

黑客在攻击成功后经常使用域名反弹的方式对目标进行远程控制,所以对于失陷主机的定位除了流量分析时通过流量的指纹特征识别威胁,也可以通过检测主机是否解析了恶意域名来判断网络中威胁。
▼不直接用威胁情报的原因
星维九州作为一家专业的MSSP服务提供商,已实现对威胁情报的采集、整合和落地使用,在使用威胁情报中恶意域名进行事件关联分析时发现完全依靠威胁情报数据用于威胁分析存在以下缺陷:
1.误报多。威胁情报误报较多。从威胁情报的质量来看,不少正规中小网站、过期的域名、甚至Alexa排名一千以内的都被列为恶意域名。威胁情报的时效性和准确性导致部分数据质量不高,误报较多。
2.漏报更多。从威胁情报的性质上来看,越是大范围/长时间的攻击的行为、大面积传播的病毒,越容易被威胁情报所捕获。反之,针对性的APT特征攻击则不容易被收录,造成漏报。目前公司客户主要是智慧城市、政府、行业客户等,更容易被境外黑客盯上并发起针对性攻击。
3.不可控。网络安全事件的识别会存在误报和漏报,这是不可避免的。但误报和漏报率应做到可控,可控的安全系统你知道什么条件下会产生误报,所以你可以用其它策略去降低误报;你会知道什么样的攻击会被系统遗漏掉,所以可以用其它的安全方案来弥补这部分缺失。而威胁情报虽然内容可读,但部分威胁情报的采集、清洗、标记过程不透明,无法判断数据来源、数据质量(误报率和漏报率)。
因此我们决定用这批威胁情报作为AI训练集,学习威胁情报背后的数据特征,通过AI强大的泛化能力,可以减少漏报,并让安全系统变得可控。

