起,「zfyw24h」应用类型的响应时间也在缓慢增加,从最初的99ms上升到了936ms。
问题最终得到确认,原来是是「zfyw24h」对应的表没有建索引导致交易越来越慢。随后应用负责人提交了紧急变更,当天13:00将对应的核心数据库的表建立索引,第三方支付系统响应时间恢复正常。
讲师总结:BPC不会无缘无故发生单系统级别告警,及时分析可以提前发现业务系统隐患,避免运维故障给业务带来影响。对重要系统,更加精细的告警配置,可以有效提高业务故障发现率(具体如何配置请看直播回放哦)。
案例回顾2
某日10:05分,核心业务系统触发响应时间告警(触发条件为:交易量>5下,连续3分钟系统响应时间高于3000ms)。此时,业务仍然能够进行,业务人员并未反馈业务问题。
随后客户通过BPC应用层图视功能分析告警时段业务运行状态,发现交易量指标平稳、效应率只有略微波动。通过网络部门的协助排查,发现是核心业务系统数据同步时网络出现波动造成,核心断开数据同步后,核心业务系统响应时间恢复正常。
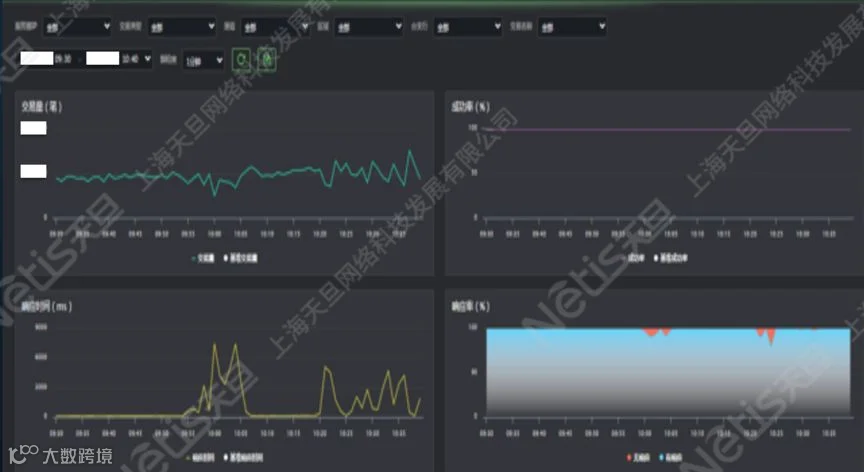
20分钟左右后,当数据同步再次打开,各分行给总行科技部打电话,反应办理业务出现卡顿,此时正是核心节点第二次响应时间指标显示异常时间(10:20左右)。而此时,客户已经了解是网络问题导致核心交易异常。BPC的实时感知告警已为运维争取了至少20分钟时间。
讲师总结:交易监控系统能够实时反映交易状态的变化,运维负责人全程关注交易监控系统的指标变化,能够为更进一步问题排查提供指导、争取更多宝贵时间,同时也可以通过指标的跟踪观察验证问题是否解决。
天旦资深客户技术经理坐镇“旦旦直播间”,对业务运维工作中最长遇到的6大故障场景进行逐个分析,配合真实用户案例,以期望BPC能够成为运维排障的神兵利器。
如果您错过了直播?
如果您想再次回顾课程案例分析?
如果您也难以快速解答以下问题:
如何准确判断业务问题来自外部 or 内部?
如何判断业务性能波动是网络问题 or 业务问题?
如何根据BPC告警快速排障?
运维部门如何通过BPC提升运维水平?





