
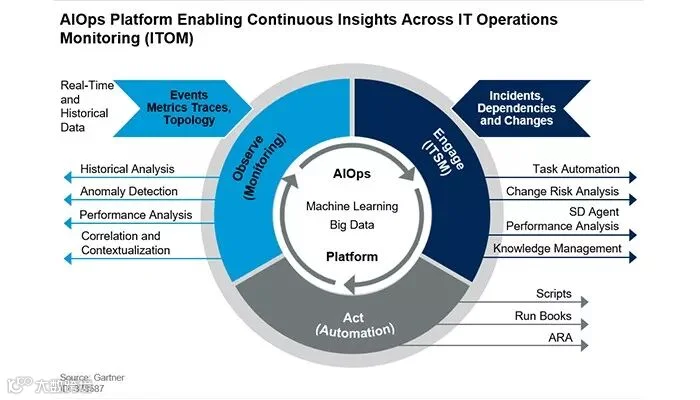
AIOps combines big data and machine learning to automate IT operations processes, including event correlation, anomaly detection and causality determination.
——Gartner
一
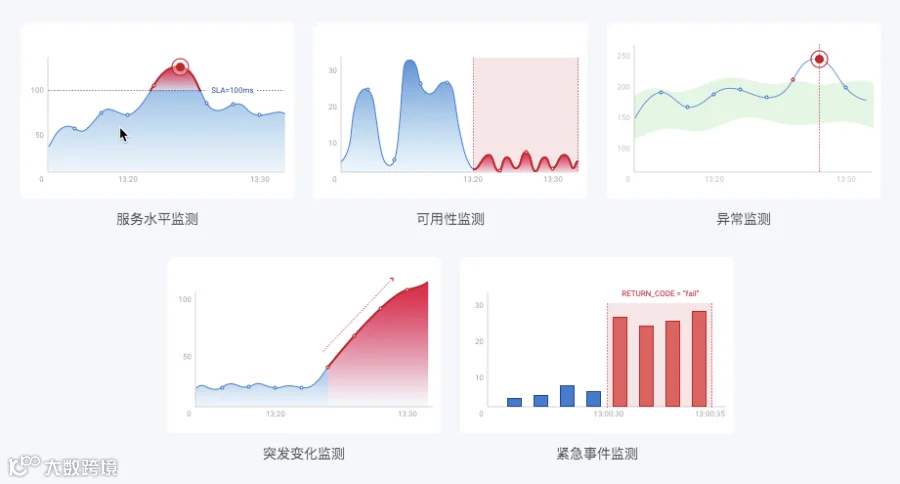
服务水平监测
案例:
2019年某日,某省农村信用社的所有应用服务器从11:46开始响应时间陡增,触发响应时间阈值,BPC发出服务水平告警。由于告警在故障发生后仅仅1分钟内就发出,运维人员及时介入,快速完成了排障并恢复了业务的正常运行,有效地避免了业务损失与影响客户体验。
二
可用性监测
案例:
过去,某股份制商业银行的密码修改业务的交易量随时间分布非常不平均,多次调整告警阈值仍反复出现低谷时间段漏报(交易量波动始终不超过阈值)和高峰时间段误报(交易量在阈值附近震荡,反复引发告警)。在升级BPC4.3后,运维人员利用可用性检测为该业务应用设定了针对特定时间段的告警(如凌晨设置低阈值,白天设置高阈值),通过计算一段时间内的平均值来降低影响,减少误报。
三
异常监测
案例:
某地城商行的个人网上银行访问量出现了小幅波动,因为该业务类型的交易量绝对值较低,相对整体交易量的影响非常小,原本的通用告警条件未被触发。在启用异常检测告警后,BPC根据过往访问量建立了基线,并且通过及时告警帮助发现了数次网络攻击及业务部门促销活动带来的访问量异常。
四
突发变化监测
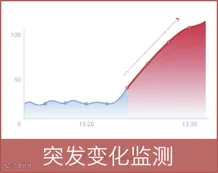
案例:
某日,某省农村信用社的核心应用发生了一个比较严重的问题,由于5124(来往业务记账接口)和5127(超网业务记账)交易超时,支付无法完成,导致出现5744自动冲正交易,数据库活期分户锁表,同时交易量累加,交易响应时间长达40多秒,支付类业务阻塞,交易量突然陡降,但仍处于正常交易量范围内,未触发阈值告警。这种情况下,如果通过判定交易量的斜率来作为告警条件,这种问题就可以尽早发现,大大缩小问题的影响面。
五
紧急事件监测
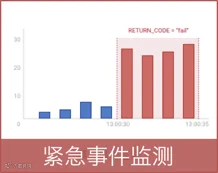
案例:
证监会对OTC交易系统的单笔交易故障定位的时间要求是5分钟。在实际场景中,在1分钟颗粒度的告警监控下,单笔交易最终确认失败耗时1分钟以上,告警需要经过至少1分钟才能形成统计数据,确定交易成功率跌破100%,此时用户已因交易失败提出投诉。在设置紧急事件监测后,一旦有交易发生失败,BPC立即在下一秒发出告警,为运维人员的故障定位和排障争取到宝贵时间。

释放科技潜力,启航数字化转型
天旦拥有丰富的行业专业知识,客户覆盖领先的数百家银行金融机构。天旦产品每天保障超过200亿笔金融交易的顺利达成。秉承让运维稳定无忧,运营做你所想的使命,天旦保障IT组织从容推进数字化转型战略而不用担忧现有关键业务的可靠运行,更可以通过互联数据促进新核心新应用即刻落地,建立实时客户洞察,直抵科技引领业务创新的新大陆。
关注天旦公众号
跟旦旦一起,
让运维稳定无忧,
运营做你所想。