▼选择AI维度
选择维度是很重要一项工作,你做的是人工智能还是人工智障,是神经网络还是神经病网络,很大程度上取决于选择的维度。
Alexa排名
一般情况下,恶意域名不会是流量非常高的网站域名。因此抓取Alexa排名作为维度。
通过接口抓取Alexa排名,如果域名没有Alexa排名数据,则认为它的排名非常靠后,设置一个非常大的数值:99999999。
如果是多级域名的话,除了抓取多级域名的Alexa,还要抓取主域名的Alexa。这样便共享了两个维度。
搜狗rank
搜狗rank和Alexa排名一样,反应的是网站的规模和流量的大小。不同的是Alexa是越小站越大,搜狗rank是值越大站越大。对于没有搜狗rank的站点,认为rank为0。
搜狗与百度的收录数量
一般情况下,恶意域名要多低调就有多低调,不会专门去做SEO的,也不会希望搜索引擎搜到到。
通过某个SEO接口爬取百度和搜狗收录页面的数量,对于搜不到的域名,认为收录数量为0。
必应收录数量
与“百度和搜狗收录数量”形成互补,因为必应对于境外域名收录的更全一些,而百度搜狗对国内收录的更好一些。本来想用Google的,但是Google太频繁的抓取会有验证码,没必要把精力花费在破解验证码上面。
必应的收录数量并没有查询接口,因此直接用site:domain.com的方式直接抓取收录数量,相比SEO查询接口,这样直接抓取也更准确一些。
网站首页完整度
很多域名会解析到web服务器,一般情况下,正规域名解析到正常的网站,而恶意域名的解析ip要么没有web服务,要么是没有内容的首页。例如404页面、Apache默认页面、空白页面等等。
那么怎么判断首页是不是正常的、完整的呢。最好的方法就是用head less浏览器(如phantomjs)去访问,检查首页(包括多媒体资源)的大小,以及媒体资源是否成功加载。这是后续可以优化的一个点。
这里我们用了一个取巧的办法,直接判断首页各个媒体标签的数量。精心设计的首页肯定有img link script等标签,满足的越多,完整度level遍越高。如下图所示,取level值作为完整度。如果没开放web服务,则level为0。
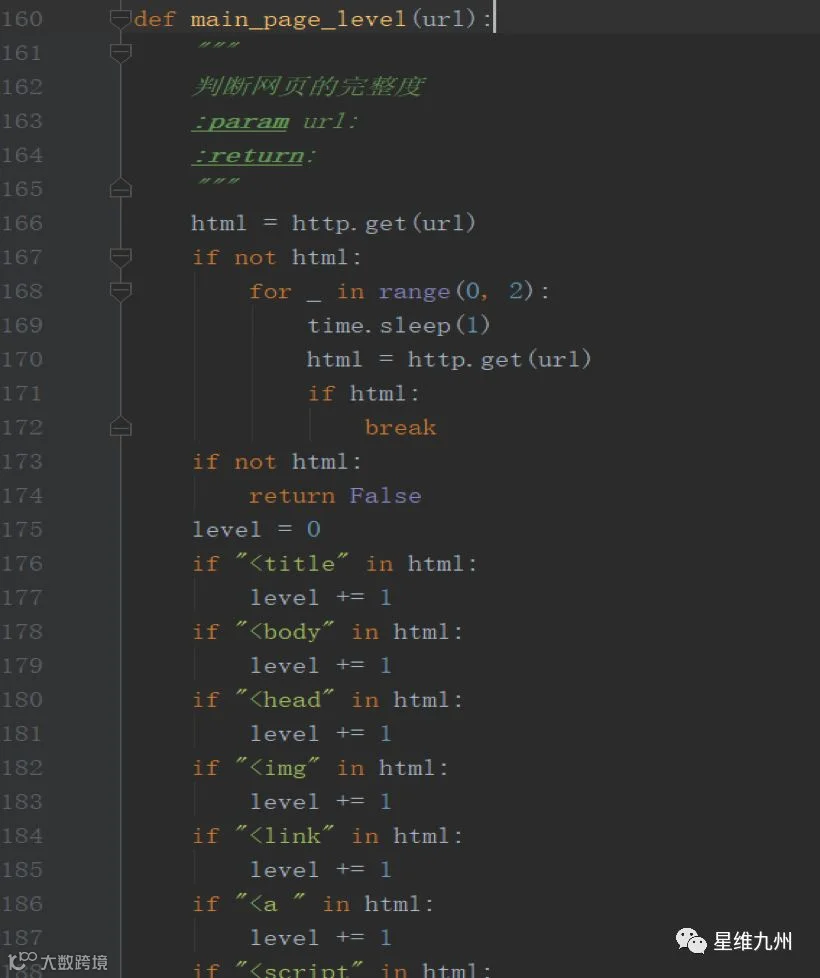
图1通过标签给网页完整度评分
是否是主流域名后缀
一般情况下,普通域名大多数常用.com、.net.、.cn等主流后缀,而恶意域名往往会喜欢注册小国家域名,如.io、.ru等。
Cn域名一般都要求实名备案,恶意域名很少有cn域名。
地理位置
国内对主机审查比较严,除了被黑的肉鸡,很少有专门申请国内主机用于黑客行为的。
另外公司客户主要是政府国企类,向境外的反连本来就是可疑行为,因此把域名的地理位置作为一个维度。
A记录与CNAME
正规公司如果有注册企业邮箱的,企业域名一般都会注册A记录和CNAME。而恶意域名可能只会注册A记录。
如果一个域名既没有A也没有CNAME,维度值为0。
待加入维度
WHOIS匿名
恶意域名的whois信息一般都选择匿名,因此whois信息是否匿名应当作为一个判断维度。在实际测试过程中,发现很多匿名域名的注册人、联系方式等字段,不是为空,而是nameserver或者域名注册商的联系方式,因此要建立一个域名商匿名信息的黑名单来判断是否匿名。维护成本有些高,在第一个版本中暂不加入该维度。
域名更新的频繁程度
使用域名的ttl值或者历史解析记录。一般认为恶意域名的解析更换的比较频繁。做坏事嘛,总是喜欢打一枪换一个地方。
是否使用CDN
检测域名是否使用了CDN。CDN一般用于流量比较大的站点进行加速,木马或shell的C&C域名一般是不会用的。

▼清洗数据
本文定义的恶意域名为黑客实施攻击时用的域名,包括但不限于:木马回连、病毒通讯、反弹shell、SSRF、XSS、DDoS、挂马、矿机、DNS隧道木马等等。总之都是黑客攻击所用。
威胁情报里的域名中有不少我们不需要的,这些信息要人工剔除。例如博彩网站、色情站、垃圾邮件域名。用AI也可以识别:抓取网站内容后直接上朴素贝叶斯,或者走NLP情感分析的套路即可,这不在本文的讨论范围内。还有钓鱼站也要剔除,识别钓鱼站是另一个话题了。
由于担心误报影响样本质量,只取置信度较高的那部分域名。
恶意域名作为正样本,正常域名作为负样本,正负样本比例大约为1:1。
取威胁情报中9月10日的全量恶意域名作为训练集,另取9月11-17日的增量部分作为测试集。

图2整理后的恶意域名样本

▼建立模型
我们训练了两种模型,一个是机器学习的代表算法支持向量机SVM,另一个是卷积神经网络CNN。最后通过多方面对比绝对线上业务使用哪个。
支持向量机
在神经网络没火之前,SVM是应用最广泛的机器学习算法之一,对于线性可分的样本集识别率很高,那也就注定了本次我们用SVM的效果不会差。
#载入训练集数据
x_data, y_label = data.load_tran_data()
#数据归一化。由于有些维度值特别高,如百度收录量和Alexa值,有些维度则特别低,只有1或者0。因此等比缩小是不可取的,否则收敛特别慢。这里将数据缩小至方差为1均值0的数组
x_data = preprocessing.scale(x_data)
svc = svm.SVC()
parameters = [
{
'C': [0.5, 0.8, 0.9, 1, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 3, 5, 7, 9, 11, 13, 15, 17, 19, 30, 50],
'gamma': [0.1, 0.5, 0.6, 0.7, 0.8, 0.9, 1, 1.2, 1.3, 1.5, 2, 2.5, 3, 4, 5, 6, 7, 8, 9, 10, 11],
'kernel': ['rbf']
},
{
'C': [0.5, 0.8, 0.9, 1, 2, 3, 4, 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 5, 5.5, 6, 7, 9, 11, 13, 15, 17, 19, 30, 50],
'kernel': ['linear']
}
]
# 使用rbf和linear两种核函数进行对比,同时使用“爆破”的方式寻找最优参数组合
clf = GridSearchCV(svc, parameters, cv=5, n_jobs=8)
clf.fit(x_data, y_label)
# 打印最优参数组合
print(clf.best_params_)
best_model = clf.best_estimator_
joblib.dump(best_model, "svm2.2.m")
最终确定的最优参数组合是核函数linear和C参数4.2,证明样本是线性可分的。
在测试集上进行测试,结果准确率97.2% 、召回率97.3%,翻译成我们熟悉的指标,误报率为2.8%、漏报率都为2.7%。
卷积神经网络
卷积神经网络CNN可以说凭一己之力掀起了近几年AI热潮。CNN的特点是强调显细节的特征,大家熟悉的是CNN在图像方面的应用,其实一维的文本、二维的图像、三维的空间、四维的宇宙、五维度的量子态……都可以卷,颇有“大饼卷一切”的趋势,连三体人的智子都望尘莫及。
总之,理论上CNN可以拟合任意函数,自然包括线性函数了。
x_data, y_label = data.load_test_data() #载入训练集并归一化
x_data = preprocessing.scale(x_data)
x_data = np.expand_dims(x_data, axis=2)
dim = len(x_data[0])
y_len = len(y_label)
model = Sequential()
# 输入层、卷基层
model.add(Conv1D(4, 3, input_shape(dim,1),padding='same',activation='relu',use_bias=True))
# BN算法,使输出信号规范为“均值0,方差1”,目的是加速收敛
model.add(BatchNormalization())
# 最大池化层
model.add(MaxPooling1D(3))
# 放弃层,防止过拟合
model.add(Dropout(0.5))
# 再来一次卷积,经过BN算法规范化后,进行平均池化
model.add(Conv1D(8, 3, padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
# 两层全连接
model.add(Dense(4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 训练模型
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_data, y_label, batch_size=20, epochs=600)
model.save("beta_cnn1.22.h5")
该模型在测试集上准确率为97.5%,召回率96.7%。

▼线上应用
SVM和CNN模型对比数据如下:
模型名称 |
准确率 |
召回率 |
SVM |
97.2% (误报率2.8%) |
97.3% (漏报率2.7%) |
CNN |
97.5% (误报率2.5%) |
96.7% (漏报率3.3%) |
两种模型相对而言,SVM误报略高漏报低,而CNN误报低漏报高。整体而言两个模型指标相近,SVM略好于CNN,最终线上决定使用SVM作为检测算法。
SVM的2.8%的误报率反映在出口流量上有点多,需要配合其他策略如黑白名单降低误报。后来在实际线上应用中,发现误报的一部分来自于程序所用的API的域名,这类域名在训练集中没有包含。修正过程本文不再赘述。



